

La codificación agéntica se está convirtiendo rápidamente en la interfaz predeterminada para desarrollar software: describes un objetivo, el modelo planea, llama herramientas, edita archivos e itera hasta que la tarea está completa. Dos modelos que aparecen con frecuencia en los stacks de desarrollo reales son Kimi K2.5 de Moonshot AI y GLM-4.7 de Z.AI, ambos diseñados para ser fuertes en contexto largo, uso de herramientas y codificación “lista para producción”.
Esta publicación compara benchmarks, velocidad y latencia, y costos (precios de Novita AI) —y luego muestra cómo probar e implementar ambos modelos al instante en Novita AI.
Introducción Básica
Aquí está la comparación lado a lado de GLM-4.7 y Kimi K2.5:
| Característica | GLM-4.7 | Kimi K2.5 |
| Desarrollador | Z.AI | Moonshot AI |
| Fecha de lanzamiento | 22 de diciembre de 2025 | 27 de enero de 2026 |
| Arquitectura | Modelo de Mezcla de Expertos (MoE) de 358B parámetros | Modelo MoE de 1T de parámetros totales (32B parámetros activos por token, 384 expertos, 8 activados por token) con arquitectura multimodal nativa |
| Ventana de contexto | 200k entrada / 128k salida | 262,144 entrada / 262,144 salida |
| Capacidades de entrada | Solo texto | Texto, Imagen, Video |
| Capacidades de salida | Texto | Texto |
| Capacidades clave | Comprensión de contexto largo, generación de código | Comprensión multimodal, colaboración en enjambre de agentes (hasta 100 subagentes), programación visual, procesamiento de documentos largos, llamada a herramientas |
Desglose de Diferencias Clave
- Escala del modelo: Kimi K2.5 tiene un recuento total de parámetros mucho mayor (1T frente a 358B) y parámetros activos más altos por token, lo que teóricamente permite una mayor capacidad de conocimiento y rendimiento.
- Soporte multimodal: Kimi K2.5 es un modelo multimodal nativo que puede entender imágenes, videos y realizar programación visual, mientras que GLM-4.7 se centra únicamente en capacidades de texto.
- Ventana de contexto: La ventana de entrada de 256k de Kimi K2.5 es más larga que los 200k de GLM-4.7, lo que lo hace más adecuado para documentos ultra largos como contratos legales completos o artículos académicos.
Comparación de Benchmarks
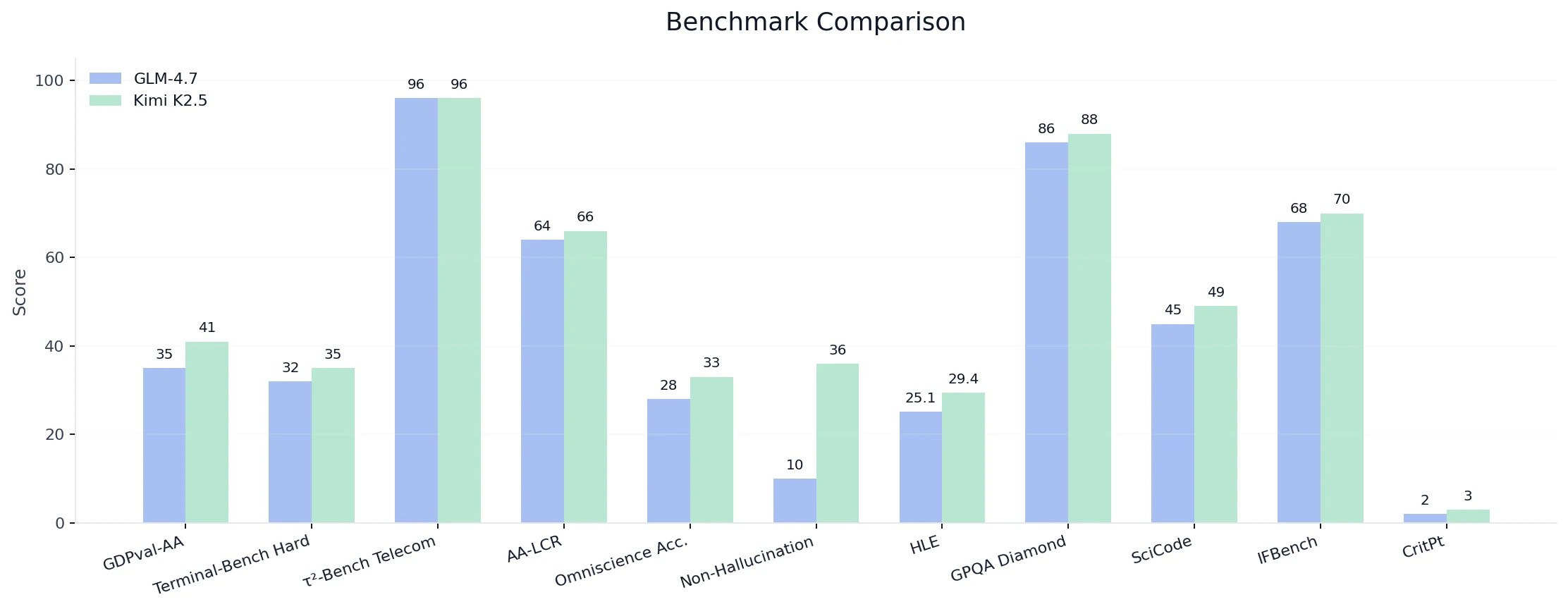
| Capacidad | Benchmark | Kimi K2.5 | GLM-4.7 | Resultado |
| Razonamiento | GDPval-AA (ELO-500/2000) | 41% | 35% | 6% |
| AA-LCR (Razonamiento de Contexto Largo) | 66% | 64% | 2% | |
| Examen Final de la Humanidad | 29.40% | 25.10% | 4.3% | |
| GPQA Diamond (Razonamiento Científico) | 88% | 86% | 2% | |
| CritPt (Razonamiento Físico) | 3% | 2% | 1% | |
| Codificación | SciCode | 49% | 45% | 4% |
| Terminal-Bench Hard (Codificación Agéntica) | 35% | 32% | 3% | |
| Herramienta / Agente | τ²-Bench Telecom (Uso de Herramientas Agénticas) | 96% | 96% | 0% (empate) |
| IFBench (Seguimiento de Instrucciones) | 70% | 68% | 2% | |
| AA-Omniscience Tasa de No Alucinación | 36% | 10% | 26% | |
| Conocimiento | Precisión AA-Omniscience | 33% | 28% | 5% |
💡Interpretación:
- En general: Kimi K2.5 lidera en 10 / 11 benchmarks, con márgenes que van desde +1% hasta +26%.
- Mayor ventaja:
- Tasa de No Alucinación: +26%, indicando una fiabilidad sustancialmente mayor en entornos de agentes/herramientas.
- Razonamiento y Codificación:
- Mayormente ganancias pequeñas a moderadas pero consistentes (+1% a +6%), lo que sugiere una superioridad amplia pero estable en lugar de depender de un único valor atípico.
- Uso de Herramientas:
- La capacidad bruta de herramientas (τ²-Bench) está empatada, pero la fiabilidad conductual favorece fuertemente a Kimi.
Comparación de Velocidad y Latencia
El rendimiento no es solo “tokens/segundo”. Para flujos de trabajo de desarrollo, lo que los usuarios sienten es:
- Tiempo hasta el primer token (qué tan rápido el modelo comienza a responder)
- Tiempo total (qué tan rápido obtienes un fragmento utilizable de salida)
- Rendimiento de salida (qué tan rápido transmite una vez que comienza)
| Métrica | Kimi K2.5 | GLM-4.7 | Qué significa |
| Velocidad de salida (tokens/segundo) | 118 | 99 | Kimi generalmente se siente más rápido en generaciones largas (código, informes, diffs de múltiples archivos). |
| Tiempo hasta el primer token de respuesta (TTFA) | 18.3s total (≈17.0s “pensando”) | 20.9s total (≈20.2s “pensando”) | Kimi comienza a responder antes en esta prueba. |
| Tiempo de respuesta total (hasta 500 tokens) | 22.6s | 26.0s | Kimi completa una respuesta de 500 tokens más rápido en esta ejecución. |
Comparación de Costos
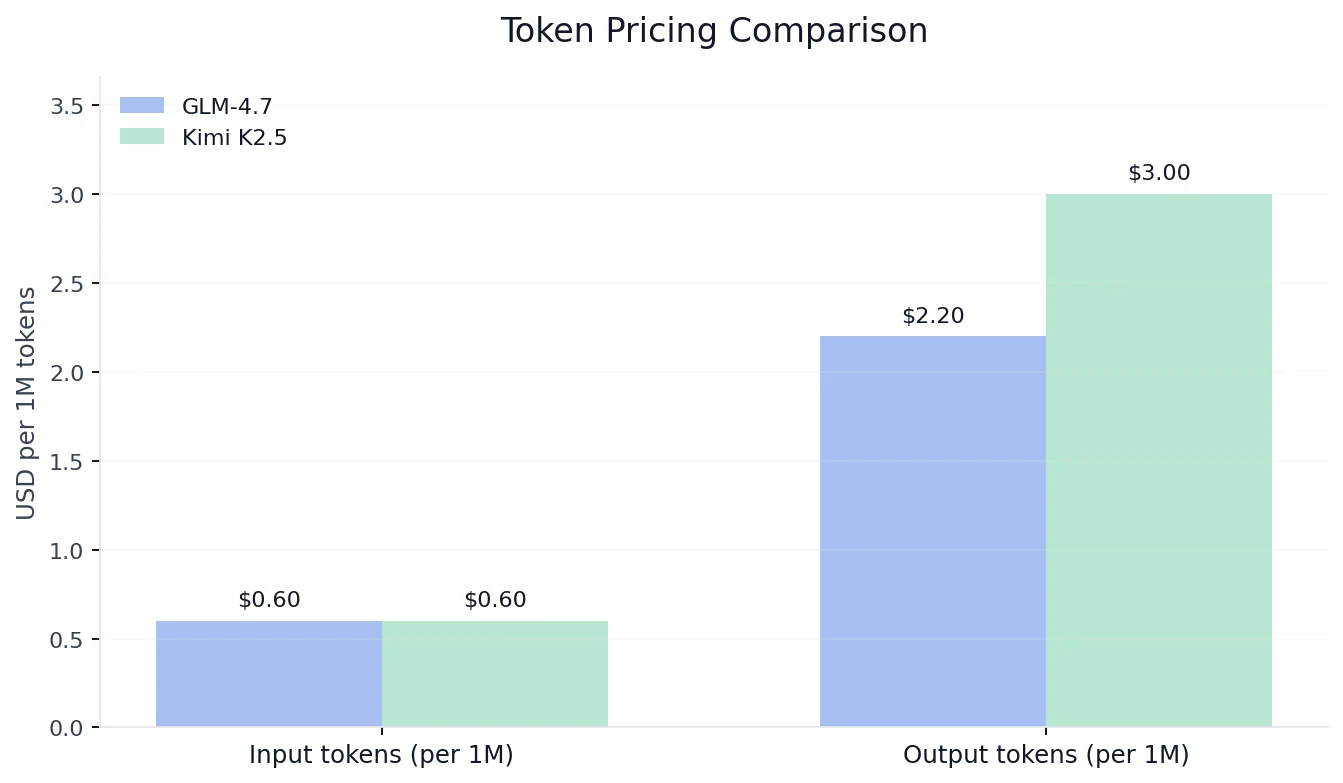
De Novita AI
Conclusión de costos: Si optimizas para el costo de tokens de salida, GLM-4.7 es materialmente más barato a la misma tasa de entrada. Si optimizas para techos de benchmark más altos + mayor rendimiento, Kimi K2.5 puede justificar la prima.
Inicio Rápido: Prueba Ambos Modelos al Instante en el Playground
La forma más rápida de sentir la diferencia entre Kimi K2.5 y GLM-4.7 es el Playground de Novita AI—sin código, sin configuración.
En el Playground, puedes:
- Cambiar entre modelos al instante entre
moonshotai/kimi-k2.5yzai-org/glm-4.7 - Ejecutar el mismo prompt exacto para comparar calidad de respuesta, estilo de razonamiento y velocidad de respuesta
- Validar prompts listos para producción (por ejemplo, JSON estricto, salidas tipo herramienta, restricciones de formato) antes de pasar a la API
Playground de Novita AI
Cómo Implementar: API, SDK e Integraciones de Terceros
Opción A: API
Obteniendo tu Clave API en Novita AI
- Paso 1: Crea o inicia sesión en tu cuenta: Visita
[https://novita.ai](https://novita.ai)y regístrate o inicia sesión. - Paso 2: Navega a Gestión de Claves: Después de iniciar sesión, busca “API Keys”.
- Paso 3: Crea una nueva clave: Haz clic en el botón “Add New Key”.
- Paso 4: Guarda tu clave inmediatamente: Copia y almacena la clave tan pronto como se genere; solo se muestra una vez.

Llama a Novita mediante endpoint
Solo cambia:
base_url:https://api.novita.ai/openaiapi_key: tu clave de Novitamodel:moonshotai/kimi-k2.5ozai-org/glm-4.7
from openai import OpenAI
client = OpenAI(
api_key="<Tu Clave API>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="moonshotai/kimi-k2.5",
messages=[
{"role": "system", "content": "Eres un asistente útil."},
{"role": "user", "content": "Hola, ¿cómo estás?"}
],
max_tokens=262144,
temperature=0.7
)
print(response.choices[0].message.content)
Opción B: SDK
Si estás construyendo flujos de trabajo agénticos (enrutamiento, transferencias, llamadas a herramientas/funciones), Novita funciona con SDK compatibles con OpenAI con cambios mínimos:
- Compatible de forma inmediata: mantén tu lógica de cliente existente; solo cambia base_url + model
- Listo para orquestación: fácil de implementar enrutamiento (Flash predeterminado → escalamiento a GLM-4.7)
- Configuración: apunta a
https://api.novita.ai/openai, estableceNOVITA_API_KEY, seleccionamoonshotai/kimi-k2.5ozai-org/glm-4.7
Opción C: Plataformas de Terceros
También puedes ejecutar modelos alojados en Novita a través de ecosistemas populares:
- Frameworks de agentes y constructores de aplicaciones: Sigue las guías de integración paso a paso de Novita para conectarte con herramientas populares como Continue, AnythingLLM, LangChain y Langflow.
- Hugging Face Hub: Novita aparece como un Proveedor de Inferencia en Hugging Face, por lo que puedes ejecutar modelos compatibles a través del flujo de trabajo y ecosistema del proveedor de Hugging Face.
- API compatible con OpenAI: Los endpoints LLM de Novita son compatibles con el estándar de la API de OpenAI, lo que facilita migrar aplicaciones existentes estilo OpenAI y conectar muchas herramientas compatibles con OpenAI ( Cline, Cursor , Trae y Qwen Code) .
- API compatible con Anthropic: Novita también proporciona acceso compatible con el SDK de Anthropic para que puedas integrar modelos respaldados por Novita en flujos de trabajo de codificación agéntica estilo Claude Code.
- OpenCode: Novita AI ahora está integrado directamente en OpenCode como un proveedor compatible, por lo que los usuarios pueden seleccionar Novita en OpenCode sin configuración manual.
Conclusión
Elige Kimi K2.5 si deseas el perfil de capacidad general más fuerte en este conjunto de benchmarks, especialmente para fiabilidad/no alucinación, además de un mejor rendimiento y generación total más rápida.
Elige GLM-4.7 si deseas un modelo insignia de contexto largo altamente capaz optimizado para codificación agéntica a un costo de token de salida más bajo, y estás operando a escala donde la economía unitaria domina.
De cualquier manera, Novita AI facilita ejecutar ambos modelos lado a lado—misma plataforma, misma superficie de facturación y cambio rápido de modelos—para que puedas tomar la decisión con datos reales de carga de trabajo en lugar de suposiciones.
Novita AI es una plataforma en la nube de IA que ofrece a los desarrolladores una forma fácil de implementar modelos de IA usando nuestra API simple, al mismo tiempo que proporciona la nube de GPU asequible y confiable para construir y escalar.
Preguntas Frecuentes
¿Es Kimi K2.5 de código abierto?
Kimi K2.5 no es completamente de código abierto en el sentido estricto. Es un modelo de pesos abiertos lanzado por Moonshot AI bajo la licencia MIT. Los pesos del modelo y el código de inferencia están disponibles públicamente para uso comercial, implementación local y ajuste fino. Sin embargo, Moonshot AI no ha publicado su código de entrenamiento completo, conjunto de datos de entrenamiento ni pipeline de entrenamiento, por lo que el modelo no puede ser completamente reproducido desde cero.
¿Qué es Kimi K2.5?
Kimi K2.5 es un modelo de lenguaje grande multimodal mejorado desarrollado por Moonshot AI. Como sucesor de Kimi K2, admite entradas multimodales que incluyen texto, imágenes y video. Ofrece un rendimiento mejorado en calidad conversacional, razonamiento lógico, procesamiento de contexto largo y comprensión multimodal, y permite a los usuarios implementar y personalizar el modelo localmente a través de sus pesos abiertos.
¿Cuál es la diferencia entre Kimi K2.5 y Kimi K2?
Kimi K2.5 es una versión mejorada de Kimi K2 con capacidades multimodales y de razonamiento más fuertes, y publica abiertamente los pesos del modelo para implementación local. Kimi K2 solo proporciona servicios API en línea sin pesos públicos.



