

Agentische Codierung wird schnell zur Standard-Schnittstelle für die Softwareentwicklung: Du beschreibst ein Ziel, das Modell plant, ruft Tools auf, bearbeitet Dateien und iteriert, bis die Aufgabe erledigt ist. Zwei Modelle, die häufig in realen Entwickler-Stacks zum Einsatz kommen, sind Kimi K2.5 von Moonshot AI und GLM-4.7 von Z.AI – beide sind darauf ausgelegt, stark im Umgang mit langen Kontexten, Tool-Nutzung und produktionsreifer Codierung zu sein.
Dieser Beitrag vergleicht Benchmarks, Geschwindigkeit & Latenz und Kosten (Novita AI Preise) – und zeigt anschließend, wie du beide Modelle sofort auf Novita AI testen und bereitstellen kannst.
Grundlegende Einführung
Hier ist der direkte Vergleich von GLM-4.7 und Kimi K2.5:
| Funktion | GLM-4.7 | Kimi K2.5 |
| Entwickler | Z.AI | Moonshot AI |
| Veröffentlichungsdatum | 22. Dez. 2025 | 27. Jan. 2026 |
| Architektur | 358B Parameter Mixture-of-Experts (MoE) | 1T Gesamtparameter-MoE-Modell (32B aktive Parameter pro Token, 384 Experten, 8 pro Token aktiviert) mit nativer multimodaler Architektur |
| Kontextfenster | 200k Eingabe / 128k Ausgabe | 262.144 Eingabe / 262.144 Ausgabe |
| Eingabefähigkeiten | Nur Text | Text, Bild, Video |
| Ausgabefähigkeiten | Text | Text |
| Hauptfunktionen | Verstehen langer Kontexte, Codegenerierung | Multimodales Verstehen, Agenten-Schwarmzusammenarbeit (bis zu 100 Sub-Agenten), visuelle Programmierung, Verarbeitung langer Dokumente, Tool-Aufrufe |
Wichtige Unterschiede im Überblick
- Modellgröße: Kimi K2.5 hat eine deutlich größere Gesamtparameterzahl (1T vs. 358B) und mehr aktive Parameter pro Token, was theoretisch eine stärkere Wissenskapazität und Leistung ermöglicht.
- Multimodale Unterstützung: Kimi K2.5 ist ein natives multimodales Modell, das Bilder, Videos verstehen und visuelle Programmierung durchführen kann, während GLM-4.7 sich ausschließlich auf Textfunktionen konzentriert.
- Kontextfenster: Das 256k-Eingabefenster von Kimi K2.5 ist länger als das 200k-Fenster von GLM-4.7, wodurch es besser für extrem lange Dokumente wie vollständige Verträge oder wissenschaftliche Arbeiten geeignet ist.
Benchmark-Vergleich
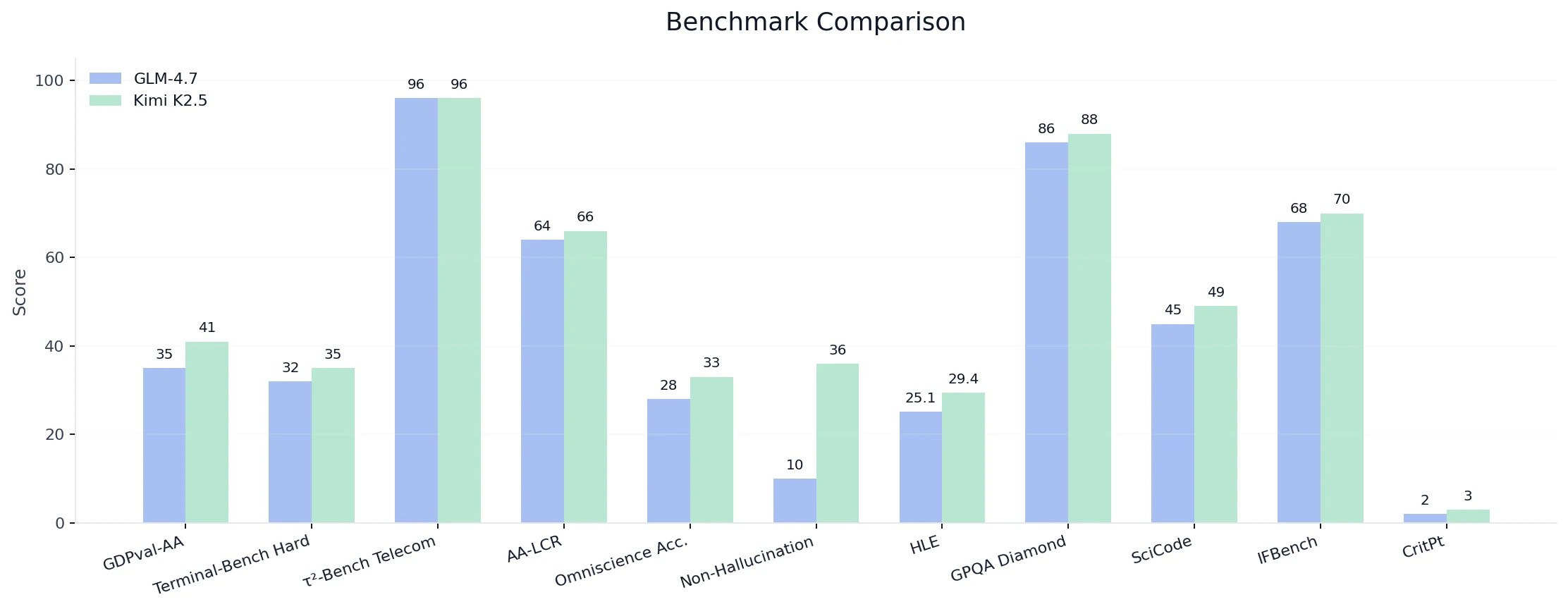
| Fähigkeit | Benchmark | Kimi K2.5 | GLM-4.7 | Ergebnis |
| Schlussfolgerung | GDPval-AA (ELO-500/2000) | 41 % | 35 % | 6 % |
| AA-LCR (Langkontext-Schlussfolgerung) | 66 % | 64 % | 2 % | |
| Humanity’s Last Exam | 29,40 % | 25,10 % | 4,3 % | |
| GPQA Diamond (Wissenschaftliche Schlussfolgerung) | 88 % | 86 % | 2 % | |
| CritPt (Physikalische Schlussfolgerung) | 3 % | 2 % | 1 % | |
| Codierung | SciCode | 49 % | 45 % | 4 % |
| Terminal-Bench Hard (Agentische Codierung) | 35 % | 32 % | 3 % | |
| Tool / Agent | τ²-Bench Telecom (Agentische Tool-Nutzung) | 96 % | 96 % | 0 % (Unentschieden) |
| IFBench (Befolgung von Anweisungen) | 70 % | 68 % | 2 % | |
| AA-Omniscience Nicht-Halluzinationsrate | 36 % | 10 % | 26 % | |
| Wissen | AA-Omniscience Genauigkeit | 33 % | 28 % | 5 % |
💡Interpretation:
- Gesamt: Kimi K2.5 führt in 10 von 11 Benchmarks mit Margen zwischen +1 % und +26 %.
- Größter Vorteil:
- Nicht-Halluzinationsrate: +26 %, was auf eine deutlich höhere Zuverlässigkeit in agenten-/toolbasierten Umgebungen hinweist.
- Schlussfolgerung & Codierung:
- Meist kleine bis moderate, aber konsistente Verbesserungen (+1 % bis +6 %), was auf eine breite, stabile Überlegenheit statt einer Abhängigkeit von einzelnen Ausreißern hindeutet.
- Tool-Nutzung:
- Die rohe Tool-Fähigkeit (τ²-Bench) ist gleichauf, aber die Verhaltenszuverlässigkeit spricht deutlich für Kimi.
Geschwindigkeits- und Latenzvergleich
Leistung ist nicht nur „Tokens/Sekunde“. Bei Entwickler-Workflows zählt, was Nutzer wahrnehmen:
- Zeit bis zum ersten Token (wie schnell das Modell mit der Antwort beginnt)
- End-to-End-Zeit (wie schnell du einen nutzbaren Teil der Ausgabe erhältst)
- Ausgabedurchsatz (wie schnell der Stream startet, sobald die Antwort beginnt)
| Metrik | Kimi K2.5 | GLM-4.7 | Bedeutung |
| Ausgabegeschwindigkeit (Tokens/Sekunde) | 118 | 99 | Kimi fühlt sich bei langen Generierungen (Code, Berichte, Multi-Datei-Diffs) in der Regel schneller an. |
| Zeit bis zum ersten Antwort-Token (TTFA) | 18,3 s gesamt (≈17,0 s „Denken“) | 20,9 s gesamt (≈20,2 s „Denken“) | Kimi beginnt in diesem Test früher mit der Antwort. |
| End-to-End-Antwortzeit (bis 500 Token) | 22,6 s | 26,0 s | Kimi schließt eine 500-Token-Antwort in diesem Durchlauf schneller ab. |
Kostenvergleich
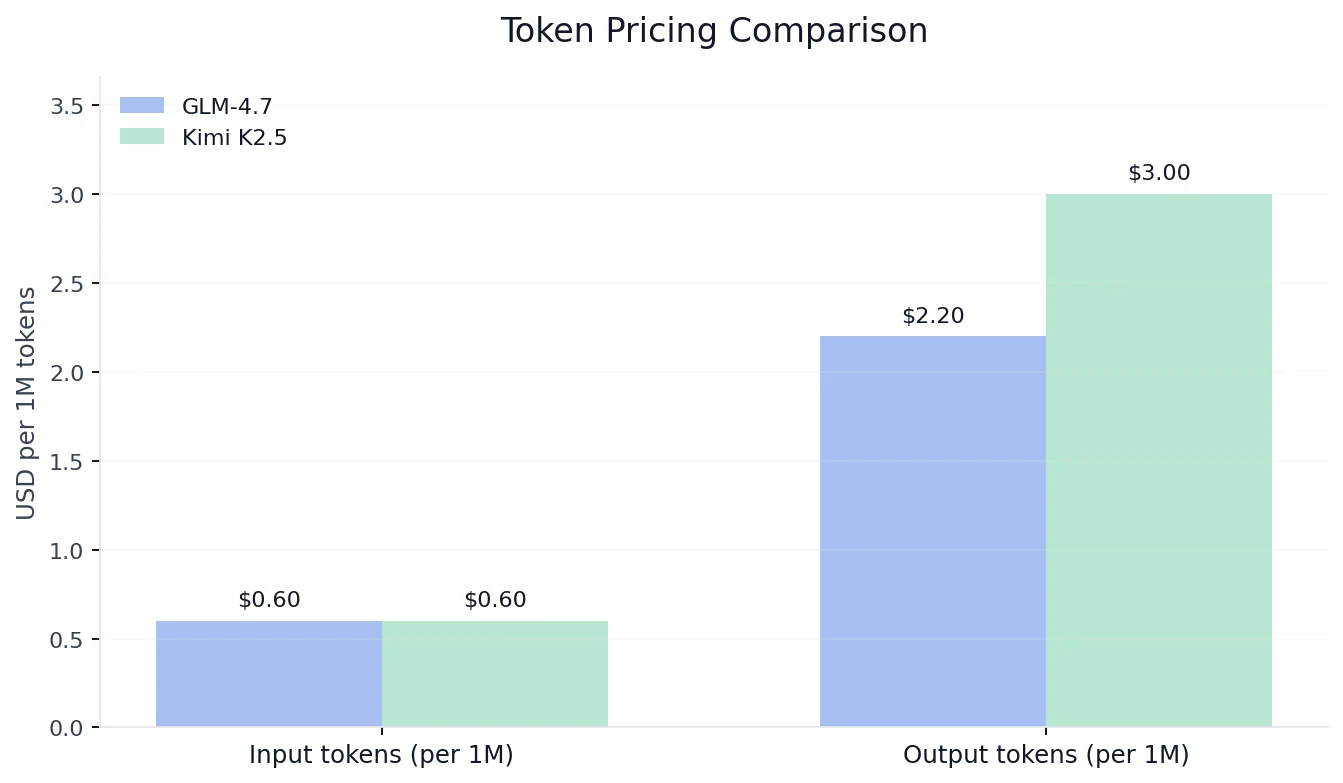
Von Novita AI
Kernaussage zu den Kosten: Wenn du auf Ausgabe-Token-Kosten optimierst, ist GLM-4.7 bei gleicher Eingaberate deutlich günstiger. Wenn du auf höhere Benchmark-Obergrenzen + schnelleren Durchsatz optimierst, kann Kimi K2.5 den Aufpreis rechtfertigen.
Schnellstart: Teste beide Modelle sofort im Playground
Der schnellste Weg, den Unterschied zwischen Kimi K2.5 und GLM-4.7 zu spüren, ist das Novita AI Playground – kein Code, keine Einrichtung.
Im Playground kannst du:
- Wechsle sofort zwischen den Modellen
moonshotai/kimi-k2.5undzai-org/glm-4.7 - Verwende den exakt gleichen Prompt, um Antwortqualität, Schlussfolgerungsstil und Antwortgeschwindigkeit zu vergleichen
- Validiere produktionsreife Prompts (z. B. strenges JSON, toolartige Ausgaben, Formatierungsvorgaben), bevor du zur API wechselst
Novita AI Playground
Bereitstellung: API, SDK und Drittanbieter-Integrationen
Option A: API
API-Schlüssel auf Novita AI erhalten
- Schritt 1: Konto erstellen oder anmelden: Besuche
[https://novita.ai](https://novita.ai)und registriere dich oder melde dich an. - Schritt 2: Zum Schlüsselverwaltung navigieren: Nach der Anmeldung findest du den Bereich „API-Schlüssel“.
- Schritt 3: Neuen Schlüssel erstellen: Klicke auf die Schaltfläche „Neuen Schlüssel hinzufügen“.
- Schritt 4: Schlüssel sofort speichern: Kopiere und speichere den Schlüssel, sobald er generiert wurde; er wird nur einmal angezeigt.

Novita über Endpunkte aufrufen
Ändere einfach Folgendes:
base_url:https://api.novita.ai/openaiapi_key: dein Novita-Schlüsselmodel:moonshotai/kimi-k2.5oderzai-org/glm-4.7
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="moonshotai/kimi-k2.5",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=262144,
temperature=0.7
)
print(response.choices[0].message.content)
Option B: SDK
Wenn du agentische Workflows (Routing, Übergaben, Tool-/Funktionsaufrufe) erstellst, funktioniert Novita mit OpenAI-kompatiblen SDKs mit minimalen Änderungen:
- Drop-in-kompatibel: Behalte deine bestehende Client-Logik; ändere nur base_url + model
- Orchestrierungsbereit: Einfache Implementierung von Routing (Flash-Standard → Eskalation zu GLM-4.7)
- Einrichtung: Zeige auf
https://api.novita.ai/openai, setzeNOVITA_API_KEY, wählemoonshotai/kimi-k2.5oderzai-org/glm-4.7
Option C: Drittanbieter-Plattformen
Du kannst auch von Novita gehostete Modelle über beliebte Ökosysteme ausführen:
- Agenten-Frameworks & App-Builder: Folge Novitas Schritt-für-Schritt-Integrationsanleitungen, um beliebte Tools wie Continue, AnythingLLM, LangChain und Langflow anzubinden.
- Hugging Face Hub: Novita ist als Inferenz-Anbieter auf Hugging Face gelistet, sodass du unterstützte Modelle über den Anbieter-Workflow und das Ökosystem von Hugging Face ausführen kannst.
- OpenAI-kompatible API: Die LLM-Endpunkte von Novita sind kompatibel mit dem OpenAI-API-Standard, sodass du bestehende OpenAI-Apps einfach migrieren und viele OpenAI-kompatible Tools anbinden kannst ( Cline, Cursor , Trae und Qwen Code ).
- Anthropic-kompatible API: Novita bietet auch Anthropic SDK-kompatiblen Zugriff, sodass du von Novita unterstützte Modelle in agentische Codierungs-Workflows im Stil von Claude Code integrieren kannst.
- OpenCode: Novita AI ist jetzt direkt in OpenCode als unterstützter Anbieter integriert, sodass Nutzer Novita in OpenCode ohne manuelle Konfiguration auswählen können.
Fazit
Wähle Kimi K2.5, wenn du das stärkste Gesamtleistungsprofil in diesem Benchmark-Set wünschst – insbesondere im Bereich Zuverlässigkeit/Keine Halluzinationen, plus besserem Durchsatz und schnellerer End-to-End-Generierung.
Wähle GLM-4.7, wenn du ein hochleistungsfähiges Langkontext-Flaggschiff suchst, das für agentische Codierung zu niedrigeren Ausgabe-Token-Kosten optimiert ist, und du im großen Maßstab arbeitest, wo die Stückkosten dominieren.
In beiden Fällen macht es Novita AI einfach, beide Modelle nebeneinander auszuführen – gleiche Plattform, gleiche Abrechnungsoberfläche und schnelles Modellwechseln – sodass du die Wahl anhand echter Arbeitslastdaten statt auf gut Glück treffen kannst.
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen, und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud für die Entwicklung und Skalierung bereitstellt.
Häufig gestellte Fragen
Ist Kimi K2.5 Open Source?
Kimi K2.5 ist im strengen Sinne nicht vollständig Open Source. Es handelt sich um ein Open-Weight-Modell, das von Moonshot AI unter der MIT-Lizenz veröffentlicht wurde. Die Modellgewichte und der Inferenzcode sind öffentlich für kommerzielle Nutzung, lokale Bereitstellung und Fine-Tuning verfügbar. Moonshot AI hat jedoch den vollständigen Trainingscode, den Trainingsdatensatz und die Trainingspipeline nicht veröffentlicht, sodass das Modell nicht vollständig von Grund auf reproduziert werden kann.
Was ist Kimi K2.5?
Kimi K2.5 ist ein aktualisiertes multimodales Large Language Model, das von Moonshot AI entwickelt wurde. Als Nachfolger von Kimi K2 unterstützt es multimodale Eingaben wie Text, Bilder und Video. Es bietet verbesserte Leistung in Gesprächsqualität, logischer Schlussfolgerung, Langkontext-Verarbeitung und multimodalem Verstehen und ermöglicht es Nutzern, das Modell lokal über seine offenen Gewichte bereitzustellen und anzupassen.
Was ist der Unterschied zwischen Kimi K2.5 und Kimi K2?
Kimi K2.5 ist eine aktualisierte Version von Kimi K2 mit stärkeren multimodalen und Schlussfolgerungsfähigkeiten, und es gibt die Modellgewichte offen für die lokale Bereitstellung frei. Kimi K2 bietet nur Online-API-Dienste ohne öffentliche Gewichte.



