

A codificação agente está se tornando rapidamente a interface padrão para construção de software: você descreve um objetivo, o modelo planeja, chama ferramentas, edita arquivos e itera até que a tarefa seja concluída. Dois modelos que aparecem com frequência em stacks de desenvolvimento do mundo real são o Kimi K2.5 da Moonshot AI e o GLM-4.7 da Z.AI—ambos projetados para serem fortes em contexto longo, uso de ferramentas e codificação “pronta para lançamento”.
Este post compara benchmarks, velocidade e latência e custo (preços da Novita AI)—e depois mostra como testar e implantar ambos os modelos instantaneamente na Novita AI.
Introdução Básica
Aqui está a comparação lado a lado do GLM-4.7 e do Kimi K2.5:
| Funcionalidade | GLM-4.7 | Kimi K2.5 |
| Desenvolvedor | Z.AI | Moonshot AI |
| Data de Lançamento | 22 de dezembro de 2025 | 27 de janeiro de 2026 |
| Arquitetura | Modelo MoE (Mixture-of-Experts) de 358B parâmetros | Modelo MoE de 1T de parâmetros totais (32B de parâmetros ativos por token, 384 especialistas, 8 ativados por token) com arquitetura multimodal nativa |
| Janela de Contexto | 200k de entrada / 128k de saída | 262.144 de entrada / 262.144 de saída |
| Funcionalidades de Entrada | Apenas texto | Texto, imagem, vídeo |
| Funcionalidades de Saída | Texto | Texto |
| Principais Funcionalidades | Compreensão de contexto longo, geração de código | Compreensão multimodal, colaboração de enxame de agentes (até 100 subagentes), programação visual, processamento de documentos longos, chamada de ferramentas |
Principais Diferenças
- Escala do Modelo: O Kimi K2.5 tem uma contagem total de parâmetros muito maior (1T vs. 358B) e parâmetros ativos mais altos por token, o que teoricamente permite maior capacidade de conhecimento e desempenho.
- Suporte Multimodal: O Kimi K2.5 é um modelo multimodal nativo que pode entender imagens, vídeos e realizar programação visual, enquanto o GLM-4.7 foca exclusivamente em funcionalidades de texto.
- Janela de Contexto: A janela de entrada de 256k do Kimi K2.5 é maior que a de 200k do GLM-4.7, tornando-o mais adequado para documentos ultra longos como contratos legais completos ou artigos acadêmicos.
Comparação de Benchmarks
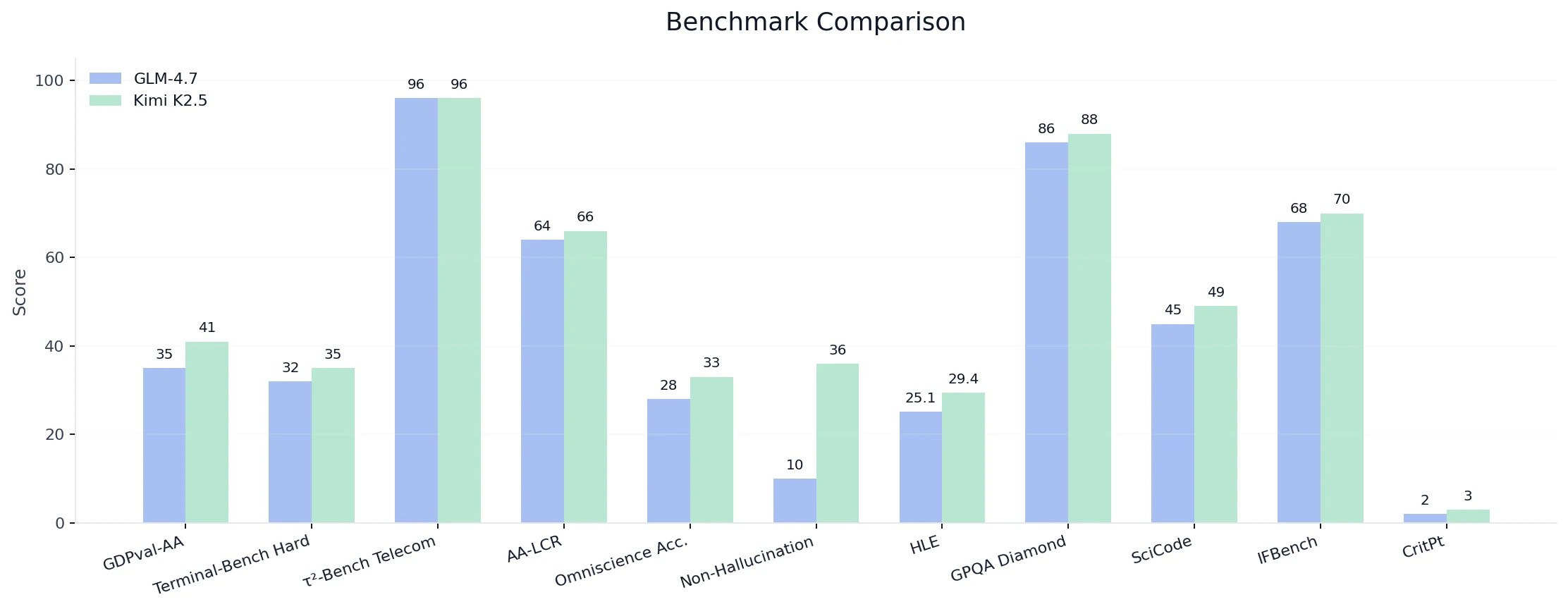
| Funcionalidade | Benchmark | Kimi K2.5 | GLM-4.7 | Resultado |
| Raciocínio | GDPval-AA (ELO-500/2000) | 41% | 35% | 6% |
| AA-LCR (Raciocínio de Contexto Longo) | 66% | 64% | 2% | |
| Exame Final da Humanidade | 29.40% | 25.10% | 4.3% | |
| GPQA Diamond (Raciocínio Científico) | 88% | 86% | 2% | |
| CritPt (Raciocínio Físico) | 3% | 2% | 1% | |
| Codificação | SciCode | 49% | 45% | 4% |
| Terminal-Bench Hard (Codificação Agente) | 35% | 32% | 3% | |
| Ferramenta / Agente | τ²-Bench Telecom (Uso de Ferramentas Agente) | 96% | 96% | 0% (empate) |
| IFBench (Seguimento de Instruções) | 70% | 68% | 2% | |
| Taxa de Não Alucinação AA-Omniscience | 36% | 10% | 26% | |
| Conhecimento | Precisão AA-Omniscience | 33% | 28% | 5% |
💡Interpretação:
- Geral: O Kimi K2.5 lidera em 10 de 11 benchmarks, com margens variando de +1% a +26%.
- Maior vantagem:
- Taxa de Não Alucinação: +26%, indicando confiabilidade substancialmente maior em ambientes baseados em agentes/ferramentas.
- Raciocínio e Codificação:
- Ganhos majoritariamente pequenos a moderados, mas consistentes (+1% a +6%), sugerindo superioridade ampla e estável, em vez de dependência de um único outlier.
- Uso de Ferramentas:
- A capacidade bruta de ferramentas (τ²-Bench) está empatada, mas a confiabilidade comportamental favorece fortemente o Kimi.
Comparação de Velocidade e Latência
O desempenho não é apenas “tokens/seg”. Para fluxos de trabalho de desenvolvimento, o que os usuários sentem é:
- Tempo até o primeiro token (o quão rápido o modelo começa a responder)
- Tempo de ponta a ponta (o quão rápido você recebe um trecho de saída utilizável)
- Throughput de saída (o quão rápido ele faz streaming assim que começa)
| Métrica | Kimi K2.5 | GLM-4.7 | O que significa |
| Velocidade de saída (tokens/seg) | 118 | 99 | O Kimi geralmente parece mais rápido em gerações longas (código, relatórios, diffs de múltiplos arquivos). |
| Tempo até o primeiro token de resposta (TTFA) | 18.3s no total (≈17.0s de “pensamento”) | 20.9s no total (≈20.2s de “pensamento”) | O Kimi começa a responder mais cedo neste teste. |
| Tempo de resposta de ponta a ponta (até 500 tokens) | 22.6s | 26.0s | O Kimi conclui uma resposta de 500 tokens mais rápido nesta execução. |
Comparação de Custos
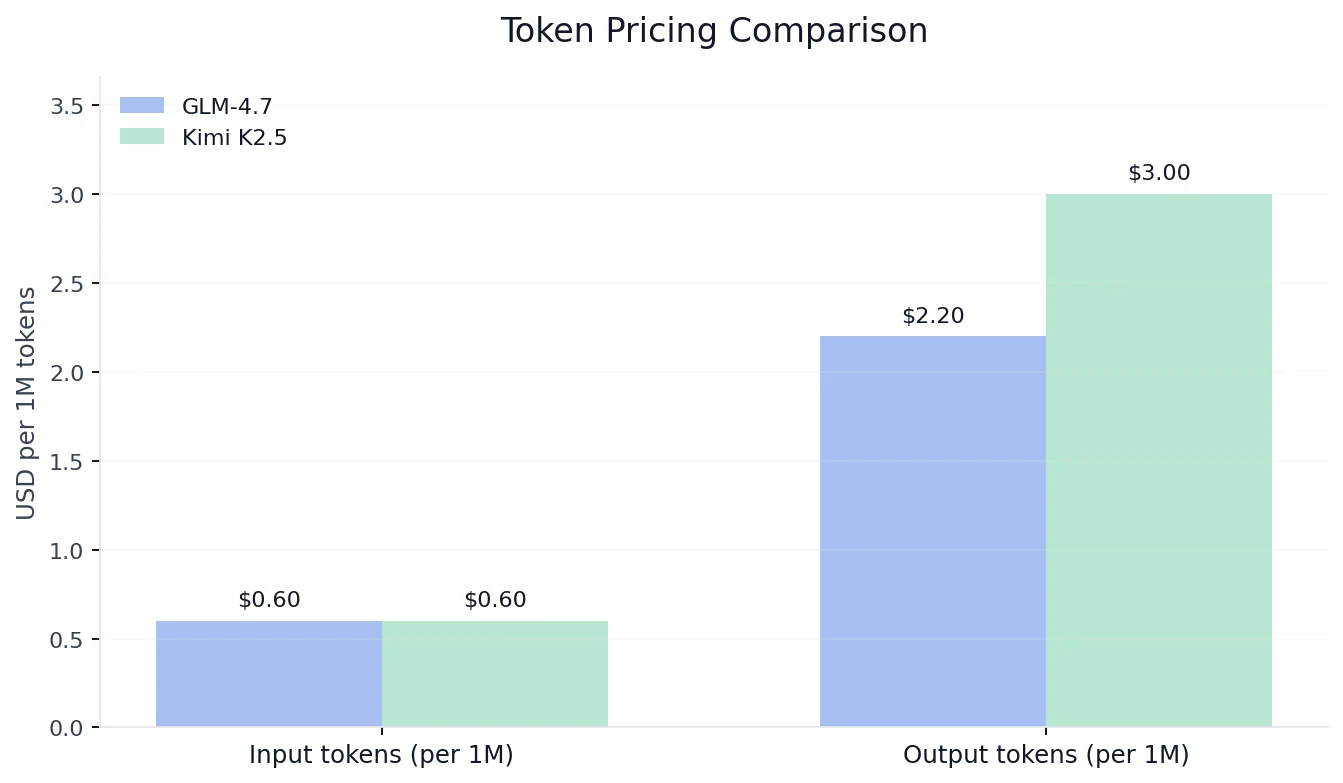
De Novita AI
Conclusão sobre custos: Se você está otimizando para custo de token de saída, o GLM-4.7 é significativamente mais barato na mesma taxa de entrada. Se você está otimizando para teto de benchmark mais alto + throughput mais rápido, o Kimi K2.5 pode justificar o preço premium.
Início Rápido: Teste Ambos os Modelos Instantaneamente no Playground
A maneira mais rápida de sentir a diferença entre o Kimi K2.5 e o GLM-4.7 é o Playground da Novita AI—sem código, sem configuração.
No Playground, você pode:
- Alternar entre modelos instantaneamente entre
moonshotai/kimi-k2.5ezai-org/glm-4.7 - Executar o exato mesmo prompt para comparar qualidade da resposta, estilo de raciocínio e velocidade de resposta
- Validar prompts prontos para produção (ex.: JSON estrito, saídas no estilo de ferramenta, restrições de formatação) antes de migrar para a API
Playground da Novita AI
Como Implantar: API, SDK e Integrações com Terceiros
Opção A: API
Como Obter Sua Chave de API na Novita AI
- Passo 1: Crie ou Faça Login na Sua Conta: Acesse
[https://novita.ai](https://novita.ai)e cadastre-se ou faça login. - Passo 2: Acesse o Gerenciamento de Chaves: Após fazer login, encontre “Chaves de API”.
- Passo 3: Crie uma Nova Chave: Clique no botão “Adicionar Nova Chave”.
- Passo 4: Salve Sua Chave Imediatamente: Copie e armazene a chave assim que ela for gerada; ela é exibida apenas uma vez.

Chamar a Novita via endpoint
Apenas altere:
base_url:https://api.novita.ai/openaiapi_key: sua chave da Novitamodel:moonshotai/kimi-k2.5ouzai-org/glm-4.7
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="moonshotai/kimi-k2.5",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=262144,
temperature=0.7
)
print(response.choices[0].message.content)
Opção B: SDK
Se você está construindo fluxos de trabalho agentes (roteamento, transferências, chamadas de ferramentas/funções), a Novita funciona com SDKs compatíveis com o OpenAI com alterações mínimas:
- Compatível para drop-in: mantenha sua lógica de cliente existente; apenas altere base_url + model
- Pronto para orquestração: fácil de implementar roteamento (padrão Flash → escalonamento para GLM-4.7)
- Configuração: aponte para
https://api.novita.ai/openai, definaNOVITA_API_KEY, selecionemoonshotai/kimi-k2.5ouzai-org/glm-4.7
Opção C: Plataformas de Terceiros
Você também pode executar modelos hospedados na Novita por meio de ecossistemas populares:
- Frameworks de agentes e construtores de apps: Siga os guias de integração passo a passo da Novita para conectar-se a ferramentas populares como Continue, AnythingLLM, LangChain e Langflow.
- Hugging Face Hub: A Novita está listada como um Provedor de Inferência no Hugging Face, então você pode executar modelos suportados por meio do fluxo de trabalho e ecossistema de provedores do Hugging Face.
- API compatível com o OpenAI: Os endpoints de LLM da Novita são compatíveis com o padrão de API do OpenAI, facilitando a migração de apps existentes no estilo OpenAI e a conexão com muitas ferramentas compatíveis com o OpenAI ( Cline, Cursor, Trae e Qwen Code ) .
- API compatível com o Anthropic: A Novita também fornece acesso compatível com o SDK do Anthropic para que você possa integrar modelos suportados pela Novita em fluxos de trabalho de codificação agente no estilo Claude Code.
- OpenCode: A Novita AI agora está integrada diretamente ao OpenCode como um provedor suportado, então os usuários podem selecionar a Novita no OpenCode sem configuração manual.
Conclusão
Escolha o Kimi K2.5 se você quer o perfil de capacidade geral mais forte neste conjunto de benchmarks—especialmente por confiabilidade/não alucinação, além de throughput melhor e geração de ponta a ponta mais rápida.
Escolha o GLM-4.7 se você quer um modelo principal de contexto longo altamente capaz, otimizado para codificação agente a um custo menor por token de saída, e você opera em escala onde a economia unitária domina.
De qualquer forma, a Novita AI facilita a execução de ambos os modelos lado a lado—mesma plataforma, mesma superfície de faturamento e troca rápida de modelos—para que você possa fazer a escolha com dados reais de carga de trabalho, em vez de suposições.
A Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma maneira fácil de implantar modelos de IA usando nossa API simples, além de fornecer uma nuvem de GPU acessível e confiável para construção e escalonamento.
Perguntas Frequentes
O Kimi K2.5 é open source?
O Kimi K2.5 não é totalmente open source no sentido estrito. É um modelo de pesos abertos lançado pela Moonshot AI sob a licença MIT. Os pesos do modelo e o código de inferência estão disponíveis publicamente para uso comercial, implantação local e ajuste fino. No entanto, a Moonshot AI não lançou seu código de treinamento completo, conjunto de dados de treinamento ou pipeline de treinamento, então o modelo não pode ser totalmente reproduzido do zero.
O que é o Kimi K2.5?
O Kimi K2.5 é um modelo de linguagem grande multimodal atualizado desenvolvido pela Moonshot AI. Como sucessor do Kimi K2, ele suporta entradas multimodais incluindo texto, imagens e vídeo. Ele oferece desempenho aprimorado em qualidade de conversação, raciocínio lógico, processamento de contexto longo e compreensão multimodal, e permite que os usuários implantem e personalizem o modelo localmente por meio de seus pesos abertos.
Qual a diferença entre o Kimi K2.5 e o Kimi K2?
O Kimi K2.5 é uma versão atualizada do Kimi K2 com habilidades multimodais e de raciocínio mais fortes, e libera abertamente os pesos do modelo para implantação local. O Kimi K2 fornece apenas serviços de API online sem pesos públicos.



