

- What are the Key Improvements in Deepseek V3.1 over R1?
- Deepseek V3.1 VS Deepseek R1: Release Notes
- Deepseek V3.1 VS Deepseek R1: Architecture
- Deepseek V3.1 VS Deepseek R1: Benchmark
- Deepseek V3.1 VS Deepseek R1: Speed
- Deepseek V3.1 VS Deepseek R1: System Requirements
- Deepseek V3.1 VS Deepseek R1: Applications
- How to Access Deepseek V3.1 and R1 Through Cheap and Stable API?
When DeepSeek introduced V3.1 in August 2025, many expected a new generation: “Why not R2?” The answer lies in its strategic shift from being a pure reasoning engine to becoming a flexible, agent-ready LLM. While DeepSeek R1 was a state-of-the-art reasoning model powered by reinforcement learning, V3.1 represents a different evolution: one that blends fast interaction, deep reasoning, and tool-use.
This article explores the key differences between DeepSeek V3.1 and R1, not just from a benchmark or architecture level—but from the perspective of why DeepSeek is pivoting toward hybrid inference, real-world agent use cases, and efficiency.
What are the Key Improvements in Deepseek V3.1 over R1?
| Dimension | DeepSeek V3.1 | R1 |
|---|---|---|
| Mode Support | Hybrid Thinking Mode. Supports switching via chat template: • <think> enables chain-of-thought reasoning• </think> switches to direct response mode | Reasoning-only mode. Primarily chain-of-thought reasoning with fixed mode |
| Tool/Agent Capability | Stronger Agent Skills. • Post-training enhances tool use • Supports structured tool calls • Specialized code/search agent templates | Initially lacked support. R1-0528 update later added JSON output and function calling |
| Inference Efficiency | Faster responses. • DeepThink mode ≈ R1 answer quality • Non-thinking mode is faster, suited for latency-sensitive applications | Slower but stable. • Primarily reasoning mode, best for accuracy-focused tasks |
Deepseek V3.1 VS Deepseek R1: Release Notes
DeepSeek R1 (January 2025)
- Inaugural RL-powered reasoning model
- Performance Parity: Matches OpenAI’s o1 (GPT-4o equivalent) on math/coding/reasoning benchmarks
- Dense Model SOTA: Six distilled smaller models (1.5B–70B) achieving state-of-the-art results
- Innovative Approach: Pioneered “large-scale RL in post-training” methodology
DeepSeek R1–0528 (May 2025)
- Interim update with quality & usability enhancements
- Benchmark Improvements: Enhanced performance metrics
- Frontend Upgrades: Improved user interaction experience
- Hallucination Reduction: Better factual consistency
- New API Features: Support for JSON output and function calling
DeepSeek V3.1 (August 2025)
- First step toward the agent era
- Hybrid Inference: One model supporting dual modes (Think & Non-Think)
- Faster Thinking: V3.1-Think achieves results quicker than R1–0528
- Enhanced Agent Skills: Post-training improvements for tool use and multi-step tasks
- Context Support: Maintains 128K token context across all modes
Deepseek V3.1 VS Deepseek R1: Architecture

Deepseek V3.1 VS Deepseek R1: Benchmark
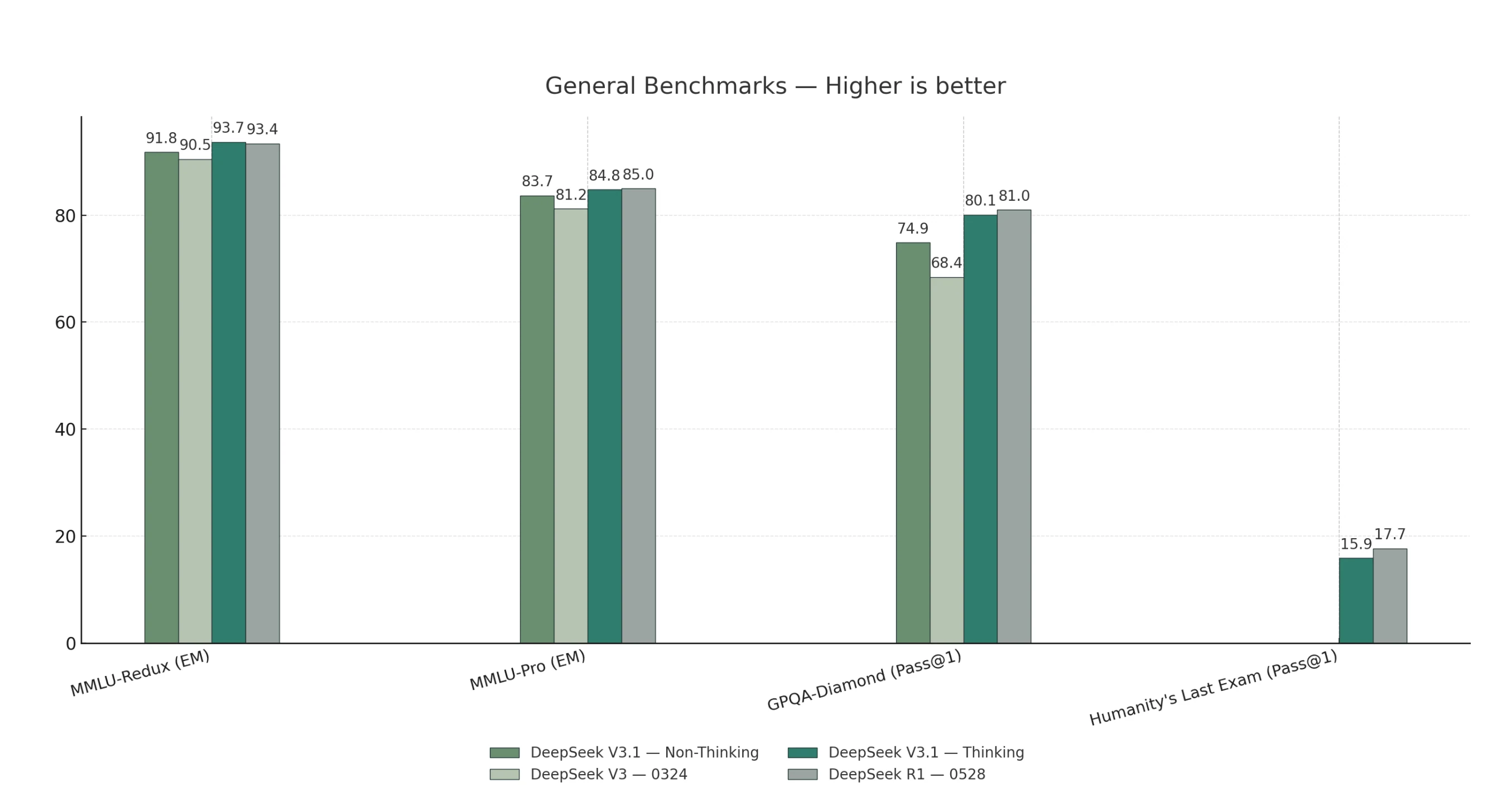
General Benchmark
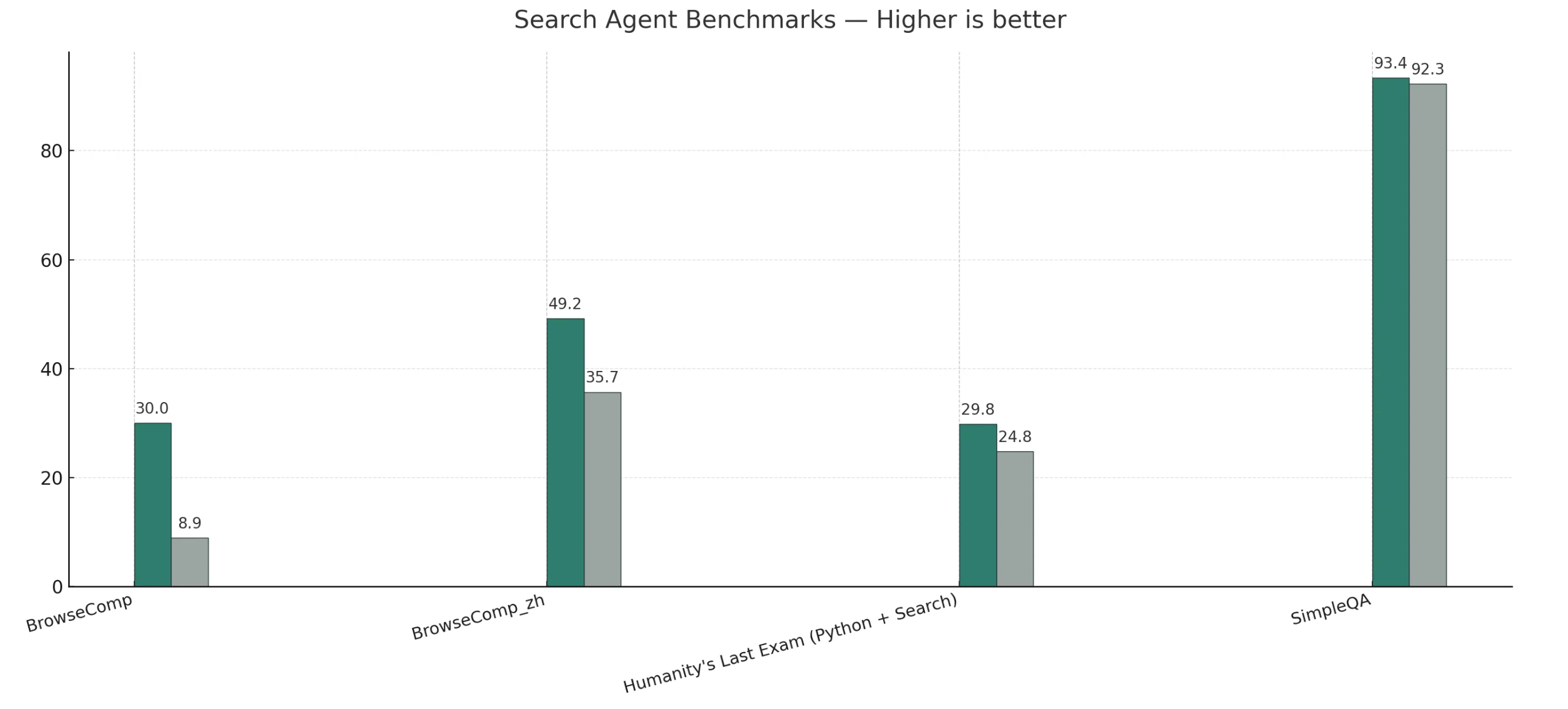
Search Agent Benchmark
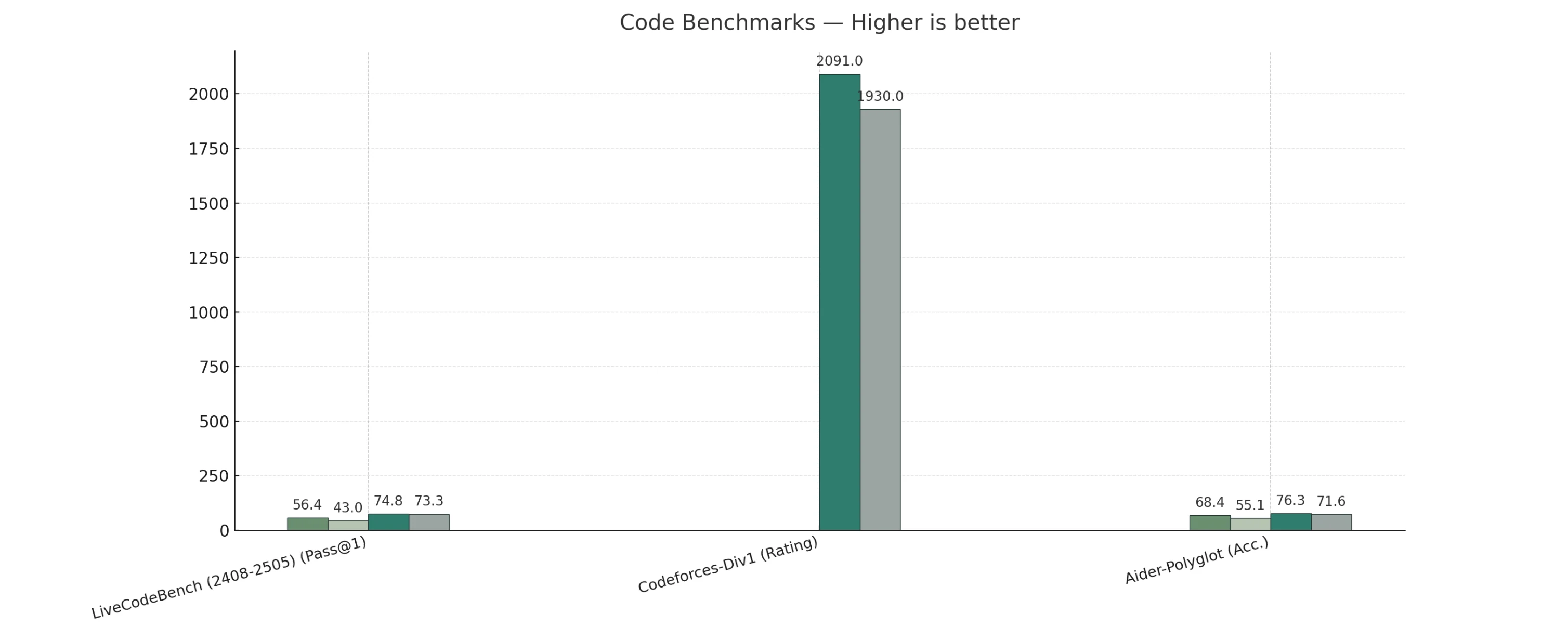
Code Benchmark
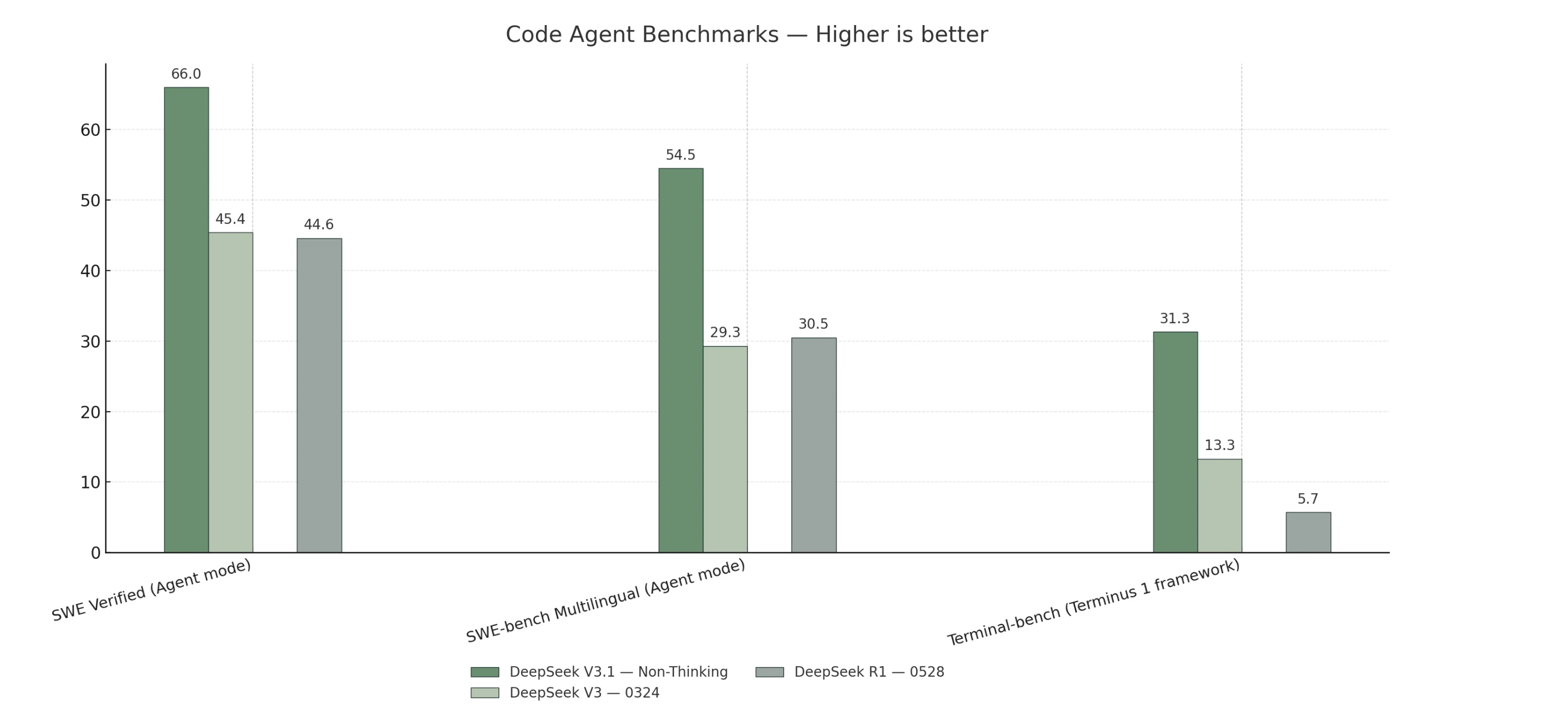
Code Agent Benchmark
Math Benchmark
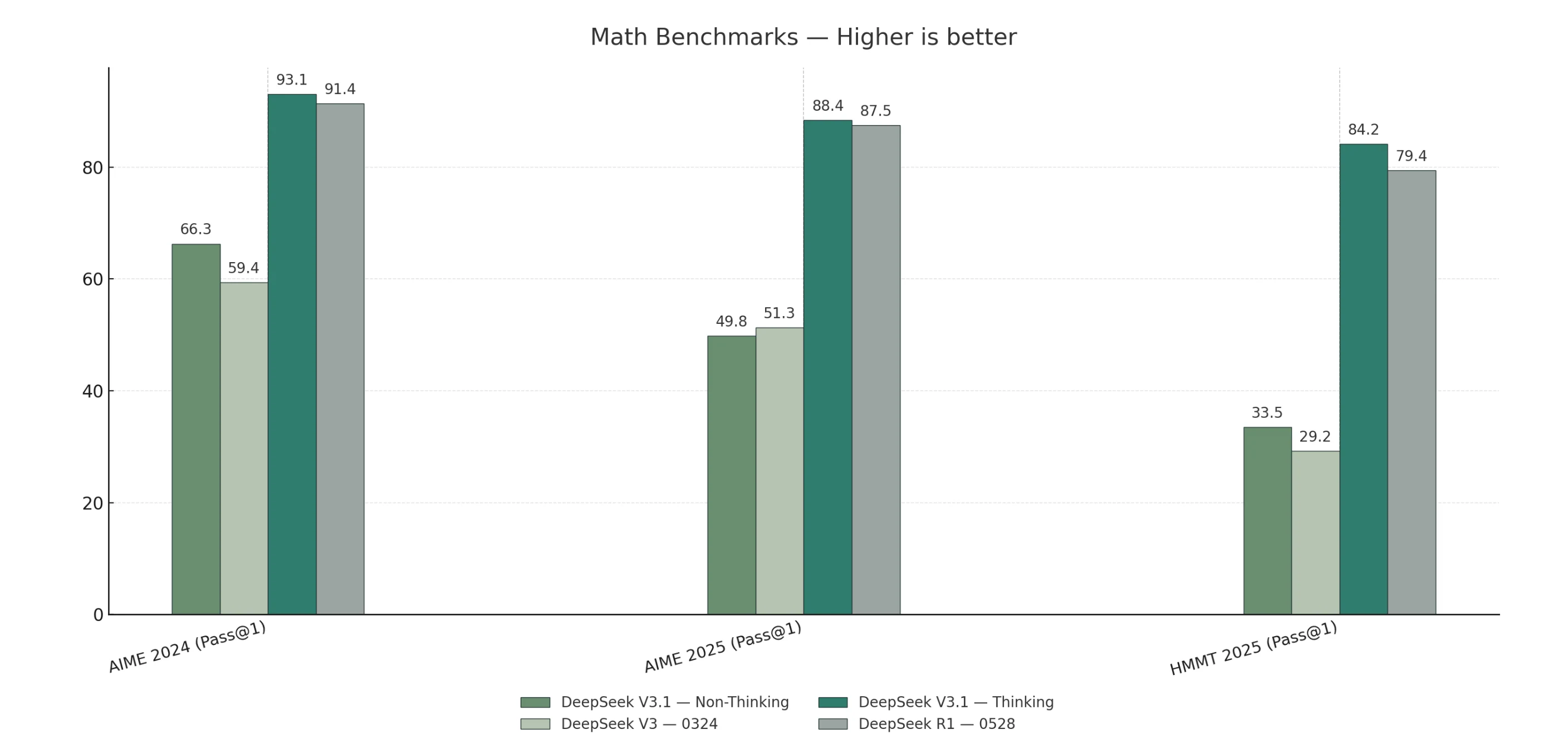
V3.1-Thinking outperforms or matches R1-0528 across general, coding, math, and search tasks.
V3.1-Non-Thinking leads on code-agent benchmarks, while R1-0528 shows only a slight advantage on long-form humanities reasoning.
Deepseek V3.1 VS Deepseek R1: Speed
| Metric | DeepSeek V3.1 (Non-thinking) | DeepSeek R1–0528 | DeepSeek V3.1 (Reasoning) |
|---|---|---|---|
| Output Speed (tokens/s, higher is better) | 20 | 20 | 20 |
| Latency – Time to First Answer Token (s) | 2.9 | 102.3 | 103.9 |
| End-to-End Response Time (500 tokens) (s, lower is better) | 28.1 (25.2 input + 2.9 output) | 127.1 (99.4 input + 24.9 output + 2.8 think est.) | 129.2 (101 input + 25.2 output + 3.0 think est.) |
Use Free Playground to Test Deepseek V3.1 Now!
The value of V3.1’s Hybrid Thinking mode lies in flexibility:
- Non-thinking mode: Lowest latency (only 2.9s to first token, 28.1s for a full 500-token response). Best suited for latency-sensitive applications such as chat or interactive APIs.
- Reasoning mode: Comparable performance to R1–0528, maintaining strong chain-of-thought accuracy. Best suited for complex reasoning tasks.
- Overall optimization: The improvement is not in raw output speed but in the ability to bypass long “thinking delays.” This allows V3.1 to balance both fast interaction and deep reasoning depending on the task.
Deepseek V3.1 VS Deepseek R1: System Requirements
| Model | #Total Params | #Activated Params | Context Length |
|---|---|---|---|
| DeepSeek-V3.1-Base | 671B | 37B | 128K |
| DeepSeek-V3.1 | 671B | 37B | 128K |
| DeepSeek-R1-0528 | 671B | 37B | 128K |
| DeepSeek-R1 | 671B | 37B | 128K |
The full 671B MoE model requires on the order of 1–1.5 TB of GPU RAM to run at full precision.
And to take advantage of V3.1’s FP8 optimizations, GPUs with FP8 support (NVIDIA H100, H200, Blackwell series) are recommended.
You can use Novita AI’s spot billing to get H200 SXM for as low as $1.63/hour, or H100 SXM for just $0.90/hour.
Deepseek V3.1 VS Deepseek R1: Applications
| Task Type | Recommended Model | Recommended Mode |
|---|---|---|
| API Tool Calling | DeepSeek V3.1 | Non-Thinking Mode |
| Multi-turn Agent Execution | DeepSeek V3.1 | Non-Thinking Mode |
| Math / Logic / Programming Reasoning | DeepSeek V3.1 or R1 | Thinking Mode |
| Fast User Interaction | DeepSeek V3.1 | Non-Thinking Mode |
| Long Document Reading & Summarization | DeepSeek V3.1 | Thinking Mode (128K Context) |
In summary, R1 is a cutting-edge reasoning engine, best for tasks emphasizing logic and calculation, while V3.1 is a more versatile, agent-capable model that can serve both general chat and sophisticated tool-based applications.
How to Access Deepseek V3.1 and R1 Through Cheap and Stable API?
Novita AI integrates a wide range of DeepSeek models, including V3.1, R1 0528, V3 Turbo, R1 Turbo, and several lightweight distillations like Qwen 14B/32B and LLaMA 70B—covering everything from long-context reasoning to cost-efficient inference.
What sets Novita apart is its in-house optimized DeepSeek R1 Turbo, featuring up to 3× faster throughput and a limited-time 60% discount, making it an ideal choice for developers seeking both performance and affordability.
| Metric | Deepseek V3.1 Value |
|---|---|
| Input Price | $0.55 |
| Output Price | $1.66 |
| Latency | 3.00s |
| Throughput | 48.28 tps |
| Uptime | 🟩🟩🟩 |
Step 1: Log In and Access the Model Library
Log in to your account and click on the Model Library button.

Step 2: Choose Your Model
Browse through the available options and select the model that suits your needs.
Step 3: Start Your Free Trial
Begin your free trial to explore the capabilities of the selected model.
Step 4: Get Your API Key
To authenticate with the API, we will provide you with a new API key. Entering the “Settings“ page, you can copy the API key as indicated in the image.

Step 5: Install the API
Install API using the package manager specific to your programming language.
After installation, import the necessary libraries into your development environment. Initialize the API with your API key to start interacting with Novita AI LLM. This is an example of using chat completions API for python users.
from openai import OpenAI
base_url = "https://api.novita.ai/openai"
api_key = "<Your API Key>"
model = "deepseek/deepseek-v3.1"
client = OpenAI(
base_url=base_url,
api_key=api_key,
)
stream = True # or False
max_tokens = 1000
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
extra_body={
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
DeepSeek R1 remains a reasoning benchmark—it pioneered RL-based post-training and rivaled GPT-4o on math and logic tasks. But it’s slow, rigid, and wasn’t built for agents.
DeepSeek V3.1, however, is designed for the real-world deployment era:
- 🔁 Switch between reasoning and speed.
- 🛠️ Call APIs, agents, and tools natively.
- 🚀 Infer faster, pay less, and integrate smarter.
Instead of naming it R2, DeepSeek chose to signal a new direction with V3.1: it’s not just smarter—it’s more usable.
For developers, researchers, and businesses, V3.1 is a practical, flexible, and production-ready alternative, while R1 remains an academic benchmark.
Frequently Asked Questions
Is V3.1 just a faster version of R1?
Not exactly. While V3.1-Think matches R1 in reasoning quality, its non-thinking mode provides ultra-low latency. More importantly, V3.1 supports agentic tasks and structured tool use, which R1 does not (natively).
Why did DeepSeek skip “R2” in naming?
Because V3.1 isn’t just a new reasoning model—it’s a new hybrid paradigm. The naming signals that DeepSeek is focusing on agent-era readiness, not just better logic.
How can I try DeepSeek V3.1 easily?
You can use Novita AI to test DeepSeek V3.1 instantly in their free playground. Novita offers:
✅ Full support for DeepSeek V3.1, R1, and Turbo models
💸 H100 from $0.90/hr, H200 from $1.63/hr (spot pricing)
Novita AI is the All-in-one cloud platform that empowers your AI ambitions. Integrated APIs, serverless, GPU Instance — the cost-effective tools you need. Eliminate infrastructure, start free, and make your AI vision a reality.
Recommend Reading
Qwen 3 in RAG Pipelines: All-in-One LLM, Embedding, and Reranking Models
Trae or Claude Code: Which Is More Suitable to Use with Kimi K2?



