

Die KI-gestützte Softwareentwicklung bewegt sich rasant voran, angetrieben von zwei großen Trends: leistungsstarken Open-Source-Modellen und vollständig integrierten KI-Entwicklungsumgebungen. GPT‑OSS ist die Open-Weight-Modellreihe von OpenAI, bekannt für starkes Reasoning, agentenähnliche Fähigkeiten und tiefe Anpassungsmöglichkeiten. TRAE von ByteDance ist eine KI-IDE, die als vollständiger „KI-Ingenieur“ fungiert und Software eigenständig erstellen kann.
Die Frage ist: Was passiert, wenn man die kontrollierbare Reasoning-Fähigkeit von GPT‑OSS mit dem werkzeugreichen, automatisierten Entwicklungsframework von TRAE kombiniert? Zusammen ergeben sie einen Workflow, der sowohl automatisiert als auch genau auf Ihre Bedürfnisse zugeschnitten ist. Diese Anleitung erklärt, wie Sie sie verbinden und ihr volles Potenzial ausschöpfen.
Was ist Trae?
TRAE ist auch der Name einer KI-gestützten integrierten Entwicklungsumgebung (IDE), die von ByteDance entwickelt wurde. Sie soll als „KI-Ingenieur“ fungieren, der Softwarelösungen eigenständig erstellen kann, indem er komplexe Aufgaben versteht und ausführt. TRAE zielt darauf ab, den Entwicklungsprozess zu optimieren, indem Benutzer Aufgaben an die KI delegieren können.
Wichtige Funktionen von Trae
Erweiterte Tool-Integration & -Fähigkeiten (Model Context Protocol – MCP)
- Externe Tool-Integration: TRAE integriert verschiedene externe Tools, sodass KI-Agenten diese für eine effektivere Aufgabenerfüllung nutzen können.
- MCP-Unterstützung: Es unterstützt das Model Context Protocol (MCP), einen offenen Standard zur Verbindung von KI-Anwendungen mit externen Datenquellen und Tools. Dies fungiert wie ein universeller „USB-C“-Anschluss für KI und löst die Herausforderung, KI-Modelle mit isolierten Daten zu verbinden.
- Erweiterte KI-Fähigkeiten: Über MCP können Agenten auf externe Ressourcen wie Google Drive, Slack, GitHub und Datenbanken zugreifen, um komplexe Aufgaben besser zu verstehen und zu erledigen.
Tieferes kontextuelles Verständnis & präzise Steuerung
- Tiefgehendes Verständnis des Entwicklungskontexts: TRAE versteht Ihren Entwicklungskontext eingehend, einschließlich Code-Repositorys, Online-Suchergebnissen und freigegebenen Dokumenten.
- Präzise Verhaltensanpassung: Sie können Regeln anpassen, um das Verhalten der KI an Ihren Workflow anzupassen und sicherzustellen, dass sie Aufgaben genau nach Ihren Vorstellungen ausführt.
- Multimodale Interaktion: Unterstützt Bild-Uploads (z. B. Design-Mockups, Fehler-Screenshots), um Anforderungen zu beschreiben und der KI die Generierung präziserer Code zu ermöglichen.
CUE: Intelligente Vorhersage & Bearbeitung mit einem Klick
- Vorhersage der nächsten Bearbeitung: Die CUE-Funktion (Context Understanding Engine) versteht Ihre Absicht und sagt Ihren nächsten Schritt voraus, indem sie Ihr Bearbeitungsverhalten analysiert.
- Navigation & Anwendung per Tastendruck: Drücken Sie einfach die
Tab-Taste, um zum nächsten vorgeschlagenen Änderung zu springen oder intelligente Vorschläge über mehrere Zeilen hinweg anzuwenden. - Kontinuierliche Optimierung: Die Funktion wird kontinuierlich auf bessere Leistung und Reaktionsfähigkeit optimiert und bietet ein flüssigeres Erlebnis bei Code-Änderung, -Generierung und Fehlerbehebung.
Umfassende IDE-Funktionen & KI-Assistenz
- Zwei Entwicklungsmodi: Bietet den IDE-Modus für einen traditionellen, benutzergesteuerten Workflow und den SOLO-Modus, in dem die KI die Entwicklung von der Anforderungsanalyse bis zur Auslieferung vollständig automatisiert führt.
- Vollwertige IDE: Bietet Standard-IDE-Funktionen wie Code-Editor, Projektverwaltung und Versionskontrolle.
- KI-Programmierassistenz: Verfügt über verschiedene KI-gestützte Hilfen, darunter intelligente Code-Vervollständigung, Refactoring, Chat-basierte Q&A und Projekterstellung aus natürlicher Sprache.
- Integrierte Web-Vorschau: Unterstützt die direkte Vorschau von Webseiten innerhalb der IDE für eine einfachere Frontend-Entwicklung und Fehlerbehebung.
Was ist Trae Solo?
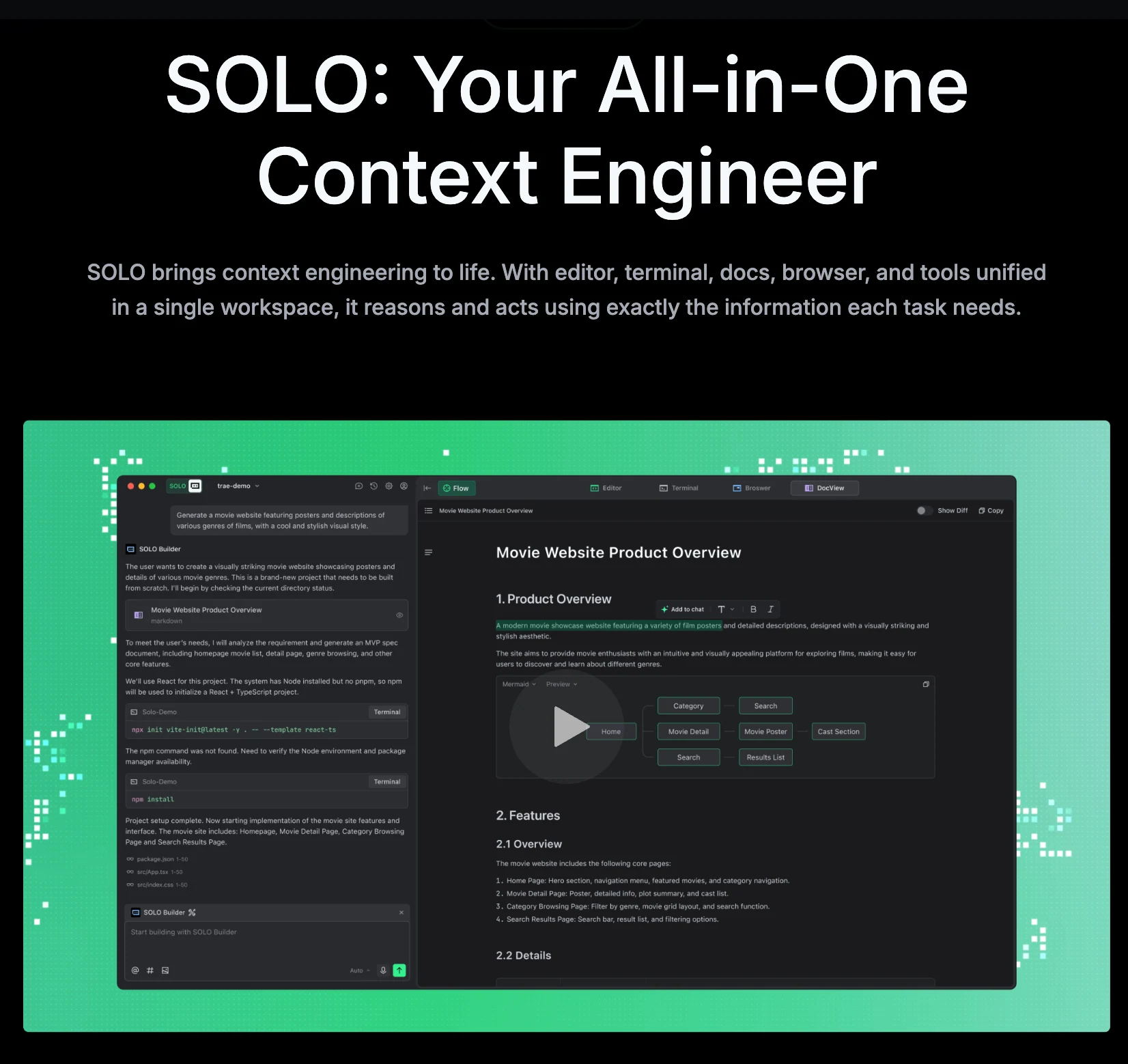
- Einheitlicher Arbeitsbereich & KI-Tool-Center:
Der SOLO-Modus integriert alle notwendigen Entwicklungstools – IDE, Browser, Terminal und Dokumente – direkt in die KI. Dadurch kann die KI präzise auf Basis der spezifischen Anforderungen jeder Aufgabe argumentieren und handeln und die Lücke zwischen Idee und Umsetzung nahtlos schließen. - KI-gesteuerte, durchgängige Entwicklung:
Sie geben lediglich die Anforderungen vor, und SOLO übernimmt autonom den gesamten Entwicklungslebenszyklus, einschließlich:- Anforderungsanalyse
- Prototyping
- Frontend-Entwicklung
- Backend-Entwicklung
- Debugging & Optimierung
- Build & Deployment
- Einheitliche Überwachungsansicht:
Benutzer können mit der KI chatten und alle Entwicklungsaktivitäten aus einer einzigen, einheitlichen Ansicht überwachen. Die „Erweiterte Ansicht“ bietet eine detaillierte Einsicht in alle Echtzeit-Ausführungsdetails. - Multimodale Interaktion: „Sprechen“ Sie Ihre Anforderungen:
Der SOLO-Modus unterstützt Spracheingabe, sodass Sie mit TRAE so natürlich interagieren können wie mit einem menschlichen Teammitglied. Die Ausgabe der KI beschränkt sich nicht auf Code; eine erweiterbare dynamische Ansicht auf der rechten Seite bietet visuelles und intuitives Feedback. - Der Kontext-Ingenieur:
Der SOLO-Modus ist als ultimativer „Kontext-Ingenieur“ konzipiert, der den gesamten Umfang Ihrer Arbeit versteht, um sicherzustellen, dass seine Aktionen und Ausgaben auf den umfassendsten und genauesten verfügbaren Informationen basieren.
Zusammenfassend ist das Ziel des TRAE SOLO-Modus die „KI, die komplette Software ausliefert“. Es befähigt Entwickler, reale Software schneller zu bauen und zu veröffentlichen – durch einen einfachen „Talk. Think. Ship.“-Prozess.
Was ist GPT OSS?
GPT-OSS (Open-Source Series) ist eine Familie leistungsstarker Open-Weight-Sprachmodelle von OpenAI, die für die kommerzielle Nutzung frei verfügbar sind und lokal auf Consumer-Hardware ausgeführt werden können. Die Serie umfasst zwei Hauptmodelle mit 20 Milliarden bzw. 120 Milliarden Parametern, die für starkes Reasoning, Tool-Nutzung und Effizienz optimiert sind – ein bedeutender Schritt von OpenAI hin zu mehr Transparenz in der KI-Community. Diese Modelle ermöglichen es Entwicklern und Forschern, sie für eigene Zwecke zu verfeinern und dabei die volle Kontrolle über ihre Daten und Infrastruktur zu behalten – sie schließen die Lücke zwischen geschlossenen, proprietären Systemen und Open-Source-KI.
| Modell | Layers | Gesamtparameter | Aktive Parameter pro Token | Gesamtexperten | Aktive Experten pro Token | Kontextlänge | VRAM-Anforderung (Single GPU) |
| gpt-oss-120b | 36 | 117B | 5.1B | 128 | 4 | 128k | 80GB |
| gpt-oss-20b | 24 | 21B | 3.6B | 32 | 4 | 128k | 16GB |
Warum GPT OSS für KI-Code wählen?
Format anpassen: Harmony
GPT‑OSS-Modelle verwenden ein spezielles Gesprächsformat namens Harmony. Dieses Format organisiert Nachrichten in klare Rollen – system, user und assistant – und ermöglicht Ihnen die Steuerung, wie das Modell denkt und antwortet. Mit Harmony können Sie die Reasoning-Tiefe (niedrig, mittel, hoch) anpassen, entscheiden, ob der Denkprozess angezeigt oder ausgeblendet wird, und das Modell veranlassen, Funktionen auf stabile, strukturierte Weise aufzurufen. Viele andere Open-Source-Modelle haben diese Steuerungsmöglichkeiten nicht eingebaut, aber GPT‑OSS versteht sie nativ, weil es darauf trainiert wurde, Harmony-Anweisungen zu befolgen. Dies erleichtert die Erzielung konsistenter, zuverlässiger und toolfreundlicher Ausgaben.
Was Harmony steuern kann
Das Harmony-Format ermöglicht es Ihnen, mehrere wichtige Verhaltensparameter für GPT‑OSS-Modelle anzupassen:
| Parameter | Beschreibung | Beispiel |
|---|---|---|
| Reasoning-Tiefe | Steuert, wie viel schrittweises Denken das Modell durchführt. | "Reasoning: low", "Reasoning: medium", "Reasoning: high" |
| Funktionsaufruf | Native Unterstützung für OpenAI-ähnliche function_call / tool_calls JSON-Ausgabe. |
"Always call function weather_api when asked about weather" |
| Reasoning-Sichtbarkeit | Zeigt die vollständige Gedankenkette in thinking-Tags an oder blendet sie aus. |
"Show reasoning" / "Hide reasoning" |
| Ausgabeformat-Regeln | Erzwingt strukturierte Ausgaben wie JSON, Markdown usw. | "Output in JSON format" |
Ein Beispiel für eine Harmony-Anfrage
{
"messages": [
{
"role": "system",
"content": "Reasoning: medium; Hide reasoning; Output in JSON format"
},
{
"role": "user",
"content": "Explain how quicksort works."
}
]
}
Vorteile bei der Verwendung von Harmony mit Tools wie Trae
Bei der Integration mit Code-Generierungs-, Debugging- und Ausführungsplattformen wie Trae bietet das Harmony-Format mehrere praktische Vorteile:
-
Stabile Strukturierte Ausgabe
- Harmony stellt sicher, dass die Ausgabe des Modells einem vorhersagbaren JSON- oder Codeblock-Format folgt.
- Trae kann dies direkt parsen, ohne fragile Regex oder Nachbearbeitung.
-
Kontrolle der Reasoning-Tiefe
- Verwenden Sie niedriges Reasoning für schnelles Prototyping oder einfachen Code.
- Verwenden Sie hohes Reasoning für komplexe Algorithmen, bei denen Korrektheit entscheidend ist.
- Spart GPU/CPU-Ressourcen, indem die Reasoning-Kosten an die Aufgabenkomplexität angepasst werden.
-
Reasoning-Sichtbarkeit umschalten
- Zeigen Sie
thinking-Reasoning für Debugging und Lernzwecke an. - Blenden Sie Reasoning in der Produktion aus, um Tokens zu reduzieren und interne Logik nicht preiszugeben.
- Zeigen Sie
-
Klares Kontextmanagement über mehrere Turns hinweg
system-Regeln bleiben über Turns hinweg bestehen und gewährleisten einen konsistenten Code-Stil und konsistente Ausführungsregeln.- Einfach zu iterieren: Ändern Sie Benutzeranweisungen, ohne globale Einstellungen zu verlieren.
-
Nahtlose API-Integration
- Harmony imitiert die OpenAI Responses API, sodass jede Toolchain oder IDE-Erweiterung, die mit OpenAI kompatibel ist, mit minimalen Änderungen mit GPT‑OSS arbeiten kann.
GPT OSS Tool-Nutzung
GPT‑OSS-Modelle sind darauf trainiert, externe Tools nativ als Teil ihres Reasoning-Prozesses zu nutzen, mit integrierter Unterstützung für Browsing, Python-Ausführung und File Patching. Diese Tools werden aktiviert, indem sie in der system-Nachricht eines Harmony-formatierten Prompts definiert werden.
1. Browser-Tool
-
Zweck: Im Web suchen, Seiten öffnen und Text auf Seiten finden.
-
Methoden:
search– nach Schlüsselbegriffen suchen.open– eine bestimmte Seite öffnen.find– Inhalt auf einer Seite lokalisieren.
-
Funktionen:
- Scrollbares Textfenster zur Verwaltung der Kontextgröße.
- Caching für schnellere Wiederbesuche derselben Seite.
- Trainiert, um Quellen in Antworten zu zitieren.
-
Verwendung: Fügen Sie die Browser-Tool-Definition über
.with_browser()oder.with_tools()imsystem-Prompt hinzu. -
Hinweis: Die Referenzimplementierung dient nur zu Bildungszwecken – verwenden Sie in der Produktion Ihr eigenes Backend.
2. Python-Tool
-
Zweck: Berechnungen durchführen oder kleine Programme als Teil der Gedankenkette ausführen.
-
Funktionen:
- Trainiert mit einem zustandsbehafteten Python-Tool für mehrschrittiges Reasoning.
- Referenzimplementierung verwendet einen zustandslosen Modus.
- Kann Standard-Tool-Beschreibungen in
openai-harmonyüberschreiben.
-
Verwendung: Fügen Sie es über
.with_python()oder.with_tools()imsystem-Prompt hinzu. -
Sicherheitswarnung: Referenzcode wird in einem permissiven Docker-Container ausgeführt – fügen Sie in der Produktion eigene Einschränkungen hinzu.
3. Apply Patch Tool
- Zweck: Lokale Dateien erstellen, aktualisieren oder löschen.
- Anwendungsfall: Code oder Projektdateien als Teil einer automatisierten Entwicklungsschleife ändern.
Wie verwendet man GPT OSS in Trae?
Voraussetzungen: API-Schlüssel besorgen
Novita AI bietet GPT-OSS 120B
APIs mit 131K Kontext zu Kosten von $0,1/Input und $0,5/Output. Novita AI bietet auch GPT-OSS 20B mit 131 Kontext zu Kosten von $0,05/Input und $0,2/Output und unterstützt damit die Maximierung des Code-Agenten-Potenzials von GPT OSS.Novita AI
Schritt 1: Einloggen und auf die Modellbibliothek zugreifen
Loggen Sie sich in Ihr Konto ein und klicken Sie auf die Schaltfläche Model Library.

Schritt 2: Wählen Sie Ihr Modell
Durchsuchen Sie die verfügbaren Optionen und wählen Sie das Modell, das Ihren Anforderungen entspricht.

Schritt 3: Starten Sie Ihre kostenlose Testphase
Beginnen Sie Ihre kostenlose Testphase, um die Fähigkeiten des ausgewählten Modells zu erkunden.

Schritt 4: API-Schlüssel abrufen
Um sich bei der API zu authentifizieren, stellen wir Ihnen einen neuen API-Schlüssel zur Verfügung. Rufen Sie die Seite „Settings“ auf und kopieren Sie den API-Schlüssel, wie im Bild gezeigt.

Schritt 5: API installieren
Installieren Sie die API mit dem für Ihre Programmiersprache spezifischen Paketmanager.
Importieren Sie nach der Installation die erforderlichen Bibliotheken in Ihre Entwicklungsumgebung. Initialisieren Sie die API mit Ihrem API-Schlüssel, um mit Novita AI LLM zu interagieren. Dies ist ein Beispiel für die Verwendung der Chat Completions API für Python-Benutzer.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="",
)
model = "openai/gpt-oss-120b"
stream = True # or False
max_tokens = 65536
system_content = ""Sei ein hilfreicher Assistent""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
GPT‑OSS in TRAE nutzen
Schritt 1: Trae öffnen und auf Modelle zugreifen
Starten Sie die Trae-App. Klicken Sie oben rechts auf Toggle AI Side Bar, um die AI Side Bar zu öffnen. Gehen Sie dann zu AI Management und wählen Sie Models.

Schritt 2: Ein benutzerdefiniertes Modell hinzufügen und Novita als Anbieter auswählen und Modelle auswählen
Klicken Sie auf die Schaltfläche Add Model, um einen benutzerdefinierten Modelleintrag zu erstellen. Wählen Sie im Dialogfeld „Modell hinzufügen“ aus dem Dropdown-Menü Provider = Novita aus.
Wählen Sie im Dropdown-Menü „Modell“ Ihr gewünschtes Modell (DeepSeek-R1-0528, Kimi K2, GLM 4.5, DeepSeek-V3-0324 oder MiniMax-M1-80k). Wenn das genaue Modell nicht aufgeführt ist, geben Sie einfach die Modell-ID ein, die Sie aus der Novita-Bibliothek notiert haben. Wählen Sie die korrekte Variante des gewünschten Modells.


Schritt 3: API-Schlüssel eingeben
Kopieren Sie den Novita AI API-Schlüssel aus Ihrer Novita-Konsole und fügen Sie ihn in das Feld „API Key“ in Trae ein.
Novita AI API-Schlüssel holen!
Einschränkungen von GPT OSS
| Funktion | GPT-OSS (Self-Hosted Model) | GPT-5 API (Managed Platform) |
|---|---|---|
| Kernangebot | Ein reines Modell (der „Motor“) | Eine vollständige, integrierte Plattform (das „Auto“) |
| Modellfähigkeit | Stark, aber eine Generation zurück | State-of-the-Art, Flaggschiff-Reasoning |
| Integrierte Tools | Keine. Erfordert massiven DIY-Aufwand. | Vollständig verwaltet: Web Search, File Search, Code Interpreter. |
| Kontextfenster | Praktisch begrenzt durch Ihre Hardware (z. B. 8k-32k) | Massiv (400k), vollständig verwaltet. |
| Agent-Framework | DIY mit Open-Source-Bibliotheken. Keine Beobachtbarkeit. | Integriertes SDK mit eingebauter Beobachtbarkeit. |
| Enterprise-Funktionen | Keine. Keine Compliance, SSO oder Admin-Steuerung. | Vollständige Suite: SOC 2, HIPAA, RBAC, SSO usw. |
| Support | Community-basiert und Self-Service. | Dediziertes Account-Team und priorisierter Support. |
| Wartung | Ihre volle Verantwortung. Setup, Skalierung, Verfügbarkeit. | Null. Wird vollständig von OpenAI übernommen. |
Die Integration von GPT‑OSS mit TRAE vereint die Vorteile beider Welten:
- GPT‑OSS ist das „Gehirn“, gesteuert durch das Harmony-Format, um die Reasoning-Tiefe anzupassen, Ausgaben zu strukturieren und Gedankenprozesse auszublenden oder anzuzeigen.
- TRAE ist der „Körper“ mit integriertem Arbeitsbereich, Tool-Verbindungen und autonomem Software-Lebenszyklus-Management – insbesondere im SOLO-Modus.
- Novita AI schließt die Lücke, indem es GPT‑OSS für Sie hostet, sodass Sie es über die API ohne teure Hardware nutzen können.
Diese Kombination ermöglicht es Entwicklern, einen maßgeschneiderten „KI-Ingenieur“ zu bauen, der ihre Anforderungen versteht und genau so ausführt, wie beabsichtigt – und damit wirklich autonome Softwareauslieferung möglich macht.
Häufig gestellte Fragen
Warum GPT‑OSS mit TRAE anstelle eines Closed-Source-API-Modells verwenden?
Sie haben die volle Kontrolle. Das Harmony-Format ermöglicht TRAE die Steuerung der Reasoning-Tiefe, des Ausgabeformats und ob der Gedankenprozess angezeigt wird. Sie können GPT‑OSS auch auf Ihren eigenen Code feinabstimmen, um eine perfekte Passung zu erzielen.
Muss ich GPT‑OSS selbst hosten?
Nein. Dienste wie Novita AI hosten es für Sie und stellen Ihnen einen API-Schlüssel zur Verfügung, sodass Sie keine teuren GPUs oder komplexe Einrichtung benötigen.
Was ist das Harmony-Format und warum ist es wichtig?
Es ist ein spezielles Nachrichtenformat, das GPT‑OSS versteht. Es macht Ausgaben stabil, strukturiert und für TRAE leicht zu verarbeiten – ohne fragiles Parsing.
Novita AI ist die All-in-One-Cloud-Plattform, die Ihre KI-Ambitionen unterstützt. Integrierte APIs, Serverless, GPU-Instanz – die kosteneffizienten Tools, die Sie brauchen. Infrastruktur überflüssig machen, kostenlos starten und Ihre KI-Vision verwirklichen.
Empfehlungen
Qwen 3 in RAG Pipelines: All-in-One LLM, Embedding, and Reranking Models
Trae or Claude Code: Which Is More Suitable to Use with Kimi K2?



