

El desarrollo de software impulsado por IA avanza rápido, impulsado por dos grandes tendencias: modelos open-source potentes y entornos de desarrollo de IA totalmente integrados. GPT‑OSS es la serie de modelos de pesos abiertos de OpenAI, conocida por su sólido razonamiento, capacidades similares a agentes y una personalización profunda. TRAE, de ByteDance, es un IDE de IA diseñado para actuar como un “Ingeniero de IA” completo que puede construir software por sí mismo.
La pregunta es: ¿qué sucede cuando combinas el poder de razonamiento controlable de GPT‑OSS con el marco de desarrollo automatizado y rico en herramientas de TRAE? Juntos, crean un flujo de trabajo automatizado y adaptado a tus necesidades exactas. Esta guía explica cómo conectarlos y liberar todo su potencial.
¿Qué es Trae?
TRAE también es el nombre de un entorno de desarrollo integrado (IDE) con IA creado por ByteDance. Está diseñado para funcionar como un “Ingeniero de IA” que puede construir soluciones de software de forma independiente, comprendiendo tareas complejas y ejecutándolas. TRAE busca optimizar el flujo de trabajo permitiendo a los usuarios delegar tareas a la IA.
Funciones clave de Trae
Integración de herramientas y capacidades mejoradas (Model Context Protocol - MCP)
- Integración con herramientas externas: TRAE se integra con varias herramientas externas, permitiendo que los agentes de IA las utilicen para ejecutar tareas de manera más efectiva.
- Soporte MCP: Soporta el Protocolo de Contexto de Modelo (MCP), un estándar abierto para conectar aplicaciones de IA con fuentes de datos y herramientas externas. Funciona como un puerto “USB-C” universal para la IA, resolviendo el desafío de conectar modelos de IA con datos aislados.
- Capacidades de IA ampliadas: A través de MCP, los agentes pueden acceder a recursos externos como Google Drive, Slack, GitHub y bases de datos para comprender y completar mejor tareas complejas.
Comprensión contextual profunda y control preciso
- Comprensión profunda del contexto de desarrollo: TRAE comprende profundamente tu contexto de desarrollo, incluidos repositorios de código, resultados de búsqueda en línea y documentos compartidos.
- Personalización precisa del comportamiento: Puedes personalizar reglas para adaptar el comportamiento de la IA a tu flujo de trabajo, asegurando que ejecute las tareas exactamente como tú deseas.
- Interacción multimodal: Admite la carga de imágenes (por ejemplo, maquetas de diseño, capturas de pantalla de errores) para ayudar a describir requisitos, permitiendo que la IA genere código más preciso.
CUE: Predicción inteligente y edición con un solo clic
- Predice tu siguiente edición: La función CUE (Context Understanding Engine) comprende tu intención y predice tu próximo movimiento analizando tu comportamiento de edición.
- Navegación y aplicación con una tecla: Simplemente presiona la tecla
Tabpara saltar al siguiente cambio sugerido o aplicar sugerencias inteligentes en múltiples líneas a la vez. - Optimización continua: La función se optimiza continuamente para obtener un mejor rendimiento y capacidad de respuesta, proporcionando una experiencia más fluida para la modificación de código, generación y corrección de errores.
Funciones integrales de IDE y asistencia de IA
- Modos de desarrollo duales: Ofrece el Modo IDE para un flujo de trabajo tradicional controlado por el usuario, y el Modo SOLO donde la IA lidera el desarrollo desde los requisitos hasta la entrega para una automatización completa.
- IDE completo: Proporciona funciones estándar de IDE como edición de código, gestión de proyectos y control de versiones.
- Asistencia de programación con IA: Cuenta con varias asistencias impulsadas por IA, incluyendo autocompletado inteligente de código, refactorización, preguntas y respuestas mediante chat, y generación de proyectos a partir de lenguaje natural.
- Vista previa web integrada: Admite la vista previa directa de páginas web dentro del IDE para facilitar el desarrollo y la depuración del frontend.
¿Qué es Trae Solo?
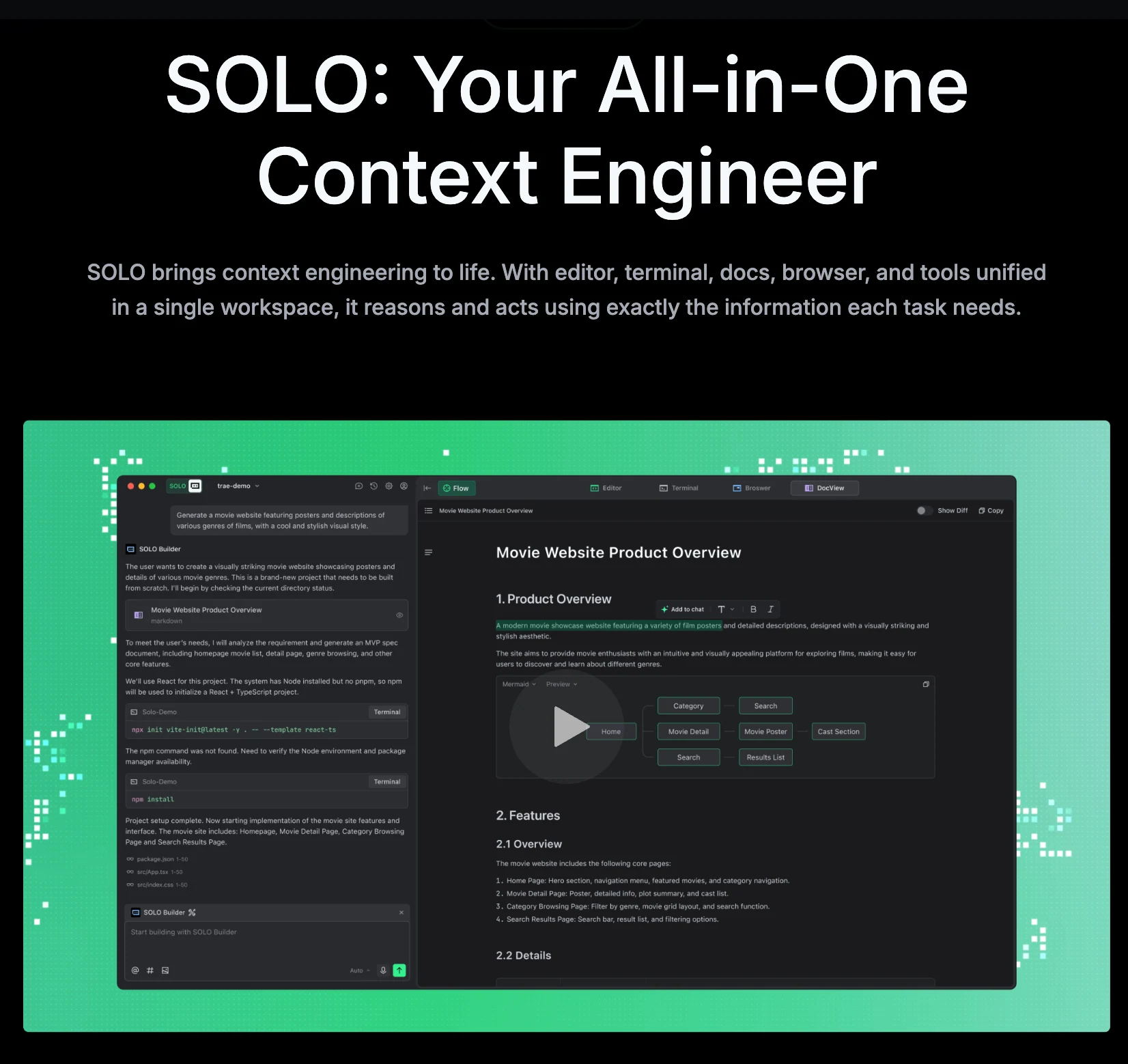
- Espacio de trabajo unificado y centro de herramientas de IA:
El modo SOLO integra todas las herramientas de desarrollo necesarias (el IDE, el navegador, la terminal y los documentos) directamente en la IA. Esto permite que la IA razone y actúe con precisión según las necesidades específicas de cada tarea, cerrando la brecha entre la idea y la ejecución. - Desarrollo de extremo a extremo liderado por IA:
Simplemente proporcionas los requisitos y SOLO maneja de forma autónoma todo el ciclo de vida del desarrollo, incluyendo:- Análisis de requisitos
- Creación de prototipos
- Desarrollo frontend
- Desarrollo backend
- Depuración y optimización
- Compilación e implementación
- Vista de monitoreo unificada:
Los usuarios pueden chatear con la IA y monitorear todas las actividades de desarrollo desde una única vista unificada. La “Vista ampliada” ofrece un detalle completo de todos los detalles de ejecución en tiempo real. - Interacción multimodal: “Habla” tus requisitos:
El modo SOLO admite entrada por voz, lo que te permite interactuar con TRAE de forma tan natural como lo harías con un compañero humano. La salida de la IA no se limita al código; una vista dinámica expandible a la derecha proporciona comentarios visuales e intuitivos. - El ingeniero de contexto:
El modo SOLO está diseñado para ser el “Ingeniero de Contexto” definitivo, capaz de comprender el alcance completo de tu trabajo para garantizar que sus acciones y resultados se basen en la información más completa y precisa disponible.
En resumen, el objetivo del modo TRAE SOLO es permitir “IA que envía software completo”. Capacita a los desarrolladores para construir y publicar software real más rápido a través de un simple proceso “Habla. Piensa. Entrega”.
¿Qué es GPT OSS?
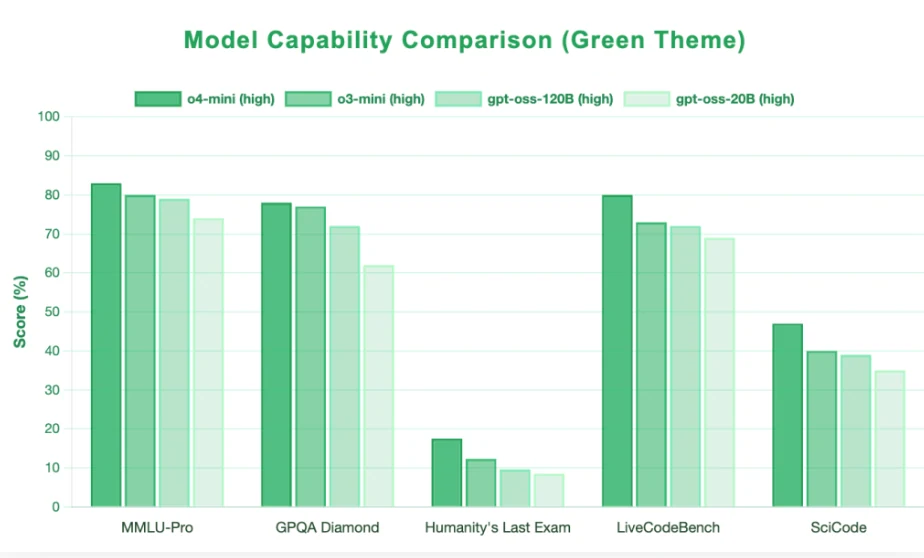
GPT-OSS (Open-Source Series) es una familia de potentes modelos de lenguaje de pesos abiertos lanzados por OpenAI, diseñados para estar disponibles libremente para uso comercial y ejecutarse localmente en hardware de consumo. La serie incluye dos modelos principales, una versión de 20 mil millones y otra de 120 mil millones de parámetros, optimizadas para un razonamiento sólido, uso de herramientas y eficiencia, lo que marca un cambio significativo de OpenAI hacia una mayor transparencia en la comunidad de IA. Estos modelos permiten a desarrolladores e investigadores ajustarlos para propósitos personalizados con control total sobre sus datos e infraestructura, cerrando la brecha entre los sistemas cerrados y propietarios y la IA de código abierto.
| Modelo | Capas | Parámetros totales | Parámetros activos por token | Expertos totales | Expertos activos por token | Longitud de contexto | Requisito de VRAM en GPU única |
| gpt-oss-120b | 36 | 117B | 5.1B | 128 | 4 | 128k | 80GB |
| gpt-oss-20b | 24 | 21B | 3.6B | 32 | 4 | 128k | 16GB |
¿Por qué elegir GPT OSS para código con IA?
Personalizar formato: Harmony
Los modelos GPT‑OSS utilizan un formato de conversación especial llamado Harmony. Este formato organiza los mensajes en roles claros — system, user y assistant — y te permite controlar cómo el modelo piensa y responde. Con Harmony, puedes ajustar la profundidad del razonamiento (baja, media, alta), decidir si mostrar u ocultar el proceso de pensamiento, y hacer que el modelo llame funciones de manera estable y estructurada. Muchos otros modelos de código abierto no tienen estos controles integrados, pero GPT‑OSS los entiende de forma nativa porque fue entrenado para seguir las instrucciones de Harmony. Esto facilita obtener resultados consistentes, confiables y amigables con herramientas.
Qué puede controlar Harmony
El formato Harmony te permite ajustar varios parámetros clave de comportamiento para los modelos GPT‑OSS:
| Parámetro | Descripción | Ejemplo |
|---|---|---|
| Profundidad de razonamiento | Controla cuánto razonamiento paso a paso realiza el modelo. | "Reasoning: low", "Reasoning: medium", "Reasoning: high" |
| Llamada a funciones | Soporte nativo para salida JSON de function_call / tool_calls al estilo OpenAI. |
"Always call function weather_api when asked about weather" |
| Visibilidad del razonamiento | Mostrar u ocultar la cadena de pensamiento completa entre etiquetas thinking. |
"Show reasoning" / "Hide reasoning" |
| Reglas de formato de salida | Forzar salida estructurada como JSON, Markdown, etc. | "Output in JSON format" |
Un ejemplo de solicitud Harmony
{
"messages": [
{
"role": "system",
"content": "Reasoning: medium; Hide reasoning; Output in JSON format"
},
{
"role": "user",
"content": "Explain how quicksort works."
}
]
}
Beneficios al usar Harmony con herramientas como Trae
Cuando se integra con plataformas de generación, depuración y ejecución de código como Trae, el formato Harmony ofrece varias ventajas prácticas:
-
Salida estructurada estable
- Harmony asegura que la salida del modelo siga un formato predecible de JSON o bloque de código.
- Trae puede analizar esto directamente sin expresiones regulares frágiles ni posprocesamiento.
-
Control de la profundidad del razonamiento
- Usa razonamiento bajo para prototipado rápido o código simple.
- Usa razonamiento alto para algoritmos complejos donde la corrección es crítica.
- Ahorra recursos de GPU/CPU al ajustar el costo del razonamiento a la complejidad de la tarea.
-
Alternar visibilidad del razonamiento
- Muestra el razonamiento en etiquetas
thinkingpara depuración y aprendizaje. - Oculta el razonamiento en producción para reducir tokens y evitar filtraciones de lógica interna.
- Muestra el razonamiento en etiquetas
-
Gestión clara del contexto en múltiples turnos
- Las reglas de
systempersisten entre turnos, asegurando un estilo de código y reglas de ejecución consistentes. - Fácil de iterar: modifica las instrucciones del usuario sin perder la configuración global.
- Las reglas de
-
Integración fluida con API
- Harmony imita la API de Respuestas de OpenAI, por lo que cualquier cadena de herramientas o plugin de IDE compatible con OpenAI puede funcionar con GPT‑OSS con cambios mínimos.
Uso de herramientas con GPT OSS
Los modelos GPT‑OSS están entrenados para usar herramientas externas de forma nativa como parte de su proceso de razonamiento, con soporte incorporado para navegación, ejecución de Python y parcheo de archivos. Estas herramientas se activan definiéndolas en el mensaje system de un prompt con formato Harmony.
1. Herramienta de navegador
-
Propósito: Buscar en la web, abrir páginas y encontrar texto en páginas.
-
Métodos:
search— buscar frases clave.open— abrir una página específica.find— localizar contenido en una página.
-
Características:
- Ventana de texto desplazable para gestionar el tamaño del contexto.
- Caché para visitas más rápidas a la misma página.
- Entrenado para citar fuentes en las respuestas.
-
Uso: Agregar la definición de la herramienta de navegador mediante
.with_browser()o.with_tools()en el promptsystem. -
Nota: La implementación de referencia es solo con fines educativos; usa tu propio backend en producción.
2. Herramienta de Python
-
Propósito: Realizar cálculos o ejecutar programas pequeños como parte de la cadena de pensamiento.
-
Características:
- Entrenado con una herramienta de Python con estado para razonamiento en múltiples pasos.
- La implementación de referencia usa un modo sin estado.
- Puede sobrescribir las descripciones predeterminadas de las herramientas en
openai‑harmony.
-
Uso: Agregar mediante
.with_python()o.with_tools()en el promptsystem. -
Advertencia de seguridad: El código de referencia se ejecuta en un contenedor Docker permisivo; añade tus propias restricciones en producción.
3. Herramienta Apply Patch (Aplicar parche)
- Propósito: Crear, actualizar o eliminar archivos locales.
- Caso de uso: Modificar código o archivos de proyecto como parte de un bucle de desarrollo automatizado.
¿Cómo usar GPT OSS en Trae?
Requisitos previos: Obtener una clave API
Novita AI proporciona API de GPT-OSS 120B
con contexto de 131K y costos de $0.1/input y $0.5/output. Novita AI también proporciona GPT-OSS 20B con 131 de contexto y costos de $0.05/input y $0.2/output , brindando un sólido soporte para maximizar el potencial del agente de código de GPT OSS.Novita AI
Paso 1: Inicia sesión y accede a la Biblioteca de Modelos
Inicia sesión en tu cuenta y haz clic en el botón Model Library.

Paso 2: Elige tu modelo
Navega por las opciones disponibles y selecciona el modelo que se adapte a tus necesidades.

Paso 3: Comienza tu prueba gratuita
Inicia tu prueba gratuita para explorar las capacidades del modelo seleccionado.

Paso 4: Obtén tu clave API
Para autenticarte con la API, te proporcionaremos una nueva clave API. Ingresa a la página de “Settings” y copia la clave API como se indica en la imagen.

Paso 5: Instala la API
Instala la API usando el gestor de paquetes específico de tu lenguaje de programación.
Después de la instalación, importa las bibliotecas necesarias en tu entorno de desarrollo. Inicializa la API con tu clave API para empezar a interactuar con Novita AI LLM. Este es un ejemplo de uso de la API de completaciones de chat para usuarios de Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="",
)
model = "openai/gpt-oss-120b"
stream = True # or False
max_tokens = 65536
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Usar GPT‑OSS en TRAE
Paso 1: Abre Trae y accede a los modelos
Inicia la aplicación Trae. Haz clic en la barra lateral de IA (Toggle AI Side Bar) en la esquina superior derecha para abrir la Barra lateral de IA. Luego, ve a AI Management y selecciona Models.

Paso 2: Agrega un modelo personalizado y elige Novita como proveedor y selecciona modelos
Haz clic en el botón Add Model para crear una entrada de modelo personalizada. En el cuadro de diálogo de agregar modelo, selecciona Provider = Novita del menú desplegable.
En el menú desplegable Model, elige tu modelo deseado (DeepSeek-R1-0528, Kimi K2, GLM 4.5, DeepSeek-V3-0324 o MiniMax-M1-80k). Si el modelo exacto no aparece en la lista, simplemente escribe el ID del modelo que anotaste de la biblioteca de Novita. Asegúrate de elegir la variante correcta del modelo que deseas usar.


Paso 3: Ingresa tu clave API
Copia la clave API de Novita AI desde tu consola de Novita y pégala en el campo API Key en Trae.
¡Obtén la clave API de Novita AI!
Limitación de GPT OSS
| Característica | GPT-OSS (Modelo auto alojado) | API GPT-5 (Plataforma gestionada) |
|---|---|---|
| Oferta principal | Un modelo en bruto (el “motor”) | Una plataforma completa e integrada (el “coche”) |
| Capacidad del modelo | Fuerte, pero una generación por detrás | De vanguardia, razonamiento emblemático |
| Herramientas integradas | Ninguna. Requiere un enorme esfuerzo DIY. | Totalmente gestionado: Búsqueda web, búsqueda de archivos, intérprete de código. |
| Ventana de contexto | Limitada prácticamente por tu hardware (ej., 8k-32k) | Masiva (400k), totalmente gestionada. |
| Marco de agente | DIY con bibliotecas de código abierto. Sin observabilidad. | SDK integrado con observabilidad incorporada. |
| Características empresariales | Ninguna. Sin cumplimiento, SSO ni controles de administración. | Suite completa: SOC 2, HIPAA, RBAC, SSO, etc. |
| Soporte | Basado en la comunidad y autoservicio. | Equipo de cuenta dedicado y soporte prioritario. |
| Mantenimiento | Tu responsabilidad total. Configuración, escalado, tiempo de actividad. | Cero. Gestionado completamente por OpenAI. |
Integrar GPT‑OSS con TRAE ofrece lo mejor de ambos mundos:
- GPT‑OSS es el “cerebro”, controlado a través del formato Harmony para ajustar la profundidad del razonamiento, estructurar las salidas y ocultar o mostrar los procesos de pensamiento.
- TRAE es el “cuerpo”, que ofrece un espacio de trabajo integrado, conexiones de herramientas y gestión autónoma del ciclo de vida del software, especialmente en el Modo SOLO.
- Novita AI cierra la brecha, alojando GPT‑OSS para ti para que puedas usarlo a través de API sin hardware costoso.
Esta combinación permite a los desarrolladores construir un “Ingeniero de IA” personalizado que entiende sus requisitos y los ejecuta exactamente como se pretende, haciendo posible la entrega de software verdaderamente autónoma.
Preguntas frecuentes
¿Por qué usar GPT‑OSS con TRAE en lugar de un modelo de API de código cerrado?
Obtienes control total. El formato Harmony permite que TRAE controle la profundidad del razonamiento, el formato de salida y si se muestra el proceso de pensamiento. También puedes ajustar GPT‑OSS con tu propio código para un ajuste perfecto.
¿Necesito alojar GPT‑OSS yo mismo?
No. Servicios como Novita AI lo alojan por ti y te proporcionan una clave API, por lo que no necesitas GPUs costosas ni una configuración compleja.
¿Qué es el formato Harmony y por qué es importante?
Es un formato de mensaje especial que GPT‑OSS entiende. Hace que las salidas sean estables, estructuradas y fáciles de procesar para TRAE, sin necesidad de análisis frágil.
Novita AI es la plataforma en la nube integral que impulsa tus ambiciones de IA. API integradas, sin servidor, instancias GPU: las herramientas rentables que necesitas. Elimina la infraestructura, comienza gratis y haz realidad tu visión de IA.
Lectura recomendada
Qwen 3 en pipelines RAG: modelo LLM, embedding y reranking todo en uno
Trae o Claude Code: ¿cuál es más adecuado para usar con Kimi K2?



