

Wichtige Highlights
Denkkontrolle: Qwen 3 32B ermöglicht anpassbare Denklänge (0–38.913 Token); QWQ 32B nicht.
Benchmark-Siege: Qwen 3 32B zeigt mit zunehmender Denklänge gleichmäßigere Leistungssteigerungen.
Bereitstellung: Qwen 3 32B benötigt ~96 GB (4× RTX 4090); QWQ 32B passt auf 1× A100 80GB.
Mehrsprachigkeit: Qwen 3 unterstützt 119 Sprachen; QWQ hat keine detaillierte mehrsprachige Unterstützung.
Qwen 3 32B VS QWQ 32B ist nicht nur ein Größenvergleich – es ist ein Vergleich von Flexibilität, Kontrolle und Bereitstellungsstrategie. Während beide einen „Denkmodus“ für komplexe Überlegungen bieten, zeichnet sich Qwen 3 32B durch die anpassbare Argumentationstiefe und eine breitere Anwendungspalette aus.
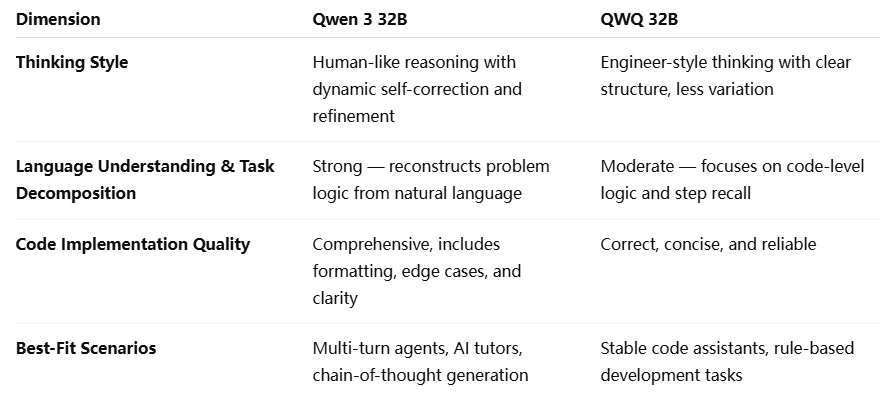
Qwen 3 32B VS QWQ 32B: Grundlegende Einführung
Qwen 3 32B

Von Qwen
QWQ 32B

Qwen 3 32B VS QWQ 32B: Denkmodus
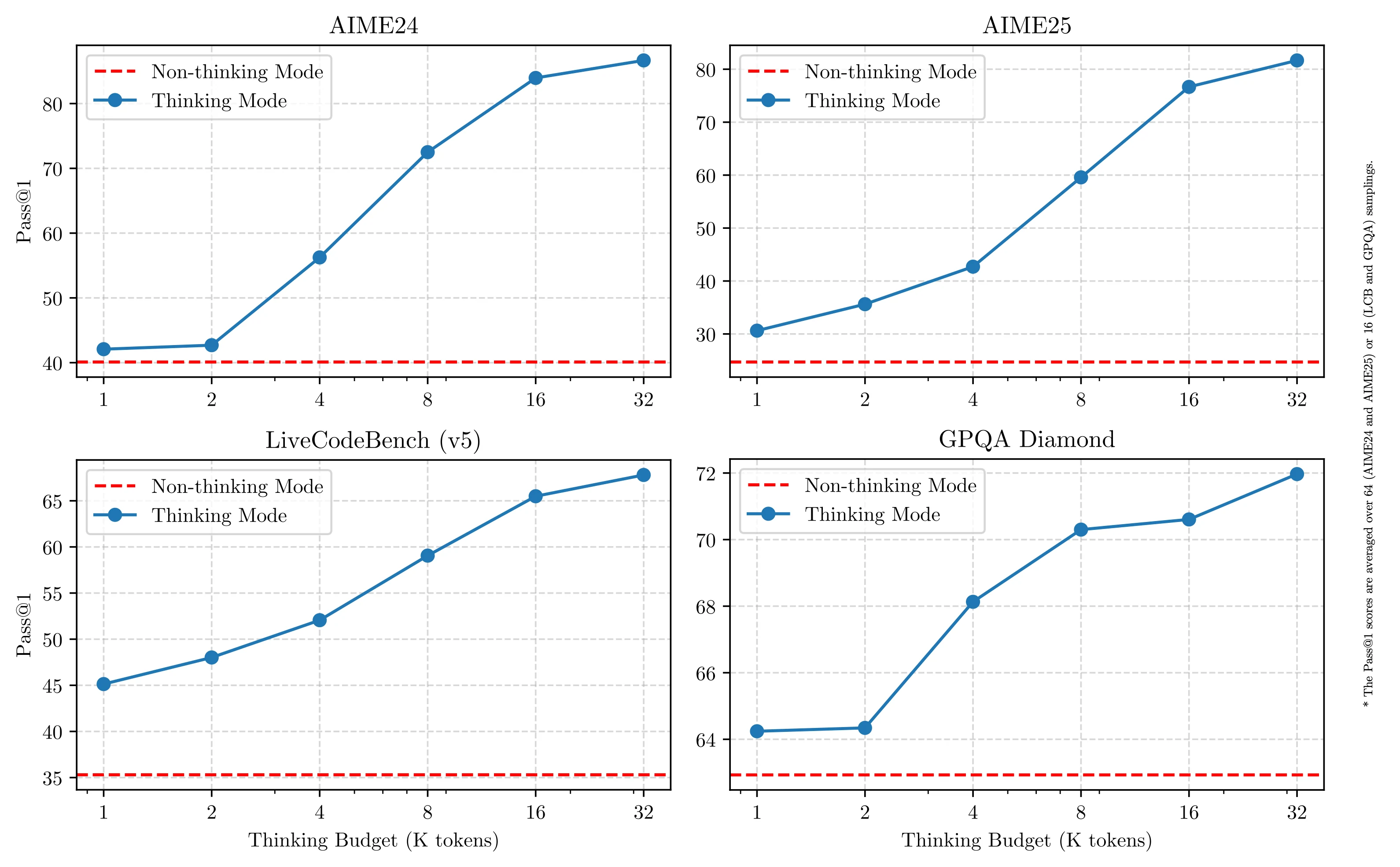
Sowohl Qwen 3 32B als auch QWQ 32B bieten einen „Denkmodus” für komplexe Überlegungen. Aber hier liegt der entscheidende Unterschied: Qwen 3 32B ermöglicht es Ihnen, die Denklänge zu steuern – von 0 bis 38.913 Token. Das bedeutet, Sie können anpassen, wie viel Überlegung das Modell anstellt.
- Schwierige Frage? Lassen Sie es länger denken.
- Einfache Aufforderung? Kurz und schnell halten.
Wie in der Grafik dargestellt, verbessert sich die Leistung gleichmäßig, wenn das Denkbudget steigt. Das macht Qwen 3 flexibler und effizienter für verschiedene Aufgaben.
Von Qwen
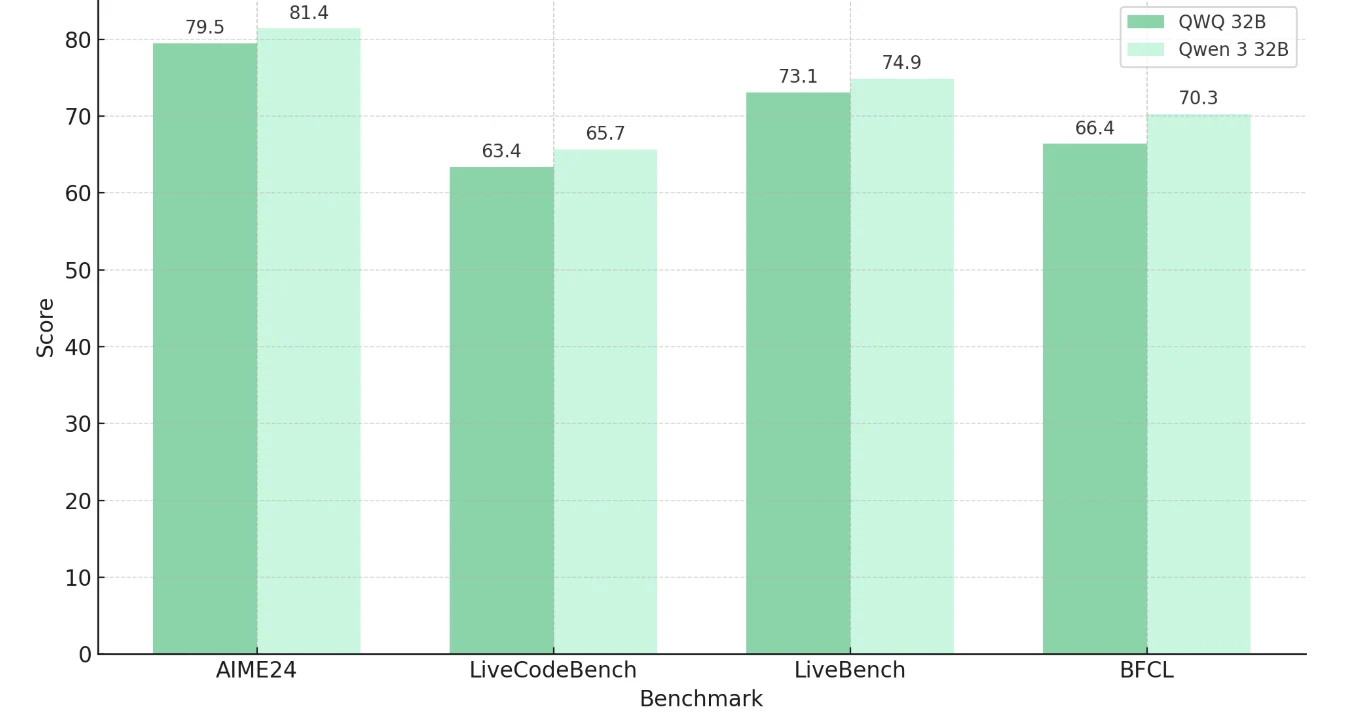
Qwen 3 32B VS QWQ 32B: Benchmark
Wenn Sie es selbst testen möchten, können Sie auf der Novita AI-Website eine kostenlose Testversion starten.

Testen Sie jetzt die Demo von Qwen 3 32B und QWQ 32B!
Qwen 3 32B VS QWQ 32B: Hardware-Anforderungen
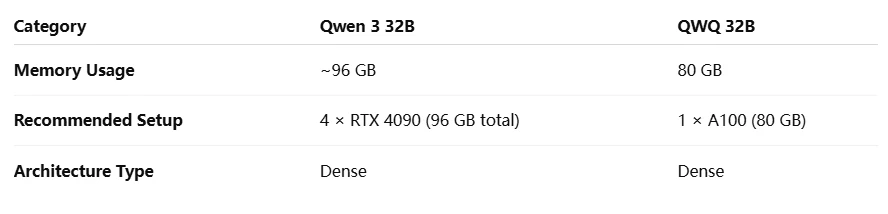
Beide Modelle erfordern High-End-GPUs für die lokale Bereitstellung, insbesondere Qwen 3 32B mit seinem größeren Speicherbedarf.
Für die meisten Entwickler ist der einfachste und kostengünstigste Weg, über API auf diese Modelle zuzugreifen, ohne in teure Hardware investieren zu müssen.
Qwen 3 32B VS QWQ 32B: Anwendungen
Qwen 3 32B
Aufgaben, die komplexe Überlegungen und langformatige Generierung erfordern
Steuerbare Denklänge – bis zu 38.913 Token
Mehrsprachige Anwendungen (unterstützt 119 Sprachen)
Agentenartige Interaktionen, kreatives Schreiben, Codierung mit Werkzeugen
Cloud-Bereitstellung bevorzugt (erfordert ~96 GB, 4× RTX 4090)
QWQ 32B
Faktenlastige Fragen und wissensintensive Aufgaben
Solide Leistung bei IFEval, MMLU und LiveCodeBench
Einfachere lokale Bereitstellung (läuft auf 1× A100 80GB)
Geeignet für unternehmenseigene Wissenssysteme und interne Tools
Qwen 3 32B VS QWQ 32B: Aufgaben
Anfragen: Schreiben Sie ein Programm, das ein Sudoku-Rätsel lösen kann.
Qwen 3 32B
QWQ 32B
Qwen 3 32B VS QWQ 32B
Wie greife ich über die Novita-API auf Qwen 3 32B und QWQ 32B zu?
Schritt 1: Einloggen und auf die Modellbibliothek zugreifen
Melden Sie sich in Ihrem Konto an und klicken Sie auf die Schaltfläche Modellbibliothek.

Schritt 2: Wählen Sie Ihr Modell aus
Durchsuchen Sie die verfügbaren Optionen und wählen Sie das Modell aus, das Ihren Anforderungen entspricht.
Schritt 3: Starten Sie Ihre kostenlose Testversion
Beginnen Sie Ihre kostenlose Testversion, um die Fähigkeiten des ausgewählten Modells zu erkunden.
Testen Sie jetzt Qwen 3 32B VS QWQ 32B!
Schritt 4: Holen Sie sich Ihren API-Schlüssel
Zur Authentifizierung mit der API erhalten Sie von uns einen neuen API-Schlüssel. Gehen Sie auf die Seite „Einstellungen“ und kopieren Sie den API-Schlüssel wie im Bild gezeigt.

Schritt 5: Installieren Sie die API
Installieren Sie die API mit dem für Ihre Programmiersprache spezifischen Paketmanager.
Importieren Sie nach der Installation die erforderlichen Bibliotheken in Ihre Entwicklungsumgebung. Initialisieren Sie die API mit Ihrem API-Schlüssel, um mit Novita AI LLM zu interagieren. Dies ist ein Beispiel für die Verwendung der Chat Completions API für Python-Benutzer.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<IHR Novita AI API-Schlüssel>",
)
model = "qwen/qwen3-32b-fp8"
stream = True # or False
max_tokens = 2048
system_content = """Seien Sie ein hilfreicher Assistent"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "user",
"content": "Hallo!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Qwen 3 32B ist ideal für dynamische, kontextreiche KI-Anwendungen mit seinem anpassbaren Denkbudget und der mehrsprachigen Unterstützung.
QWQ 32B liefert gute Ergebnisse bei statischen QA- und Logikaufgaben und ist für hardwarebeschränkte Umgebungen besser bereitstellbar.
Häufig gestellte Fragen
Qwen 3 32B VS QWQ 32B: Welches ist besser für längere Überlegungen?
Qwen 3 32B. Es unterstützt eine steuerbare Denklänge von bis zu 38.913 Token, was die Leistung bei komplexen Aufgaben steigert.
Qwen 3 32B oder QWQ 32B ist einfacher lokal bereitzustellen?
QWQ 32B. Es läuft auf einer einzigen A100 80GB, während Qwen 3 32B einen 4× RTX 4090 Aufbau erfordert.
Qwen 3 32B oder QWQ unterstützt mehr Sprachen?
Qwen 3 32B unterstützt 119 Sprachen und Dialekte – ideal für mehrsprachige Anwendungen.
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen, und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud für den Aufbau und die Skalierung bietet.



