

احصل على $10 من واجهة برمجة تطبيقات LLM
النقاط الرئيسية
التحكم في التفكير: يتيح Qwen 3 32B ضبط طول التفكير (0–38,913 رمزًا)؛ بينما لا يوفر QWQ 32B ذلك.
تفوق المعايير: يُظهر Qwen 3 32B تحسنًا سلسًا في الأداء مع زيادة طول التفكير.
النشر: يتطلب Qwen 3 32B حوالي 96 جيجابايت (4× RTX 4090)؛ بينما يناسب QWQ 32B تشغيله على 1× A100 80 جيجابايت.
التعدد اللغوي: يدعم Qwen 3 119 لغة؛ بينما يفتقر QWQ إلى دعم متعدد اللغات مفصل.
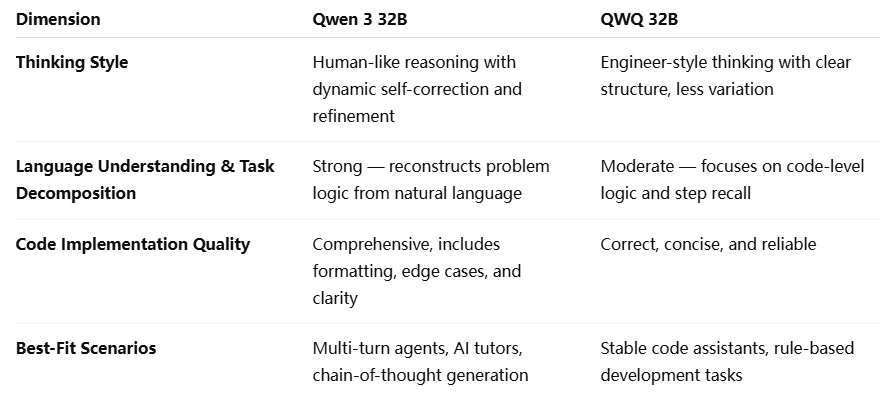
مقارنة Qwen 3 32B وQWQ 32B ليست مجرد مقارنة في الحجم - إنها مقارنة في المرونة والتحكم واستراتيجية النشر. بينما يقدم كلاهما “وضع التفكير” للاستدلال المعقد، يتميز Qwen 3 32B بعمق استدلال قابل للتخصيص ونطاق تطبيقات أوسع.
Qwen 3 32B مقابل QWQ 32B: مقدمة أساسية
Qwen 3 32B

من Qwen
QWQ 32B

Qwen 3 32B مقابل QWQ 32B: وضع التفكير
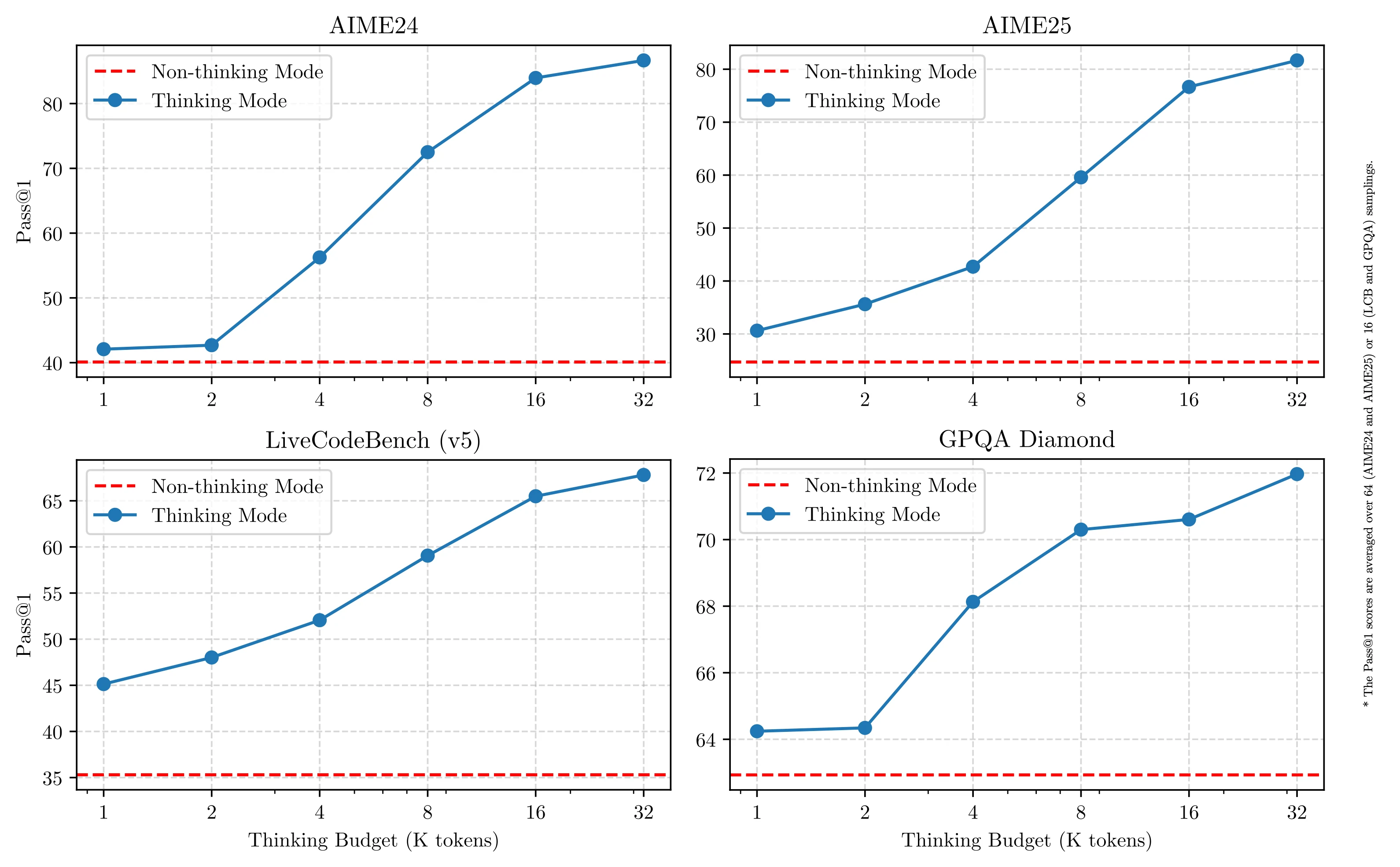
يقدم كل من Qwen 3 32B و QWQ 32B “وضع التفكير” للاستدلال المعقد. لكن إليك الفرق الرئيسي: يتيح لك Qwen 3 32B التحكم في طول التفكير — من 0 إلى 38,913 رمزًا. هذا يعني أنه يمكنك تخصيص مقدار الاستدلال الذي يؤديه النموذج.
- لديك سؤال صعب؟ دعه يفكر لفترة أطول.
- استعلام بسيط؟ أبقِه قصيرًا وسريعًا.
كما هو موضح في المخطط، يتحسن الأداء بسلاسة مع زيادة ميزانية التفكير. وهذا يجعل Qwen 3 أكثر مرونة وكفاءة عبر المهام المختلفة.
من Qwen
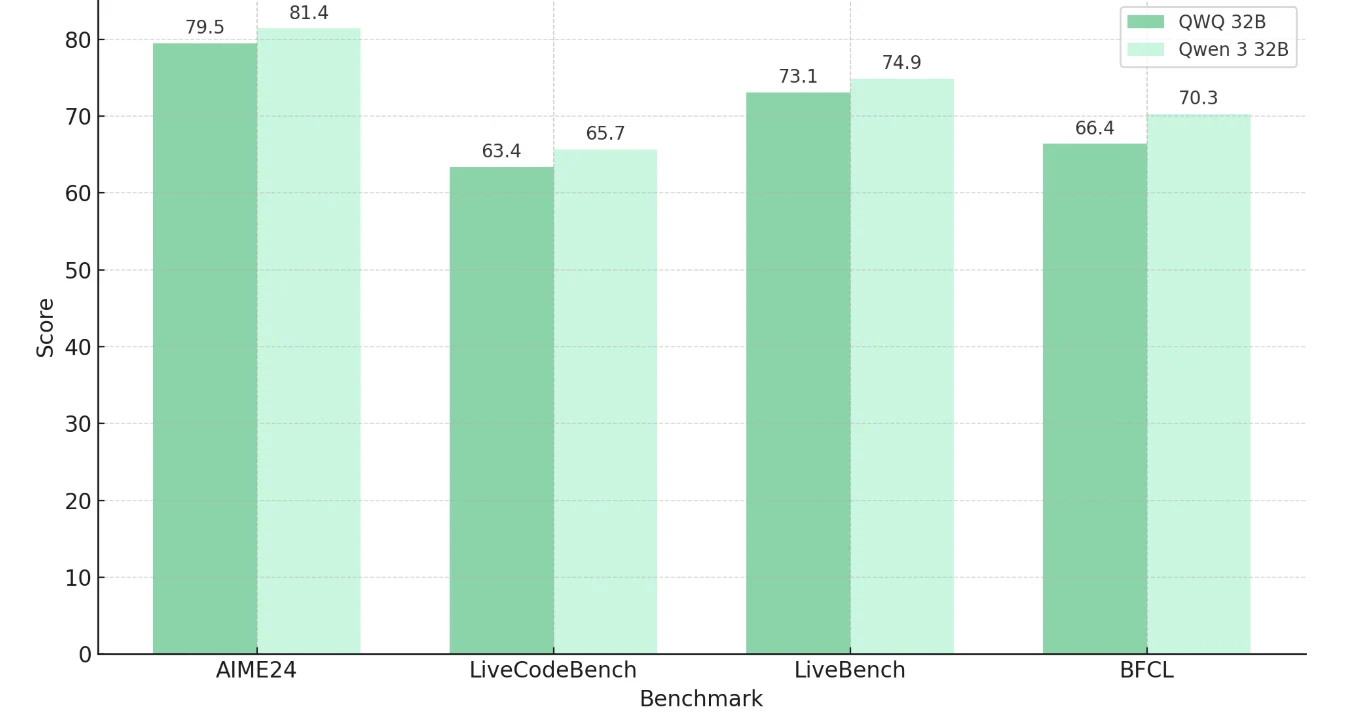
Qwen 3 32B مقابل QWQ 32B: المعايير
إذا كنت ترغب في اختباره بنفسك، يمكنك بدء تجربة مجانية على موقع Novita AI.

جرب عرض Qwen 3 32B وQWQ 32B الآن!
Qwen 3 32B مقابل QWQ 32B: متطلبات الأجهزة
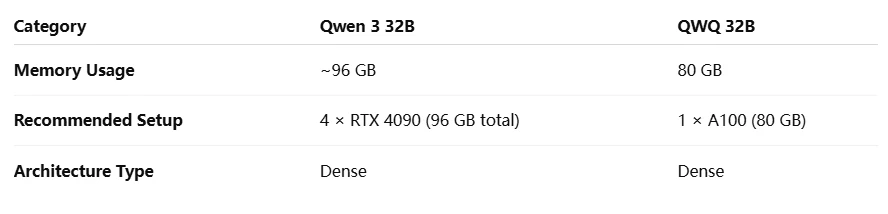
يتطلب كلا النموذجين وحدات معالجة رسومية عالية الجودة للنشر المحلي، خاصة Qwen 3 32B مع بصمة الذاكرة الأكبر.
بالنسبة لمعظم المطورين، الخيار الأسهل والأكثر فعالية من حيث التكلفة هو الوصول إلى هذه النماذج عبر واجهة برمجة التطبيقات، دون الحاجة إلى الاستثمار في أجهزة باهظة الثمن.
Qwen 3 32B مقابل QWQ 32B: التطبيقات
Qwen 3 32B
المهام التي تتطلب استدلالًا معقدًا وتوليدًا طويل النص
طول تفكير قابل للتحكم — حتى 38,913 رمزًا
تطبيقات متعددة اللغات (يدعم 119 لغة)
تفاعلات تشبه الوكيل، كتابة إبداعية، برمجة بأدوات
يفضل النشر السحابي (يتطلب حوالي 96 جيجابايت، 4× RTX 4090)
QWQ 32B
الاستعلامات الثقيلة بالحقائق والمهام كثيفة المعرفة
أداء قوي في IFEval وMMLU وLiveCodeBench
نشر محلي أسهل (يعمل على 1× A100 80 جيجابايت)
مناسب لـ أنظمة المعرفة المؤسسية والأدوات الداخلية
Qwen 3 32B مقابل QWQ 32B: المهام
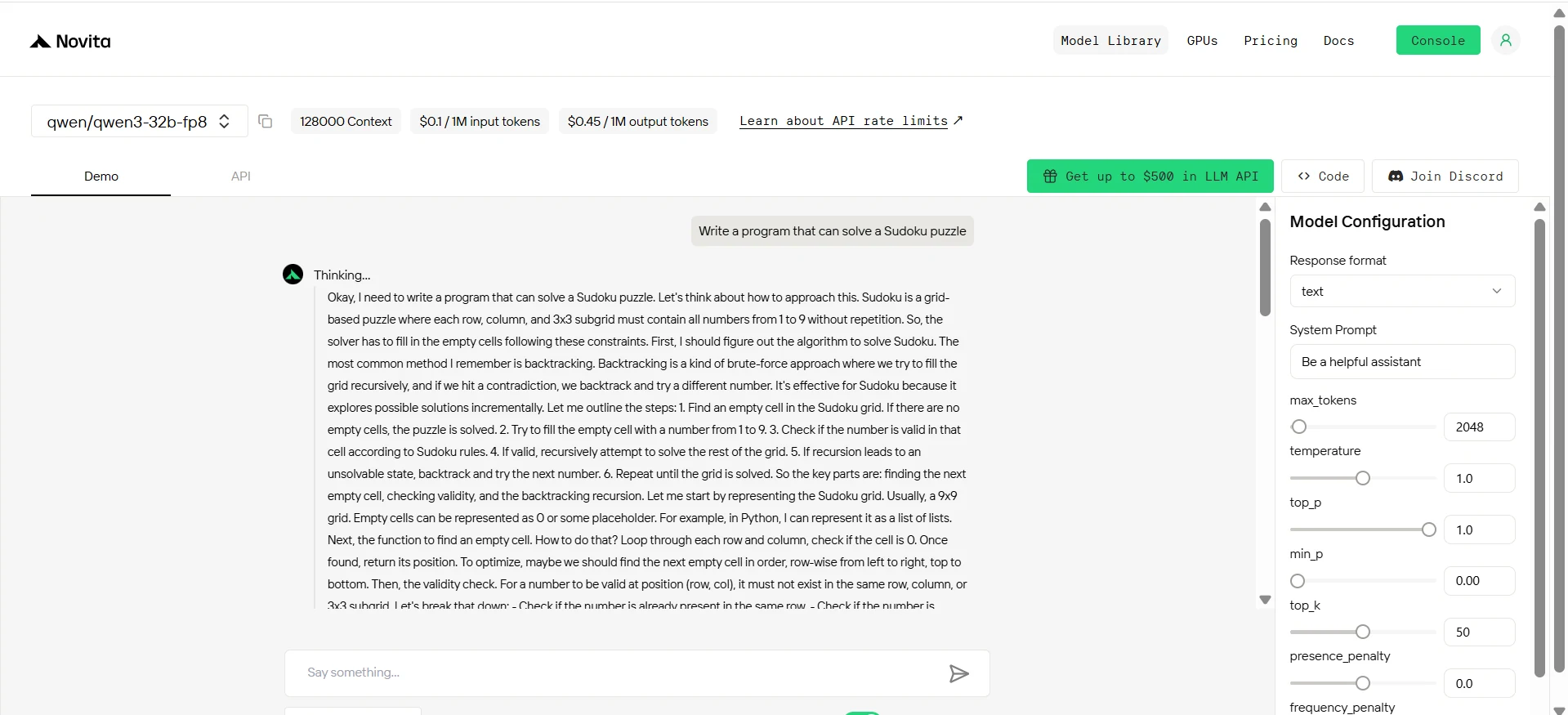
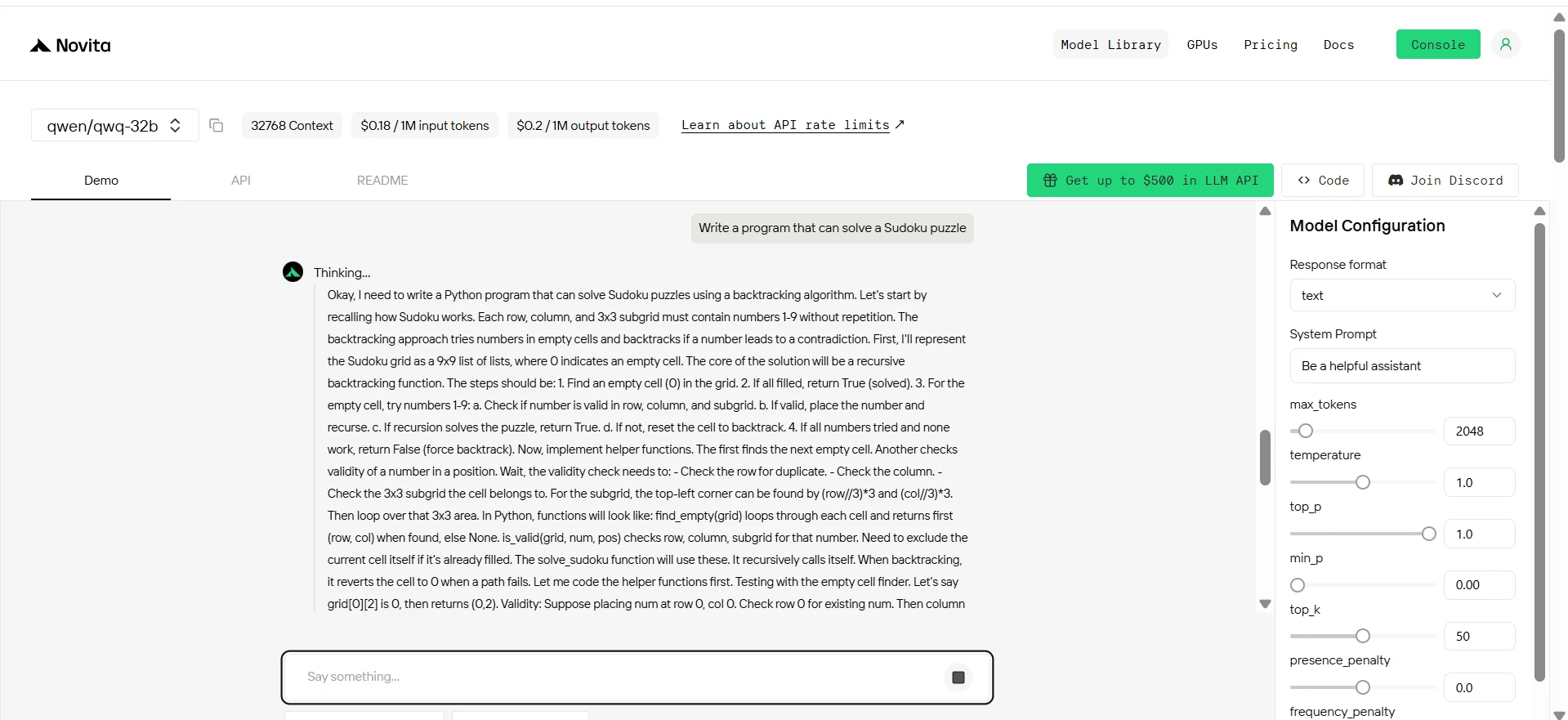
الأوامر: اكتب برنامجًا يمكنه حل لغز سودوكو.
Qwen 3 32B
QWQ 32B
مقارنة Qwen 3 32B وQWQ 32B
كيفية الوصول إلى Qwen 3 32B وQWQ 32B عبر واجهة Novita API؟
الخطوة 1: تسجيل الدخول والوصول إلى مكتبة النماذج
سجل الدخول إلى حسابك وانقر على زر مكتبة النماذج.

الخطوة 2: اختر النموذج الخاص بك
تصفح الخيارات المتاحة واختر النموذج الذي يناسب احتياجاتك.
الخطوة 3: ابدأ فترة التجربة المجانية
ابدأ فترة التجربة المجانية لاستكشاف إمكانيات النموذج المختار.
الخطوة 4: احصل على مفتاح واجهة برمجة التطبيقات
للمصادقة مع واجهة برمجة التطبيقات، سنقدم لك مفتاح API جديد. ادخل إلى صفحة “الإعدادات”، يمكنك نسخ مفتاح API كما هو موضح في الصورة.

الخطوة 5: تثبيت واجهة برمجة التطبيقات
قم بتثبيت واجهة برمجة التطبيقات باستخدام مدير الحزم الخاص بلغة البرمجة التي تستخدمها.
بعد التثبيت، قم باستيراد المكتبات اللازمة في بيئة التطوير الخاصة بك. قم بتهيئة واجهة برمجة التطبيقات باستخدام مفتاح API الخاص بك لبدء التفاعل مع Novita AI LLM. هذا مثال لاستخدام واجهة برمجة تطبيقات الدردشة الكاملة لمستخدمي Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "qwen/qwen3-32b-fp8"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Qwen 3 32B مثالي لتطبيقات الذكاء الاصطناعي الديناميكية عالية السياق بفضل ميزانية التفكير القابلة للضبط والدعم متعدد اللغات.
يؤدي QWQ 32B بشكل جيد في مهام الاستعلامات الثابتة والمنطق، وهو أكثر ملاءمة للنشر في البيئات المحدودة بالأجهزة.
الأسئلة المتكررة
Qwen 3 32B أم QWQ 32B: أيهما أفضل للاستدلال الطويل النص؟
Qwen 3 32B. فهو يدعم طول تفكير قابل للتحكم يصل إلى 38,913 رمزًا، مما يعزز الأداء في المهام المعقدة.
Qwen 3 32B أم QWQ 32B أسهل في النشر محليًا؟
QWQ 32B. فهو يعمل على بطاقة A100 80 جيجابايت واحدة، بينما يتطلب Qwen 3 32B إعداد 4 × RTX 4090.
Qwen 3 32B أم QWQ يدعم المزيد من اللغات؟
Qwen 3 32B يدعم 119 لغة ولهجة — مثالي للتطبيقات متعددة اللغات.
Novita AI هي منصة سحابية للذكاء الاصطناعي تقدم للمطورين طريقة سهلة لنشر نماذج الذكاء الاصطناعي باستخدام واجهة برمجة التطبيقات البسيطة لدينا، بينما توفر أيضًا سحابة GPU موثوقة وبأسعار معقولة للبناء والتوسع.



