

Wichtige Highlights
Es erreicht 92,1 im IFEval für hervorragende Instruktionsbefolgung, 88,4 % im HumanEval für starke Codegenerierung und 91,1 im MGSM für mehrsprachiges mathematisches Problemlösen.
Mit effizientem Ressourcenverbrauch (40 GB GPU-VRAM) und niedrigen Tokenkosten (0,39 $ pro Million Tokens von Novita AI) ist es ideal für Startups und kleine Unternehmen.
Entwickler können einfach über Novita AI auf LLaMA 3.3 zugreifen. Melden Sie sich für eine kostenlose Testversion an, erhalten Sie einen API-Schlüssel und integrieren Sie das Modell in Anwendungen, um sein volles Potenzial für Sprachaufgaben zu nutzen.
LLaMA 3.3 ist Metas neuester Durchbruch bei großen Sprachmodellen und bietet deutliche Verbesserungen bei Leistung und Effizienz gegenüber früheren Versionen. Trotz weniger Parameter übertrifft das LLaMA 3.3 70B Modell viele traditionelle große Modelle, einschließlich LLaMA 3.1 405B, in mehreren wichtigen Benchmarks. Diese Optimierung bietet eine ideale Balance zwischen Recheneffizienz und Verarbeitungsleistung, reduziert die Hardwareanforderungen und behält gleichzeitig eine hohe Leistung bei. Dieser Artikel bietet eine detaillierte Analyse der Benchmark-Leistung von LLaMA 3.3 in mehreren kritischen Dimensionen.
Übersicht über Benchmark-Metriken für LLMs
Bei der Bewertung großer Sprachmodelle (LLMs) werden vier kritische Benchmarks verwendet, um ihre Gesamtleistung zu bewerten: Gesamt, Generierungsqualität, Effizienz und Praktische Anwendung. Zusammen bieten diese Standards einen umfassenden Überblick über die Effektivität und Benutzerfreundlichkeit eines LLMs.
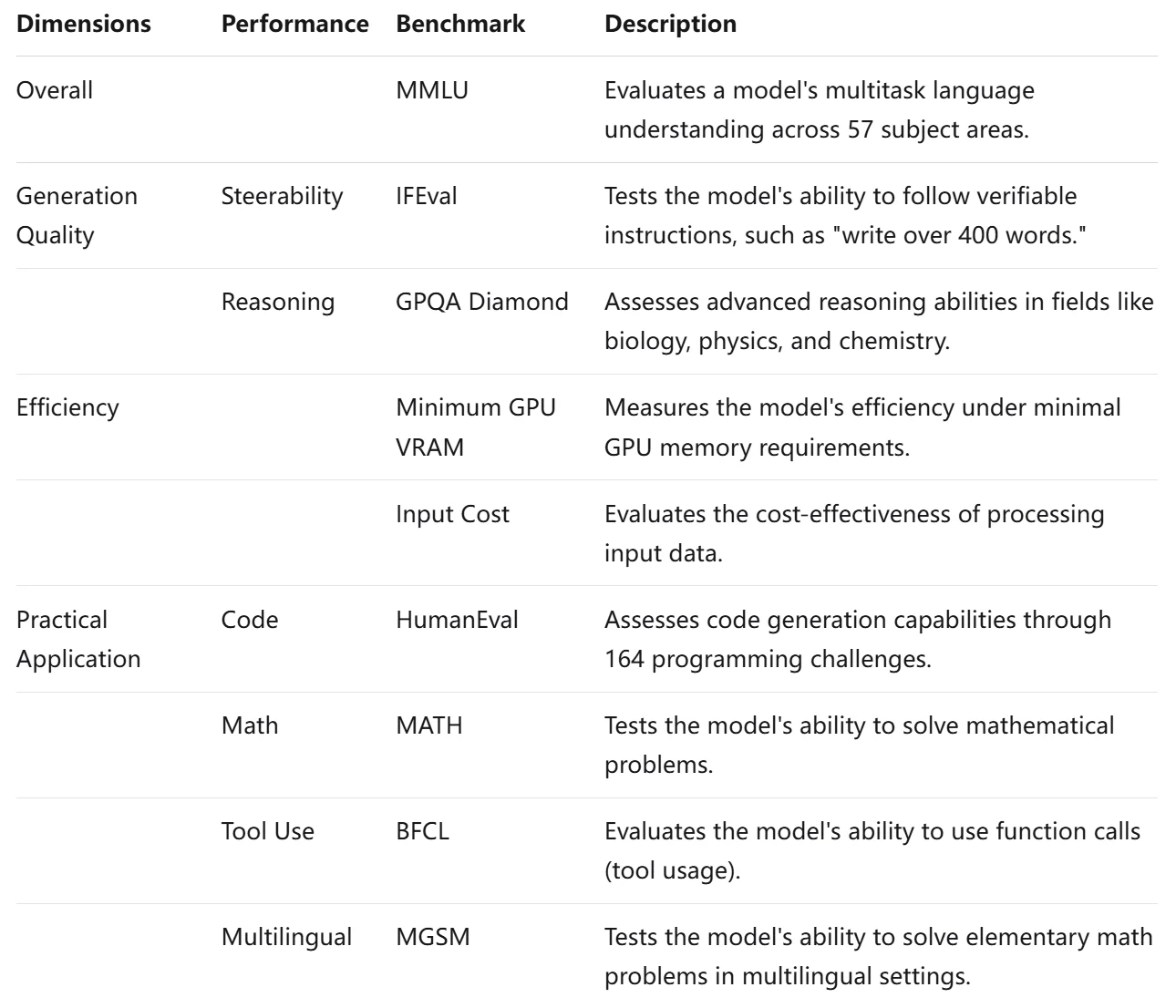
Gesamtdimension
Man kann durchaus sagen, dass MMLU im Vergleich zu anderen Teststandards ein relativ umfassender Benchmark zur Beschreibung von Modellfähigkeiten ist. Es ist jedoch wichtig zu beachten, dass kein einzelner Benchmark alle Aspekte der Leistung eines Modells erfassen kann. Er wird oft in Verbindung mit anderen Benchmarks für eine vollständigere Bewertung verwendet.
Was ist MMLU?
MMLU (Massive Multitask Language Understanding) ist ein umfassender Benchmark, der entwickelt wurde, um die Leistung von KI-Sprachmodellen über eine Vielzahl von Themen und Aufgaben hinweg zu bewerten. Er bewertet die Multitask-Fähigkeiten, das Allgemeinwissen und die Problemlösungsfähigkeiten eines Modells in verschiedenen Bereichen.
Erfassungsinhalt:
- Mehrbereichswissen
MMLU deckt 57 verschiedene Fachgebiete ab, darunter MINT, Geisteswissenschaften, Sozialwissenschaften und Berufsfelder. - Argumentationsfähigkeit
Bewertet die Argumentations- und Problemlösungsfähigkeiten des Modells durch verschiedene Fragetypen. - Sprachverständnis
Testet die Fähigkeit des Modells, Sprache in verschiedenen Kontexten zu verstehen und zu verarbeiten. - Multitask-Verarbeitung
Bewertet die Fähigkeit des Modells, zwischen mehreren Aufgaben zu wechseln und Wissen zu generalisieren.
Erfassungsmethoden:
MMLU bewertet Sprachmodelle durch einen strukturierten Arbeitsablauf, der mit der Präsentation von Multiple-Choice-Fragen zu 57 verschiedenen Themen beginnt. Modelle werden in Zero-Shot- und Few-Shot-Einstellungen getestet, die reale Szenarien simulieren. Ihre Leistung wird durch Genauigkeitsbewertung gemessen, die den Anteil der richtigen Antworten bewertet. Schließlich wird ein umfassender Score durch Mittelung der Genauigkeit über alle Bereiche berechnet, was zu einem Score zwischen 0 und 1 führt, der die Gesamtfähigkeiten des Modells zusammenfasst.
Generierungsqualität
Die Generierungsqualität umfasst die Kohärenz, Relevanz und Flüssigkeit des vom Modell generierten Textes. Eine hohe Generierungsqualität ist entscheidend für Anwendungen, die Inhaltserstellung, Dialogsysteme und mehr umfassen.
Zwei bedeutende Benchmarks in diesem Bereich sind IFEval und GPQA.
Was ist IFEval?
IFEval (Instruction-Following Evaluation) ist ein Benchmark, der entwickelt wurde, um die Fähigkeit eines Sprachmodells zu bewerten, Anweisungen genau zu verstehen und zu befolgen. IFEval konzentriert sich darauf, zu bewerten, wie gut ein Sprachmodell in natürlicher Sprache gegebene Anweisungen verstehen und ausführen kann. Der Benchmark ist entscheidend, um sicherzustellen, dass Modelle Benutzer in realen Szenarien, in denen das Befolgen von Anweisungen unerlässlich ist, effektiv unterstützen können.
Beispiel Workflow
- Anweisungsgenerierung: Erstellen Sie Prompts, die eine oder mehrere überprüfbare Anweisungen aus einem Satz von 25 vordefinierten Typen enthalten, z. B. „schreibe mehr als 400 Wörter“ oder „erwähne das Keyword KI mindestens dreimal“.
- Modellantwort: Das Sprachmodell generiert eine Antwort basierend auf den gegebenen Anweisungen.
- Evaluierungsmetriken:
- Strenge Metrik: Überprüft, ob die Ausgabe des Modells die Anweisungen streng durch exakten String-Abgleich befolgt.
- Lockere Metrik: Bewertet die Ausgabe nach Anwendung verschiedener Transformationen, um Flexibilität bei Format und Formulierung zu ermöglichen und falsch-negative Ergebnisse zu reduzieren.
- Bewertung: Berechnet die Genauigkeit basierend auf dem Prozentsatz der korrekt befolgten Anweisungen, sowohl auf Prompt-Ebene als auch auf Anweisungsebene.
- Ausgabedaten: Fasst die Ergebnisse zusammen, um Einblicke in die Instruktionsbefolgungsfähigkeiten des Modells zu geben und Stärken und Schwächen hervorzuheben.
Was ist GPQA?
GPQA (General Purpose Question Answering) ist ein Benchmark für das allgemeine Frage-Antworten. Dieser Benchmark ist besonders nützlich, um die Fähigkeit eines Modells zu bewerten, verschiedene Arten von Anfragen zu verstehen und genaue Antworten zu generieren, was ihn zu einer entscheidenden Metrik für Anwendungen wie virtuelle Assistenten, Chatbots und Informationsabrufsysteme macht.
Beispiel-Workflow ähnlich wie IFEval, aber mit einigen Unterschieden
- Fokus auf Schwierigkeit:
- IFEval: Konzentriert sich darauf, wie gut das Modell verschiedene natürliche Sprachinstruktionen befolgt.
- GPQA: Ziel sind schwierige Fragen, die selbst für Experten eine Herausforderung darstellen und nicht einfach durch Online-Suchen beantwortet werden können.
- Fragenentwicklung:
- IFEval: Bewertet hauptsächlich, wie gut Modelle gegebene Anweisungen ausführen, ohne umfangreiche Validierung.
- GPQA: Experten erstellen und validieren komplexe Fragen.
Effizienz
Effizienz im Kontext von LLMs umfasst sowohl die Lauffähigkeit als auch die Eingabekosten. Minimaler GPU-VRAM und Eingabekosten spielen eine entscheidende Rolle bei der Bestimmung, wie effizient ein großes Sprachmodell (LLM) wie LLaMA 3.3 arbeitet. Hier ist eine detaillierte Erklärung jeder Metrik und der für ihre Berechnung verwendeten Standards:
Was ist minimaler GPU-VRAM?
Minimaler GPU-VRAM bezeichnet die minimale Menge an Video-RAM (VRAM), die erforderlich ist, um das Modell effektiv auszuführen. VRAM ist wesentlich zum Speichern der Modellparameter sowie der Zwischenberechnungen während der Inferenz und des Trainings. Ein geringerer minimaler GPU-VRAM bedeutet eine erhöhte Zugänglichkeit. Für Entwickler und Organisationen, die die Leistungsfähigkeit der KI ohne prohibitive Kosten nutzen möchten.
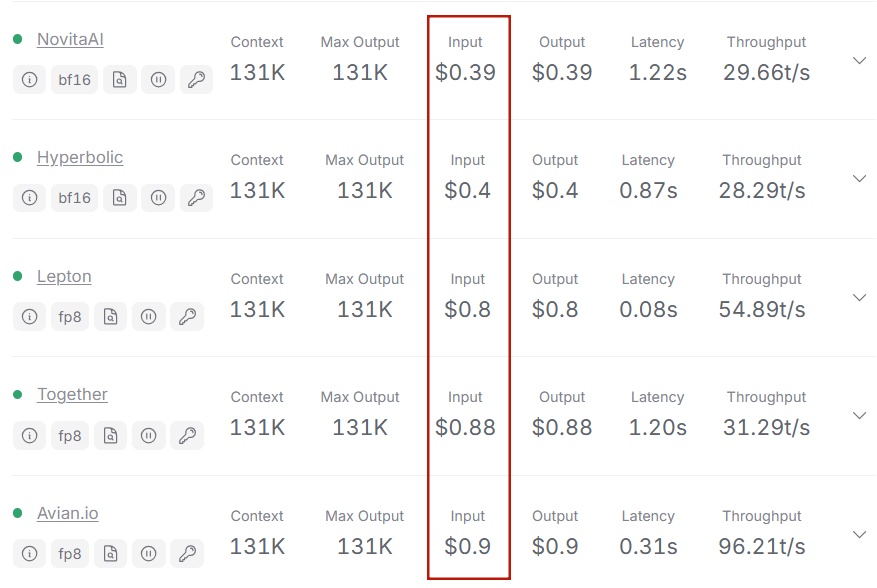
Was sind Eingabekosten? (z. B. Novita AI)
Eingabekosten beziehen sich auf die Ausgaben, die mit der Verarbeitung von Eingaben verbunden sind, gemessen an den genutzten Rechenressourcen. Die Eingabekosten werden typischerweise auf der Grundlage realer Nutzungsszenarien berechnet und können je nach Dienstanbieter variieren. Beispielsweise können die Kosten aus der API-Nutzung abgeleitet werden.
Praktische Anwendung
Metriken zur praktischen Anwendung bewerten, wie gut ein Modell bei realen Aufgaben abschneidet. Wichtige Benchmarks in diesem Bereich sind:
| Benchmark | Bedeutung |
|---|---|
| HumanEval | Ein Benchmark zur Bewertung der Codegenerierungsfähigkeiten von Sprachmodellen. |
| MATH | Ein Benchmark, der sich auf die Bewertung mathematischer Problemlösungsfähigkeiten von Sprachmodellen konzentriert. |
| BFCL v2 | Ein Benchmark zur Bewertung der Funktionsaufruf-Fähigkeiten großer Sprachmodelle. |
| MGSM | Ein Benchmark zur Bewertung mehrsprachigen Problemlösens in elementarer Mathematik. |
Nachdem wir nun einen umfassenden und universellen Benchmarking-Rahmen für LLMs untersucht haben, tauchen wir in die Leistung von LLaMA 3.3 in diesen Dimensionen ein!
Übersicht über Benchmarks für Llama 3.3, verglichen mit Llama 3.1 70b instruct und GPT-4o
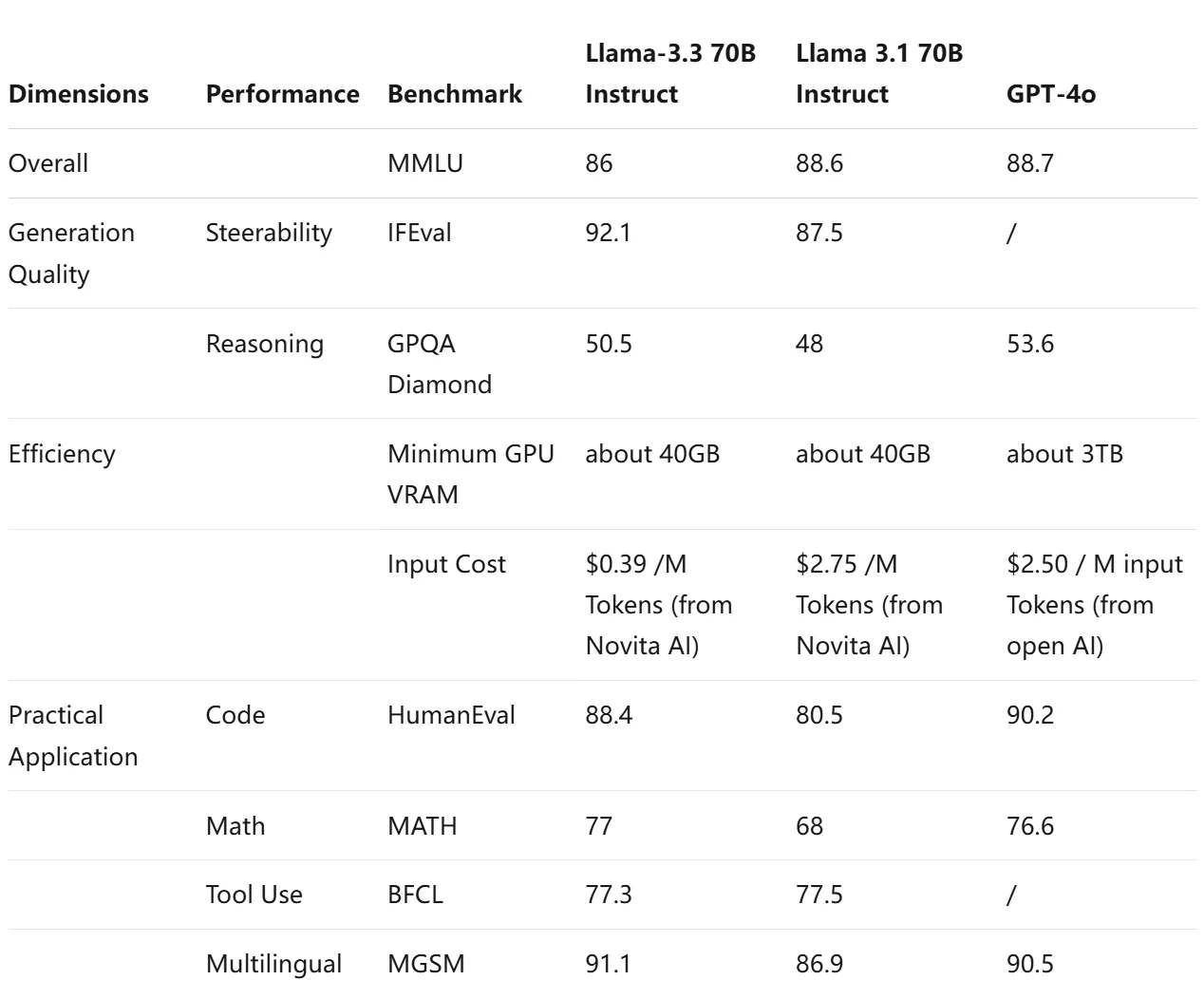
Insgesamt bieten diese Benchmarks wertvolle Einblicke, wie jedes Modell in verschiedenen Dimensionen des Sprachverständnisses und der Sprachgenerierung abschneidet, und helfen dabei, das am besten geeignete Modell für bestimmte Anwendungen zu identifizieren.
Highlights, in denen LLaMA 3.3 herausragt
| Vorteil | Beschreibung | Anwendungsbereiche |
|---|---|---|
| Instruktionsbefolgung | Erzielt 92,1 im IFEval und zeigt die Fähigkeit, komplexe Anweisungen effektiv zu befolgen. | KI-Assistenten, automatisierter Kundensupport, interaktive Anwendungen. |
| Hohe Leistung beim Codieren | Erreicht eine Bestehensquote von 88,4 % im HumanEval-Coding-Benchmark, was auf starke Codegenerierungsfähigkeiten hinweist. | KI-gestützte Programmierwerkzeuge, Softwareentwicklungsumgebungen. |
| Mehrsprachige Unterstützung | Unterstützt mehrere Sprachen mit einem Wert von 91,1 im MGSM und erleichtert die Kommunikation über verschiedene Märkte hinweg. | Globale Anwendungen, Übersetzungsdienste, mehrsprachige Chatbots. |
| Effiziente Ressourcennutzung | Benötigt nur etwa 40 GB GPU-VRAM, sodass es auf mittlerer Hardware ausgeführt werden kann. | Entwicklung für Benutzer mit begrenzten Rechenressourcen oder Consumer-Hardware. |
| Kosteneffizienz | Niedrige Tokenkosten (z. B. 0,10 $ pro Million Eingabe-Tokens), was die Bereitstellung erschwinglich macht. | Startups, kleine Unternehmen, budgetbewusste Projekte. |
Basierend auf den Vorteilen des Llama 3.3 Modells eignet es sich besonders gut für kleine Unternehmen und Entwickler. Im Folgenden nehmen wir Novita AI als Beispiel, um zu zeigen, wie Sie Llama 3.3 über die einfache API-Methode testen können.
Wie kann man LLaMA 3.3 schnell über Novita AI testen?
Schritt 1: Einloggen und auf die Modellbibliothek zugreifen
Melden Sie sich in Ihrem Konto an und klicken Sie auf die Schaltfläche Modellbibliothek.

Schritt 2: Wählen Sie Ihr Modell
Durchsuchen Sie die verfügbaren Optionen und wählen Sie das Modell aus, das Ihren Anforderungen entspricht.

Schritt 3: Starten Sie Ihre kostenlose Testversion
Beginnen Sie Ihre kostenlose Testversion, um die Fähigkeiten des ausgewählten Modells zu erkunden.

Schritt 4: Holen Sie sich Ihren API-Schlüssel
Zur Authentifizierung mit der API stellen wir Ihnen einen neuen API-Schlüssel zur Verfügung. Gehen Sie auf die Seite „Einstellungen“, dort können Sie den API-Schlüssel wie im Bild gezeigt kopieren.

Schritt 5: Installieren Sie die API
Installieren Sie die API mit dem für Ihre Programmiersprache spezifischen Paketmanager.

Importieren Sie nach der Installation die erforderlichen Bibliotheken in Ihre Entwicklungsumgebung. Initialisieren Sie die API mit Ihrem API-Schlüssel, um mit der Interaktion mit Novita AI LLM zu beginnen. Dies ist ein Beispiel für die Verwendung der Chat Completions API für Python-Benutzer.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
# Holen Sie sich den Novita AI API-Schlüssel, indem Sie auf https://novita.ai/docs/get-started/quickstart.html#_2-manage-api-key verweisen.
api_key="<IHR Novita AI API-Schlüssel>",
)
model = "meta-llama/llama-3.3-70b-instruct"
stream = True # oder False
max_tokens = 512
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": "Verhalten Sie sich wie ein hilfreicher Assistent.",
},
{
"role": "user",
"content": "Hallo!",
}
],
stream=stream,
max_tokens=max_tokens,
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "")
else:
print(chat_completion_res.choices[0].message.content)
Nach der Registrierung erhalten Sie von Novita AI ein Guthaben von 0,50 $, um loszulegen!
Wenn das kostenlose Guthaben aufgebraucht ist, können Sie bezahlen, um es weiter zu nutzen.
Fazit
Llama 3.3, entwickelt von Meta, ist ein leistungsstarkes Sprachmodell mit 70 Milliarden Parametern, das sich durch Instruktionsbefolgung, Codierung und mehrsprachige Unterstützung auszeichnet. Es bietet Kosteneffizienz, senkt die Betriebskosten und liefert gleichzeitig qualitativ hochwertige Ergebnisse. Novita AI bietet einen einfachen Zugang zu Llama 3.3 über eine API, sodass Entwickler es für Aufgaben in Anwendungen integrieren können.
Häufig gestellte Fragen
Novita AI ist die All-in-One-Cloud-Plattform, die Ihre KI-Ambitionen unterstützt. Integrierte APIs, serverlos, GPU-Instanz – die kostengünstigen Tools, die Sie brauchen. Vermeiden Sie Infrastruktur, starten Sie kostenlos und machen Sie Ihre KI-Vision zur Realität.



