

Ключевые моменты
LLaMA 3.3, разработанная Meta, — это мощная языковая модель с впечатляющими возможностями.
Она набирает 92,1 балла в IFEval за отличное следование инструкциям, 88,4% в HumanEval за качественную генерацию кода и 91,1 в MGSM за решение многоязычных математических задач.
Благодаря эффективному использованию ресурсов (40 ГБ видеопамяти GPU) и низкой стоимости токенов ($0,39 за миллион токенов от Novita AI) модель идеально подходит для стартапов и малого бизнеса.
Разработчики могут легко получить доступ к LLaMA 3.3 через Novita AI. Просто зарегистрируйтесь для бесплатного пробного периода, получите API-ключ и интегрируйте модель в свои приложения, раскрывая весь её потенциал для языковых задач.
LLaMA 3.3 — это последний прорыв Meta в области больших языковых моделей, предлагающий значительные улучшения производительности и эффективности по сравнению с предыдущими версиями. Несмотря на меньшее количество параметров, модель LLaMA 3.3 70B превосходит многие традиционные крупномасштабные модели, включая LLaMA 3.1 405B, по нескольким ключевым бенчмаркам. Эта оптимизация обеспечивает идеальный баланс между вычислительной эффективностью и вычислительной мощностью, снижая требования к оборудованию при сохранении высокой производительности. В этой статье представлен углублённый анализ производительности LLaMA 3.3 по бенчмаркам в нескольких ключевых измерениях.
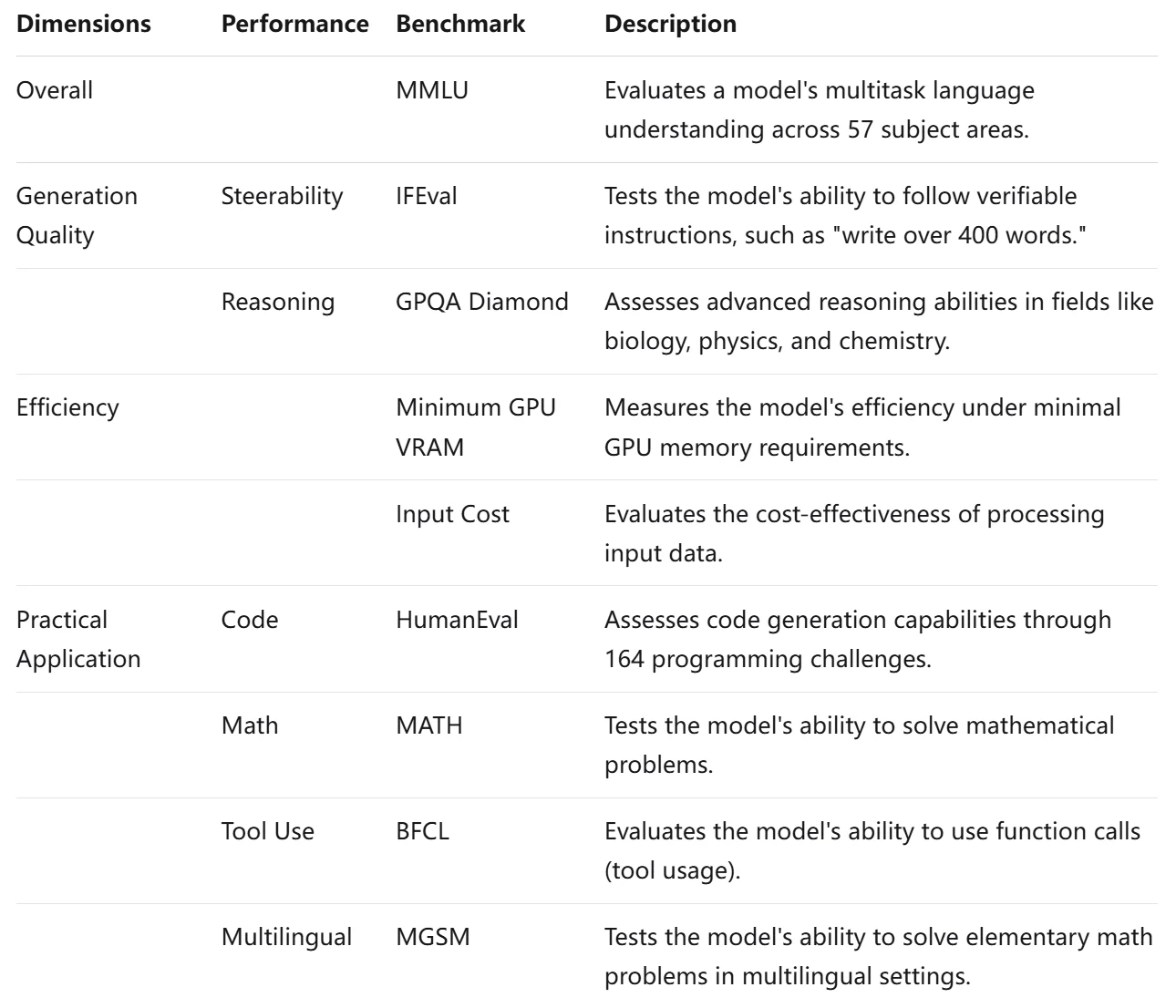
Обзор метрик бенчмарков для LLM
При оценке больших языковых моделей (LLM) используются четыре критически важных бенчмарка, позволяющих оценить их общую производительность: Общая, Качество генерации, Эффективность и Практическое применение. Вместе эти стандарты дают всестороннее представление об эффективности и удобстве использования LLM.
Общее измерение
Можно с уверенностью сказать, что MMLU является относительно комплексным бенчмарком для описания возможностей модели по сравнению с другими стандартами тестирования. Однако важно отметить, что ни один отдельный бенчмарк не может охватить все аспекты производительности модели. MMLU часто используется в сочетании с другими бенчмарками для более полной оценки.
Что такое MMLU?
MMLU (Massive Multitask Language Understanding) — это комплексный бенчмарк, предназначенный для оценки производительности AI-языковых моделей в широком спектре предметов и задач. Он оценивает многозадачные способности модели, общие знания и навыки решения проблем в различных областях.
Содержание проверки:
- Многодисциплинарные знания
MMLU охватывает 57 различных предметных областей, включая STEM, гуманитарные науки, социальные науки и профессиональные сферы. - Способность к рассуждению
Оценивает способность модели рассуждать и решать проблемы с помощью разнообразных типов вопросов. - Понимание языка
Тестирует способность модели понимать и обрабатывать язык в различных контекстах. - Многозадачная обработка
Оценивает способность модели переключаться между несколькими задачами и обобщать знания.
Методы проверки:
MMLU оценивает языковые модели с помощью структурированного рабочего процесса, который начинается с предъявления вопросов с множественным выбором по 57 различным предметам. Модели тестируются в условиях zero-shot и few-shot, имитирующих реальные сценарии. Их производительность измеряется с помощью оценки точности, которая определяет долю правильных ответов. Наконец, вычисляется итоговая оценка путём усреднения точности по всем областям, что даёт результат от 0 до 1, обобщающий общие возможности модели.
Качество генерации
Качество генерации включает в себя связность, релевантность и беглость текста, создаваемого моделью. Высокое качество генерации критически важно для приложений, связанных с созданием контента, диалоговыми системами и другими.
Двумя значимыми бенчмарками в этой области являются IFEval и GPQA.
Что такое IFEval?
IFEval (Instruction-Following Evaluation) — это бенчмарк, предназначенный для оценки способности языковой модели точно понимать и выполнять инструкции. IFEval фокусируется на оценке того, насколько хорошо языковая модель может понимать и выполнять инструкции, данные на естественном языке. Этот бенчмарк крайне важен для обеспечения того, чтобы модели могли эффективно помогать пользователям в реальных сценариях, где следование инструкциям необходимо.
Пример рабочего процесса
- Генерация инструкций: Создание промптов, содержащих одну или несколько проверяемых инструкций из набора 25 предопределённых типов, например, «напишите более 400 слов» или «упомяните ключевое слово AI как минимум три раза».
- Ответ модели: Языковая модель генерирует ответ на основе заданных инструкций.
- Метрики оценки:
- Строгая метрика: Проверка, строго ли выходные данные модели соответствуют инструкциям, с использованием точного сравнения строк.
- Нестрогая метрика: Оценка выходных данных после применения различных преобразований для обеспечения гибкости в формате и формулировках, что снижает количество ложноположительных результатов.
- Оценка: Расчёт точности на основе процента правильно выполненных инструкций, как на уровне промпта, так и на уровне отдельных инструкций.
- Выходные данные: Сбор результатов для получения информации о способностях модели следовать инструкциям, с выделением сильных и слабых сторон.
Что такое GPQA?
GPQA (General Purpose Question Answering) — это бенчмарк общего назначения для вопросно-ответных систем. Этот бенчмарк особенно полезен для оценки способности модели понимать и генерировать точные ответы на различные типы запросов, что делает его критически важной метрикой для таких приложений, как виртуальные ассистенты, чат-боты и системы поиска информации.
Пример рабочего процесса, схожий с IFEval, но с некоторыми отличиями
- Фокус на сложности:
- IFEval: Концентрируется на способности модели следовать различным инструкциям на естественном языке.
- GPQA: Ориентирован на вопросы высокой сложности, которые являются сложными даже для экспертов, и гарантирует, что на них нельзя легко ответить с помощью поиска в интернете.
- Разработка вопросов:
- IFEval: В первую очередь оценивает, насколько хорошо модели выполняют заданные инструкции, без тщательной валидации.
- GPQA: Включает создание и валидацию сложных вопросов экспертами.
Эффективность
Эффективность в контексте LLM включает в себя как совместимость выполнения, так и стоимость ввода. Минимальный объём видеопамяти GPU и Стоимость ввода — играют решающую роль в определении того, насколько эффективно работает большая языковая модель (LLM), такая как LLaMA 3.3. Ниже приводится подробное объяснение каждой метрики и стандартов, используемых для их расчёта:
Что такое минимальный объём видеопамяти GPU (Minimum GPU VRAM)?
Минимальный объём видеопамяти GPU — это минимальное количество видеопамяти (VRAM), необходимое для эффективной работы модели. Видеопамять необходима для хранения параметров модели, а также промежуточных вычислений во время инференса и обучения. Меньший минимальный объём видеопамяти GPU означает большую доступность для разработчиков и организаций, которые хотят использовать возможности AI без непомерных затрат.
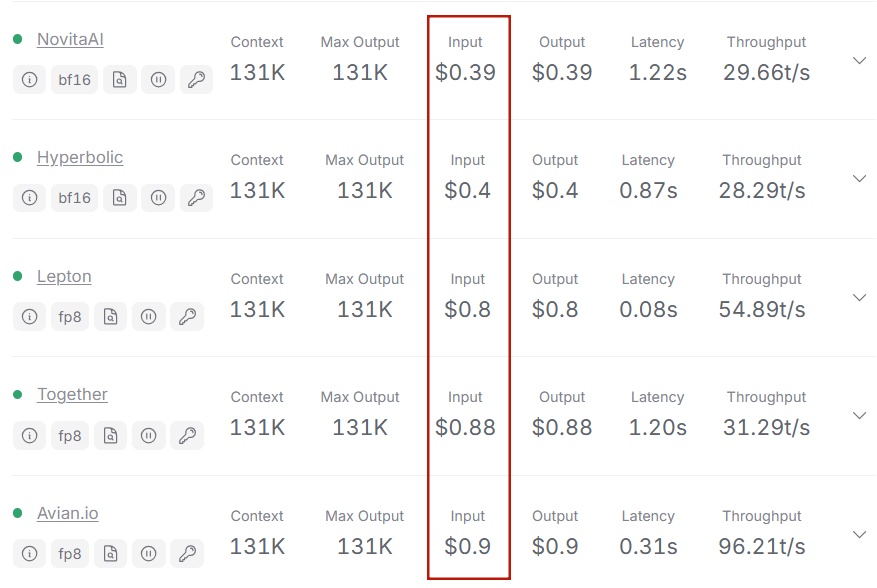
Что такое стоимость ввода (на примере Novita AI)?
Стоимость ввода относится к расходам, связанным с обработкой входных данных, измеряемым в использованных вычислительных ресурсах. Стоимость ввода обычно рассчитывается на основе сценариев реального использования и может варьироваться в зависимости от поставщика услуг. Например, стоимость может быть получена из использования API.
Практическое применение
Метрики практического применения оценивают, насколько хорошо модель справляется с реальными задачами. Ключевые бенчмарки в этой области включают:
| Бенчмарк | Значение |
|---|---|
| HumanEval | Бенчмарк для оценки способностей языковых моделей к генерации кода. |
| MATH | Бенчмарк, направленный на оценку способностей языковых моделей к решению математических задач. |
| BFCL v2 | Бенчмарк для оценки способностей больших языковых моделей к вызову функций. |
| MGSM | Бенчмарк, предназначенный для оценки многоязычного решения задач в области элементарной математики. |
Теперь, когда мы изучили всестороннюю и универсальную систему бенчмарков для LLM, давайте рассмотрим производительность LLaMA 3.3 по этим измерениям!
Обзор бенчмарков для Llama 3.3 в сравнении с Llama 3.1 70B Instruct и GPT-4o
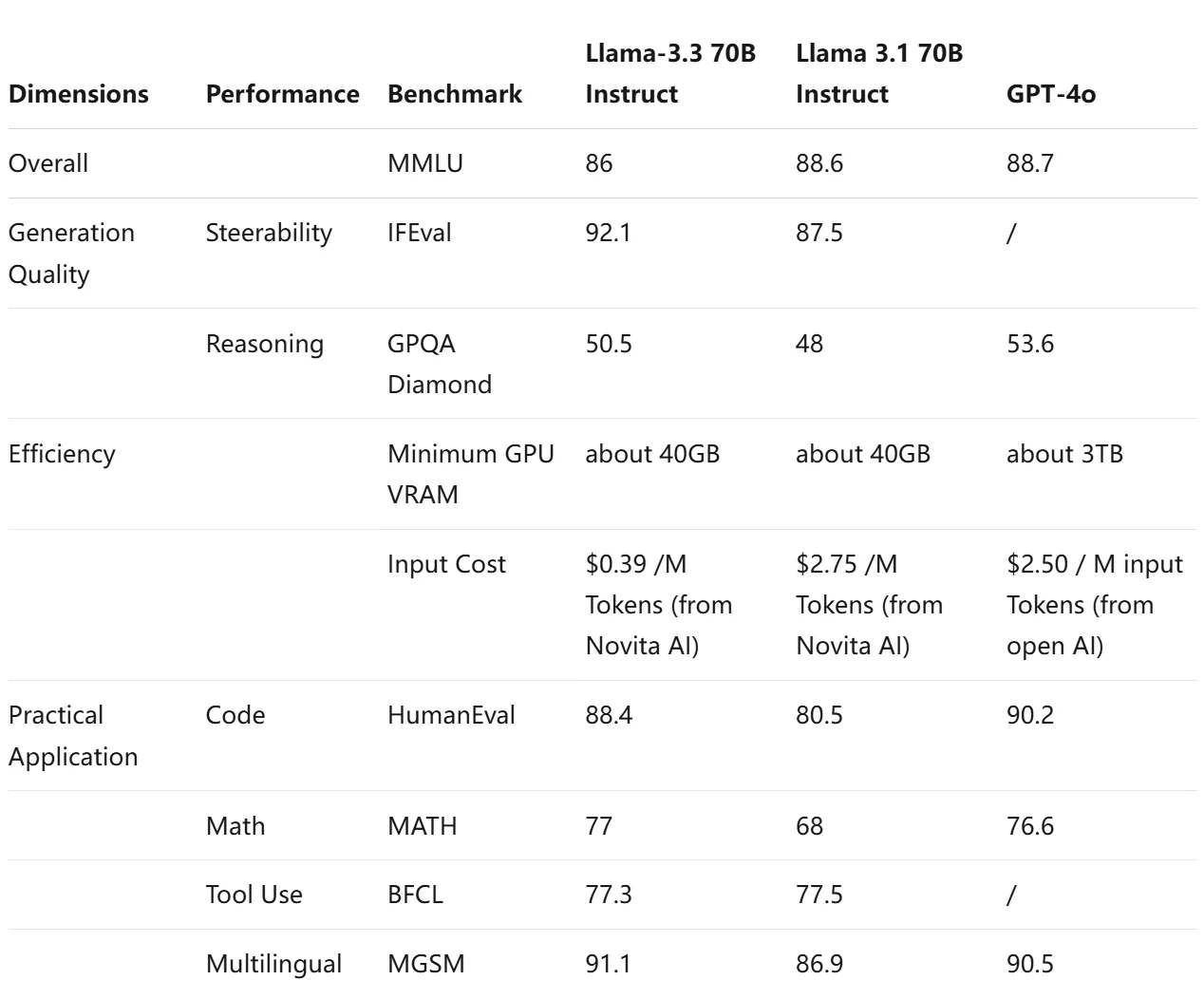
В целом, эти бенчмарки дают ценную информацию о том, как каждая модель работает по различным аспектам понимания и генерации языка, помогая выбрать наиболее подходящую модель для конкретных приложений.
Сильные стороны LLaMA 3.3
| Преимущество | Описание | Области применения |
|---|---|---|
| Следование инструкциям | Набирает 92,1 балла в IFEval, демонстрируя способность эффективно следовать сложным инструкциям. | AI-ассистенты, автоматизированная поддержка клиентов, интерактивные приложения. |
| Высокая производительность в кодировании | Достигает 88,4% успешных проходов в бенчмарке HumanEval, что указывает на мощные возможности генерации кода. | Инструменты AI-помощи программистам, среды разработки ПО. |
| Многоязычная поддержка | Поддерживает несколько языков с результатом 91,1 балла в MGSM, что облегчает общение на различных рынках. | Глобальные приложения, сервисы перевода, многоязычные чат-боты. |
| Эффективное использование ресурсов | Требует лишь около 40 ГБ видеопамяти GPU, что позволяет запускать модель на оборудовании среднего уровня. | Разработка для пользователей с ограниченными вычислительными ресурсами или оборудованием потребительского класса. |
| Экономическая эффективность | Низкая стоимость токенов (например, $0,10 за миллион входных токенов), что делает развёртывание доступным. | Стартапы, малый бизнес, проекты с ограниченным бюджетом. |
Основываясь на преимуществах модели Llama 3.3, она особенно хорошо подходит для малого бизнеса и разработчиков. Поэтому далее мы на примере Novita AI расскажем, как можно попробовать Llama 3.3 с помощью простого API-метода.
Как быстро опробовать LLaMA 3.3 через Novita AI?
Шаг 1: Войдите в систему и откройте библиотеку моделей
Войдите в свою учётную запись и нажмите кнопку Model Library.

Шаг 2: Выберите модель
Просмотрите доступные варианты и выберите модель, которая подходит для ваших задач.

Шаг 3: Начните бесплатный пробный период
Начните бесплатный пробный период, чтобы изучить возможности выбранной модели.

Шаг 4: Получите API-ключ
Для аутентификации в API мы предоставим вам новый API-ключ. Перейдите на страницу «Settings» и скопируйте API-ключ, как показано на изображении.

Шаг 5: Установите API
Установите API с помощью менеджера пакетов, специфичного для вашего языка программирования.

После установки импортируйте необходимые библиотеки в вашу среду разработки. Инициализируйте API с вашим API-ключом, чтобы начать взаимодействие с Novita AI LLM. Это пример использования chat completions API для пользователей Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
# Получите API-ключ Novita AI, обратившись к: https://novita.ai/docs/get-started/quickstart.html#_2-manage-api-key.
api_key="<YOUR Novita AI API Key>",
)
model = "meta-llama/llama-3.3-70b-instruct"
stream = True # or False
max_tokens = 512
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": "Act like you are a helpful assistant.",
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "")
else:
print(chat_completion_res.choices[0].message.content)
После регистрации Novita AI предоставляет кредит в размере $0,5, чтобы вы могли начать работу!
Если бесплатные кредиты закончатся, вы можете оплатить и продолжить использование.
Заключение
Llama 3.3, разработанная Meta, — это мощная языковая модель с 70 миллиардами параметров, превосходно справляющаяся со следованием инструкциям, кодированием и многоязычной поддержкой. Она обеспечивает экономическую эффективность, снижая операционные расходы и предоставляя высококачественные результаты. Novita AI предоставляет лёгкий доступ к Llama 3.3 через API, позволяя разработчикам интегрировать её в приложения для выполнения задач.
Часто задаваемые вопросы
Novita AI — это единая облачная платформа, которая расширяет ваши AI-амбиции. Интегрированные API, бессерверные вычисления, GPU-инстансы — все необходимые экономически эффективные инструменты. Устраните инфраструктурные сложности, начните бесплатно и воплотите своё AI-видение в реальность.



