

探索 Kimi K2 Thinking 的開發者很快就會遇到一個核心問題:它的萬億參數 MoE 架構與 256K 上下文視窗需要極高的 VRAM,使得本地部署成本高昂且困難。
本文將釐清 Kimi K2 Thinking 需要如此大量記憶體的原因,比較不同量化等級的 VRAM 需求,並提出 實惠的部署路徑——包含量化、卸載、雲端 GPU 策略與 API 使用方式。本文也提供簡潔的藍圖,協助開發者根據預算、硬體限制與專案目標選擇最適合的方法。
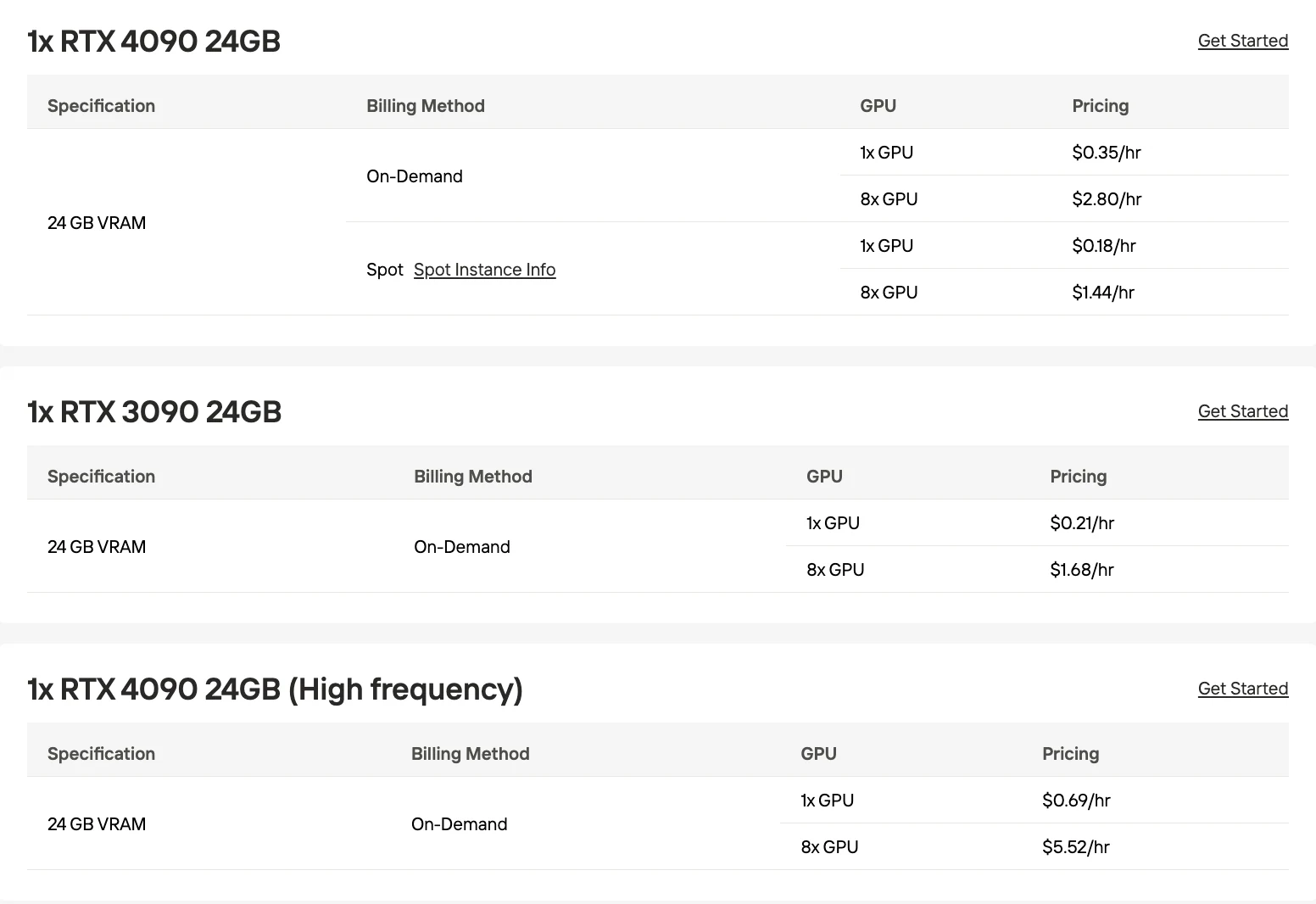
Kimi K2 Thinking VRAM 需求
FP16
| 上下文長度 | 所需 VRAM | GPU 配置 |
|---|---|---|
| 1024 tokens | 2009.74 GB | 132× RTX 4090 (24GB) 33× H100 (80GB) 28× M3 Max (128GB) |
| 256,000 tokens | 2901.64 GB | 208× RTX 4090 (24GB) 49× H100 (80GB) 46× M3 Max (128GB) |
INT8
| 上下文長度 | 所需 VRAM | GPU 配置 |
|---|---|---|
| 1024 tokens | 1008.85 GB | 58× RTX 4090 (24GB) 15× H100 (80GB) 12× M3 Max (128GB) |
| 256,000 tokens | 1677.77 GB | 106× RTX 4090 (24GB) 27× H100 (80GB) 23× M3 Max (128GB) |
INT4 / Ollama
| 上下文長度 | 所需 VRAM | GPU 配置 |
|---|---|---|
| 1024 tokens | 508.40 GB | 27× RTX 4090 (24GB) 8× H100 (80GB) 6× M3 Max (128GB) |
| 256,000 tokens | 1065.84 GB | 62× RTX 4090 (24GB) 16× H100 (80GB) 13× M3 Max (128GB) |
為什麼 Kimi K2 Thinking 需要大量 VRAM?
模型概覽
- 模型系列: Kimi K2 → Kimi K2 Thinking
- 活躍參數數: 1T
- 上下文長度: 256,000 tokens
- 模态: 文字
- 架構: 混合專家(MoE)
- 授權: 修改版 MIT
- 發布日期: 2025 年 11 月 7 日
Kimi K2 Thinking 的 MoE 系統每次前向傳播都會載入大量專家,大幅增加記憶體佔用、KV 快取擴展與計算開銷。
混合專家架構:
- 專家總數: 384 個
- 每個 token 活躍的專家數: 8 個
- 這使得記憶體使用量遠高於密集模型,因為必須同時載入多個專家區塊的權重。
專家參數量:
- 每個專家集的參數量: 320 億(專家參數總量)
- 高維度的專家圖層需要大量的記憶體頻寬。
256K 上下文:
- KV 快取會隨上下文長度線性擴展。
- 在 256K tokens 的情況下,即使使用低位元量化,快取本身就會佔據大部分 VRAM。
萬億參數活躍規模:
- 推理過程中的 1T 活躍參數 意味著即使量化後的版本仍然非常龐大。
- 沒有數百張 GPU 幾乎無法運行 FP16 版本。
如何以最低成本在本地運行 Kimi K2 Thinking?
只有透過重度量化與完整卸載,才能本地運行 Kimi K2 Thinking。低成本部署取決於縮小模型規模,並將大部分權重推送到 RAM 或硬碟而非 VRAM。
若不想購買本地硬體,選擇低成本雲端 GPU 的話,Novita AI 提供雲端 GPU、搶占式實例與多種計費方案,這比直接購買大型 GPU 更划算。
https://www.youtube.com/watch?v=y6U36dO2jk0
一段 YouTube 演示展示了在極端量化與卸載的情況下,Kimi K2 Thinking 在 Mac Studio 上本地運行的情況。

Unsloth 提供的 1.8 位元動態量化能將這個 1T 參數的模型從 TB 級別縮小到大多數機器都能載入的尺寸——當然也有取捨!你可以在 Novita AI 的雲端 GPU 上部署這個模型,觀察 kimi k2 thinking 的效能,為你自己的業務做好準備!
Novita AI 的搶占式實例將提供以下服務:
- 1 小時保護期
- 最高 50% 的成本節省
- 1 小時提前中斷通知
只有符合以下條件時,你才能使用搶占式計算資源:
- 資料庫是 分散式且備份複寫 的
- 系統能 承受節點損失
- 工作負載是 非關鍵性 的,或僅用於 測試目的
Kimi K2 Thinking 在 Novita AI 上的部署指南
步驟 1:註冊帳號
透過我們的網站建立 Novita AI 帳號。註冊完成後,前往左側邊欄的「探索」板塊,查看我們提供的 GPU 方案,開始你的 AI 開發之旅。

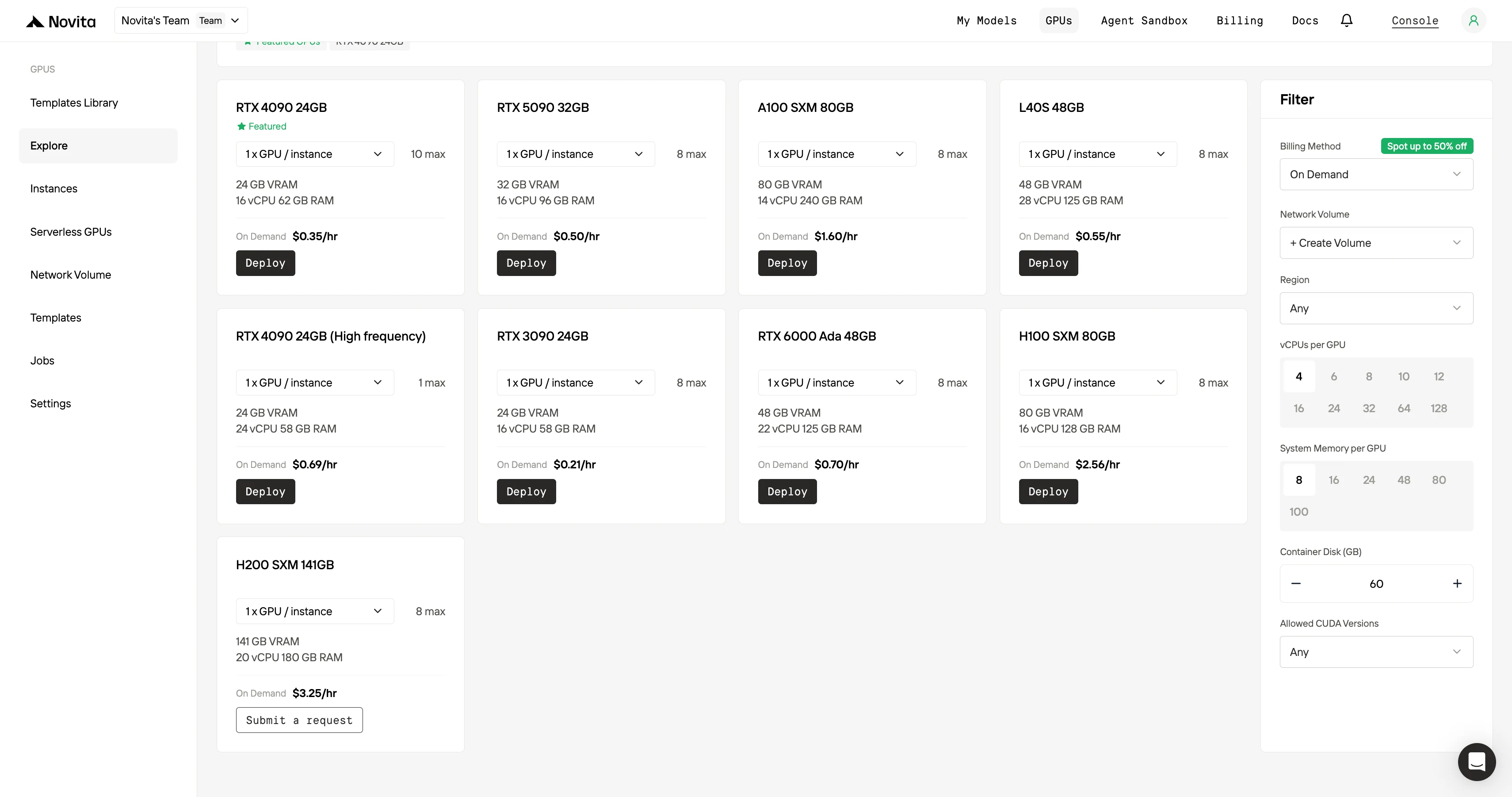
步驟 2:探索模板與 GPU 伺服器
根據你的專案需求選擇對應的模板,例如 PyTorch、TensorFlow 或 CUDA。接著選擇你偏好的 GPU 配置——可選方案包含強大的 L40S、RTX 4090 或 A100 SXM4,每款都有不同的 VRAM、RAM 與儲存規格。
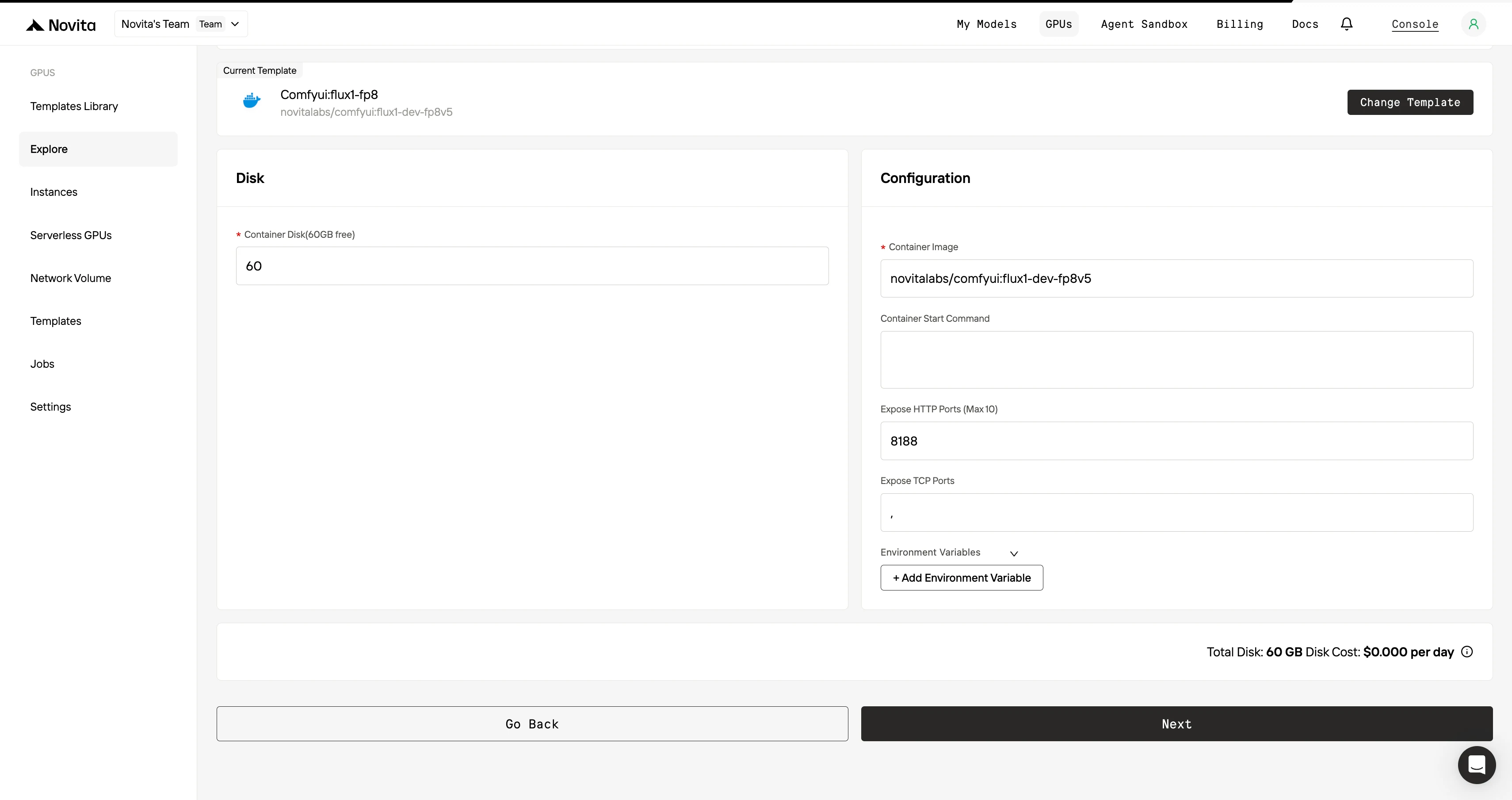
步驟 3:客製化你的部署
選擇你偏好的作業系統與配置選項來客製化你的環境,確保你的 AI 工作負載與開發需求能獲得最佳效能。
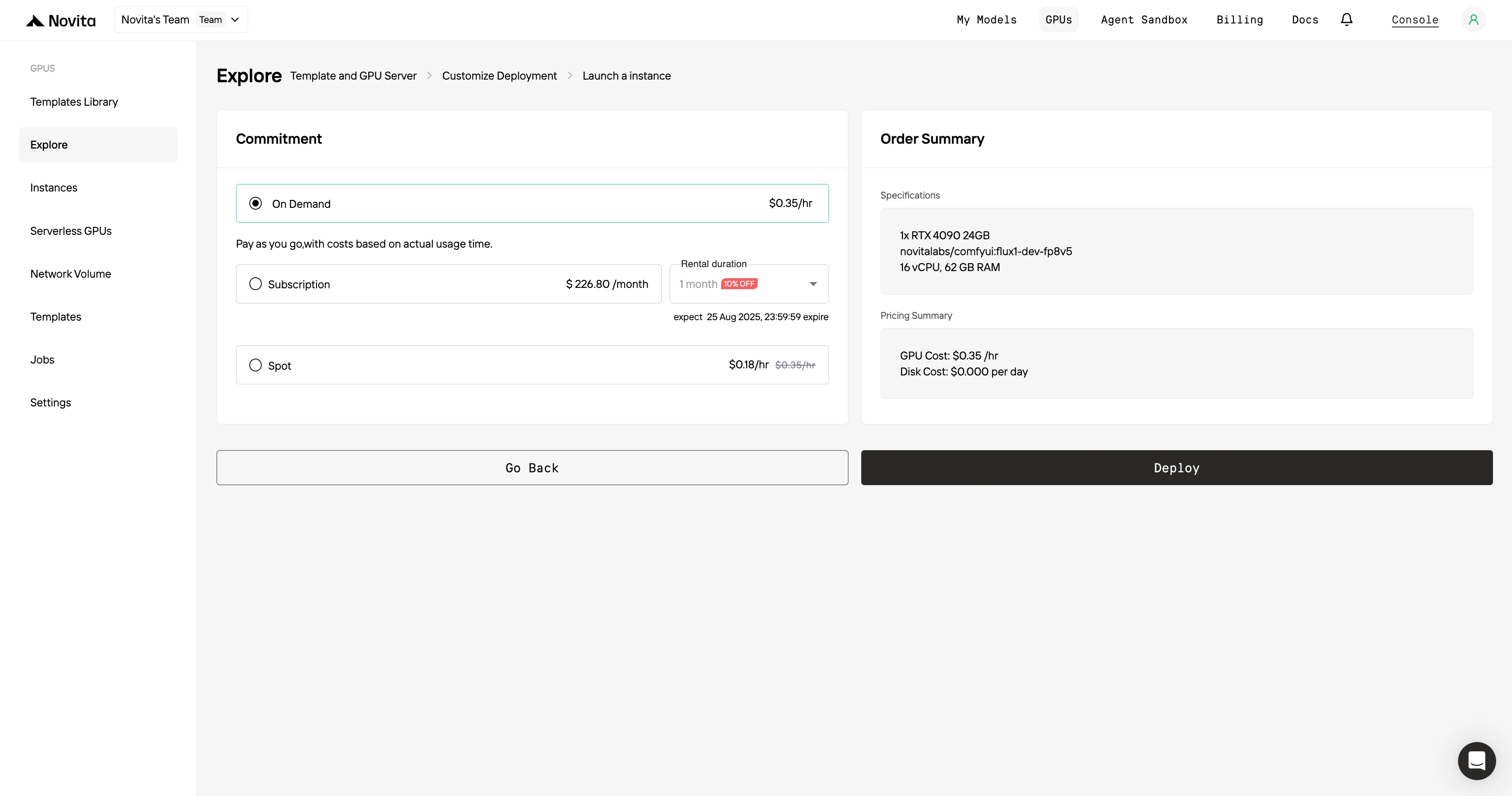
步驟 4:啟動實例
選擇「啟動實例」開始你的部署。你的高效能 GPU 環境將在幾分鐘內準備完成,讓你可以立刻開始機器學習、渲染或計算專案。
如何在部署中節省 Kimi K2 Thinking 的記憶體?
1. 選擇性 GPU 卸載
可以。你可以將路由器與注意力機制保留在 GPU 上,並使用正則表示式遮罩將 MoE FFN 專家卸載到 RAM/SSD。這在 llama.cpp 的 GGUF MoE 版本中可用。
2. 動態 2 位元量化(Q2-K-XL)
可以。Unsloth 有提供 Kimi K2 / K2 Thinking 的 Q2 與 1.8 位元量化模型,這些模型能大幅減少記憶體使用,同時保持高準確率。
3. KV 快取量化
可以。使用 --cache-type-k q4_1 與 --cache-type-v q4_1 能將 KV 快取記憶體減少約 4 倍,對 256K 上下文模型非常有效。
4. Flash Attention 與高吞吐量模式
如果你的構建版本支援 MoE + Flash Attention 就可以使用。這能減少啟動記憶體使用並提升速度。
5. 上下文截斷
可以。將歷史記錄縮短至 8K–16K tokens 能大幅降低 KV 記憶體使用,對 Kimi K2 Thinking 來說是必備技巧。
6. 批次處理
部分有效。它不會降低單次請求的 VRAM 使用,但能提升吞吐量
使用 Kimi K2 Thinking 的另一個有效方式:透過 API
Novita AI 提供具備 262K 上下文 的 Kimi K2 Thinking Instruct API,輸入費用為 $0.60/輸入,輸出費用為 $2.5/輸出,能充分發揮 Kimi K2 Thinking 在程式碼代理方面的潛力。
Novita AI
| 面向 | API | 本地 GPU | 雲端 GPU |
|---|---|---|---|
| 設置 | 即時 | 複雜 | 中等 |
| 維護成本 | 無 | 高 | 中等 |
| 成本 | 單次最高 | 大規模部署時最低 | 中等 |
| 擴展性 | 自動 | 困難 | 容易 |
| 隱私性 | 資料會傳出 | 完全本地 | 資料會傳出 |
| 自訂程度 | 最低 | 最高 | 高 |
| 最適合場景 | 快速啟動、中小規模、無基礎設施 | 大型穩定工作負載、最大隱私需求 | 大型/可變工作負載、自訂模型 |
步驟 1:登入你的帳號,點擊「模型庫」按鈕。

步驟 2:選擇你的模型
瀏覽所有可選方案,選擇最適合你需求的模型。
步驟 3:開始免費試用
開始免費試用,探索所選模型的能力。
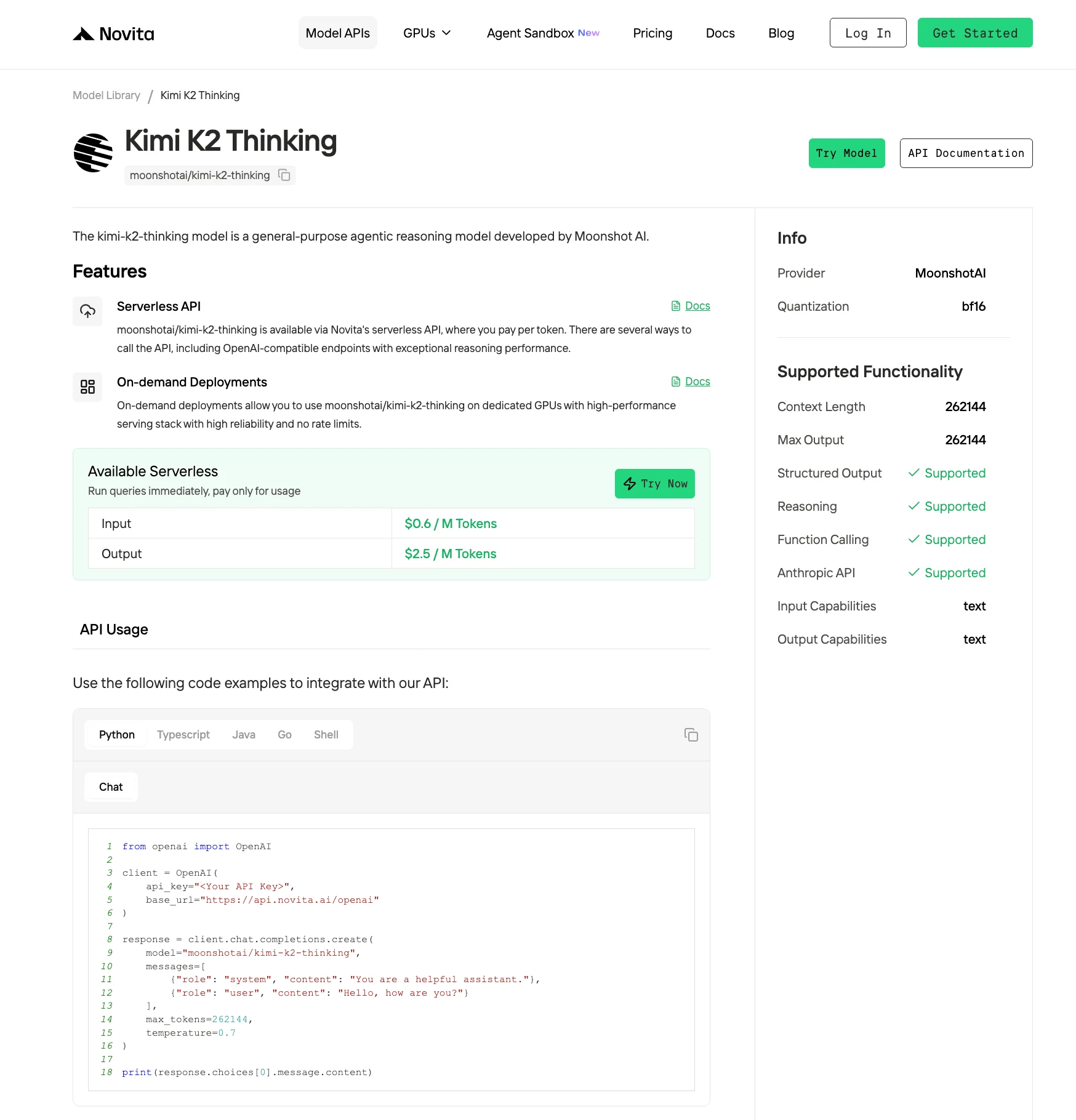
步驟 4:取得你的 API 金鑰
要進行 API 驗證,我們會提供你新的 API 金鑰。進入「設定」頁面後,你就可以按照圖片指示複製 API 金鑰。

步驟 5:安裝 API
使用對應程式語言的套件管理器安裝 API。
安裝完成後,將必要的函式庫匯入你的開發環境。使用你的 API 金鑰初始化 API,即可開始與 Novita AI LLM 互動。以下是一個給 Python 使用者的聊天完成 API 使用範例:
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="moonshotai/kimi-k2-thinking",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=262144,
temperature=0.7
)
print(response.choices[0].message.content)
Kimi K2 Thinking 的龐大記憶體佔用來自其 1T 活躍參數、MoE 架構與 256K KV 快取擴展。VRAM 需求範圍從約 500GB(INT4)到接近 3TB(FP16),遠超消費級 GPU 的能力。不過,透過重度量化、選擇性卸載、KV 快取壓縮與上下文控制,還是能實現有限的本地部署。雲端 GPU 與 Novita AI 的隨用隨付 API 是最容易取得且擴展性最高的替代方案。這些選項結合起來,讓業餘愛好者與生產環境工作負載都能在不需要購買大量硬體的情況下運行 Kimi K2 Thinking。
常見問題
為什麼 Kimi K2 Thinking 需要這麼大的 VRAM?
Kimi K2 Thinking 採用萬億參數的 MoE 架構,包含 384 個專家,每個 token 會啟動 8 個專家,再加上 256K 的上下文視窗。這些結構使得權重載入與 KV 快取記憶體的需求遠高於一般模型。
Kimi K2 Thinking 在 FP16 模式下需要多少 VRAM?
FP16 模式的 Kimi K2 Thinking 在 1K tokens 時需要約 2009GB VRAM,256K tokens 時需要約 2901GB VRAM,因此只有大型多 GPU 叢集能運行。
我可以在 24GB 的 GPU 上本地運行 Kimi K2 Thinking 嗎?
可以——但必須使用 Unsloth 的 1.8 位元量化版 Kimi K2 Thinking,並將所有 MoE 部分卸載到 RAM 或 SSD。預期速度會非常慢(每秒 1-2 個 token)。
Novita AI 是一個 AI 雲端平台,為開發者提供簡單的 API 來部署 AI 模型,同時也提供實惠且可靠的 GPU 雲端服務,用於建構與擴展 AI 應用。
推薦閱讀



