

Kimi K2 Thinking を探求する開発者は、すぐに一つの核心的な問題に直面します。兆パラメータのMoE設計と256Kコンテキストウィンドウが極端なVRAMを要求し、ローカルデプロイを高コストかつ困難にします。
本記事では、なぜKimi K2 Thinkingがこれほど多くのメモリを必要とするのかを明確にし、量子化レベルごとのVRAM要件を比較し、実用的で低コストなデプロイパス—量子化、オフローディング、クラウドGPU戦略、API利用などを提示します。予算、ハードウェアの制限、プロジェクトの目標に応じて適切な方法を選ぶための簡潔な設計図を提供します。
Kimi K2 ThinkingのVRAM要件
FP16
| コンテキストサイズ | 必要VRAM | GPU構成 |
|---|---|---|
| 1024トークン | 2009.74 GB | 132× RTX 4090 (24GB) 33× H100 (80GB) 28× M3 Max (128GB) |
| 256,000トークン | 2901.64 GB | 208× RTX 4090 (24GB) 49× H100 (80GB) 46× M3 Max (128GB) |
INT8
| コンテキストサイズ | 必要VRAM | GPU構成 |
|---|---|---|
| 1024トークン | 1008.85 GB | 58× RTX 4090 (24GB) 15× H100 (80GB) 12× M3 Max (128GB) |
| 256,000トークン | 1677.77 GB | 106× RTX 4090 (24GB) 27× H100 (80GB) 23× M3 Max (128GB) |
INT4 / Ollama
| コンテキストサイズ | 必要VRAM | GPU構成 |
|---|---|---|
| 1024トークン | 508.40 GB | 27× RTX 4090 (24GB) 8× H100 (80GB) 6× M3 Max (128GB) |
| 256,000トークン | 1065.84 GB | 62× RTX 4090 (24GB) 16× H100 (80GB) 13× M3 Max (128GB) |
なぜKimi K2 Thinkingは膨大なVRAMを必要とするのか?
モデル概要
- モデルファミリー: Kimi K2 → Kimi K2 Thinking
- アクティブパラメータ: 1T
- コンテキスト長: 256,000トークン
- モダリティ: テキスト
- アーキテクチャ: 混合エキスパート(MoE)
- ライセンス: 修正MIT
- リリース日: 2025年11月7日
Kimi K2 ThinkingのMoEシステムは、1フォワードパスで多くのエキスパートをロードするため、メモリフットプリント、KVキャッシュの拡大、計算オーバーヘッドが劇的に増加します。
混合エキスパート(MoE):
- 合計384のエキスパート
- トークンあたり8つのエキスパートがアクティブ
- これは、複数のエキスパートブロックが同時に重みをロードする必要があるため、高密度モデルと比較してメモリ使用量が倍増します。
エキスパートパラメータ数:
- エキスパートセットあたり32Bパラメータ(全エキスパートパラメータ)
- 高次元のエキスパート層は、広いメモリ帯域幅を必要とします。
256Kコンテキスト:
- KVキャッシュはコンテキスト長に比例して増加します。
- 256Kトークンでは、低ビット量子化でもキャッシュだけでVRAMを支配します。
兆パラメータのアクティブサイズ:
- 推論中に1Tのアクティブパラメータがあるため、量子化バージョンでも非常に大きくなります。
- FP16では、数百のGPUなしではホストするのはほぼ不可能です。
Kimi K2 Thinkingを最安でローカル実行する方法は?
Kimi K2 Thinkingをローカルで実行できるのは、強力な量子化と完全なオフローディングを行った場合のみです。低コストなデプロイは、モデルを縮小し、ほとんどの重みをVRAMではなくRAMまたはディスクに追いやることに依存します。
ローカルハードウェアではなく低コストのクラウドGPUを求める場合、Novita AIはクラウドGPU、スポットインスタンス、複数の料金階層を提供します。これにより、大型GPUを直接購入するよりも安価なパスが得られます。
https://www.youtube.com/watch?v=y6U36dO2jk0
YouTubeのデモでは、Kimi K2 Thinkingが極端な量子化とオフローディングのもとでMac Studio上でローカル実行されている様子が示されています。

Unslothは1.8ビットの動的量子化を提供し、1Tパラメータモデルをテラバイト規模からほとんどのマシンがロードできるサイズに削減しますが、トレードオフがあります!このモデルをNovita AIのクラウドGPUにデプロイして、kimi k2 thinkingのパフォーマンスを確認し、自社ビジネスに備えることができます!
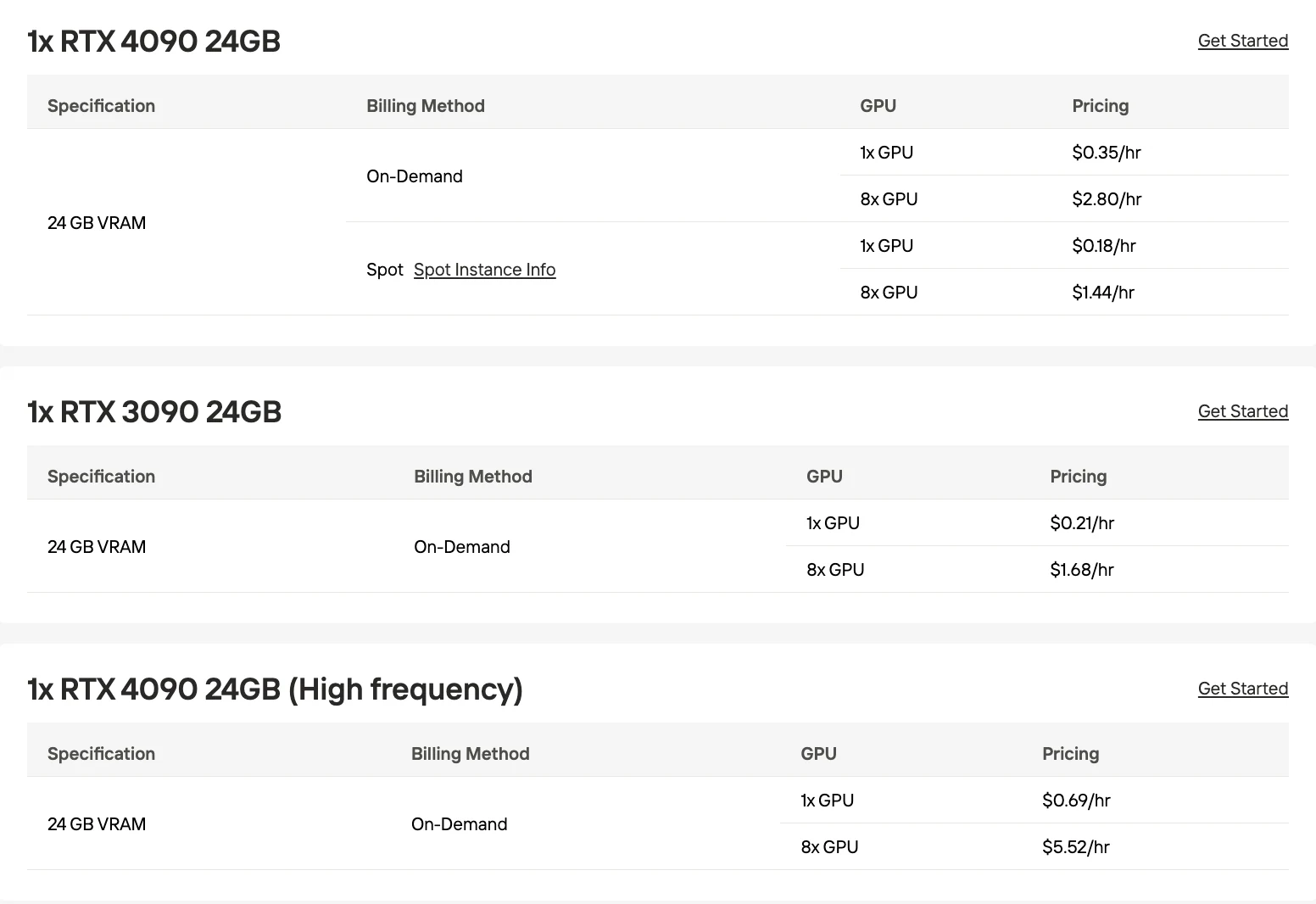
Novita AIのスポットインスタンスは以下の特徴で起動します:
- 1時間の保護期間
- 最大50%のコスト削減
- 1時間の事前中断通知
スポットインスタンスは以下の条件でのみ使用できます:
- データベースが分散かつレプリケートされている場合
- システムがノード損失に耐性がある場合
- ワークロードが重要でないまたはテスト目的の場合
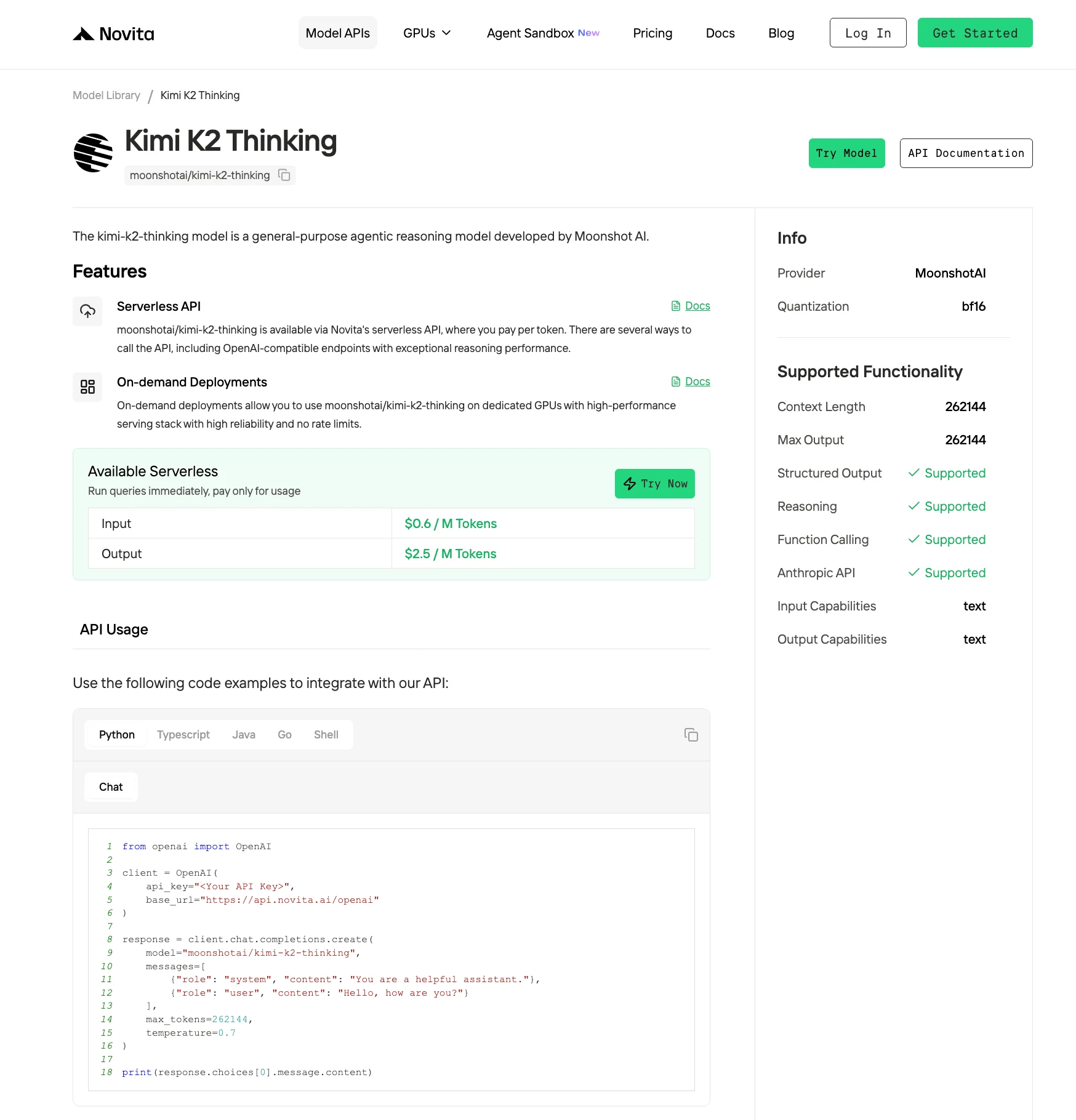
Novita AIでのKimi K2 Thinkingデプロイガイド
ステップ1:アカウント登録
ウェブサイトからNovita AIアカウントを作成します。登録後、左サイドバーの「Explore」セクションに移動し、GPU提供内容を確認してAI開発の旅を始めましょう。

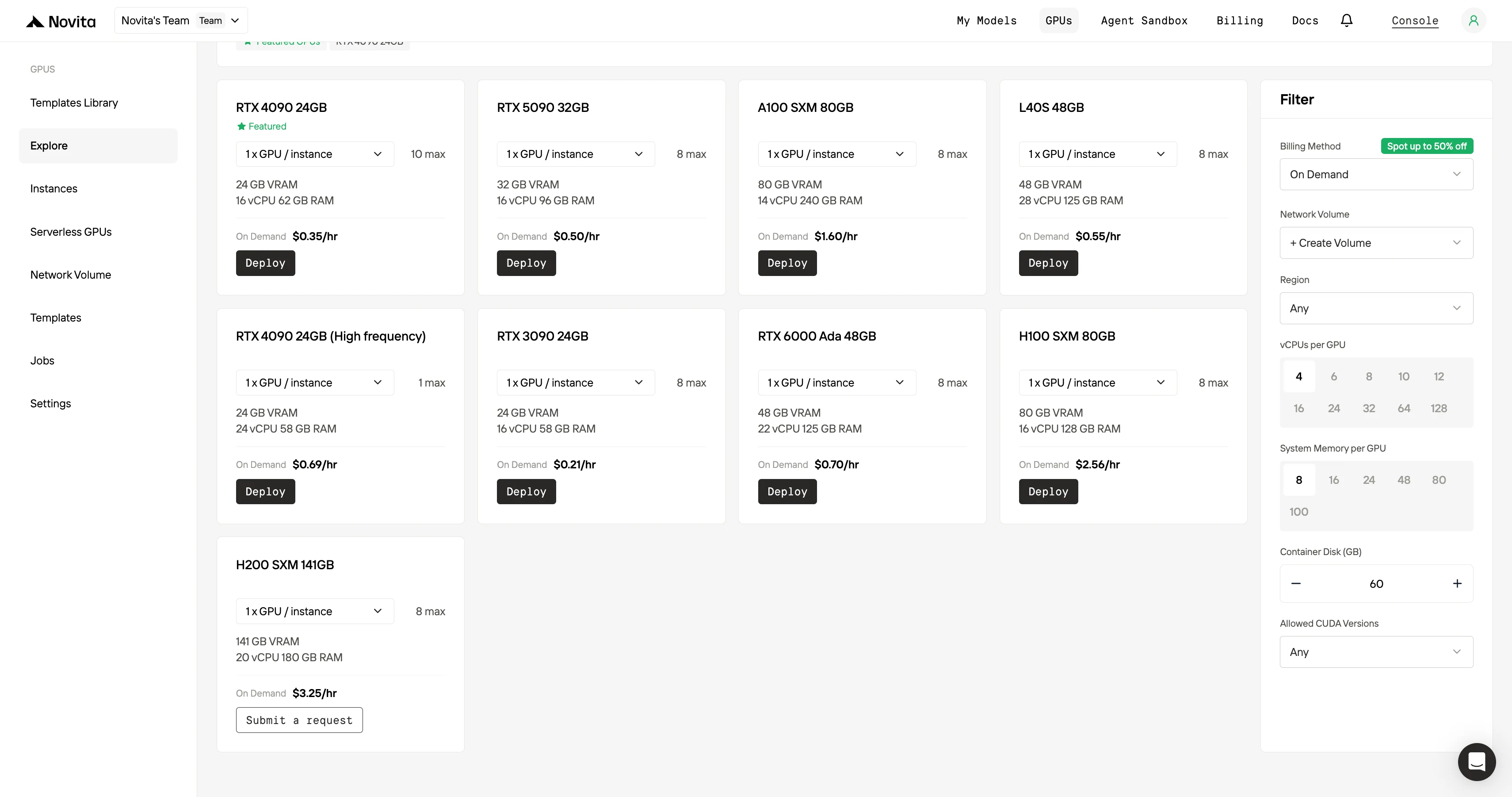
ステップ2:テンプレートとGPUサーバーの探索
プロジェクトのニーズに合ったPyTorch、TensorFlow、CUDAなどのテンプレートを選択します。次に、希望するGPU構成を選択します。オプションには、強力なL40S、RTX 4090、またはA100 SXM4があり、それぞれ異なるVRAM、RAM、ストレージ仕様があります。
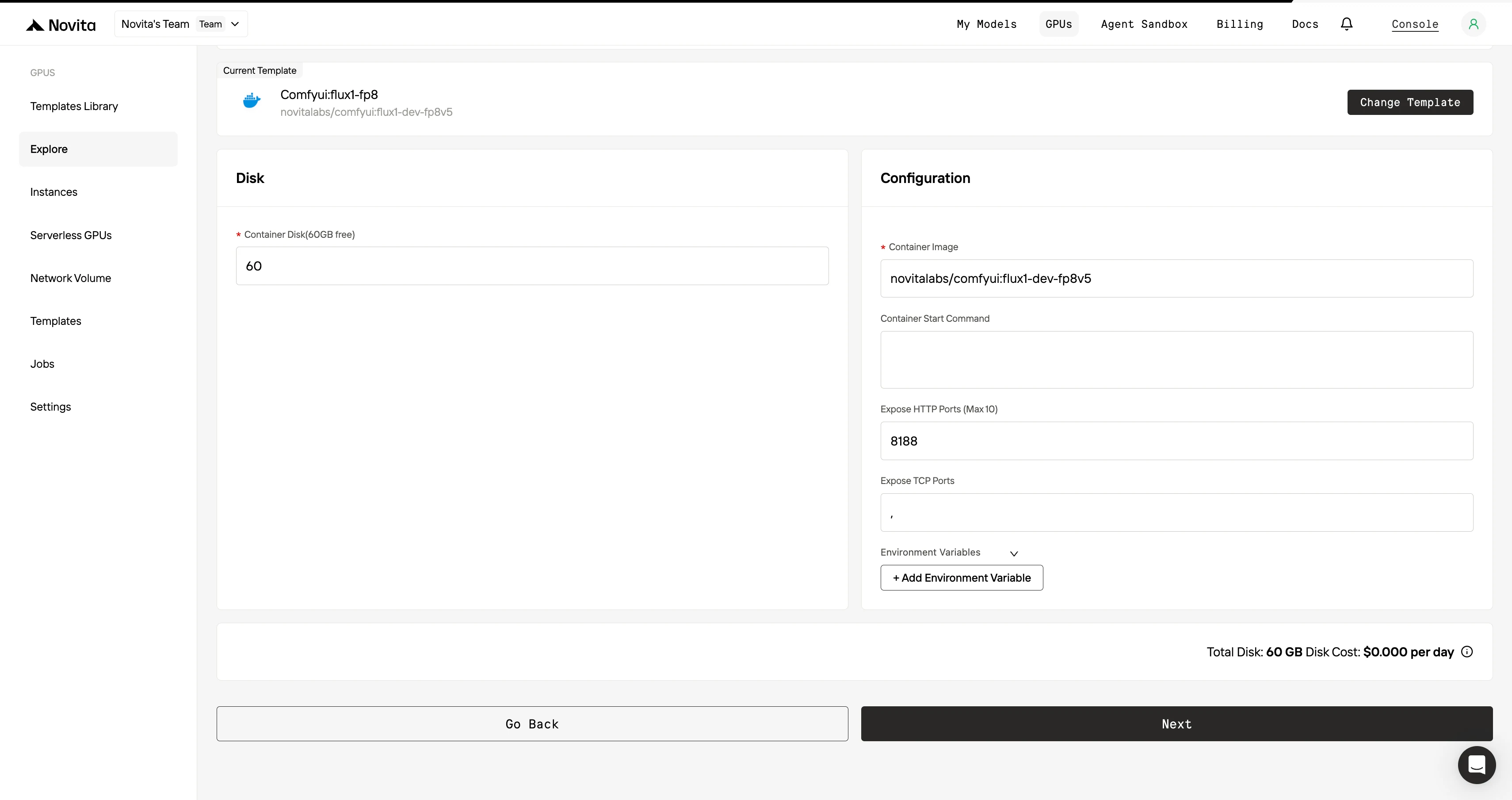
ステップ3:デプロイのカスタマイズ
好みのオペレーティングシステムと構成オプションを選択して環境をカスタマイズし、特定のAIワークロードと開発ニーズに対して最適なパフォーマンスを確保します。
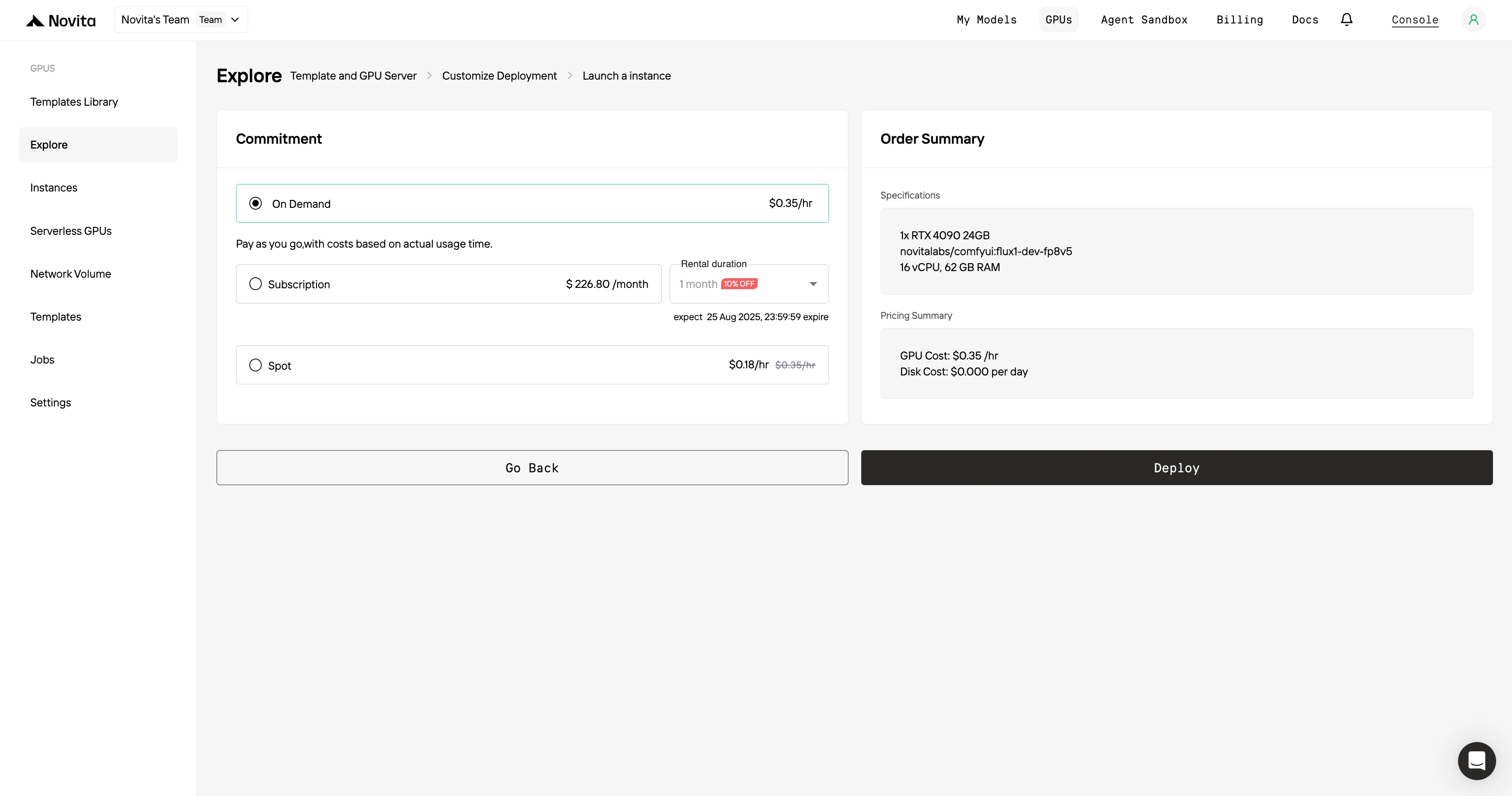
ステップ4:インスタンスの起動
「Launch Instance」を選択してデプロイを開始します。高性能GPU環境が数分で準備され、機械学習、レンダリング、計算プロジェクトをすぐに開始できます。
デプロイ時にKimi K2 Thinkingのメモリを節約する方法
1. 選択的GPUオフロード
可能。ルーターとアテンションをGPUに保持し、MoE FFNエキスパートをRAM/SSDにオフロードするために正規表現マスクを使用できます。llama.cppのGGUF MoEビルドで動作します。
2. 動的2ビット量子化(Q2-K-XL)
可能。UnslothはKimi K2 / K2 Thinking向けにQ2および1.8ビット量子化モデルを提供しています。これによりメモリが大幅に削減されつつ、高い精度が維持されます。
3. KVキャッシュ量子化
可能。--cache-type-k q4_1 および --cache-type-v q4_1 を使用すると、KVキャッシュメモリが約4倍削減されます。256Kコンテキストモデルに非常に効果的です。
4. Flash Attentionおよび高スループットモード
可能(ビルドがMoE + Flash Attentionをサポートしている場合)。アクティベーションメモリの削減と速度向上に役立ちます。
5. コンテキスト切り詰め
可能。履歴を8K~16Kトークンに減らすことで、KVメモリが大幅に低下します。Kimi K2 Thinkingでは不可欠です。
6. バッチ処理
部分的に有効。リクエストごとのVRAMは減りませんが、スループットは向上します。
Kimi K2 Thinkingを利用する別の効果的な方法:APIの活用
Novita AIは、262Kコンテキストを持つKimi K2 Thinking Instruct APIを提供しており、コストは**$0.60/入力**、$2.5/出力です。Kimi K2 Thinkingのコードエージェントとしての可能性を最大限に引き出す強力なサポートを提供します。
Novita AI
| 側面 | API | ローカルGPU | クラウドGPU |
|---|---|---|---|
| セットアップ | 即時 | 複雑 | 中程度 |
| メンテナンス | 不要 | 高い | 中程度 |
| コスト | 単価が最も高い | (大規模では)最も低い | 中程度 |
| スケーラビリティ | 自動 | 困難 | 簡単 |
| プライバシー | データが外部に送信 | 完全ローカル | データが外部に送信 |
| カスタマイズ | 最も少ない | 最も多い | 多い |
| 最適な用途 | 迅速な開始、小中規模、インフラ不要 | 大規模で安定したワークロード、最大のプライバシー | 大規模/変動するワークロード、カスタムモデル |
ステップ1:アカウントにログインし、モデルライブラリボタンをクリック。

ステップ2:モデルを選択
利用可能なオプションを参照し、ニーズに合ったモデルを選択します。
ステップ3:無料トライアルを開始
選択したモデルの機能を試すために、無料トライアルを開始します。
ステップ4:APIキーを取得
API認証のために、新しいAPIキーが提供されます。「設定」ページに移動し、画像のようにAPIキーをコピーします。

ステップ5:APIのインストール
プログラミング言語に応じたパッケージマネージャーを使用してAPIをインストールします。
インストール後、開発環境に必要なライブラリをインポートします。APIキーを使用してAPIを初期化し、Novita AI LLMとの対話を開始します。これはPythonユーザー向けのチャット補完APIの例です。
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="moonshotai/kimi-k2-thinking",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=262144,
temperature=0.7
)
print(response.choices[0].message.content)
Kimi K2 Thinkingの巨大なメモリフットプリントは、1Tのアクティブパラメータ、MoEアーキテクチャ、256KのKVキャッシュ拡張に起因します。VRAM要件は約500GB(INT4)から約3TB(FP16)まで及び、コンシューマーGPUの範囲をはるかに超えています。しかし、強力な量子化、選択的オフローディング、KVキャッシュ圧縮、コンテキスト制御により、限定的なローカルデプロイが可能です。クラウドGPUとNovita AIの従量課金APIは、最もアクセスしやすくスケーラブルな代替手段を提供します。これらのオプションを組み合わせることで、巨大なハードウェアを購入することなく、ホビイストから本番ワークロードまでKimi K2 Thinkingの実行が可能になります。
よくある質問
なぜKimi K2 Thinkingはこれほど大きなVRAMを必要とするのですか?
Kimi K2 Thinkingは、384のエキスパートとトークンあたり8つのアクティブエキスパートを持つ兆パラメータのMoEアーキテクチャに加え、256Kのコンテキストウィンドウを使用しています。これらの構造により、重みのロードとKVキャッシュメモリが標準的なモデルをはるかに超えて拡大します。
FP16でのKimi K2 Thinkingの必要VRAMはどれくらいですか?
FP16 Kimi K2 Thinkingは、1Kトークンで約2009GB、256Kトークンで約2901GBのVRAMを必要とし、大規模なマルチGPUクラスターでのみ実現可能です。
24GB GPUでKimi K2 Thinkingをローカル実行できますか?
可能です—ただし、Unslothの1.8ビット量子化Kimi K2 Thinkingと、RAMまたはSSDへの完全なMoEオフローディングが必要です。非常に遅い速度(1–2トークン/秒)を覚悟してください。
Novita AI は、開発者がシンプルなAPIを使用してAIモデルを簡単にデプロイできるAIクラウドプラットフォームであり、構築とスケーリングのための手頃で信頼性の高いGPUクラウドも提供しています。
おすすめの記事



