

Разработчики, которые пробуют работать с Kimi K2 Thinking, быстро сталкиваются с основной проблемой: его архитектура MoE с триллионом параметров и контекстное окно на 256K токенов требуют огромного объема VRAM, что делает локальное развертывание дорогим и сложным.
В этой статье мы разбираем, почему Kimi K2 Thinking требует так много памяти, сравниваем потребности в VRAM для разных уровней квантования и представляем практические недорогие способы развертывания — включая квантование, выгрузку на внешние носители, стратегии работы с облачными GPU и использование API. Мы даем краткое руководство по выбору подходящего метода в зависимости от бюджета, ограничений оборудования и целей проекта.
Требования к VRAM для Kimi K2 Thinking
FP16
| Размер контекста | Требуемый объем VRAM | Конфигурация GPU |
|---|---|---|
| 1024 токена | 2009.74 ГБ | 132× RTX 4090 (24ГБ) 33× H100 (80ГБ) 28× M3 Max (128ГБ) |
| 256 000 токенов | 2901.64 ГБ | 208× RTX 4090 (24ГБ) 49× H100 (80ГБ) 46× M3 Max (128ГБ) |
INT8
| Размер контекста | Требуемый объем VRAM | Конфигурация GPU |
|---|---|---|
| 1024 токена | 1008.85 ГБ | 58× RTX 4090 (24ГБ) 15× H100 (80ГБ) 12× M3 Max (128ГБ) |
| 256 000 токенов | 1677.77 ГБ | 106× RTX 4090 (24ГБ) 27× H100 (80ГБ) 23× M3 Max (128ГБ) |
INT4 / Ollama
| Размер контекста | Требуемый объем VRAM | Конфигурация GPU |
|---|---|---|
| 1024 токена | 508.40 ГБ | 27× RTX 4090 (24ГБ) 8× H100 (80ГБ) 6× M3 Max (128ГБ) |
| 256 000 токенов | 1065.84 ГБ | 62× RTX 4090 (24ГБ) 16× H100 (80ГБ) 13× M3 Max (128ГБ) |
Почему Kimi K2 Thinking требует огромного объема VRAM?
Обзор модели
- Семейство моделей: Kimi K2 → Kimi K2 Thinking
- Активные параметры: 1T
- Длина контекста: 256 000 токенов
- Модальность: Текст
- Архитектура: Смесь экспертов (MoE)
- Лицензия: Модифицированная MIT
- Дата релиза: 7 ноября 2025 г.
Система MoE в Kimi K2 Thinking загружает множество экспертов за один проход прямого распространения, что значительно увеличивает объем занимаемой памяти, размер KV-кэша и вычислительные затраты.
Смесь экспертов:
- Всего экспертов: 384
- Активных экспертов на токен: 8
- Это увеличивает потребление памяти по сравнению с плотными моделями, поскольку одновременно должны загружаться веса нескольких блоков экспертов.
Количество параметров на эксперта:
- 32B параметров на набор экспертов (общее количество параметров экспертов)
- Слои экспертов с высокой размерностью требуют большой пропускной способности памяти.
Контекст на 256K токенов:
- Размер KV-кэша линейно растет с увеличением длины контекста.
- При длине контекста в 256K токенов один только кэш занимает большую часть VRAM, даже при низкобитном квантовании.
Активный размер в триллион параметров:
- 1T активных параметров во время инференса означает, что даже квантованные версии модели остаются очень большими.
- Развертывание в формате FP16 практически невозможно без сотен GPU.
Как запустить Kimi K2 Thinking локально с минимальными затратами?
Запустить Kimi K2 Thinking локально можно только при использовании агрессивного квантования и полной выгрузки весов на внешние носители. Недорогое развертывание зависит от уменьшения размера модели и переноса большей части весов в оперативную память или на диск вместо VRAM.
Если вам нужны недорогие облачные GPU вместо локального оборудования, Novita AI предлагает облачные GPU, спотовые инстансы и несколько тарифных планов. Это дешевле, чем покупка крупных GPU для постоянного использования.
https://www.youtube.com/watch?v=y6U36dO2jk0
В демонстрации на YouTube показано, как Kimi K2 Thinking запускается локально на Mac Studio при агрессивном квантовании и выгрузке весов на внешние носители

Unsloth предоставляет динамическое квантование на 1.8 бит, которое уменьшает модель с триллионом параметров с терабайтного размера до такого, который может загрузить большинство машин — но есть компромиссы! Вы можете развернуть эту модель на облачных GPU Novita AI, чтобы оценить производительность kimi k2 thinking и подготовиться к использованию в вашем бизнесе!
Проверить недорогие облачные GPU на Novita AI
Спотовые инстансы Novita AI запускаются со следующими условиями:
- 1 час периода защиты
- Экономия до 50% затрат
- Предварительное уведомление о прерывании за 1 час
Вы можете использовать вычислительные ресурсы по типу спотовых только в том случае, если:
- База данных является распределенной и реплицированной
- Система устойчива к потере узлов
- Нагрузка является некритичной или предназначена для тестирования
Руководство по развертыванию Kimi K2 Thinking на Novita AI
Шаг 1: Зарегистрируйте аккаунт
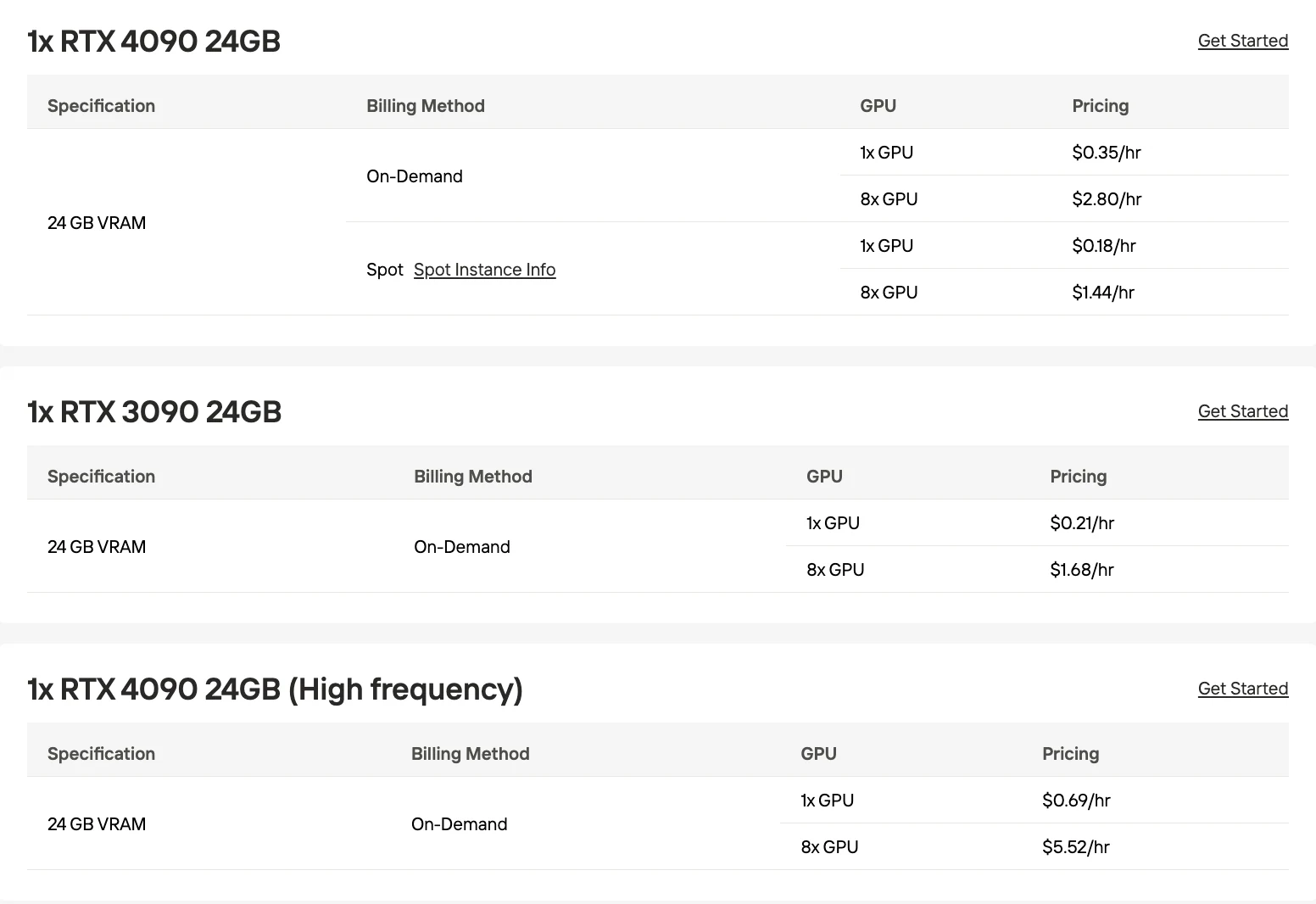
Создайте аккаунт Novita AI на нашем сайте. После регистрации перейдите в раздел «Explore» (Обзор) в левой боковой панели, чтобы посмотреть наши предложения по GPU и начать работу над проектами в области ИИ.

Шаг 2: Изучение шаблонов и GPU-серверов**
Выбирайте подходящие для вашего проекта шаблоны, такие как PyTorch, TensorFlow или CUDA. Затем выберите нужную конфигурацию GPU: доступны мощные L40S, RTX 4090 или A100 SXM4, каждый с разными характеристиками по объему VRAM, оперативной памяти и хранилища.
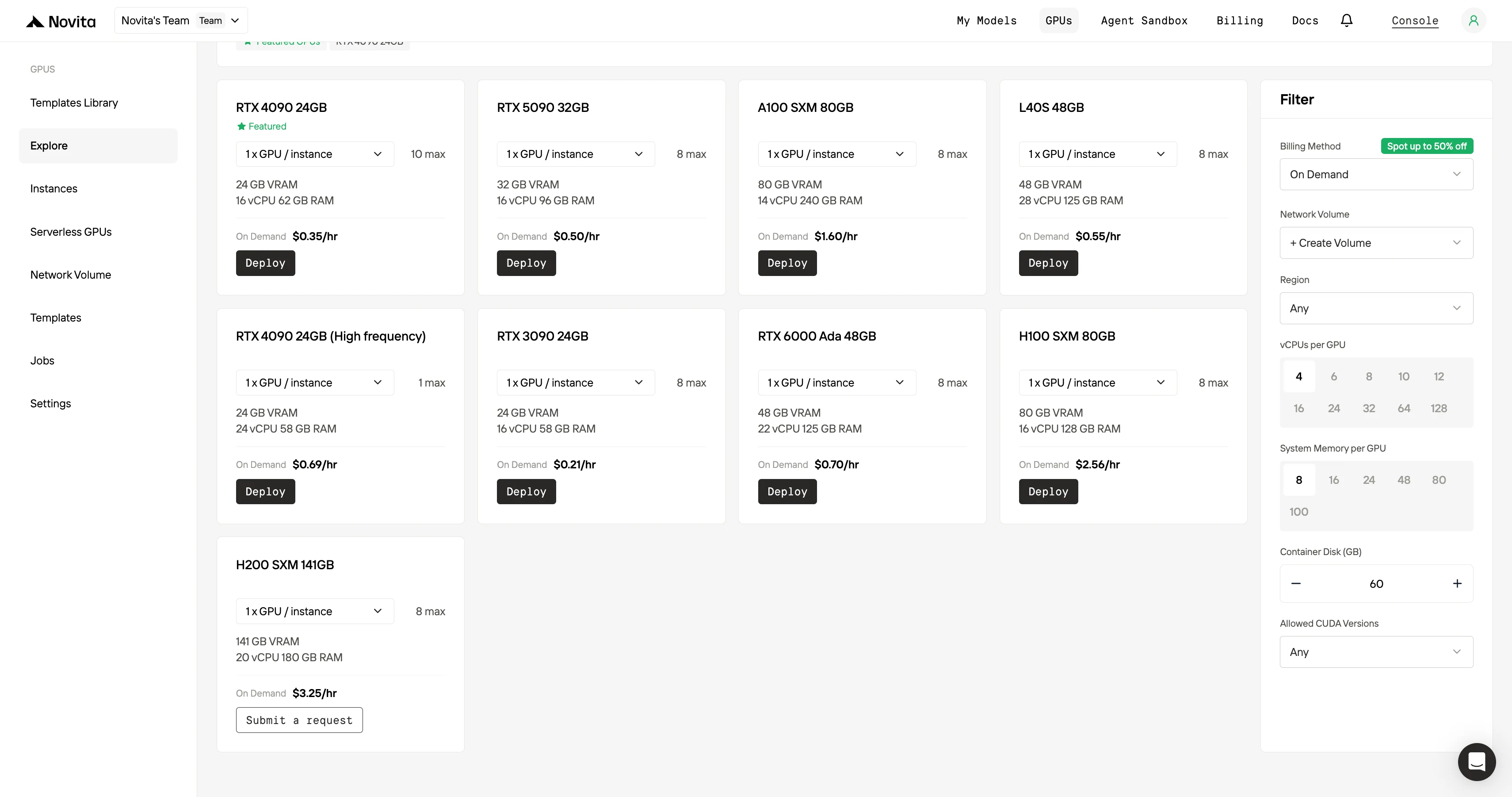
Шаг 3: Настройка развертывания под ваши нужды
Настройте окружение, выбрав предпочитаемую операционную систему и параметры конфигурации, чтобы обеспечить максимальную производительность для ваших конкретных рабочих нагрузок ИИ и потребностей разработки.
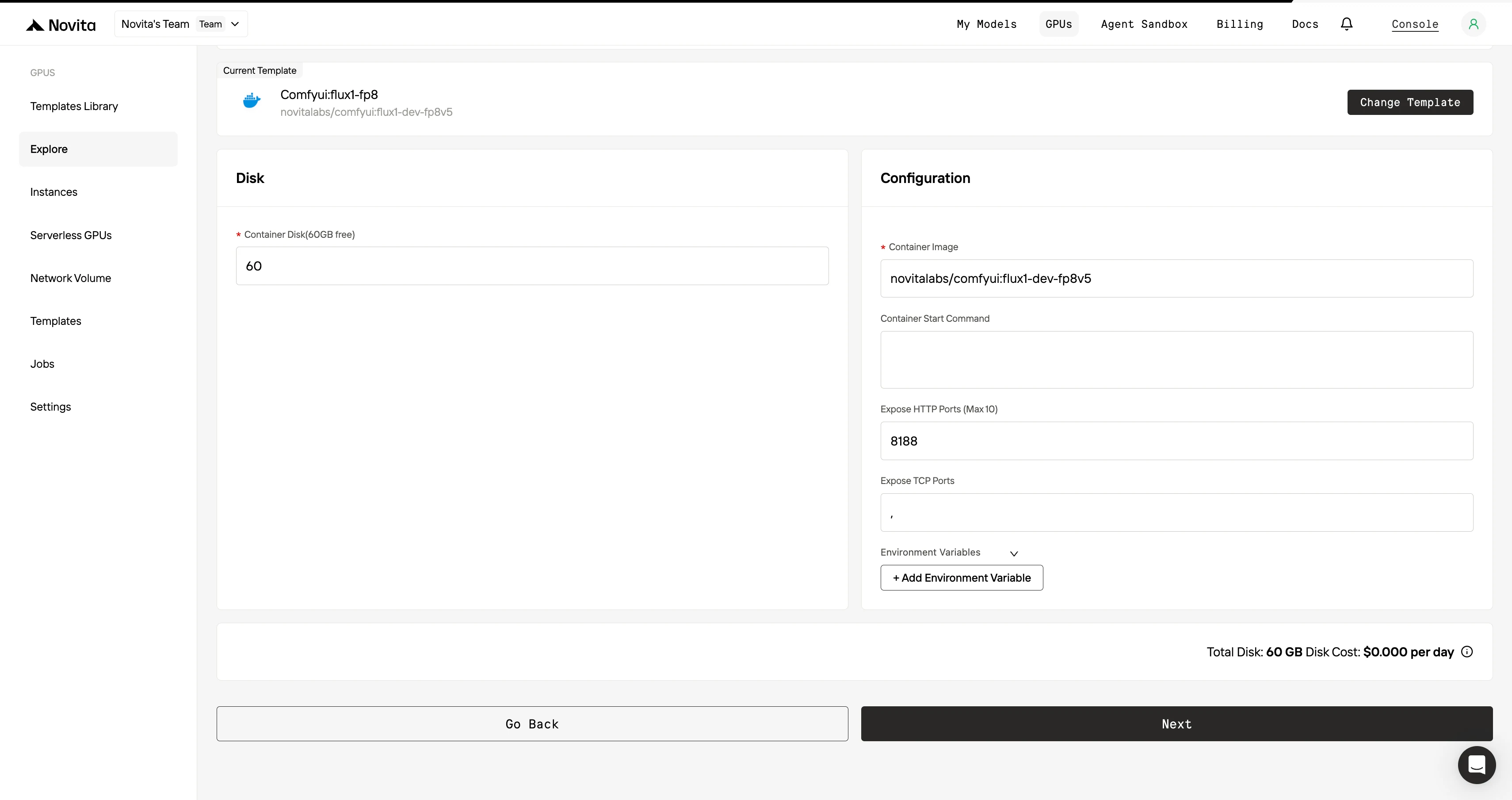
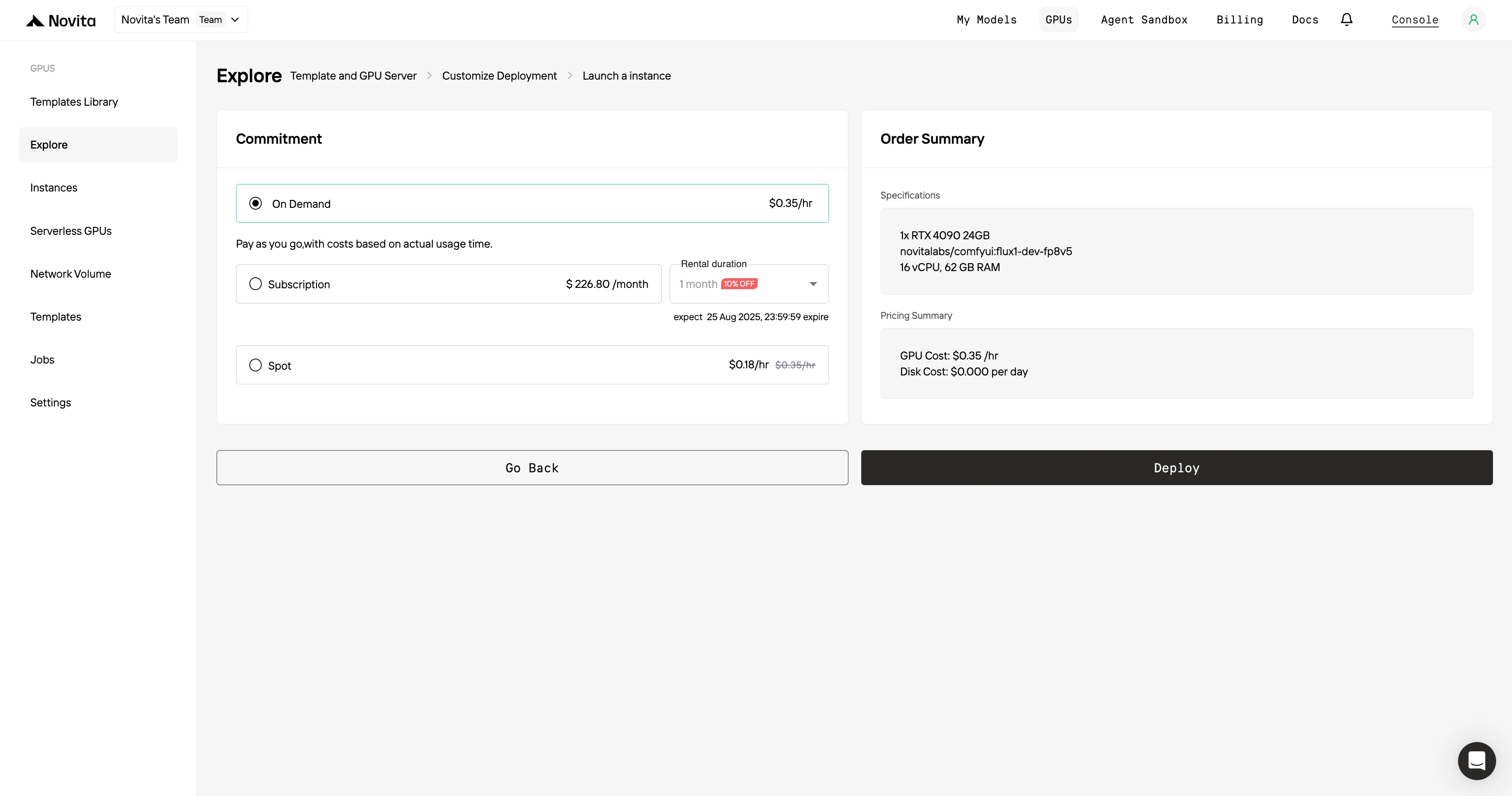
Шаг 4: Запуск инстанса****
Нажмите «Launch Instance» (Запустить инстанс), чтобы начать развертывание. Ваше высокопроизводительное GPU-окружение будет готово в течение нескольких минут, и вы сможете сразу приступить к проектам в области машинного обучения, рендеринга или вычислительных задач.
Как сэкономить память при развертывании Kimi K2 Thinking?
1. Выборочная выгрузка на GPU
Да. Вы можете оставить роутер и механизм внимания на GPU, а выгрузить эксперты MoE FFN в оперативную память или SSD с помощью масок regex. Работает в llama.cpp с сборками MoE в формате GGUF.
2. Динамическое 2-битное квантование (Q2-K-XL)
Да. Unsloth предоставляет квантованные модели Q2 и 1.8-бит для Kimi K2 / K2 Thinking. Они значительно уменьшают потребление памяти при сохранении высокой точности.
3. Квантование KV-кэша
Да. Использование параметров --cache-type-k q4_1 и --cache-type-v q4_1 уменьшает объем памяти, занимаемый KV-кэшем, примерно в 4 раза. Очень эффективно для моделей с контекстом на 256K токенов.
4. Flash Attention и режим высокой пропускной способности
Да, если ваша сборка поддерживает MoE + Flash Attention. Помогает уменьшить память, занимаемую активациями, и увеличить скорость.
5. Обрезка контекста
Да. Уменьшение истории до 8K–16K токенов значительно снижает объем памяти, занимаемый KV-кэшем. Это обязательный шаг для работы с Kimi K2 Thinking.
6. Батчинг
Частично. Это не уменьшает объем VRAM на один запрос, но повышает thr
Еще один эффективный способ использования Kimi K2 Thinking: работа через API
Novita AI предоставляет API Kimi K2 Thinking Instruct с контекстом на 262K токенов по стоимости $0.60 за вход и $2.5 за выход, что обеспечивает надежную поддержку для максимального раскрытия потенциала Kimi K2 Thinking как кодового агента.
Novita AI
| Аспект | API | Локальный GPU | Облачный GPU |
|---|---|---|---|
| Настройка | Мгновенная | Сложная | Умеренная |
| Поддержка | Отсутствует | Высокая | Умеренная |
| Стоимость | Самая высокая за единицу | Самая низкая (при масштабировании) | Умеренная |
| Масштабируемость | Автоматическое | Сложное | Легкое |
| Конфиденциальность | Данные уходят за пределы | Полностью локальная | Данные уходят за пределы |
| Кастомизация | Минимальная | Максимальная | Высокая |
| Лучше всего подходит для | Быстрый старт, малые/средние проекты, отсутствие инфраструктуры | Крупные стабильные нагрузки, максимальная конфиденциальность | Крупные/изменяемые нагрузки, кастомные модели |
Шаг 1: Войдите в свой аккаунт и нажмите кнопку «Библиотека моделей».

Попробуйте Kimi K2 Thinking сейчас!
Шаг 2: Выберите модель
Просмотрите доступные варианты и выберите модель, которая подходит для ваших задач.
Шаг 3: Начните бесплатный пробный период
Начните бесплатный пробный период, чтобы изучить возможности выбранной модели.
Шаг 4: Получите ваш API-ключ
Для аутентификации через API мы предоставим вам новый API-ключ. Перейдя на страницу «Settings» (Настройки), вы можете скопировать API-ключ, как показано на изображении.

Шаг 5: Установите API
Установите API с помощью менеджера пакетов, соответствующего вашему языку программирования.
После установки импортируйте необходимые библиотеки в ваше окружение для разработки. Инициализируйте API с вашим API-ключом, чтобы начать взаимодействие с Novita AI LLM. Ниже приведен пример использования API завершения чата для пользователей Python.
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="moonshotai/kimi-k2-thinking",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=262144,
temperature=0.7
)
print(response.choices[0].message.content)
Огромный объем памяти, который занимает Kimi K2 Thinking, обусловлен 1T активных параметров, архитектурой MoE и расширением KV-кэша на 256K токенов. Потребности в VRAM варьируются от ~500 ГБ (INT4) до почти 3 ТБ (FP16), что значительно превышает возможности потребительских GPU. Однако агрессивное квантование, выборочная выгрузка весов, сжатие KV-кэша и контроль контекста позволяют запускать модель локально с ограничениями. Облачные GPU и API Novita AI с оплатой по факту использования являются наиболее доступной и масштабируемой альтернативой. Вместе эти варианты делают запуск Kimi K2 Thinking возможным как для любителей, так и для производственных рабочих нагрузок без покупки массивного оборудования.
Часто задаваемые вопросы
Почему Kimi K2 Thinking требует такого большого объема VRAM?
Kimi K2 Thinking использует архитектуру MoE с триллионом параметров, 384 экспертами и 8 активными на токен, а также контекстное окно на 256K токенов. Эти структуры значительно увеличивают объем загружаемых весов и памяти, занимаемой KV-кэшем, по сравнению с типичными моделями.
Сколько VRAM требуется для Kimi K2 Thinking в формате FP16?
Для Kimi K2 Thinking в формате FP16 требуется ~2009 ГБ для контекста на 1K токенов и ~2901 ГБ для контекста на 256K токенов, поэтому развертывание возможно только на крупных многопроцессорных GPU-кластерах.
Можно ли запустить Kimi K2 Thinking локально на GPU с 24 ГБ памяти?
Да — только с использованием квантованной до 1.8-бит версии Kimi K2 Thinking от Unsloth и полной выгрузки весов MoE в оперативную память или SSD. Ожидайте очень низкую скорость (1–2 токена в секунду).
Novita AI — это облачная ИИ-платформа, которая предлагает разработчикам простой способ развертывания ИИ-моделей с помощью нашего простого API, а также доступное и надежное облако GPU для разработки и масштабирования.
Рекомендуемые материалы



