

探索 GPT Neo 的威力:這款超大規模自迴歸語言模型搭配 Mesh-Tensorflow。在我們的部落格上了解更多!
簡介
語言模型已經徹底改變了自然語言處理(NLP)的領域,讓機器能夠理解並生成類似人類的文字。GPT Neo 便是其中一例,它是一個基於 GPT 架構的大規模自迴歸語言模型。GPT Neo 擁有驚人的 1.25 億個參數,能夠生成高品質的文字,並執行各種 NLP 任務,使其成為在 EleutherAI 和 Hugging Face 上進行實際小樣本學習的寶貴工具。這個模型可以輕鬆整合到文字生成的流程中,每次執行時都能生成不同的序列。
什麼是 GPT Neo?
GPT Neo 是一個預先訓練好的語言模型,在大型資料集上進行訓練,以理解並生成類似人類的文字。它屬於 GPT 系列模型,並基於 GPT 架構。GPT Neo 擁有 1.25 億個參數,這讓它能夠捕捉自然語言的複雜性,並生成連貫且語境相關的文字。GPT Neo 的一個獨特之處在於,它在每隔一層的注意力機制中使用了視窗大小為 256 個 token 的局部注意力,使其成為語言處理任務的強大工具。模型的詞彙量設定為 50257 個 token,讓 GPT Neo 能夠辨識並生成極廣泛的 token,成為一個高度通用且精確的語言模型。
該模型使用 Pile 資料集進行訓練,這是一個龐大的文字語料庫,提供了多樣且豐富的訓練資料。這個資料集讓 GPT Neo 能夠學習英文的規律與結構,從而生成高品質的文字。
自迴歸語言模型的演進
自迴歸語言模型在機器學習與自然語言處理的演進中扮演了重要角色。這類模型(例如 GPT Neo)會根據先前的詞語來預測序列中的下一個詞,從而生成連貫且語境相關的文字。
多年來,自迴歸語言模型在規模與效能上持續演化。隨著硬體與訓練技術的進步,像 GPT Neo 這樣的模型已能擴展到數百萬個參數,捕捉更複雜的語言模式,生成更精確的文字。
自迴歸語言模型的發展大幅促進了機器翻譯、情感分析、文字生成及其他 NLP 任務的進步。這些模型為自然語言理解開闢了新的可能性,也為更先進語言模型的發展奠定了基礎。
GPT Neo 的主要特色
GPT Neo 擁有幾項關鍵特色,使其成為強大的語言模型。其架構基於 GPT 模型,能夠理解並生成類似人類的文字。憑藉其龐大的規模,GPT Neo 能夠捕捉複雜的語言模式,並生成連貫且語境相關的文字。
另一個突出特色是 GPT Neo 能夠擴展到大規模語言建模任務。這得益於它使用 Mesh-Tensorflow 框架進行實現,該框架能夠高效地進行平行處理。透過利用多個 GPU,GPT Neo 可以處理龐大的資料量,並以極高效率執行運算。
此外,現在也推出了 GPU 專用的 GPT NeoX 儲存庫,讓希望充分發揮模型 GPU 潛力的使用者能夠使用。GPT NeoX 的參數可以在 YAML 設定檔中定義,並傳遞給 deepy.py 啟動器。為了方便起見,我們在 configs 資料夾中提供了一些範例 .yml 檔案,展示了多樣的功能與模型規模。這些檔案通常內容完整,但可能並非對每個使用案例都是最佳選擇。
這些關鍵特色讓 GPT Neo 成為文字生成、語言翻譯、情感分析及其他 NLP 應用的多功能強大工具。
架構與設計原則
GPT Neo 的架構基於 GPT 模型,GPT 代表「生成式預訓練轉換器」(Generative Pretrained Transformer)。轉換器是一種神經網路架構,徹底改變了自然語言處理任務。GPT 架構由多層自注意力機制和前饋神經網路組成。
在 GPT Neo 中,轉換器架構讓模型能夠捕捉文字中詞語之間的依賴關係與關聯性,從而生成連貫且語境相關的文字。
GPT 架構的核心是 token 的概念。Token 代表文字的基本單位,例如單詞或字元。透過處理這些 token,GPT Neo 能夠理解文字的結構與意義,並生成適當的回應。
GPT Neo 的設計原則優先考慮生成高品質且語境相關的文字。該模型在大型資料集上進行訓練,學習自然語言的規律與結構,使其能夠生成連貫且有意義的文字。
1.25 億個參數的力量
GPT Neo 擁有驚人的 1.25 億個參數,這有助於生成高品質且語境相關的文字。參數是模型在訓練過程中學習的變數。模型的參數越多,它能捕捉的模式就越複雜,生成的文字也越出色。
GPT Neo 的模型規模是其效能的重要因素。憑藉大量的參數,它可以捕捉複雜的語言模式,並生成連貫且語境相關的文字。
此外,GPT Neo 擁有龐大的詞彙量,能夠理解並生成極廣泛的詞語與短語。這種廣泛的詞彙進一步增強了其生成準確且多樣化文字的能力。
訓練 GPT Neo:幕後過程
訓練 GPT Neo 涉及複雜的流程,包括處理大型資料集以及最佳化模型的參數。該模型使用 Pile 資料集進行訓練,該資料集提供了多樣且豐富的文字訓練資料。
在訓練過程中,模型會分批處理資料集,每批包含固定數量的範例。批次大小是影響訓練流程的重要參數。較大的批次大小可能加速訓練,但需要更多記憶體;較小的批次大小則可能減慢訓練速度,但有助於防止過擬合。
透過訓練流程,GPT Neo 學習了自然語言的規律與結構,從而能夠生成連貫且語境相關的文字。

運用 Pile 資料集進行訓練
GPT Neo 使用 Pile 資料集進行訓練,這是一個龐大的文字語料庫,提供了多樣且豐富的訓練資料。Pile 資料集包含各種文字來源,包括書籍、文章、網站等。這種多樣化的文字集合讓 GPT Neo 能夠學習語言的規律與結構,生成連貫且語境相關的文字。
在訓練過程中,GPT Neo 處理 Pile 資料集中的文字資料,並最佳化參數以捕捉語言的複雜性。透過向模型暴露大量的文字資料,GPT Neo 變得擅長理解並生成人類文字。
Pile 資料集在訓練 GPT Neo 的過程中扮演關鍵角色,為模型提供了學習並泛化自然語言知識所需的資料。
Mesh-TensorFlow:擴展以滿足 GPT Neo 的需求
Mesh-TensorFlow 在高效擴展 GPT Neo 以滿足其需求方面扮演著重要角色。透過利用 GPU 的威力並採用平行處理,Mesh-TensorFlow 最佳化了大型語言模型的訓練與推論流程。其功能可與 GPT Neo 無縫整合,在訓練與部署階段都能達到最佳效能。這種系統化的方法確保 GPT Neo 能夠應付其 1.25 億個參數與龐大詞彙量的複雜性,並使用張量-專家-資料並行的框架進行高效處理。這使 GPT Neo 成為自然語言處理應用中的強大力量。
GPT Neo 的實際應用
GPT Neo 能夠生成高品質且語境相關的文字,因此擁有廣泛的實際應用。其中一個關鍵應用是內容生成,例如撰寫部落格文章、論文及其他形式的書面內容。憑藉對自然語言的理解,GPT Neo 可以生成連貫且吸引人的特定主題文字。
此外,GPT Neo 也可用於各種自然語言處理任務,包括情感分析、文字翻譯、問答等。它理解與生成文字的能力使其成為在需要自然語言理解與生成的實際應用中實施模型的有價值的工具。
內容生成:部落格、文章等
內容生成是 GPT Neo 的主要應用之一。憑藉對自然語言的理解以及生成連貫且語境相關文字的能力,GPT Neo 可用於生成部落格文章、論文及其他書面內容。
對於部落客與內容創作者來說,GPT Neo 提供了一個有價值的工具,可以生成各種主題的高品質且吸引人的內容。透過提供一些範例或提示,GPT Neo 就能生成完整的文章或文字片段,這些內容與人類撰寫的內容難以區分。
自然語言處理任務
GPT Neo 的自然語言處理能力使其適用於廣泛的任務。它可用於情感分析,即判斷給定文字中表達的情緒或情感。這對於分析客戶回饋、社群媒體內容及其他形式的文字資料非常有價值。
GPT Neo 還可用於機器翻譯,將文字從一種語言翻譯成另一種語言。透過理解輸入文字的語境與結構,GPT Neo 可以生成準確的翻譯。
推論時間指的是 GPT Neo 在給定輸入後生成回應或預測所需的時間。GPT Neo 的架構與設計原則優先考慮效率,使其能夠及時執行推論。這使其適合需要快速回應的即時應用。
GPT Neo 與其他語言模型的比較
GPT Neo 是語言模型家族的一員,其他著名模型還包括 GPT-3 與 BERT。每個模型都有其優勢與應用場景。
在比較 GPT Neo 與 GPT-3 時,一個關鍵差異在於它們的規模與參數數量。GPT-3 遠大於 GPT Neo,擁有 1750 億個參數,而 GPT Neo 只有 1.25 億個參數。這種規模上的差異影響了它們捕捉複雜語言模式與生成準確文字的能力。
另一方面,BERT 是一種不同類型的語言模型,專注於文字的雙向表示。雖然 GPT Neo 與 BERT 用途不同,但它們都為自然語言理解與生成的進步做出了貢獻。
GPT Neo 對比 GPT-3:差異何在?
GPT Neo 與 GPT-3 都屬於 GPT 模型家族,但在規模與效能上存在關鍵差異。GPT-3 是一個更大的模型,擁有 1750 億個參數,而 GPT Neo 則有 1.25 億個參數。這種規模差異影響了它們捕捉複雜語言模式與生成準確文字的能力。
由於規模更大,GPT-3 在零樣本任務(即未提供特定訓練)上表現通常更佳。而 GPT Neo 則需要一些範例或提示才能獲得良好結果。
GPT Neo 與 GPT-3 都在自然語言處理任務上表現出色,但它們在規模與效能上的差異使它們適合不同的應用與使用案例。
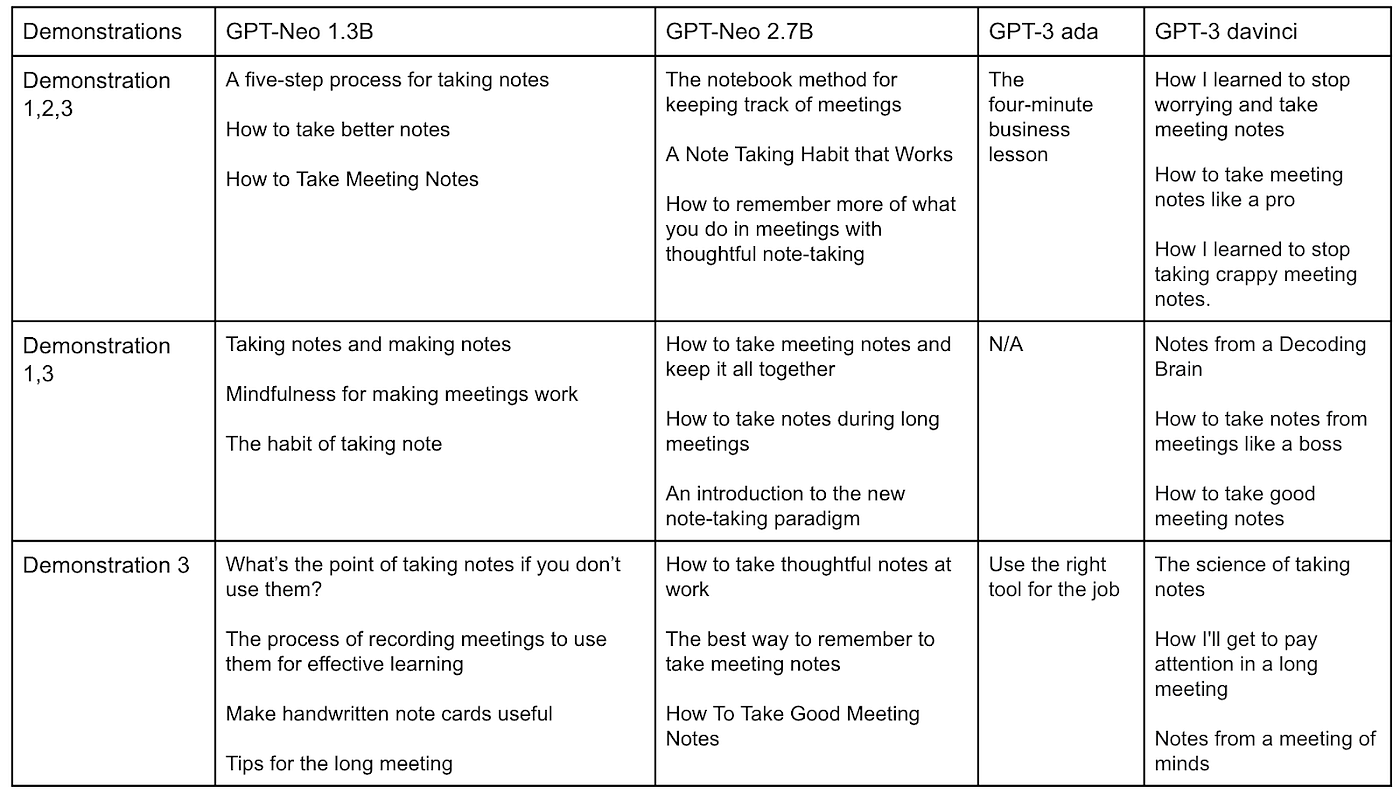
GPT Neo 在新興模型中的地位
GPT Neo 是一個新興的語言模型,因其出色的效能與能力而備受關注。作為 GPT 家族模型的一員,GPT Neo 在市場上其他著名語言模型中佔有一席之地。
雖然 GPT-3 與 BERT 等模型主導了市場,但 GPT Neo 憑藉其強大的架構與大規模能力提供了一個有力的替代方案。它能夠生成連貫且語境相關的文字,加上使用 Mesh-TensorFlow 的擴展性,使其有別於其他新興模型。
隨著 GPT Neo 持續開發與完善,預計它將為自然語言處理領域做出重大貢獻,並在市場上與成熟的模型並駕齊驅。
在實際應用中實施 GPT Neo
GPT Neo 在各個行業的實際應用中具有巨大的潛力。其自然語言理解與生成能力使其適用於聊天機器人、虛擬助理與客戶支援系統等任務。
在實際應用中部署 GPT Neo 時,必須遵循指南與最佳實踐,以確保最佳效能並降低潛在偏見。使用語言模型時,也必須考慮倫理問題,以確保公平且無偏袒的結果。
GPT Neo 的一般使用方式是提供一些範例或提示來引導模型的預測。透過針對特定任務進行微調與調整,開發人員可以在其應用中利用 GPT Neo 的威力。
部署指南
在實際應用中部署 GPT Neo 或任何語言模型時,必須遵循指南與最佳實踐,以確保最佳效能並降低潛在偏見。
首先,需要考慮模型將部署的具體使用案例與任務,包括決定適當的輸入格式、定義期望的輸出,以及設定評估模型效能的標準。
此外,必須考量倫理議題,以解決潛在偏見,確保公平且無偏袒的結果。這涉及仔細策劃訓練資料,並監控模型的預測,以偵測並修正可能出現的任何偏見。
最後,可能需要定期更新與重新訓練模型,以適應不斷變化的資料,並隨著時間提升其效能。
透過遵守這些指南,開發人員可以確保 GPT Neo 在實際應用中成功部署與實施。
處理限制與偏見
與任何語言模型一樣,GPT Neo 有其限制與潛在偏見。在實際應用中部署模型時,必須處理這些限制與偏見。
GPT Neo 的限制之一是其對訓練資料的依賴。如果訓練資料存在偏見或缺乏多樣性,模型生成的文字可能表現出偏見。
為了減輕偏見,必須仔細策劃訓練資料,並監控模型的預測。透過納入多樣且包容的訓練資料,並定期評估模型的輸出,開發人員可以將偏見的影響降到最低。
使用語言模型時也應考慮倫理問題,確保其部署符合公平、透明與負責的原則。透過處理限制與偏見,開發人員可以確保 GPT Neo 在實際應用中負責任且合乎道德地使用。
隱私與個人資訊問題是 GPT Neo 的另一個嚴重限制,因為它是開源的。
為了克服上述限制,您可以應用我們強大的 LLM API 來降低偏見的機率,並確保您的個人資訊安全。

除此之外,Novita AI LLM 透過強大的推理 API 為您提供不受限制的對話。憑藉最優惠的定價與可擴展的模型,Novita AI LLM 推理 API 為您的 LLM 提供令人難以置信的穩定性,並在不到 2 秒的時間內實現極低的延遲。

此外,我們的 API 包含了最近發布的最新且強大的 Meta Llama 3 模型:

GPT Neo 與自迴歸模型的未來
GPT Neo 與自迴歸語言模型的未來前景看好。隨著技術進步以及在自然語言處理領域進行更多研究,我們可以期待像 GPT Neo 這樣的模型在效能與能力上進一步提升。
其中一個可能持續的趨勢是語言模型擴展到更大的規模,使其能夠捕捉更複雜的語言模式並生成更準確的文字。此外,我們可以預期微調技術的進步,以及語言模型整合到各種應用中,進一步擴大其實用性與影響力。
結論
總而言之,GPT Neo 作為一個尖端的自迴歸語言模型,展現了令人印象深刻的能力。憑藉龐大的參數數量與創新的 Mesh-TensorFlow 技術,它在各種應用中擁有巨大的潛力,從內容生成到複雜的自然語言處理任務。隨著未來的發展,GPT Neo 在語言建模領域的演進與影響力,預計將重塑我們與 AI 驅動技術的互動方式。敬請關注這個令人興奮領域的最新趨勢與進展。
常見問題
開發人員如何處理 GPT Neo 中潛在的偏見?
開發人員透過仔細策劃訓練資料(納入多樣且包容的範例)來處理潛在偏見。他們也會監控模型的預測,並評估其輸出,以偵測並修正可能出現的任何偏見。
訓練像 GPT Neo 這樣的大規模模型面臨哪些挑戰?
一個挑戰是所需的計算資源,因為大規模模型需要強大的 GPU 與大量記憶體。另一個挑戰是最佳化批次大小,因為較大的批次可以加速訓練,但需要更多記憶體。平衡這些因素對於大規模模型的高效訓練至關重要。
Novita AI 是一個一站式平台,為無限創意提供超過 100 個 API。從影像生成、語言處理,到音訊增強與影片編輯,按使用量付費,價格低廉,讓您在建立自己的產品時無需擔憂 GPU 維護的麻煩。立即免費試用。
推薦閱讀



