

Gemma3-12B-IT是Google最新推出的指令調優語言模型,兼具強大的推理能力與高易用性。除了模型本身的能力之外,還有一個實際問題:要順暢運行它需要多少GPU記憶體?VRAM是決定能否在地端部署、企業硬體部署或使用雲端服務的關鍵因素。本文將為你說明Gemma3-12B-IT的VRAM需求,並比較地端部署與API方案的差異。
Gemma3-12B-IT:基礎資訊與基準測試
| Feature | Gemma3 12B it |
| Model Size | 模型大小:12B參數 |
| Open Source | 開源:是 |
| Context Window | 上下文視窗:128K Tokens |
| Architecture | 架構:僅解碼器Transformer |
| Multimodality | 多模態:文字與圖片 |
| Multilingual Support | 多語言支援:英語 + 140種語言 |
| Benchmark | 分數 |
| MMLU-Pro | 60% |
| GPQA Diamond | 35% |
| Humanity’s Last Exam | 4.8% |
| LiveCodeBench | 14% |
| SciCode | 17% |
| IFBench | 37% |
| AIME 2025 | 18% |
| AA-LCR | 7% |
核心能力:
- 文件分析:從包含圖表、圖形和技術視覺內容的報告中提取有意義的洞察。
- 視覺理解:結合完整的上下文推理,回答複雜的圖片相關問題。
- 內容生成:產出融合視覺與文字資訊的豐富描述、圖說和解釋性文本。
- 學習輔助:提供結合清晰解說與視覺學習資源的深度輔導。
什麼是VRAM?
視訊隨機存取記憶體(VRAM)是GPU上的專用記憶體,用於儲存模型參數、權重和中間計算結果。對於大型語言模型(LLM)而言,VRAM至關重要,因為它決定了模型是否能夠被載入、上下文視窗的長度,以及能支援的批次大小。與一般系統RAM不同,VRAM以極高的頻寬運行,能處理現代Transformer定義的大量矩陣運算。簡而言之,VRAM是推理與訓練的瓶頸資源:VRAM不足會導致記憶體溢位錯誤、上下文長度受限,或是效率低下的卸載(offloading)現象。
VRAM常見問題排查
VRAM中的模型儲存
像Gemma-3-12B-IT這樣的大型模型,僅載入權重和參數就需要數十GB的記憶體。如果VRAM不足,模型要麼無法運行,要麼會將部分工作卸載到速度較慢的系統RAM或磁碟中。實際的解決方案是使用更小或經量化(quantized)的檢查點,或是選擇記憶體容量更高的GPU。
批次處理限制
批次大小直接影響吞吐量與延遲。較大的批次每次步驟能處理更多標記,但會快速消耗額外的VRAM。當記憶體緊缺時,開發者必須縮小批次大小,或將工作拆分為微批次,這會降低效能。最終,升級到VRAM更高的GPU,是實現穩定大批次推理最直接的方案。
模型優化
有限的VRAM往往需要權衡效率。量化(Quantization)——例如使用8位元或4位元運行而非全精度——能將記憶體需求降低2至4倍,同時保留模型大部分效能。修剪冗餘參數或將特定操作卸載也能起到幫助。這些技術能讓大型模型在較低規格的硬體上運行,且不會造成嚴重的品質損失。
KV快取因素
除了權重之外,Transformer模型中的鍵值快取(KV-Cache)會導致記憶體使用量大幅增長。這個快取會儲存每個注意力層的中間狀態,且會隨序列長度擴展。對於支援最高128K標記的Gemma-3-12B-IT而言,如果不加管控,快取佔用的記憶體可能超過模型權重本身。Google透過混合本地/全局注意力設計降低了這部分開銷,但開發者仍然需要謹慎管理快取。相關策略包括限制上下文長度、採用滑動窗口注意力,或是使用VRAM預留空間更大的硬體。
推理 vs. 訓練
推理通常需要的記憶體較少——根據量化程度不同,8至24GB通常就足夠——而訓練的需求則高得多,很容易就超過80GB。這使得完整訓練對大多數團隊來說都不切實際。取而代之的是,參數高效微調(Parameter-Efficient Fine-Tuning)方法如LoRA或QLoRA是首選方案,能在有效適配模型的同時降低記憶體成本。
Gemma3-12B-IT VRAM需求
| 量化方式 | 僅權重(約) | 含KV快取(約) | 最低配置 | 推薦GPU |
| BF16 | 24.0 GB | 38.9 GB | Nvidia L40S ×1 | Nvidia H200 ×1 |
| SFP8 | 12.4 GB | 27.3 GB | Nvidia T4 ×1 | Nvidia A100 ×1 |
| INT4 | 6.6 GB | 21.5 GB | Nvidia T4 ×1 | Nvidia L40S ×1 |
重點整理:
- 全精度運行僅能在企業級GPU上順暢執行。
- 量化模型能大幅降低記憶體需求,讓消費級GPU也能部署,但需權衡取捨。
- 長上下文推理時KV快取會膨脹記憶體需求——規劃快取空間和規劃權重空間同樣重要。
Gemma-3-12B-IT:地端部署 vs API存取
| 面向 | 地端部署 | 雲端GPU | API存取 |
| 初期投入 | $15,000–$30,000+(1-2張企業級GPU如H100/H200,加上硬體建置成本) | 按小時付費,無需大額前期硬體投入 | 隨用隨付定價,無前期硬體成本 |
| 基礎設施 | 需要GPU、散熱、穩定電源供應 | Novita AI提供H100、H200、B200、RTX 6000 Ada等GPU實例,可隨需取用 | 無需任何基礎設施,運行於Novita AI優化的基礎設施上 |
| 技術專業度 | 需要機器學習/DevOps專業知識進行設定、驅動程式安裝和環境配置 | 僅需基礎設定,營運負擔遠低於地端部署 | 僅需基礎API使用知識 |
| 維護 | 需要持續監控、驅動程式更新、硬體保養 | Novita AI負責驅動程式、更新和硬體保養,使用者僅需管理自身應用程式 | 無需維護 |
| 擴展性 | 受限於本地硬體容量 | 彈性擴展——可根據工作負載增減GPU實例 | 可即時擴展,資源分配靈活 |
| 可靠性 | 效能取決於本地設定的穩定性 | 有SLA保證和穩定基礎設施支援 | 企業級SLA與優化運行時 |
| 效能 | 取決於所選GPU和配置 | 企業級GPU效能,可根據任務需求選擇合適的實例類型 | 供應商優化 |
| 資料隱私 | 完全本地控制資料 | 取決於供應商 | 取決於供應商 |
對於偏好直接控制權和GPU靈活性的使用者,Novita AI提供隨需取用的雲端GPU實例(包含H100、H200、B200、RTX 6000 Ada等),無需負擔本地硬體設定的負擔,即可實現高效能部署。
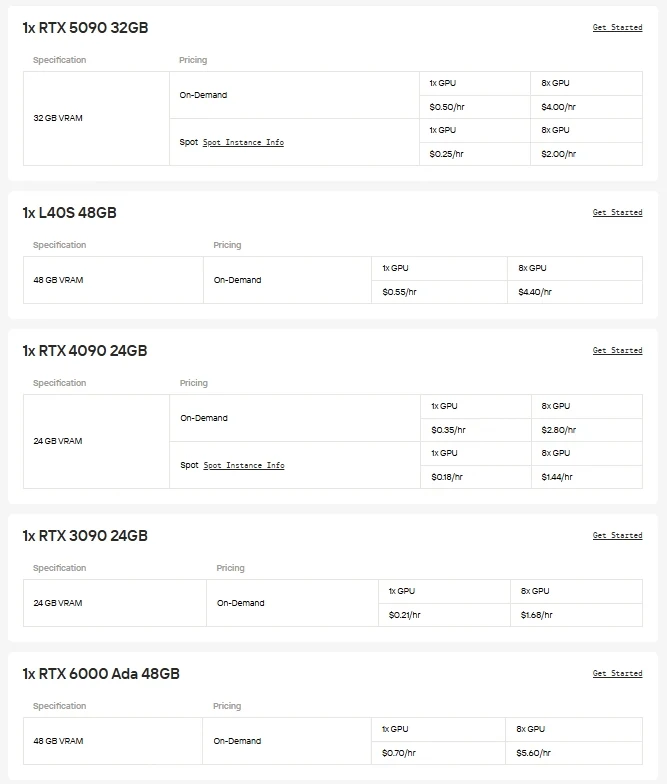
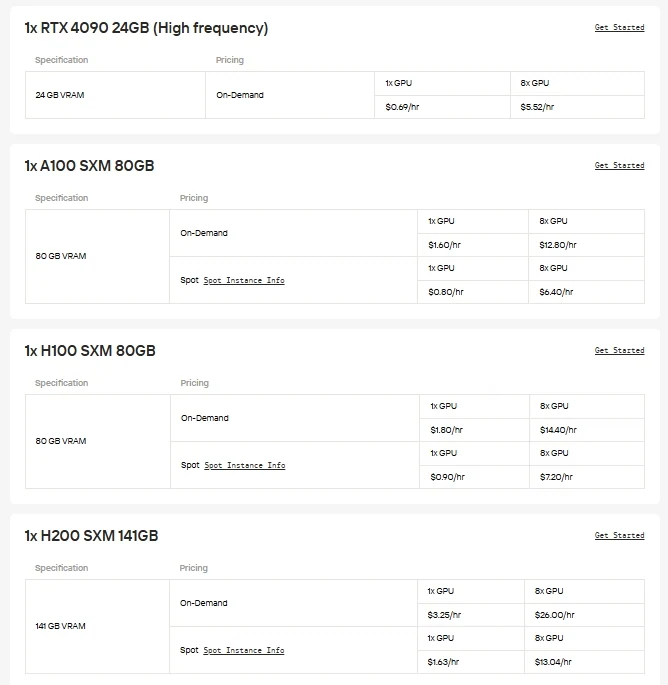
Novita AI 提供的Gemma-3-12B-IT API擁有131K上下文視窗,輸入價格為**$0.05/百萬標記**,輸出價格為**$0.1/百萬標記**,能以具成本效益的方式使用最先進的指令調優能力。
如何透過API存取Gemma-3-12B-IT
步驟1:登入並存取模型庫
登入你的帳號,點擊模型庫按鈕。
步驟2:開始免費試用
選擇你的模型,開始免費試用,探索所選模型的能力。
步驟3:取得你的API金鑰
要進行API驗證,我們會提供你新的API金鑰。進入「設定」頁面,即可按照圖片指示複製API金鑰。
步驟4:安裝API
使用對應程式語言的套件管理器安裝API。
安裝完成後,將必要的函式庫匯入你的開發環境。使用你的API金鑰初始化API,即可開始與Novita AI LLM互動。以下為Python使用者使用聊天完成API的範例:
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/openai",
api_key="session_Um3Ozta39g2J__yeP9b_rOegzeA_qSYYquKzJS2oitKENIo8_H2FL2sCtl25-sKWjCY_wsmN18iuDp1zv_Xkaw==",
)
model = "google/gemma-3-12b-it"
stream = True # or False
max_tokens = 4096
system_content = "Be a helpful assistant"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
常見問題
什麼是Gemma-3-12B-it?
Gemma-3-12B-it是Google Gemma 3系列的指令調優大型語言模型,支援文字與多模態輸入,並針對長上下文推理進行了優化。
運行Gemma-3-12B-it時為什麼VRAM很重要?
VRAM決定了模型是否能夠被載入並有效運行,它會影響模型精度、上下文長度、批次大小,以及整體推理速度。
在地端運行Gemma-3-12B-it需要多少VRAM?
以完整BF16精度運行時,僅權重就需要約24GB,加上快取後最高約40GB。量化版本僅權重需要6至12GB,但長上下文情況下快取仍會將需求推高至20GB以上。
Novita AI 是一個AI雲端平台,為開發者提供簡單的API來部署AI模型,同時也提供平價且可靠的GPU雲端服務,用於建構與擴展AI應用。



