

O Gemma3-12B-IT é o mais recente modelo de linguagem ajustado para instruções do Google, combinando raciocínio forte com acessibilidade. Além de suas capacidades, há uma questão prática: quanta memória de GPU é necessária para executá-lo bem? A VRAM é o fator decisivo para implantação local, hardware empresarial ou acesso à nuvem. Este artigo irá guiá-lo pelos requisitos de VRAM do Gemma3-12B-IT e comparar configurações locais com opções de API.
Gemma3-12B-IT: Noções Básicas e Benchmark
| Recurso | Gemma3 12B it |
| Tamanho do Modelo | 12B Parâmetros |
| Código Aberto | Sim |
| Janela de Contexto | 128K Tokens |
| Arquitetura | transformer apenas decodificador |
| Multimodalidade | Texto e Imagens |
| Suporte Multilíngue | Inglês + 140 idiomas |
| Benchmark | Pontuação |
| MMLU-Pro | 60% |
| GPQA Diamond | 35% |
| Humanity’s Last Exam | 4,8% |
| LiveCodeBench | 14% |
| SciCode | 17% |
| IFBench | 37% |
| AIME 2025 | 18% |
| AA-LCR | 7% |
Capacidades Principais:
- Análise de Documentos: Extrair insights significativos de relatórios que incluem gráficos, tabelas e visuais técnicos.
- Compreensão Visual: Responder a perguntas complexas relacionadas a imagens com raciocínio contextual completo.
- Geração de Conteúdo: Produzir descrições ricas, legendas e texto explicativo que combinam informações visuais e escritas.
- Suporte ao Aprendizado: Fornecer tutoriais aprofundados que integram explicações claras com recursos de aprendizado visual.
O que é VRAM?
A Memória de Acesso Aleatório de Vídeo (VRAM, na sigla em inglês) é a memória dedicada em uma GPU usada para armazenar parâmetros de modelo, pesos e computações intermediárias. Para modelos de linguagem grandes (LLMs, na sigla em inglês), a VRAM é crítica porque determina se um modelo pode ser carregado, qual o tamanho da janela de contexto e qual o tamanho de lote que pode ser suportado. Diferente da RAM geral do sistema, a VRAM opera com largura de banda extremamente alta para lidar com as operações massivas de matriz que definem os transformadores modernos. Em resumo, a VRAM é o recurso gargalo tanto para inferência quanto para treinamento: pouca VRAM significa erros de falta de memória, comprimento de contexto restrito ou offloading ineficiente.
Solução de Problemas com VRAM
Armazenamento do Modelo na VRAM
Modelos em larga escala como o Gemma-3-12B-it requerem dezenas de gigabytes apenas para carregar pesos e parâmetros. Se a VRAM for insuficiente, o modelo não consegue executar ou recorre ao offloading de partes da carga de trabalho para a RAM mais lenta do sistema ou disco. As soluções práticas são usar checkpoints menores ou quantizados, ou escolher GPUs com maior capacidade de memória.
Limites de Processamento em Lote
O tamanho do lote impacta diretamente a taxa de transferência e a latência. Lotes maiores processam mais tokens por etapa, mas consomem rapidamente VRAM adicional. Quando a memória está limitada, os desenvolvedores devem reduzir o tamanho dos lotes ou dividir o trabalho em micro-lotes, o que reduz o desempenho. No final, atualizar para GPUs com mais VRAM oferece o caminho mais simples para inferência estável com lotes grandes.
Otimização de Modelo
A VRAM limitada frequentemente força trade-offs de eficiência. A quantização — como executar em 8 bits ou 4 bits em vez de precisão total — reduz as necessidades de memória em 2 a 4 vezes, mantendo a maior parte da qualidade do modelo. A poda de parâmetros redundantes ou o offloading de certas operações também pode ajudar. Essas técnicas permitem que modelos grandes sejam executados em hardware mais modesto sem perda grave de qualidade.
O Fator do KV-Cache
Além dos pesos, o uso de memória cresce significativamente por causa do cache de chave-valor em modelos de transformador. Esse cache armazena estados intermediários para cada camada de atenção e escala com o comprimento da sequência. Para o Gemma-3-12B-it, que suporta até 128 mil tokens, o cache pode exceder os pesos do modelo se não for controlado. O Google reduziu essa sobrecarga com um design de atenção local/global misto, mas os desenvolvedores ainda precisam gerenciar o cache com cuidado. As estratégias incluem limitar o comprimento do contexto, adotar atenção de janela deslizante ou usar hardware com reservas de VRAM maiores.
Inferência vs. Treinamento
A inferência geralmente requer menos memória — 8 a 24 GB geralmente são suficientes, dependendo da quantização — enquanto as demandas de treinamento são muito maiores, facilmente ultrapassando a faixa de 80 GB. Isso torna o treinamento completo impraticável para a maioria das equipes. Em vez disso, métodos de ajuste fino eficientes em parâmetros, como LoRA ou QLoRA, são as soluções padrão, reduzindo os custos de memória enquanto ainda adaptam os modelos de forma eficaz.
Requisitos de VRAM do Gemma3-12B-IT
| Quantização | Apenas Pesos (Aproximado) | Com KV-cache (Aproximado) | Configuração Mínima | GPU Recomendada |
| BF16 | 24,0 GB | 38,9 GB | Nvidia L40S ×1 | Nvidia H200 ×1 |
| SFP8 | 12,4 GB | 27,3 GB | Nvidia T4 ×1 | Nvidia A100 ×1 |
| INT4 | 6,6 GB | 21,5 GB | Nvidia T4 ×1 | Nvidia L40S ×1 |
Principais conclusões:
- A execução em precisão total funciona sem problemas apenas em GPUs de nível empresarial.
- Modelos quantizados reduzem drasticamente as demandas de memória, permitindo implantação em GPUs de consumo com trade-offs.
- O KV-cache infla os requisitos durante a inferência de longo contexto — planejar o cache é tão importante quanto planejar os pesos.
Gemma-3-12B-IT: Implantação Local vs Acesso por API
| Aspecto | Implantação Local | GPU em Nuvem | Acesso por API |
| Investimento Inicial | US$ 15 mil a US$ 30 mil+ (1 a 2 GPUs empresariais como H100/H200, além de configuração de hardware) | Pagamento por hora, sem grande investimento inicial em hardware | Preço pagamento por uso; sem custo inicial de hardware |
| Infraestrutura | Requer GPUs, refrigeração, fonte de alimentação estável | Instâncias de GPU (H100, H200, B200, RTX 6000 Ada, etc.) fornecidas pela Novita AI, disponíveis sob demanda | Nenhuma necessária; executa na infraestrutura otimizada da Novita AI |
| Especialização Técnica | Especialização em ML/DevOps necessária para configuração, drivers e ambiente | Apenas configuração básica necessária; muito menos sobrecarga operacional que a implantação local | Conhecimento básico de uso de API |
| Manutenção | Monitoramento contínuo, atualizações de drivers, manutenção de hardware | A Novita AI cuida de drivers, atualizações e manutenção de hardware; os usuários gerenciam apenas seus aplicativos | Nenhuma necessária |
| Escalabilidade | Limitada pela capacidade de hardware local | Escalabilidade elástica — adicione ou libere instâncias de GPU conforme a carga de trabalho muda | Escalável instantaneamente, alocação de recursos flexível |
| Confiabilidade | Desempenho vinculado à estabilidade da configuração local | Com garantias de SLA e infraestrutura estável | SLA de nível empresarial e runtime otimizado |
| Desempenho | Dependente da GPU e configuração escolhidas | Desempenho de GPU de nível empresarial, com flexibilidade para escolher o tipo de instância certo para a tarefa | Otimizado pelo Provedor |
| Privacidade de Dados | Controle local total sobre os dados | Dependente do Provedor | Dependente do Provedor |
Para usuários que preferem controle direto e flexibilidade de GPU, a Novita AI oferece instâncias de GPU em nuvem sob demanda (incluindo H100, H200, B200, RTX 6000 Ada, etc.), permitindo implantação de alto desempenho sem o ônus da configuração de hardware local.
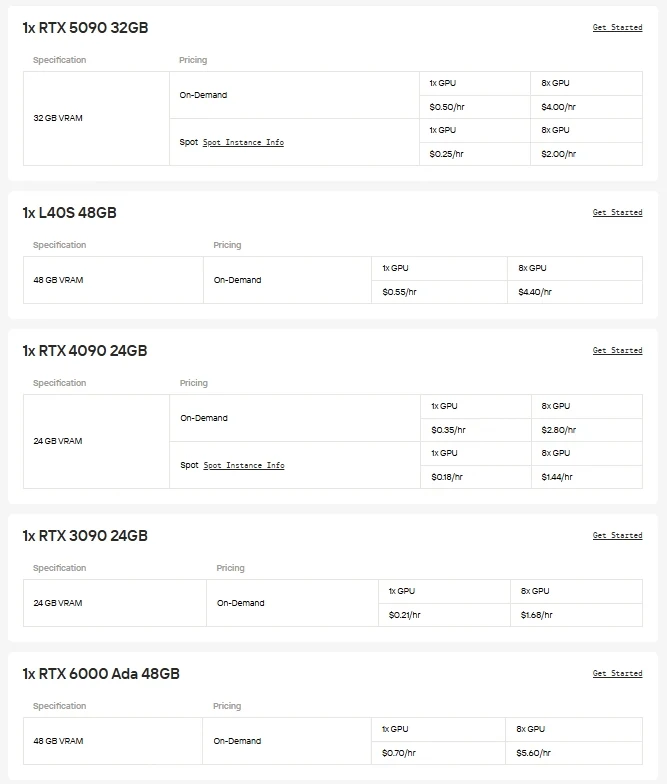
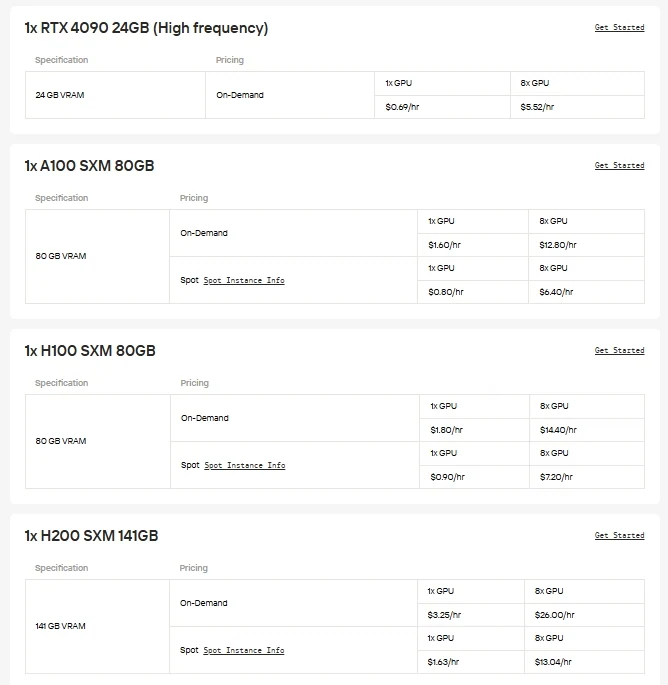
A Novita AI fornece APIs do Gemma-3-12B-IT com janela de contexto de 131K a custos de US$ 0,05/1M tokens de entrada e US$ 0,1/1M tokens de saída, oferecendo acesso econômico a capacidades de ajuste para instruções de última geração.
Como Acessar o Gemma-3-12B-IT via API
Passo 1: Faça Login e Acesse a Biblioteca de Modelos
Faça login na sua conta e clique no botão Biblioteca de Modelos.
Experimente a Demonstração do Gemma 3 12B IT Agora!
Passo 2: Inicie Seu Teste Gratuito
Selecione seu modelo e inicie seu teste gratuito para explorar as capacidades do modelo selecionado.
Passo 3: Obtenha Sua Chave de API
Para autenticar com a API, forneceremos uma nova chave de API. Acessando a página de “Configurações“, você pode copiar a chave de API conforme indicado na imagem.
Passo 4: Instale a API
Instale a API usando o gerenciador de pacotes específico da sua linguagem de programação.
Após a instalação, importe as bibliotecas necessárias para o seu ambiente de desenvolvimento. Inicialize a API com sua chave de API para começar a interagir com o LLM da Novita AI. Este é um exemplo de uso da API de conclusões de chat para usuários de Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/openai",
api_key="session_Um3Ozta39g2J__yeP9b_rOegzeA_qSYYquKzJS2oitKENIo8_H2FL2sCtl25-sKWjCY_wsmN18iuDp1zv_Xkaw==",
)
model = "google/gemma-3-12b-it"
stream = True # or False
max_tokens = 4096
system_content = "Be a helpful assistant"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Pergunta Frequente
O que é o Gemma-3-12B-it? O Gemma-3-12B-it é um modelo de linguagem grande ajustado para instruções da família Gemma 3 do Google. Ele suporta entradas de texto e multimodais e é otimizado para raciocínio de longo contexto.
Por que a VRAM é importante ao executar o Gemma-3-12B-it? A VRAM determina se o modelo pode ser carregado e executado de forma eficaz. Ela impacta a precisão do modelo, o comprimento do contexto, o tamanho do lote e a velocidade geral de inferência.
Quanta VRAM é necessária para executar o Gemma-3-12B-it localmente? Em precisão BF16 total, ele requer cerca de 24 GB apenas para pesos e até ~40 GB com cache. Versões quantizadas podem ser executadas com 6 a 12 GB para pesos, mas o cache ainda eleva os requisitos para mais de 20 GB em contextos mais longos.
A Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma maneira fácil de implantar modelos de IA usando nossa API simples, além de fornecer uma nuvem de GPU acessível e confiável para construir e escalar.



