

Gemma3-12B-IT est le dernier modèle de langage ajusté par instruction de Google, alliant des capacités de raisonnement solides et une grande accessibilité. Au-delà de ses fonctionnalités, une question pratique se pose : quelle quantité de mémoire GPU est nécessaire pour l’exécuter correctement ? La VRAM est le facteur décisif pour le déploiement local, le matériel d’entreprise ou l’accès cloud. Cet article vous guidera à travers les besoins en VRAM de Gemma3-12B-IT et comparera les configurations locales avec les options d’API.
Gemma3-12B-IT : Bases et benchmarks
| Fonctionnalité | Gemma3 12B it |
| Taille du modèle | 12B Paramètres |
| Open Source | Oui |
| Fenêtre de contexte | 128K Jetons |
| Architecture | decoder-only transformer |
| Multimodalité | Texte et images |
| Support multilingue | Anglais + 140 langues |
| Benchmark | Score |
| MMLU-Pro | 60% |
| GPQA Diamond | 35% |
| Humanity’s Last Exam | 4.8% |
| LiveCodeBench | 14% |
| SciCode | 17% |
| IFBench | 37% |
| AIME 2025 | 18% |
| AA-LCR | 7% |
Capacités principales :
- Analyse de documents : Extraire des insights pertinents de rapports incluant des graphiques, des schémas et des éléments visuels techniques.
- Compréhension visuelle : Répondre à des questions complexes liées aux images avec un raisonnement contextuel complet.
- Génération de contenu : Produire des descriptions détaillées, des légendes et des textes explicatifs qui mélangent des informations visuelles et écrites.
- Support à l’apprentissage : Fournir un tutorat approfondi qui intègre des explications claires et des ressources d’apprentissage visuelles.
Qu’est-ce que la VRAM ?
La mémoire vidéo à accès aléatoire (VRAM, pour Video Random Access Memory) est la mémoire dédiée d’un GPU utilisée pour stocker les paramètres du modèle, les poids et les calculs intermédiaires. Pour les grands modèles de langage (LLM), la VRAM est essentielle car elle détermine si un modèle peut être chargé du tout, la longueur de la fenêtre de contexte possible et la taille de batch supportée. Contrairement à la RAM système générale, la VRAM fonctionne avec une bande passante extrêmement élevée pour gérer les opérations matricielles massives qui définissent les transformeurs modernes. En résumé, la VRAM est la ressource limitante pour l’inférence et l’entraînement : trop peu de VRAM entraîne des erreurs de mémoire insuffisante, une longueur de contexte restreinte ou un déchargement inefficace.
Dépannage de la VRAM
Stockage du modèle en VRAM
Les modèles à grande échelle comme Gemma-3-12B-it nécessitent des dizaines de gigaoctets rien que pour charger les poids et les paramètres. Si la VRAM est insuffisante, le modèle ne peut pas s’exécuter ou se rabat sur le déchargement d’une partie de la charge de travail vers la RAM système plus lente ou le disque. Les solutions pratiques consistent à utiliser des checkpoints quantifiés plus petits, ou à choisir des GPU avec une capacité de mémoire plus élevée.
Limites du traitement par batch
La taille de batch a un impact direct sur le débit et la latence. Des batches plus grands traitent plus de jetons par étape mais consomment rapidement de la VRAM supplémentaire. Lorsque la mémoire est limitée, les développeurs doivent réduire la taille des batches ou diviser le travail en micro-batches, ce qui ralentit les performances. En fin de compte, passer à des GPU avec plus de VRAM est la solution la plus simple pour obtenir une inférence stable avec de grands batches.
Optimisation du modèle
Une VRAM limitée impose souvent des compromis d’efficacité. La quantification — comme exécuter le modèle en 8 bits ou 4 bits au lieu de la précision complète — réduit les besoins en mémoire de 2 à 4 fois tout en conservant la plupart de la qualité du modèle. L’élagage des paramètres redondants ou le déchargement de certaines opérations peut également aider. Ces techniques permettent aux grands modèles de s’exécuter sur du matériel plus modeste sans perte de qualité sévère.
Le facteur cache KV
Au-delà des poids, l’utilisation de la mémoire augmente considérablement en raison du cache clé-valeur dans les modèles de transformeur. Ce cache stocke les états intermédiaires pour chaque couche d’attention et évolue avec la longueur de séquence. Pour Gemma-3-12B-it, qui prend en charge jusqu’à 128K jetons, le cache peut dépasser le poids du modèle s’il n’est pas contrôlé. Google a réduit ce surcoût grâce à une conception d’attention mixte locale/globale, mais les développeurs doivent toujours gérer le cache avec soin. Les stratégies incluent la limitation de la longueur de contexte, l’adoption d’une attention à fenêtre glissante ou l’utilisation de matériel avec des réserves de VRAM plus importantes.
Inférence vs. Entraînement
L’inférence nécessite généralement moins de mémoire — 8 à 24 Go sont souvent suffisants selon la quantification — tandis que les besoins en mémoire pour l’entraînement sont beaucoup plus élevés, atteignant facilement plus de 80 Go. Cela rend l’entraînement complet peu pratique pour la plupart des équipes. À la place, les méthodes d’ajustement fin efficaces en termes de paramètres comme LoRA ou QLoRA sont les solutions privilégiées, réduisant les coûts en mémoire tout en adaptant efficacement les modèles.
Exigences en VRAM de Gemma3-12B-IT
| Quantification | Poids uniquement (approx.) | Avec cache KV (approx.) | Configuration minimale | GPU recommandé |
| BF16 | 24.0 Go | 38.9 Go | Nvidia L40S ×1 | Nvidia H200 ×1 |
| SFP8 | 12.4 Go | 27.3 Go | Nvidia T4 ×1 | Nvidia A100 ×1 |
| INT4 | 6.6 Go | 21.5 Go | Nvidia T4 ×1 | Nvidia L40S ×1 |
Points clés à retenir :
- La précision complète s’exécute sans problème uniquement sur des GPU de classe entreprise.
- Les modèles quantifiés réduisent considérablement les besoins en mémoire, permettant le déploiement sur des GPU grand public avec des compromis.
- Le cache KV augmente les exigences lors de l’inférence en long contexte — planifier le cache est aussi important que planifier les poids.
Gemma-3-12B-IT : Déploiement local vs accès API
| Aspect | Déploiement local | GPU cloud | Accès API |
| Investissement initial | 15 000 à 30 000 $ et plus (1 à 2 GPU d’entreprise comme H100/H200, plus la configuration matérielle) | Paiement à l’heure, pas de gros investissement matériel initial | Tarification à l’usage ; pas de coût matériel initial |
| Infrastructure | Nécessite des GPU, un système de refroidissement, une alimentation électrique stable | Instances GPU (H100, H200, B200, RTX 6000 Ada, etc.) fournies par Novita AI, disponibles à la demande | Aucune requise ; s’exécute sur l’infrastructure optimisée de Novita AI |
| Expertise technique | Expertise en ML/DevOps nécessaire pour la configuration, les pilotes et l’environnement | Seule une configuration de base est requise ; beaucoup moins de charge opérationnelle que le déploiement local | Connaissance de base de l’utilisation des API |
| Maintenance | Surveillance continue, mises à jour des pilotes, entretien du matériel | Novita AI gère les pilotes, les mises à jour et l’entretien du matériel ; les utilisateurs ne gèrent que leurs applications | Aucune requise |
| Scalabilité | Limitée par la capacité du matériel local | Scaling élastique — ajoutez ou libérez des instances GPU selon l’évolution de la charge de travail | Instantanément scalable, allocation flexible des ressources |
| Fiabilité | Performance liée à la stabilité de la configuration locale | Garantie par des accords de niveau de service (SLA) et une infrastructure stable | SLA de classe entreprise et runtime optimisé |
| Performance | Dépend du GPU et de la configuration choisis | Performance de GPU de classe entreprise, avec la flexibilité de choisir le type d’instance adapté à la tâche | Optimisé par le fournisseur |
| Confidentialité des données | Contrôle local total des données | Dépendant du fournisseur | Dépendant du fournisseur |
Pour les utilisateurs qui préfèrent un contrôle direct et la flexibilité des GPU, Novita AI propose des instances de GPU cloud à la demande (y compris H100, H200, B200, RTX 6000 Ada, etc.), permettant un déploiement haute performance sans la charge de configuration d’un matériel local.
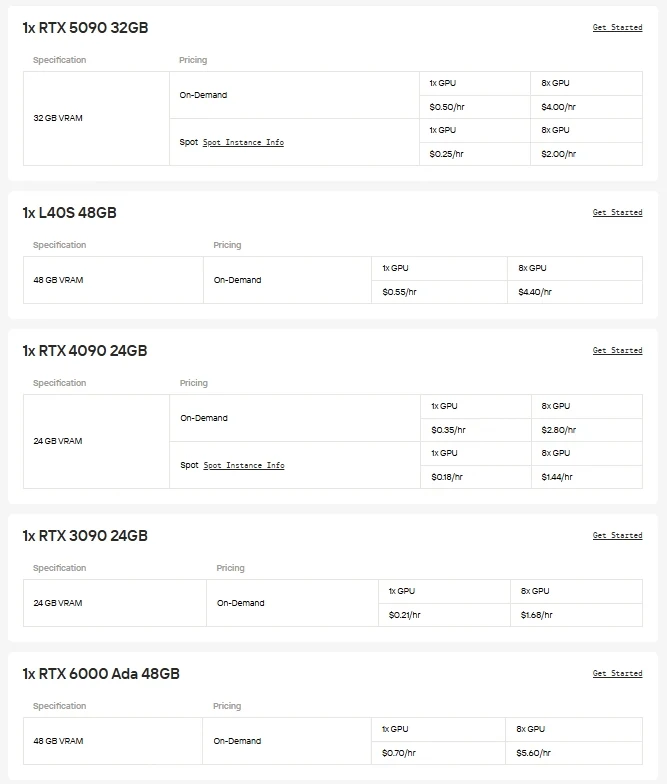
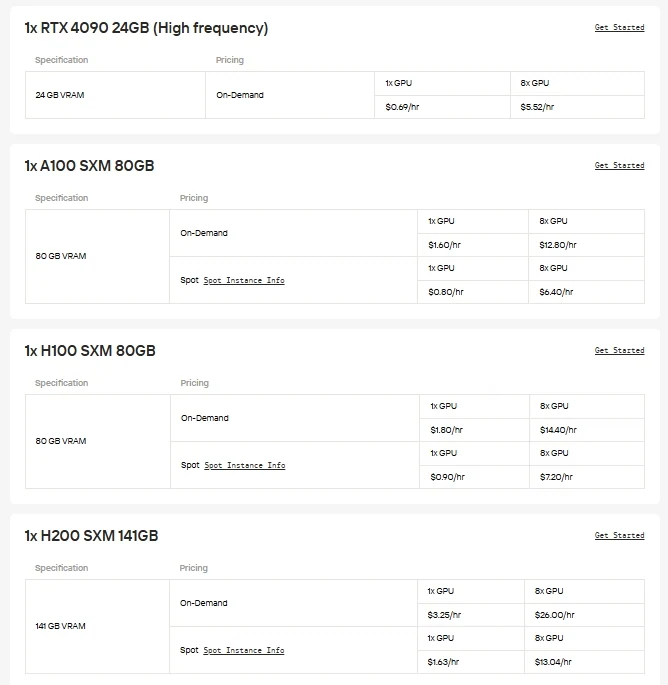
Novita AI propose des API pour Gemma-3-12B-IT avec une fenêtre de contexte de 131K jetons pour des coûts de 0,05 $ par million de jetons en entrée et 0,1 $ par million de jetons en sortie, offrant un accès rentable à des capacités d’ajustement par instruction de pointe.
Comment accéder à Gemma-3-12B-IT via API
Étape 1 : Connectez-vous et accédez à la bibliothèque de modèles
Connectez-vous à votre compte et cliquez sur le bouton Bibliothèque de modèles.
Essayez la démo de Gemma 3 12B IT dès maintenant !
Étape 2 : Démarrez votre essai gratuit
Sélectionnez votre modèle et commencez votre essai gratuit pour explorer les capacités du modèle sélectionné.
Étape 3 : Récupérez votre clé API
Pour vous authentifier auprès de l’API, nous vous fournirons une nouvelle clé API. En accédant à la page « Paramètres », vous pouvez copier la clé API comme indiqué sur l’image.
Étape 4 : Installez l’API
Installez l’API à l’aide du gestionnaire de paquets spécifique à votre langage de programmation.
Après l’installation, importez les bibliothèques nécessaires dans votre environnement de développement. Initialisez l’API avec votre clé API pour commencer à interagir avec le LLM de Novita AI. Voici un exemple d’utilisation de l’API de complétion de chat pour les utilisateurs Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/openai",
api_key="session_Um3Ozta39g2J__yeP9b_rOegzeA_qSYYquKzJS2oitKENIo8_H2FL2sCtl25-sKWjCY_wsmN18iuDp1zv_Xkaw==",
)
model = "google/gemma-3-12b-it"
stream = True # or False
max_tokens = 4096
system_content = "Be a helpful assistant"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Questions fréquemment posées
Qu’est-ce que Gemma-3-12B-it ?
Gemma-3-12B-it est un grand modèle de langage ajusté par instruction de la famille Gemma 3 de Google. Il prend en charge des entrées textuelles et multimodales et est optimisé pour le raisonnement en long contexte.
Pourquoi la VRAM est-elle importante lors de l’exécution de Gemma-3-12B-it ?
La VRAM détermine si le modèle peut être chargé et exécuté efficacement. Elle impacte la précision du modèle, la longueur de contexte, la taille de batch et la vitesse d’inférence globale.
Quelle quantité de VRAM est nécessaire pour exécuter Gemma-3-12B-it localement ?
En précision BF16 complète, il nécessite environ 24 Go rien que pour les poids et jusqu’à ~40 Go avec le cache. Les versions quantifiées peuvent s’exécuter avec 6 à 12 Go pour les poids, mais le cache pousse tout de même les exigences au-delà de 20 Go pour des contextes plus longs.
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles IA via notre API intuitive, tout en fournissant un cloud GPU abordable et fiable pour construire et mettre à l’échelle des projets.



