

在前一篇文章中,我們檢視了 GLM 4.7 Flash 的性能天花板,確立了它作為具備長上下文推理與強勁編碼能力的 Agent 級模型地位。緊接著評估後出現下一個實際障礙:要如何在本地部署這樣一個模型,又不用把基礎設施維護變成全職工作?
大多數開發者,尤其是構建私有 Agent 或端側系統的開發者,都會遇到三個具體痛點:環境不一致、設定成本高、執行時穩定性差。安裝 CUDA、對齊驅動程式、編譯執行環境、配置 API、調整記憶體往往會消耗比模型整合本身更多的時間。
本文聚焦於一個目標:以可預測、可重複、低摩擦的方式實現 GLM 4.7 Flash 的本地部署。透過 Novita AI 的 GPU 模板,我們將說明如何將原始 GPU 轉換為可投入生產的端點、GLM 4.7 Flash 如何適配主流 24GB 到 48GB 的硬體,以及初級開發者如何在幾分鐘內(而非數小時)完成部署。
什麼是 GPU 模板?
對初級開發者來說,GPU 模板就像「AI 版一鍵伺服器」。它不需要你安裝 CUDA、編譯推理引擎、調整記憶體限制或配置網路連線,你拿到的是已經運行、且提供 OpenAI 相容 API 的端點。
從概念上來說,模板會定義:
- 要運行哪個容器映像檔
- 容器如何啟動
- 需要多少磁碟空間
- 開放哪些連接埠
- 存在哪些環境變數
- 實例啟動時的行為方式
換句話說,模板會將原始 GPU 轉換為開箱即用的產品環境。
https://www.youtube.com/watch?v=RIiJZZsYITs
GPU 模板能解決什麼問題?
GPU 模板能將運行大型模型的運維負擔化繁為簡,把複雜的基礎設施轉換為開箱即用的服務。
對開發者(尤其是初級開發者)來說,這能解決三個具體問題。
第一,消除環境不確定性。
你不再需要糾結「哪個 CUDA 版本能用」、「哪個後端最穩定」、「該執行哪條指令」,模板已經以可執行形式給出了所有答案。
第二,將實驗流程壓縮到單一點擊。
你不再需要花數小時組裝 Docker 映像檔和啟動腳本,只要從模板庫中選擇對應模板,就能部署一個開箱即用的實例。首個 Token 的生成時間從數小時縮短到數分鐘。
第三,實現基礎設施層級的知識傳承。
模板本質上是「基礎設施即產品」:當有人搭建了一個高品質的 GLM-4.7 Flash 執行環境後,其他人不需要了解其內部原理,就能部署完全相同的環境。這也是平台鼓勵公開模板和 README 檔案的原因。
使用 GPU 模板,以上所有問題都已預先解決
| 維度 | 手動設定 | GPU 模板 |
|---|---|---|
| 環境 | 手動搭建 | 預先配置 |
| 模型 | 手動下載 | 預先載入 |
| 執行環境 | 本地編譯 | 開箱即用 |
| API | 自行實現 | 內建 |
| 穩定性 | 不可預測 | 生產級別 |
為什麼 GLM 4.7 Flash 非常適配 GPU 模板
GLM 4.7 Flash 特別適合在面向 Agent 的系統中進行本地部署,因為它將長期推理能力與實際硬體效率完美結合。
其 300 億參數的 MoE 架構,每個 Token 僅激活 36 億參數,推理成本接近中型模型,同時保留大型模型的能力,這使得基於 GPU 的本地模板不僅可行,而且性價比極高。
20 萬 Token 的上下文窗口能實現持久記憶、擴展規劃和穩定的多輪狀態追蹤,這些都是自主 Agent 的基礎能力。
| 基準測試 | GLM 4.7 Flash | Qwen3-30B | GPT-OSS-20B |
|---|---|---|---|
| AIME 25 | 91.6 | 85.0 | 91.7 |
| GPQA | 75.2 | 73.4 | 71.5 |
| SWE-bench Verified | 59.2 | 22.0 | 34.0 |
| τ²-Bench | 79.5 | 49.0 | 47.7 |
| BrowseComp | 42.8 | 2.29 | 28.3 |
基準測試結果進一步印證了它的 Agent 特質:在 AIME 上接近頂尖的數學推理能力、在 GPQA 上表現出強勁的碩士級理解能力、在 SWE-bench Verified 上具備真實世界的軟體工程能力、在 τ²-Bench 上展現穩健的多步驟規劃能力。
結合資訊整合任務的穩健表現,GLM 4.7 Flash 佔據了一個獨特的位置:它是一個快速、通用的模型,可以本地部署的同時,仍能提供高階推理、可靠的編碼能力和穩定的長鏈執行能力,是端側或私有 Agent 基礎設施的理想核心。
GLM 4.7 Flash 能從 GPU 模板獲得什麼、收益幾何?
將 GLM-4.7 Flash 與 GPU 模板結合使用,能為開發者帶來三個具體收益:確定性部署、本地規模的 Agent 級能力、多節點系統的運維簡化。你將獲得一個可重複的環境,其中 CUDA、VRAM、系統記憶體和磁碟都已與模型的 MoE 特性預先對齊,因此每個實例在區域和團隊間的行為都完全一致。
Novita AI 的 GPU 模板能讓這些能力在通用硬體上運行,且價格可預測。
由於每個 Token 僅激活少量參數,GLM-4.7 Flash 能在 24GB 到 48GB 的 GPU 上高效運行,這正好落在消費級和專業級顯卡的價格區間內。
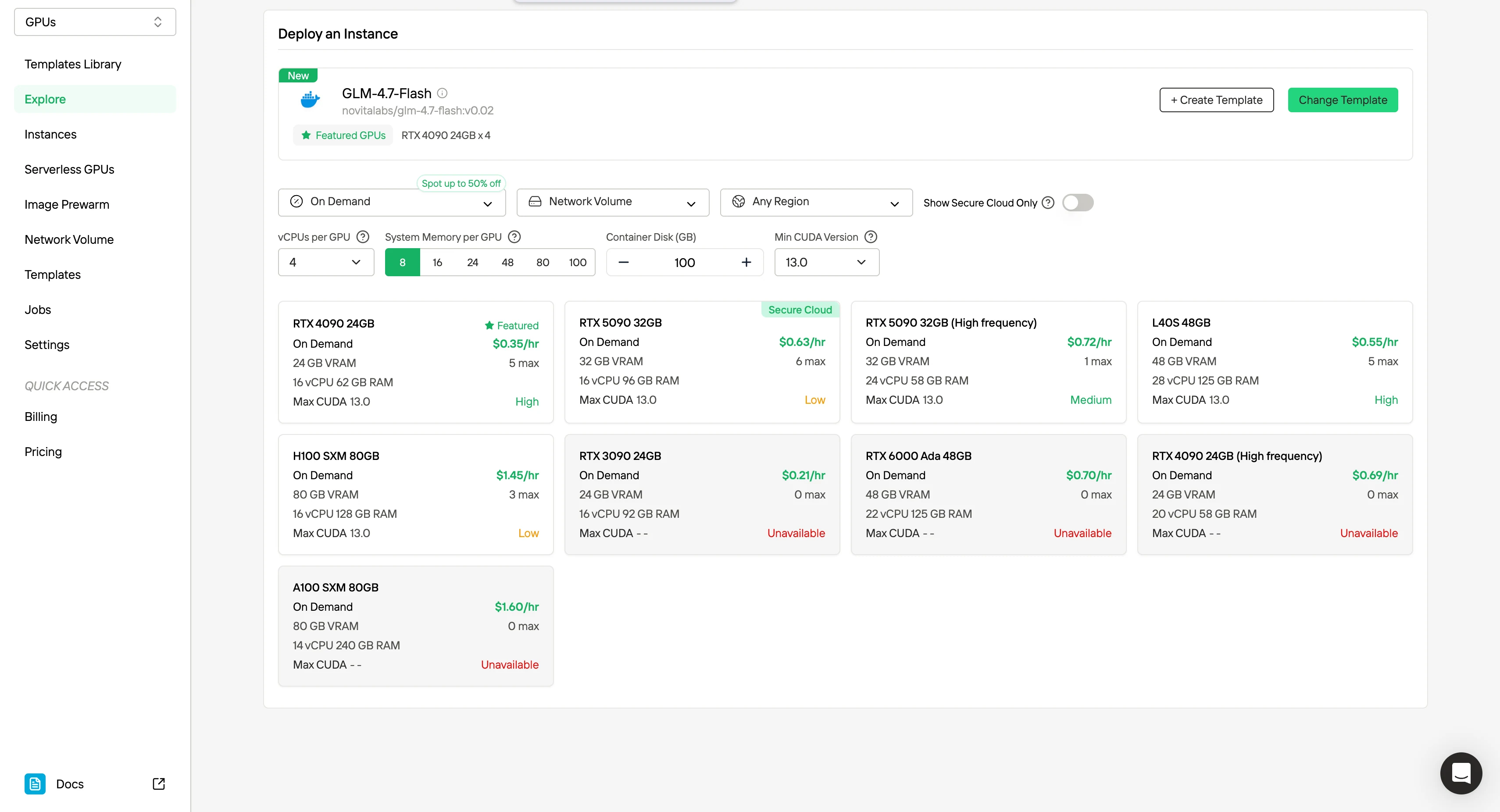
| GPU 等級 | VRAM | 典型每小時成本 | 部署層級 |
|---|---|---|---|
| RTX 3090 / RTX 4090 | 24GB | $0.21–$0.35 | 最低生產級別 |
| RTX 5090 | 32GB | $0.60–$0.70 | 額外效能空間 |
| L40S / RTX 6000 Ada | 48GB | $0.55–$0.70 | Agent 部署推薦 |
| H100 / A100 | 80GB | $1.40+ | 對 Flash 來說性能過剩 |
使用 GPU 模板後:
- 24GB 節點可作為可行的 Agent 工作節點
- 48GB 節點可承載完整上下文、多工具 Agent
- 集群擴展的成本和投入呈線性關係
這實現了以下的成本結構:
- Agent 節點每小時成本低於 1 美元
- 擴展的瓶頸在於邏輯,而非基礎設施
- 本地或私有部署在經濟上仍可行
因此 GLM-4.7 Flash 佔據了一個獨特的位置:它提供了 Agent 級推理和長上下文行為,同時符合主流 GPU 的經濟成本區間。GPU 模板將這種架構優勢轉化為實際系統的可實踐、可重複部署模型。
初級開發者如何搭配 Novita AI GPU 模板使用 GLM 4.7 Flash?
步驟 1:進入控制台
啟動 GPU 介面,選擇「開始使用」進入部署管理頁面。
步驟 2:選擇套件
在模板庫中找到 GLM-4.7-Flash,開始安裝流程。
步驟 3:基礎設施設定
配置計算參數,包括記憶體分配、儲存需求和網路設定,選擇「部署」即可執行。
步驟 4:檢查並建立
再次確認你的配置細節和費用摘要,確認無誤後點擊「部署」開始建立流程。
步驟 5:等待建立完成
啟動部署後,系統會自動跳轉到實例管理頁面,你的實例會在背景中建立。
步驟 6:監控下載進度
即時追蹤映像檔下載進度,部署完成後實例狀態會從「拉取中」變為「運行中」,你可以點擊實例名稱旁的箭頭圖示查看詳細進度。
步驟 7:驗證實例狀態
點擊「日誌」按鈕查看實例日誌,確認 InvokeAI 服務已正常啟動。
步驟 8:環境存取
透過「連接」介面啟動開發空間,然後初始化「啟動 Web 終端」。
步驟 9:演示
curl --location --request POST 'http://127.0.0.1:8000/v1/chat/completions' \
> --header 'Content-Type: application/json' \
> --header 'Accept: */*' \
> --header 'Connection: keep-alive' \
> --data-raw '{
> "model": "zai-org/GLM-4.7-Flash",
> "messages": [
> {
> "role": "system",
> "content": "you are a helpful assitant."
> },
> {
> "role": "user",
> "content": "hello"
> }
> ],
> "max_tokens": 20,
> "stream": false
> }'
{"id":"chatcmpl-943f20f1c3a690ba","object":"chat.completion","created":1768823899,"model":"zai-org/GLM-4.7-Flash","choices":[{"index":0,"message":{"role":"assistant","content":"1. **Analyze the Input:** The user said \"hello\".\
2. **Ident","refusal":null,"annotations":null,"audio":null,"function_call":null,"tool_calls":[],"reasoning":null,"reasoning_content":null},"logprobs":null,"finish_reason":"length","stop_reason":null,"token_ids":null}],"service_tier":null,"system_fingerprint":null,"usage":{"prompt_tokens":14,"total_tokens":34,"completion_tokens":20,"prompt_tokens_details":null},"prompt_logprobs":null,"prompt_token_ids":null,"kv_transfer_params":null}
GPU 模板能將 GLM 4.7 Flash 從強大的基準測試模型轉變為實用的本地 Agent 核心。透過預先解決環境設定、執行環境配置和 API 暴露問題,它能實現主流 GPU 上的確定性部署。這使得 Agent 級推理、長上下文記憶和多步驟規劃能力,在私有和端側系統中具備經濟和運維上的可行性。
為什麼 GLM 4.7 Flash 適合搭配 GPU 模板進行本地部署? GLM 4.7 Flash 每個 Token 僅激活少量參數,因此能在 24GB 到 48GB 的 GPU 上高效運行,同時保留長上下文和 Agent 級推理能力。
GPU 模板能為 GLM 4.7 Flash 使用者解決什麼問題? GPU 模板透過預先配置 CUDA、執行環境、API 端點和儲存,消除了 GLM 4.7 Flash 的環境不確定性,確保每個 GLM 4.7 Flash 實例的行為一致。
什麼硬體足夠運行生產級別的 GLM 4.7 Flash? GLM 4.7 Flash 在 RTX 3090、RTX 4090、L40S 和 RTX 6000 Ada 等級的 GPU 上都能高效運行,因此可以在廣泛普及的硬體上部署。
Novita AI 是一個 AI 雲端平台,為開發者提供簡單的 API 來部署 AI 模型,同時也提供平價、可靠的 GPU 雲端服務,用於構建和擴展 AI 應用。



