

في المقال السابق، فحصنا السقف الأدائي لنموذج GLM 4.7 Flash وثبتنا مكانته كنموذج من فئة الوكلاء مع قدرة على الاستدلال سياقي طويل وقدرة برمجية قوية. العائق الحقيقي التالي يظهر فور الانتهاء من التقييم: كيف يمكن نشر مثل هذا النموذج محليًا دون تحويل البنية التحتية إلى وظيفة بدوام كامل؟
يواجه معظم المطورين، خاصة أولئك الذين يبنون وكلاء خاصين أو أنظمة على الجهاز، ثلاث احتكاكات ملموسة: عدم اتساق البيئة، تكلفة إعداد عالية، واستقرار وقت التشغيل الهش. غالبًا ما يستغرق تثبيت CUDA، ومحاذاة برامج التشغيل، وتجميع أوقات التشغيل، وتكوين واجهات برمجة التطبيقات، وضبط الذاكرة وقتًا أكثر من تكامل النموذج نفسه.
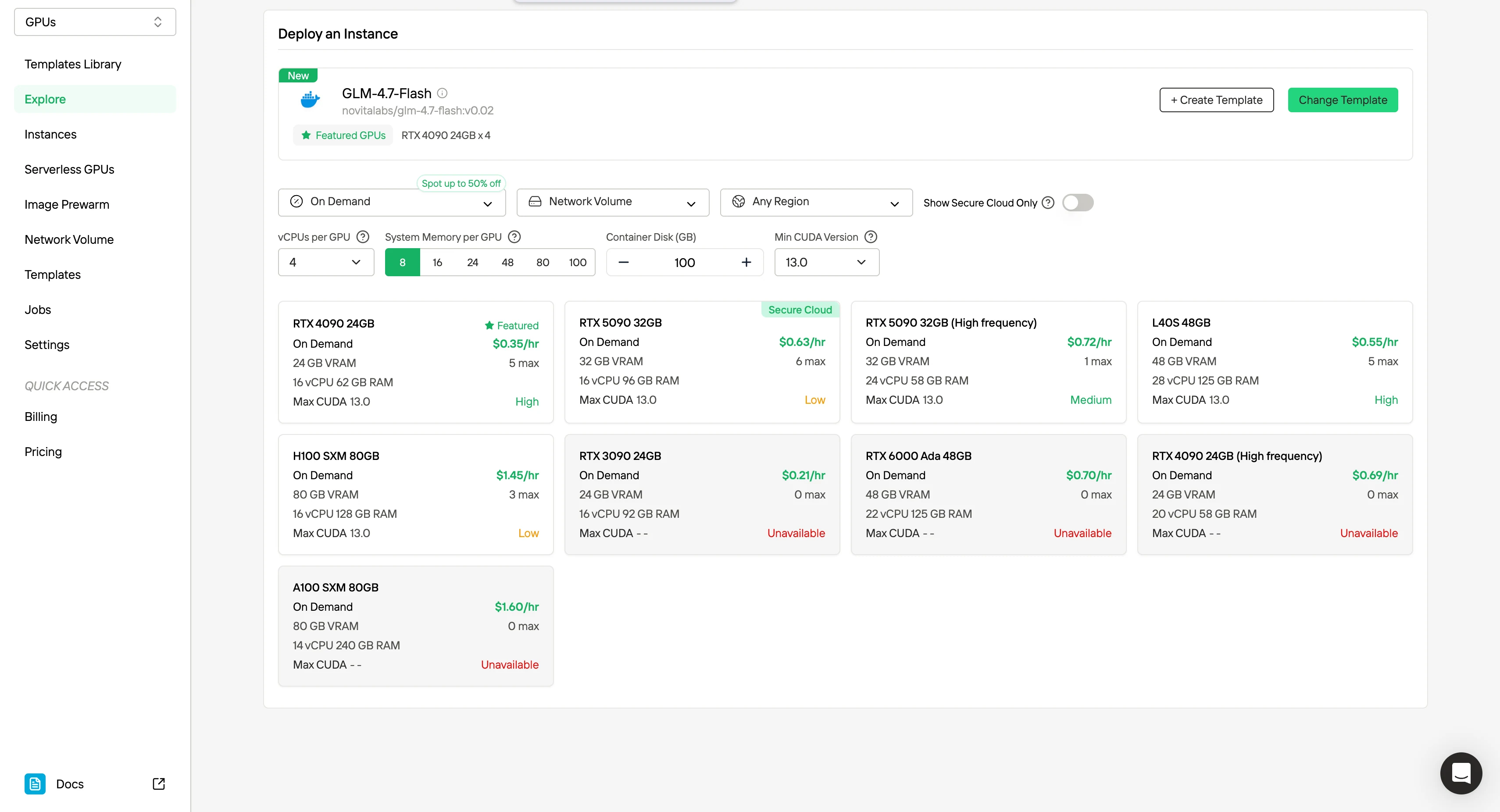
يركز هذا المقال على هدف واحد: جعل نموذج GLM 4.7 Flash قابلًا للنشر محليًا بطريقة يمكن التنبؤ بها، وقابلة للتكرار، وذات احتكاك منخفض. من خلال قوالب GPU على Novita AI، نشرح كيف يتم تحويل وحدات GPU الخام إلى نقاط نهاية جاهزة للإنتاج، وكيف يتناسب نموذج GLM 4.7 Flash مع أجهزة 24 جيجابايت إلى 48 جيجابايت السائدة، وكيف يمكن لمطور مبتدئ إتمام النشر في دقائق بدلاً من ساعات.
ما هو قالب GPU؟
بالنسبة لمطور مبتدئ، يعمل قالب GPU مثل “خادم بنقرة واحدة للذكاء الاصطناعي”. يلغي الحاجة إلى تثبيت CUDA، أو تجميع محركات الاستدلال، أو ضبط حدود الذاكرة، أو توصيل الشبكة. تحصل على نقطة نهاية قيد التشغيل تعرض بالفعل واجهة برمجة تطبيقات متوافقة مع OpenAI.
على مستوى مفاهيمي، يحدد القالب ما يلي:
- أي صورة حاوية لتشغيلها
- كيف تبدأ الحاوية
- مقدار المساحة التخزينية المطلوبة
- أي المنافذ يتم كشفها
- أي متغيرات البيئة موجودة
- كيف يتصرف المثال عند الإقلاع
بعبارة أخرى، يحول القالب وحدة GPU الخام إلى بيئة منتج جاهزة للاستخدام.
https://www.youtube.com/watch?v=RIiJZZsYITs
جرّب نموذج GLM 4.7 Flash الآن!
ما المشكلة التي يحلها قالب GPU؟
يلغي قالب GPU العبء التشغيلي لتشغيل النماذج الكبيرة عن طريق تحويل البنية التحتية المعقدة إلى خدمة جاهزة للاستخدام.
بالنسبة للمطور، خاصة المبتدئ، يحل هذا ثلاث مشاكل ملموسة.
أولاً، يلغي عدم اليقين في البيئة. لم تعد تسأل “أي إصدار من CUDA يعمل”، “أي خلفية مستقرة”، أو “أي أمر يجب أن أشغله”. يجيب القالب بالفعل عن هذه الأسئلة بشكل قابل للتنفيذ.
ثانيًا، يحول التجربة إلى نقرة واحدة. بدلاً من قضاء ساعات في تجميع صور Docker ونصوص بدء التشغيل، تختار قالبًا من المكتبة وتنشر مثالًا يعمل بالفعل. ينخفض الوقت حتى الرمز الأول من ساعات إلى دقائق.
ثالثًا، يتيح نقل المعرفة على مستوى البنية التحتية. القالب هو فعليًا “البنية التحتية كمنتج”. عندما يبني شخص ما وقت تشغيل عالي الجودة لنموذج GLM-4.7 Flash، يمكن للآخرين نشر نفس البيئة بالضبط دون فهم أي من تفاصيلها الداخلية. هذا هو السبب في أن المنصة تشجع القوالب العامة وملفات README.
باستخدام قالب GPU، كل هذا تم حله مسبقًا
| البعد | الإعداد اليدوي | قالب GPU |
|---|---|---|
| البيئة | مبني يدويًا | مهيأ مسبقًا |
| النموذج | تم تنزيله يدويًا | محمّل مسبقًا |
| وقت التشغيل | مجمّع محليًا | جاهز |
| واجهة برمجة التطبيقات | منفذ ذاتيًا | مدمج |
| الاستقرار | غير قابل للتنبؤ | من فئة الإنتاج |
لماذا يتناسب نموذج GLM 4.7 Flash مع قوالب GPU
يتناسب نموذج GLM 4.7 Flash بشكل خاص مع النشر المحلي في الأنظمة الموجهة للوكلاء لأنه يربط بين الاستدلال طويل الأمد وكفاءة الأجهزة العملية.
تعمل بنية MoE الخاصة به ذات المعلمات 30 مليار على تنشيط 3.6 مليار معلمة فقط لكل رمز، مما يحافظ على تكاليف الاستدلال قريبة من تكاليف النماذج متوسطة الحجم مع الاحتفاظ بقدرات النماذج الكبيرة، مما يجعل القوالب المحلية القائمة على GPU ممكنة من الناحية العملية وذات تكلفة فعالة.
تتيح نافذة السياق ذات 200 ألف رمز ذاكرة دائمة، وتخطيط ممتد، وتتبع حالة متعددة الأدوار مستقر، وجميعها أساسية للوكلاء المستقلين.
| معيار الاختبار | GLM 4.7 Flash | Qwen3-30B | GPT-OSS-20B |
|---|---|---|---|
| AIME 25 | 91.6 | 85.0 | 91.7 |
| GPQA | 75.2 | 73.4 | 71.5 |
| SWE-bench Verified | 59.2 | 22.0 | 34.0 |
| τ²-Bench | 79.5 | 49.0 | 47.7 |
| BrowseComp | 42.8 | 2.29 | 28.3 |
تؤكد نتائج معايير الاختبار ملفه كوكيل بشكل أكبر: استدلال رياضي قريب من المستوى الأعلى على AIME، فهم قوي على مستوى الدراسات العليا على GPQA، كفاءة في هندسة البرمجيات في العالم الحقيقي على SWE-bench Verified، وتخطيط متعدد الخطوات قوي على τ²-Bench.
بالإضافة إلى أداء قوي في مهام تركيب المعلومات، يشغل نموذج GLM 4.7 Flash مكانة نادرة كنموذج سريع متعدد الأغراض يمكن نشره محليًا مع تقديم استدلال عالي المستوى، وقدرة برمجية موثوقة، وتنفيذ سلسلة طويلة متين، مما يجعله العمود الفقري المثالي للبنى التحتية للوكلاء على الأجهزة أو الخاصة.
ماذا يكتسب نموذج GLM 4.7 Flash من قوالب GPU وكم؟
يمنح استخدام قوالب GPU مع نموذج GLM-4.7 Flash المطورين ثلاث مكاسب ملموسة: نشر حتمي، وقدرات من فئة الوكلاء على نطاق محلي، وبساطة تشغيلية للأنظمة متعددة العقد. تحصل على بيئة قابلة للتكرار حيث يتم محاذاة CUDA، وذاكرة الوصول العشوائي للفيديو (VRAM)، وذاكرة النظام، والمساحة التخزينية مسبقًا مع ملف MoE الخاص بالنموذج، لذا يتصرف كل مثال بشكل متطابق عبر المناطق والفرق.
تتيح قوالب GPU من Novita AI تشغيل هذه القدرات على أجهزة استهلاكية ذات تسعير يمكن التنبؤ به.
نظرًا لتنشيط مجموعة فرعية صغيرة فقط من المعلمات لكل رمز، يعمل نموذج GLM-4.7 Flash بكفاءة على وحدات GPU ذات 24 جيجابايت إلى 48 جيجابايت. هذا يضعه مباشرة في فئة أسعار البطاقات الاستهلاكية وشبه الاحترافية المتاحة على نطاق واسع.
جرّب نموذج GLM 4.7 Flash الآن!
| فئة GPU | VRAM | التكلفة الساعية النموذجية | مستوى النشر |
|---|---|---|---|
| RTX 3090 / RTX 4090 | 24 جيجابايت | 0.21–0.35 دولار | إنتاج أدنى |
| RTX 5090 | 32 جيجابايت | 0.60–0.70 دولار | مساحة إضافية محسنة |
| L40S / RTX 6000 Ada | 48 جيجابايت | 0.55–0.70 دولار | موصى به للوكلاء |
| H100 / A100 | 80 جيجابايت | 1.40+ دولار | مبالغ فيه لنموذج Flash |
باستخدام قوالب GPU:
- تصبح العقدة ذات 24 جيجابايت عامل وكيل قابلًا للتطبيق
- يمكن للعقدة ذات 48 جيجابايت استضافة وكلاء بسياق كامل وأدوات متعددة
- يتم توسيع الأسطول بشكل خطي من حيث التكلفة والجهد
يتيح هذا بنية تكلفة حيث:
- عقد الوكلاء أقل من دولار واحد في الساعة
- التوسع محدد بالمنطق، وليس بالبنية التحتية
- تظل النشرات المحلية أو الخاصة مجدية من الناحية الاقتصادية
لذلك يشغل نموذج GLM-4.7 Flash مكانة نادرة: فهو يقدم استدلالًا من فئة الوكلاء وسلوك سياقي طويل مع الاندماج في الغلاف الاقتصادي لوحدات GPU السائدة. تحول قوالب GPU هذه الميزة المعمارية إلى نموذج نشر عملي وقابل للتكرار للأنظمة الحقيقية.
كيف يستخدم المطور المبتدئ نموذج GLM 4.7 Flash مع قالب GPU من Novita AI؟
الخطوة 1: الدخول إلى وحدة التحكم
أطلق واجهة GPU واختر “ابدأ” للوصول إلى إدارة النشر.
الخطوة 2: اختيار الحزمة
ابحث عن نموذج GLM-4.7-Flash في مستودع القوالب وابدأ تسلسل التثبيت.
جرّب نموذج GLM 4.7 Flash الآن!
الخطوة 3: إعداد البنية التحتية
قم بتكوين معلمات الحوسبة بما في ذلك تخصيص الذاكرة، ومتطلبات المساحة التخزينية، وإعدادات الشبكة. اختر “نشر” للتنفيذ.
الخطوة 4: المراجعة والإنشاء
تحقق مرة أخرى من تفاصيل التكوين وملخص التكلفة. عندما تكون راضيًا، انقر على “نشر” لبدء عملية الإنشاء.
الخطوة 5: انتظر الإنشاء
بعد بدء النشر، سيعيد النظام توجيهك تلقائيًا إلى صفحة إدارة المثال. سيتم إنشاء مثيلك في الخلفية.
الخطوة 6: مراقبة تقدم التنزيل
تتبع تقدم تنزيل الصورة في الوقت الفعلي. ستتغير حالة مثيلك من “سحب” إلى “قيد التشغيل” بمجرد اكتمال النشر. يمكنك عرض التقدم التفصيلي بالنقر على أيقونة السهم بجانب اسم مثيلك.
الخطوة 7: التحقق من حالة المثال
انقر على زر “السجلات” لعرض سجلات المثال وتأكيد بدء خدمة InvokeAI بشكل صحيح.
الخطوة 8: الوصول إلى البيئة
أطلق مساحة التطوير من خلال واجهة “الاتصال”، ثم قم بتهيئة “بدء طرفية الويب”.
الخطوة 9: عرض تجريبي
curl --location --request POST 'http://127.0.0.1:8000/v1/chat/completions' \
> --header 'Content-Type: application/json' \
> --header 'Accept: */*' \
> --header 'Connection: keep-alive' \
> --data-raw '{
> "model": "zai-org/GLM-4.7-Flash",
> "messages": [
> {
> "role": "system",
> "content": "you are a helpful assitant."
> },
> {
> "role": "user",
> "content": "hello"
> }
> ],
> "max_tokens": 20,
> "stream": false
> }'
{"id":"chatcmpl-943f20f1c3a690ba","object":"chat.completion","created":1768823899,"model":"zai-org/GLM-4.7-Flash","choices":[{"index":0,"message":{"role":"assistant","content":"1. **Analyze the Input:** The user said \"hello\".\
2. **Ident","refusal":null,"annotations":null,"audio":null,"function_call":null,"tool_calls":[],"reasoning":null,"reasoning_content":null},"logprobs":null,"finish_reason":"length","stop_reason":null,"token_ids":null}],"service_tier":null,"system_fingerprint":null,"usage":{"prompt_tokens":14,"total_tokens":34,"completion_tokens":20,"prompt_tokens_details":null},"prompt_logprobs":null,"prompt_token_ids":null,"kv_transfer_params":null}
تحول قوالب GPU نموذج GLM 4.7 Flash من نموذج معايير قوي إلى عمود فقري عملي للوكلاء المحليين. من خلال حل مسبق لمشاكل إعداد البيئة، وتكوين وقت التشغيل، وكشف واجهة برمجة التطبيقات، فإنها تتيح نشرًا حتميًا على وحدات GPU السائدة. هذا يحول الاستدلال من فئة الوكلاء، والذاكرة السياقية الطويلة، والتخطيط متعدد الخطوات إلى قدرات مجدية من الناحية الاقتصادية والتشغيلية للأنظمة الخاصة وعلى الأجهزة.
لماذا يتناسب نموذج GLM 4.7 Flash مع النشر المحلي باستخدام قوالب GPU؟ ينشط نموذج GLM 4.7 Flash مجموعة فرعية صغيرة فقط من المعلمات لكل رمز، مما يسمح له بالعمل بكفاءة على وحدات GPU ذات 24 جيجابايت إلى 48 جيجابايت مع الحفاظ على الاستدلال السياقي الطويل ومن فئة الوكلاء.
ما المشكلة التي يحلها قالب GPU لمستخدمي نموذج GLM 4.7 Flash؟ يزيل قالب GPU عدم اليقين في البيئة لنموذج GLM 4.7 Flash عن طريق تكوين CUDA، ووقت التشغيل، ونقاط نهاية واجهة برمجة التطبيقات، والتخزين مسبقًا بحيث يتصرف كل مثال من نماذج GLM 4.7 Flash بشكل متسق.
ما الأجهزة الكافية لتشغيل نموذج GLM 4.7 Flash في الإنتاج؟ يعمل نموذج GLM 4.7 Flash بفعالية على وحدات GPU من فئة RTX 3090 و RTX 4090 و L40S و RTX 6000 Ada، مما يجعل نموذج GLM 4.7 Flash قابلًا للتطبيق على الأجهزة المتاحة على نطاق واسع.
Novita AI هي منصة سحابية للذكاء الاصطناعي تقدم للمطورين طريقة سهلة لنشر نماذج الذكاء الاصطناعي باستخدام واجهة برمجة التطبيقات البسيطة الخاصة بنا، مع توفير سحابة GPU بأسعار معقولة وموثوقة للبناء والتوسع.



