

В предыдущей статье мы рассмотрели производительностный потолок GLM 4.7 Flash и определили его позицию как модели агентного класса с возможностью длинного контекстного рассуждения и сильными навыками написания кода. Следующее реальное препятствие появляется сразу после оценки: как можно развернуть такую модель локально, не превратив инфраструктуру в полноценную работу на полный день?
Большинство разработчиков, особенно тех, кто создает частных агентов или встроенные системы, сталкиваются с тремя конкретными сложностями: непредсказуемость окружения, высокая стоимость настройки и хрупкая стабильность во время выполнения. Установка CUDA, согласование драйверов, компиляция рантаймов, настройка API и тюнинг памяти часто занимают больше времени, чем сама интеграция модели.
Эта статья сосредоточена на одной цели: сделать GLM 4.7 Flash локально развертываемым предсказуемым, повторяемым и с минимальными сложностями способом. С помощью GPU-шаблонов на Novita AI мы объясним, как не настроенные GPU преобразуются в готовые к продакшену конечные точки, как GLM 4.7 Flash подходит для распространенного оборудования на 24–48 ГБ, и как начинающий разработчик может завершить развертывание за минуты, а не за часы.
Что такое GPU-шаблон?
Для начинающего разработчика GPU-шаблон работает как «однокликовый сервер для ИИ». Он устраняет необходимость установки CUDA, компиляции движков вывода, тюнинга лимитов памяти или настройки сети. Вы получаете работающую конечную точку, которая уже предоставляет совместимый с OpenAI API.
На концептуальном уровне шаблон определяет:
- Какой контейнерный образ запускать
- Как запускается контейнер
- Сколько диска ему нужно
- Какие порты открыты
- Какие переменные окружения существуют
- Как экземпляр ведет себя при загрузке
Другими словами, шаблон превращает не настроенный GPU в готовое к использованию продуктовое окружение.
https://www.youtube.com/watch?v=RIiJZZsYITs
Попробуйте GLM 4.7 Flash сейчас!
Какую проблему решает GPU-шаблон?
GPU-шаблон устраняет операционную нагрузку от запуска больших моделей, превращая сложную инфраструктуру в готовый к использованию сервис.
Для разработчика, особенно начинающего, это решает три конкретные проблемы.
Во-первых, он устраняет непредсказуемость окружения.
Вы больше не задаетесь вопросами «Какая версия CUDA подойдет», «Какой бэкенд стабилен» или «Какую команду нужно запустить». Шаблон уже отвечает на эти вопросы в исполняемой форме.
Во-вторых, он превращает экспериментирование в один клик.
Вместо того чтобы тратить часы на сборку Docker-образов и стартовых скриптов, вы выбираете шаблон из библиотеки и развертываете экземпляр, который уже работает. Время до первого токена сокращается с часов до минут.
В-третьих, он позволяет передавать знания на уровне инфраструктуры.
Шаблон по сути является «инфраструктурой как продукт». Когда кто-то создает высококачественный рантайм GLM-4.7 Flash, другие могут развернуть точно такое же окружение, не понимая никаких его внутренних механизмов. Именно поэтому платформа поощряет публичные шаблоны и файлы README.
С GPU-шаблоном все это уже предрешено
| Параметр | Ручная настройка | GPU-шаблон |
|---|---|---|
| Окружение | Создается вручную | Преднастроено |
| Модель | Загружается вручную | Предзагружена |
| Рантайм | Компилируется локально | Готов к работе |
| API | Реализуется самостоятельно | Встроен |
| Стабильность | Непредсказуема | Продуктивного уровня |
Почему GLM 4.7 Flash подходит для GPU-шаблонов
GLM 4.7 Flash особенно хорошо подходит для локального развертывания в агентных системах, поскольку сочетает долгосрочное рассуждение с практической эффективностью использования оборудования.
Его архитектура MoE с 30 млрд параметров активирует только 3,6 млрд параметров на токен, что сохраняет затраты на вывод ближе к моделям среднего размера, сохраняя при этом возможности больших моделей. Это делает локальные GPU-шаблоны как выполнимыми, так и экономически эффективными.
Окно контекста на 200K токенов обеспечивает постоянную память, расширенное планирование и стабильное отслеживание многоходового состояния, все это является основой для автономных агентов.
| Бенчмарк | GLM 4.7 Flash | Qwen3-30B | GPT-OSS-20B |
|---|---|---|---|
| AIME 25 | 91,6 | 85,0 | 91,7 |
| GPQA | 75,2 | 73,4 | 71,5 |
| SWE-bench Verified | 59,2 | 22,0 | 34,0 |
| τ²-Bench | 79,5 | 49,0 | 47,7 |
| BrowseComp | 42,8 | 2,29 | 28,3 |
Результаты бенчмарков дополнительно подтверждают его профиль для агентов: близкий к топовому математическое рассуждение на AIME, сильное понимание на уровне выпускников вузов на GPQA, реальная компетенция в программной инженерии на SWE-bench Verified и надежное многошаговое планирование на τ²-Bench.
В сочетании с устойчивой производительностью в задачах синтеза информации GLM 4.7 Flash занимает редкую позицию быстрой универсальной модели, которую можно локально развернуть, при этом сохраняя высокоуровневое рассуждение, надежные навыки написания кода и устойчивое выполнение длинных цепочек задач, что делает его идеальной основой для встроенных или частных инфраструктур агентов.
Что получает GLM 4.7 Flash от GPU-шаблонов и сколько это стоит?
Использование GPU-шаблонов с GLM-4.7 Flash дает разработчикам три конкретных преимущества: детерминированное развертывание, возможности уровня агентов в локальном масштабе и операционную простоту для многоузловых систем. Вы получаете повторяемое окружение, где CUDA, VRAM, системная память и диск предварительно согласованы с MoE-профилем модели, поэтому каждый экземпляр ведет себя одинаково в разных регионах и командах.
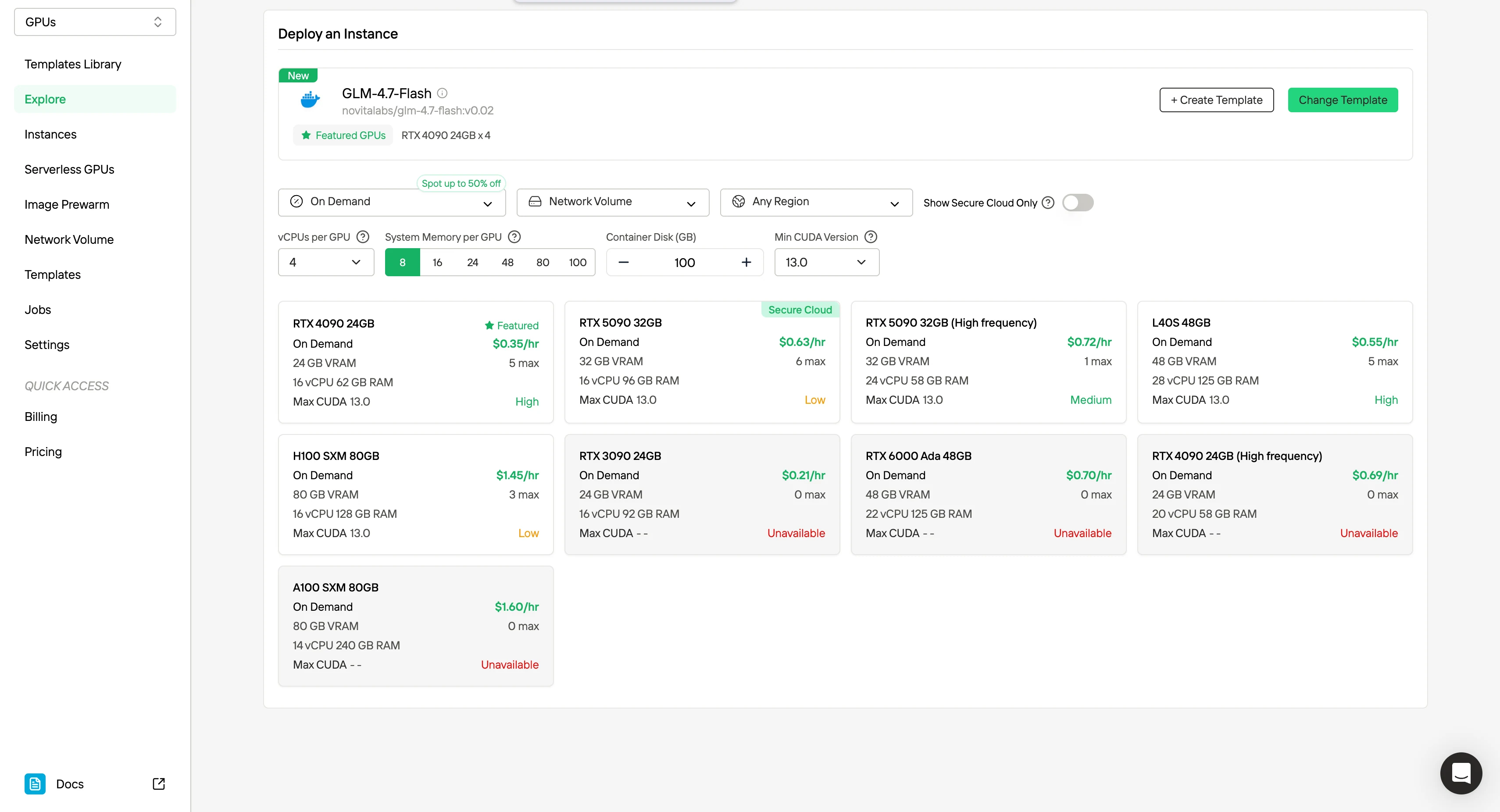
GPU-шаблоны Novita AI позволяют запускать эти возможности на широко доступном оборудовании с предсказуемой стоимостью.
Поскольку только небольшая подмножество параметров активна на каждый токен, GLM-4.7 Flash эффективно работает на GPU с 24 до 48 ГБ. Это помещает его прямо в ценовой диапазон широко доступных потребительских и полупрофессиональных видеокарт.
Попробуйте GLM 4.7 Flash сейчас!
| Класс GPU | Объем VRAM | Типичная почасовая стоимость | Уровень развертывания |
|---|---|---|---|
| RTX 3090 / RTX 4090 | 24GB | $0.21–$0.35 | Минимальный уровень для продакшена |
| RTX 5090 | 32GB | $0.60–$0.70 | Расширенный запас ресурсов |
| L40S / RTX 6000 Ada | 48GB | $0.55–$0.70 | Рекомендуется для агентов |
| H100 / A100 | 80GB | $1.40+ | Избыточно для Flash |
С GPU-шаблонами:
- Узел на 24 ГБ становится пригодным для использования рабочим агентом
- Узел на 48 ГБ может размещать агентов с полным контекстом и несколькими инструментами
- Масштабирование парка линейно по стоимости и усилиям
Это позволяет получить такую структуру затрат:
- Стоимость узлов агентов составляет менее одного доллара в час
- Масштабирование ограничено логикой, а не инфраструктурой
- Локальные или частные развертывания остаются экономически жизнеспособными
GLM-4.7 Flash поэтому занимает редкую позицию: он предоставляет возможности рассуждения уровня агентов и поведение с длинным контекстом, при этом вписываясь в экономический конверт распространенных GPU. GPU-шаблоны превращают это архитектурное преимущество в практическую, повторяемую модель развертывания для реальных систем.
Как начинающий разработчик использует GLM 4.7 Flash с GPU-шаблоном Novita AI?
Шаг 1: Вход в консоль
Запустите GPU-интерфейс и выберите «Начать», чтобы получить доступ к управлению развертыванием.
Шаг 2: Выбор пакета
Найдите GLM-4.7-Flash в репозитории шаблонов и начните последовательность установки.
Попробуйте GLM 4.7 Flash сейчас!
Шаг 3: Настройка инфраструктуры
Настройте вычислительные параметры, включая распределение памяти, требования к хранилищу и сетевые настройки. Выберите «Развернуть» для применения.
Шаг 4: Проверка и создание
Дважды проверьте детали конфигурации и сводку по стоимости. Если все удовлетворяет, нажмите «Развернуть», чтобы начать процесс создания.
Шаг 5: Ожидание создания
После запуска развертывания система автоматически перенаправит вас на страницу управления экземплярами. Ваш экземпляр будет создан в фоновом режиме.
Шаг 6: Мониторинг прогресса загрузки
Отслеживайте прогресс загрузки образа в реальном времени. Статус вашего экземпляра изменится с «Загрузка» на «Работает» после завершения развертывания. Подробный прогресс можно посмотреть, нажав на иконку стрелки рядом с именем вашего экземпляра.
Шаг 7: Проверка статуса экземпляра
Нажмите кнопку «Логи», чтобы просмотреть логи экземпляра и подтвердить, что сервис InvokeAI запустился корректно.
Шаг 8: Доступ к окружению
Запустите пространство разработки через интерфейс «Подключение», затем инициализируйте «Запустить веб-терминал».
Шаг 9: Демонстрация
curl --location --request POST 'http://127.0.0.1:8000/v1/chat/completions' \
> --header 'Content-Type: application/json' \
> --header 'Accept: */*' \
> --header 'Connection: keep-alive' \
> --data-raw '{
> "model": "zai-org/GLM-4.7-Flash",
> "messages": [
> {
> "role": "system",
> "content": "you are a helpful assitant."
> },
> {
> "role": "user",
> "content": "hello"
> }
> ],
> "max_tokens": 20,
> "stream": false
> }'
{"id":"chatcmpl-943f20f1c3a690ba","object":"chat.completion","created":1768823899,"model":"zai-org/GLM-4.7-Flash","choices":[{"index":0,"message":{"role":"assistant","content":"1. **Analyze the Input:** The user said \"hello\".\
2. **Ident","refusal":null,"annotations":null,"audio":null,"function_call":null,"tool_calls":[],"reasoning":null,"reasoning_content":null},"logprobs":null,"finish_reason":"length","stop_reason":null,"token_ids":null}],"service_tier":null,"system_fingerprint":null,"usage":{"prompt_tokens":14,"total_tokens":34,"completion_tokens":20,"prompt_tokens_details":null},"prompt_logprobs":null,"prompt_token_ids":null,"kv_transfer_params":null}
GPU-шаблоны превращают GLM 4.7 Flash из мощной бенчмарк-модели в практическую локальную основу для агентов. Предварительно решая проблемы настройки окружения, конфигурации рантайма и предоставления API, они обеспечивают детерминированное развертывание на распространенных GPU. Это превращает возможности рассуждения уровня агентов, память длинного контекста и многошаговое планирование в возможности, которые экономически и операционно жизнеспособны для частных и встроенных систем.
Почему GLM 4.7 Flash подходит для локального развертывания с GPU-шаблонами? GLM 4.7 Flash активирует только небольшую подмножество параметров на каждый токен, что позволяет ему эффективно работать на GPU с 24 до 48 ГБ, сохраняя при этом возможности длинного контекста и рассуждения уровня агентов.
Какую проблему решает GPU-шаблон для пользователей GLM 4.7 Flash? GPU-шаблон устраняет непредсказуемость окружения для GLM 4.7 Flash, предварительно настраивая CUDA, рантайм, конечные точки API и хранилище, поэтому каждый экземпляр GLM 4.7 Flash ведет себя последовательно.
Какое оборудование достаточно для запуска GLM 4.7 Flash в продакшене? GLM 4.7 Flash эффективно работает на GPU классов RTX 3090, RTX 4090, L40S и RTX 6000 Ada, что делает его жизнеспособным на широко доступном оборудовании.
Novita AI — это облачная ИИ-платформа, которая предлагает разработчикам простой способ развертывать ИИ-модели с помощью нашего простого API, а также предоставляет доступное и надежное облако GPU для построения и масштабирования.



