

No artigo anterior, analisamos o limite de desempenho do GLM 4.7 Flash e estabelecemos sua posição como um modelo de nível para agentes, com raciocínio de longo contexto e forte capacidade de programação. O próximo obstáculo real aparece imediatamente após a avaliação: como implantar tal modelo localmente sem transformar a infraestrutura em um trabalho de tempo integral?
A maioria dos desenvolvedores, especialmente aqueles que constroem agentes privados ou sistemas no dispositivo, enfrentam três atritos concretos: inconsistência de ambiente, alto custo de configuração e estabilidade de execução frágil. Instalar o CUDA, alinhar drivers, compilar tempos de execução, configurar APIs e ajustar a memória geralmente consome mais tempo do que a própria integração do modelo.
Este artigo tem um objetivo único: tornar o GLM 4.7 Flash implantável localmente de forma previsível, repetível e com baixo atrito. Por meio de modelos de GPU na Novita AI, explicamos como GPUs brutas são convertidas em endpoints prontos para produção, como o GLM 4.7 Flash se adapta a hardware convencional de 24GB a 48GB e como um desenvolvedor júnior pode concluir a implantação em minutos, em vez de horas.
O que é um Modelo de GPU?
Para um desenvolvedor júnior, um modelo de GPU funciona como um “servidor de IA com um clique”. Ele elimina a necessidade de instalar o CUDA, compilar motores de inferência, ajustar limites de memória ou configurar redes. Você recebe um endpoint em execução que já expõe uma API compatível com a OpenAI.
Em um nível conceitual, um modelo define:
- Qual imagem de contêiner executar
- Como o contêiner é iniciado
- Quanto espaço em disco ele precisa
- Quais portas são expostas
- Quais variáveis de ambiente existem
- Como a instância se comporta na inicialização
Em outras palavras, um modelo transforma uma GPU bruta em um ambiente de produto pronto para uso.
https://www.youtube.com/watch?v=RIiJZZsYITs
Experimente o GLM 4.7 Flash Agora!
Que Problema um Modelo de GPU Resolve?
Um modelo de GPU elimina o ônus operacional de executar modelos grandes, transformando infraestrutura complexa em um serviço pronto para uso.
Para um desenvolvedor, especialmente um júnior, isso resolve três problemas concretos.
Primeiro, elimina a incerteza de ambiente.
Você não precisa mais perguntar “Qual versão do CUDA funciona”, “Qual backend é estável” ou “Qual comando devo executar”. O modelo já responde a essas perguntas em forma executável.
Segundo, converte a experimentação em um único clique.
Em vez de gastar horas montando imagens Docker e scripts de inicialização, você escolhe um modelo na biblioteca e implanta uma instância que já funciona. O tempo até o primeiro token cai de horas para minutos.
Terceiro, permite a transferência de conhecimento no nível de infraestrutura.
Um modelo é efetivamente “infraestrutura como produto”. Quando alguém constrói um tempo de execução de alta qualidade do GLM-4.7 Flash, outros podem implantar o exato mesmo ambiente sem entender nenhum de seus internos. É por isso que a plataforma incentiva modelos públicos e arquivos README.
Com um Modelo de GPU, tudo isso já está pré-resolvido
| Dimensão | Configuração Manual | Modelo de GPU |
|---|---|---|
| Ambiente | Construído manualmente | Pré-configurado |
| Modelo | Baixado manualmente | Pré-carregado |
| Tempo de Execução | Compilado localmente | Pronto |
| API | Implementado por conta própria | Integrado |
| Estabilidade | Imprevisível | Nível de produção |
Por que o GLM 4.7 Flash se Adapta a Modelos de GPU
O GLM 4.7 Flash é particularmente adequado para implantação local em sistemas orientados a agentes, pois alinha o raciocínio de longo horizonte com a eficiência prática de hardware.
Sua arquitetura MoE de 30B de parâmetros ativa apenas 3,6B de parâmetros por token, mantendo os custos de inferência próximos aos de modelos de porte médio, enquanto retém a capacidade de modelos grandes, o que torna os modelos de GPU locais tanto viáveis quanto econômicos.
A janela de contexto de 200K tokens permite memória persistente, planejamento estendido e rastreamento de estado multirronda estável, todos fundamentais para agentes autônomos.
| Benchmark | GLM 4.7 Flash | Qwen3-30B | GPT-OSS-20B |
|---|---|---|---|
| AIME 25 | 91.6 | 85.0 | 91.7 |
| GPQA | 75.2 | 73.4 | 71.5 |
| SWE-bench Verified | 59.2 | 22.0 | 34.0 |
| τ²-Bench | 79.5 | 49.0 | 47.7 |
| BrowseComp | 42.8 | 2.29 | 28.3 |
Os resultados dos benchmarks confirmam ainda mais seu perfil voltado para agentes: raciocínio matemático próximo ao nível mais alto no AIME, forte compreensão de nível de pós-graduação no GPQA, competência em engenharia de software do mundo real no SWE-bench Verified e planejamento robusto de múltiplos passos no τ²-Bench.
Combinado com um desempenho sólido em tarefas de síntese de informações, o GLM 4.7 Flash ocupa uma posição rara como um modelo rápido e de propósito geral que pode ser implantado localmente, ao mesmo tempo que oferece raciocínio de alto nível, capacidade de programação confiável e execução de longa cadeia durável, tornando-se uma base ideal para infraestruturas de agentes no dispositivo ou privadas.
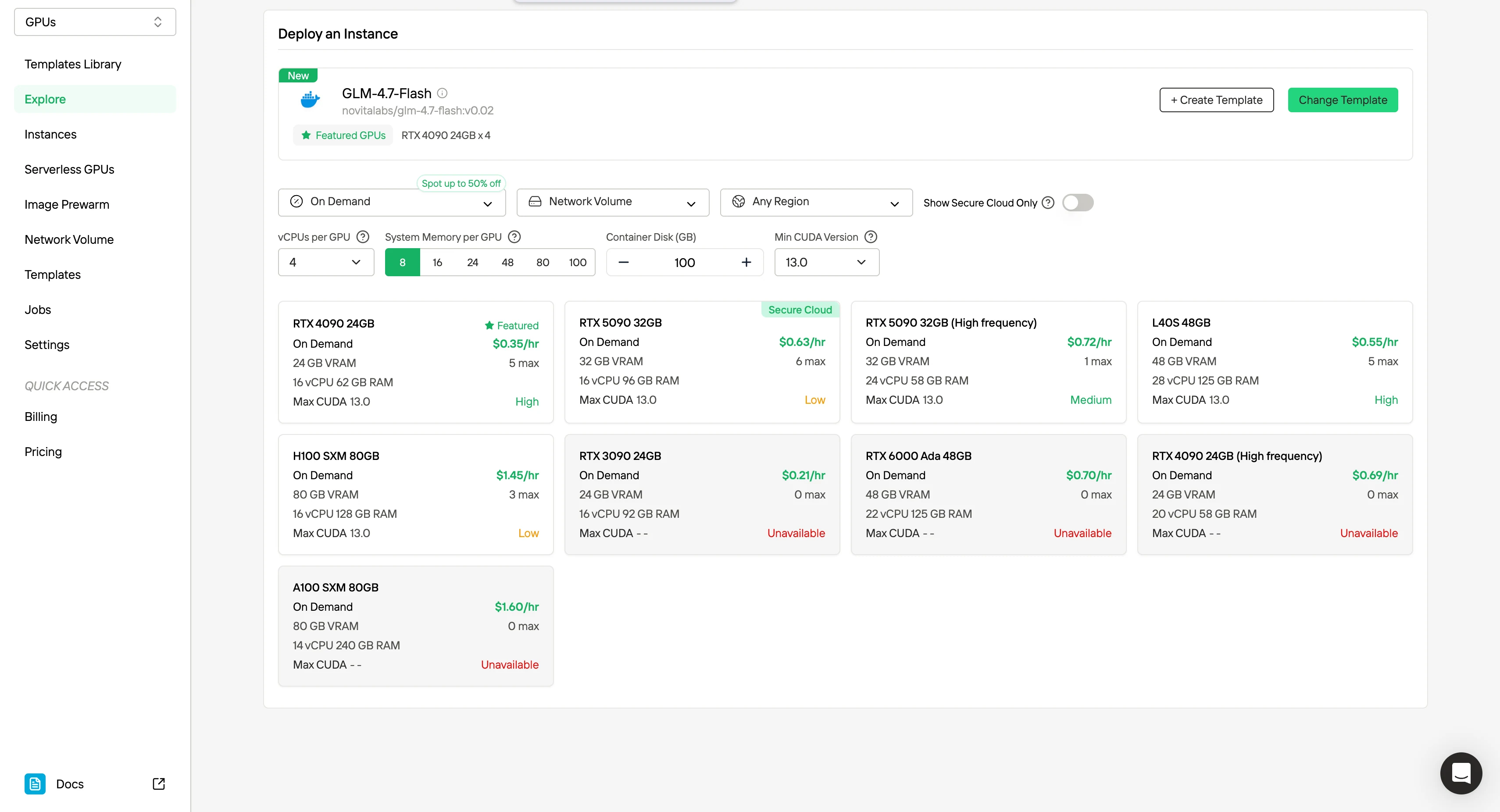
O que o GLM 4.7 Flash Ganha com Modelos de GPU e Quanto?
O uso de modelos de GPU com o GLM-4.7 Flash oferece aos desenvolvedores três ganhos concretos: implantação determinística, capacidade de nível para agentes em escala local e simplicidade operacional para sistemas multinó. Você obtém um ambiente repetível onde CUDA, VRAM, memória do sistema e disco são pré-alinhados com o perfil MoE do modelo, para que cada instância se comporte de forma idêntica em diferentes regiões e equipes.
Os modelos de GPU da Novita AI permitem que essas capacidades sejam executadas em hardware comum com preços previsíveis.
Como apenas um pequeno subconjunto de parâmetros está ativo por token, o GLM-4.7 Flash é executado de forma eficiente em GPUs de 24GB a 48GB. Isso o coloca diretamente na faixa de preço de placas de consumo e prossumidor amplamente disponíveis.
Experimente o GLM 4.7 Flash Agora!
| Classe de GPU | VRAM | Custo Hora Típico | Nível de Implantação |
|---|---|---|---|
| RTX 3090 / RTX 4090 | 24GB | $0,21–$0,35 | Produção mínima |
| RTX 5090 | 32GB | $0,60–$0,70 | Espaço adicional aprimorado |
| L40S / RTX 6000 Ada | 48GB | $0,55–$0,70 | Recomendado para agentes |
| H100 / A100 | 80GB | $1,40+ | Exagero para o Flash |
Com modelos de GPU:
- Um nó de 24GB se torna um trabalhador de agente viável
- Um nó de 48GB pode hospedar agentes de contexto completo e multiferramenta
- A expansão da frota é linear em custo e esforço
Isso possibilita uma estrutura de custos em que:
- Os nós de agente custam menos de um dólar por hora
- A escalabilidade é limitada pela lógica, não pela infraestrutura
- Implantações locais ou privadas permanecem economicamente viáveis
O GLM-4.7 Flash, portanto, ocupa uma posição rara: oferece raciocínio de nível para agentes e comportamento de longo contexto, ao mesmo tempo que se encaixa no envelope econômico de GPUs convencionais. Os modelos de GPU transformam essa vantagem arquitetônica em um modelo de implantação prático e repetível para sistemas reais.
Como um Desenvolvedor Júnior Usa o GLM 4.7 Flash com o Modelo de GPU da Novita AI?
Passo 1: Acesso ao Console Inicie a interface de GPU e selecione Começar para acessar o gerenciamento de implantações.
Passo 2: Seleção de Pacote Localize o GLM-4.7-Flash no repositório de modelos e inicie a sequência de instalação.
Experimente o GLM 4.7 Flash Agora!
Passo 3: Configuração de Infraestrutura Configure os parâmetros de computação, incluindo alocação de memória, requisitos de armazenamento e configurações de rede. Selecione Implantar para executar.
Passo 4: Revisão e Criação Verifique novamente os detalhes da sua configuração e o resumo de custos. Quando estiver satisfeito, clique em Implantar para iniciar o processo de criação.
Passo 5: Aguarde a Criação Após iniciar a implantação, o sistema redirecionará você automaticamente para a página de gerenciamento de instâncias. Sua instância será criada em segundo plano.
Passo 6: Monitore o Progresso do Download Acompanhe o progresso do download da imagem em tempo real. O status da sua instância mudará de Baixando para Em execução assim que a implantação for concluída. Você pode ver o progresso detalhado clicando no ícone de seta ao lado do nome da sua instância.
Passo 7: Verifique o Status da Instância Clique no botão Logs para visualizar os registros da instância e confirmar que o serviço InvokeAI foi iniciado corretamente.
Passo 8: Acesso ao Ambiente Inicie o espaço de desenvolvimento por meio da interface Conectar, depois inicialize o Terminal Web Inicial.
Passo 9: Uma Demonstração
curl --location --request POST 'http://127.0.0.1:8000/v1/chat/completions' \
> --header 'Content-Type: application/json' \
> --header 'Accept: */*' \
> --header 'Connection: keep-alive' \
> --data-raw '{
> "model": "zai-org/GLM-4.7-Flash",
> "messages": [
> {
> "role": "system",
> "content": "you are a helpful assitant."
> },
> {
> "role": "user",
> "content": "hello"
> }
> ],
> "max_tokens": 20,
> "stream": false
> }'
{"id":"chatcmpl-943f20f1c3a690ba","object":"chat.completion","created":1768823899,"model":"zai-org/GLM-4.7-Flash","choices":[{"index":0,"message":{"role":"assistant","content":"1. **Analyze the Input:** The user said \"hello\".\
2. **Ident","refusal":null,"annotations":null,"audio":null,"function_call":null,"tool_calls":[],"reasoning":null,"reasoning_content":null},"logprobs":null,"finish_reason":"length","stop_reason":null,"token_ids":null}],"service_tier":null,"system_fingerprint":null,"usage":{"prompt_tokens":14,"total_tokens":34,"completion_tokens":20,"prompt_tokens_details":null},"prompt_logprobs":null,"prompt_token_ids":null,"kv_transfer_params":null}
Os modelos de GPU transformam o GLM 4.7 Flash de um modelo de benchmark poderoso em uma base de agente local prática. Ao pré-resolver a configuração de ambiente, a configuração de tempo de execução e a exposição de API, eles permitem a implantação determinística em GPUs convencionais. Isso transforma o raciocínio de nível para agentes, a memória de longo contexto e o planejamento de múltiplos passos em capacidades que são economicamente e operacionalmente viáveis para sistemas privados e no dispositivo.
Por que o GLM 4.7 Flash é adequado para implantação local com modelos de GPU? O GLM 4.7 Flash ativa apenas um pequeno subconjunto de parâmetros por token, permitindo que ele seja executado de forma eficiente em GPUs de 24GB a 48GB, preservando o raciocínio de longo contexto e de nível para agentes.
Que problema um modelo de GPU resolve para os usuários do GLM 4.7 Flash? Um modelo de GPU elimina a incerteza de ambiente para o GLM 4.7 Flash, pré-configurando CUDA, tempo de execução, endpoints de API e armazenamento, para que cada instância do GLM 4.7 Flash se comporte de forma consistente.
Qual hardware é suficiente para executar o GLM 4.7 Flash em produção? O GLM 4.7 Flash opera de forma eficaz em GPUs das classes RTX 3090, RTX 4090, L40S e RTX 6000 Ada, tornando-o viável em hardware amplamente disponível.
Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma maneira fácil de implantar modelos de IA usando nossa API simples, além de fornecer uma nuvem de GPU acessível e confiável para construção e escalonamento.



