

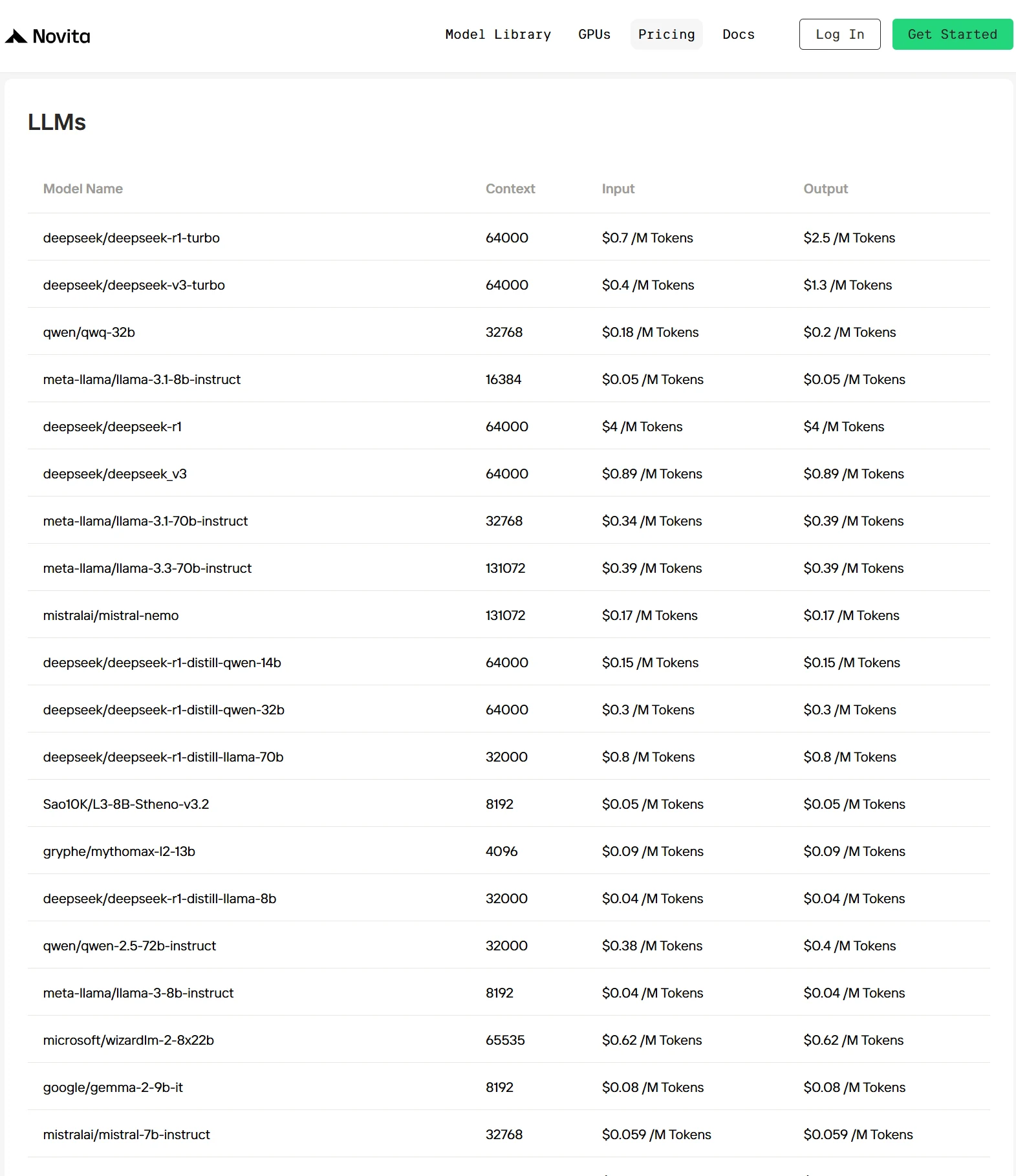
关键亮点
QWQ 32B 是一款高性能大语言模型,在 LiveCodeBench、IFEval 和 MMLU 数据集上均展现出出色的基准成绩。
硬件要求 极高,标准运行需要 A100 80GB 或双 RTX 4090 GPU。
API 访问 提供了一种智能替代方案,无需昂贵的基础设施即可获得完整的模型能力。
最佳 QWQ 32B API 提供商:
Novita AI:快速、经济、预集成的多模态访问。
Nebius:具备 NVIDIA H100/H200 的企业级基础设施。
DeepInfra:通过简单设置即可直接 API 访问开源模型。
QWQ 32B 性能卓越,但其极高的硬件要求使得本地部署对大多数用户来说不切实际。选择可靠的 QWQ 32B API 提供商提供了更快、更经济的解决方案,让开发者无需在服务器和维护上投入巨资即可利用最先进的模型。
什么是 QWQ 32B?

QWQ 32B 基准测试

QWQ 硬件要求
| 精度 | 显存需求 | 最低硬件 |
|---|---|---|
| 16-bit | 80 GB | 1× A100 (80GB) |
| 8-bit | 40 GB | 2× RTX 4090 (48GB) |
| 4-bit | 20 GB | RTX 4090 |
为什么选择 API?
尽管 QWQ 32B 性能令人印象深刻,但其硬件要求极高。本地运行需要强大的配置,如 A100 80GB 服务器 GPU 或双 RTX 4090 显卡——远超大多数开发者的能力范围。在这种情况下,使用 API 成为更明智、更具成本效益的选择。API 提供对强大基础设施的即时访问,无需大量硬件投资或持续维护,让开发者专注于构建应用,而不是管理服务器。
API 的优势
| ⚙️ **自动化 ** 自动执行任务,减少人工工作,提升效率。 |
🧩 ** 集成 ** 连接系统,打造无缝体验。 |
📈 ** 可扩展性 ** 轻松扩展,无需重构。 |
💡 ** 创新** 更快、更便宜、更智能地构建方案。 |
API 与其他方法的对比

如何选择 API 提供商(5 个指标)

QWQ 32B 的三大 API 提供商
1. Novita AI
Novita AI 是一个先进的 AI 云平台,让开发者能够通过简单的 API 轻松部署 AI 模型。此外,它还提供经济且可靠的 GPU 云,用于构建和扩展 AI 解决方案。

为什么选择 Novita AI?
开发效率: 预集成的多模态模型(如 DeepSeek V3、DeepSeek R1 和 LLaMA 3.3 70B)可立即部署,无需额外设置。
成本优势: 专有优化技术使推理成本相比主要提供商降低 30%–50%。
如何通过 Novita API 访问 QWQ 32B?
步骤 1:开始免费试用
开始免费试用,探索所选模型的能力。
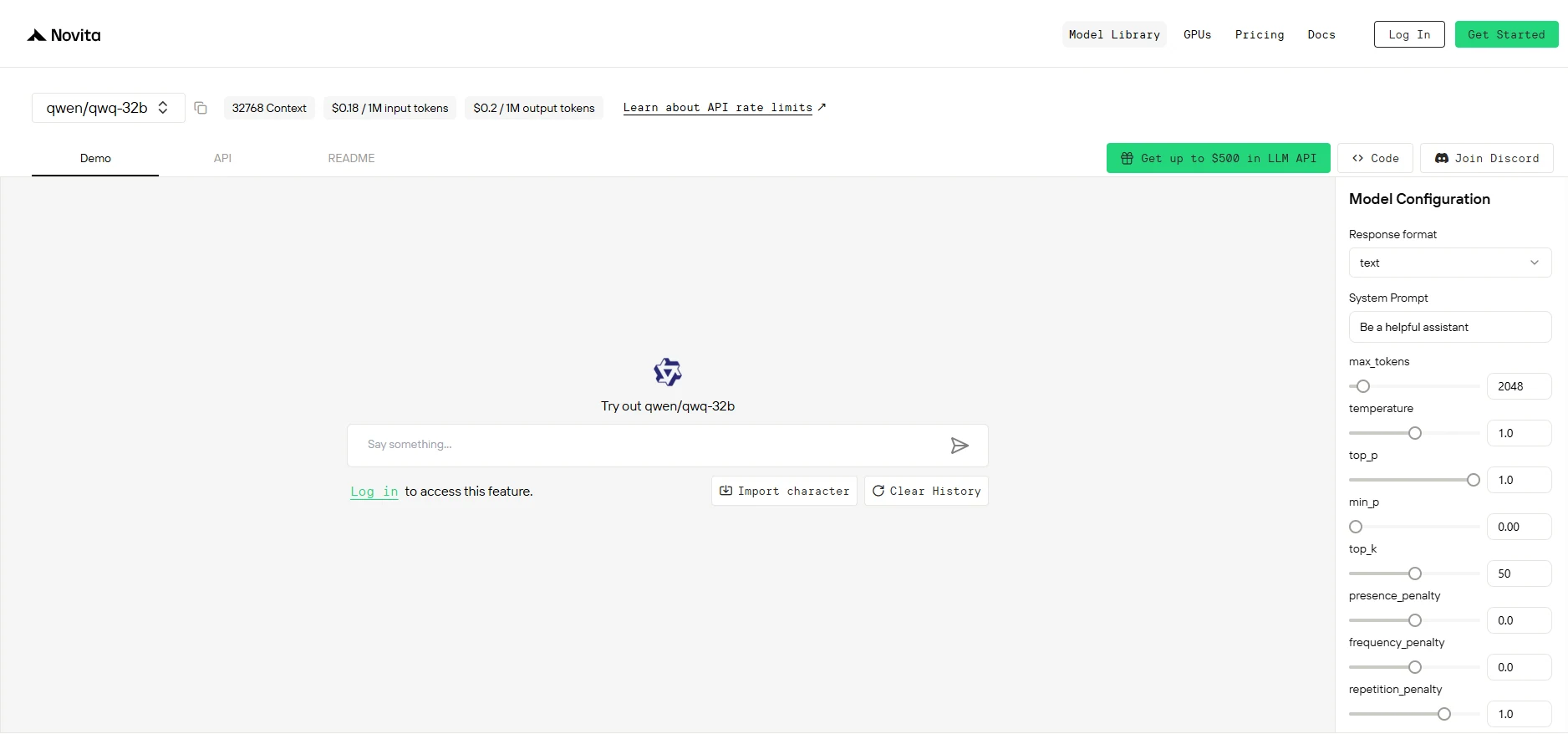
步骤 2:获取 API 密钥
为了对 API 进行身份验证,我们将为您提供一个新 API 密钥。进入“设置”页面,按照图示复制 API 密钥。

步骤 3:安装 API
使用适用于您编程语言的包管理器安装 API。

安装完成后,将所需库导入开发环境。使用 API 密钥初始化 API,开始与 Novita AI LLM 交互。以下是针对 Python 用户的聊天补全 API 使用示例。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "qwen/qwq-32b"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
2. Nebius
Nebius 是一个综合性 AI 开发平台,提供在高级 NVIDIA® GPU 上进行模型构建、微调和部署的无缝体验,具有业界领先的效率和性能。

为什么选择它?
强大的基础设施: Nebius 的 AI 原生云平台利用基于 InfiniBand 网络连接的尖端 NVIDIA H100/H200 GPU,提供卓越的模型微调和扩展能力,以及灵活的高性能、低延迟数据处理和应用部署 API。

如何通过它访问 DeepSeek R1?
使用 DeepSeek R1 的聊天端点生成模型响应。
import os
from openai import OpenAI
client = OpenAI(
base_url="https://api.studio.nebius.com/v1/",
api_key=os.environ.get("NEBIUS_API_KEY")
)
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-R1",
max_tokens=8192,
temperature=0.6,
top_p=0.95,
messages=[]
)
print(response.to_json())
3. Deepinfra
DeepInfra 是一个提供对强大开源 AI 模型(如 LLaMA、Mistral、Qwen 等)进行简单 API 访问的平台。您无需自行搭建复杂的硬件和软件环境,直接通过简单的 API 调用即可使用这些 AI 模型。
为什么 应选择 Deepinfra?

如何通过它访问 QWQ 32B?
# Assume openai>=1.0.0
from openai import OpenAI
# Create an OpenAI client with your deepinfra token and endpoint
openai = OpenAI(
api_key="$DEEPINFRA_TOKEN",
base_url="https://api.deepinfra.com/v1/openai",
)
chat_completion = openai.chat.completions.create(
model="qwen/qwq-32b",
messages=[{"role": "user", "content": "Hello"}],
)
print(chat_completion.choices[0].message.content)
print(chat_completion.usage.prompt_tokens, chat_completion.usage.completion_tokens)
通过 Novita AI、Nebius 和 DeepInfra 等值得信赖的 API 提供商访问 QWQ 32B,开发者可以轻松发挥世界级 AI 性能。无需受硬件限制,团队可以专注于创新、产品开发和应用扩展,同时将运维开销降至最低。
常见问题
什么是 QWQ 32B API 提供商?
QWQ 32B API 提供商(如 Novita AI、Nebius 和 DeepInfra)提供对 QWQ 32B 模型的云端访问,让用户无需专用硬件即可运行强大的 AI 任务。
我为什么要使用 QWQ 32B API 提供商?
因为本地运行 QWQ 32B 需要非常昂贵的 GPU,使用 API 可以以更低成本即时访问相同模型,且无需任何设置麻烦。
哪个提供商最适合快速集成?
Novita AI 因其预集成的多模态模型和具有成本效益的部署选项而备受推荐。
Novita AI 是一个 AI 云平台,为开发者提供通过简单 API 部署 AI 模型的简易方式,同时还提供经济且可靠的 GPU 云,用于构建和扩展应用。



