

主なハイライト
QWQ 32B は、LiveCodeBench、IFEval、MMLU データセットで強力なベンチマーク結果を示す高性能な大規模言語モデルです。
ハードウェア要件 は非常に高く、標準運用には A100 80GB またはデュアル RTX 4090 GPU が必要です。
API アクセス は、高コストなインフラを不要にし、完全なモデル機能を提供するスマートな代替手段です。
トップ QWQ 32B API プロバイダー :
Novita AI : 高速で手頃な価格、事前統合されたマルチモーダルアクセス。
Nebius : エンタープライズグレードのインフラストラクチャ(NVIDIA H100/H200 搭載)。
DeepInfra : オープンソースモデルへの直接 API アクセス、簡単セットアップ。
QWQ 32B は卓越したパフォーマンスを提供しますが、その極端なハードウェア要件により、ほとんどのユーザーにとってローカル展開は非現実的です。信頼できる QWQ 32B API プロバイダーを選択することで、より迅速で費用対効果の高いソリューションが得られ、開発者はサーバーやメンテナンスへの多額の投資なしに最先端のモデルを活用できます。
QWQ 32B とは?

QWQ 32B ベンチマーク

QWQ ハードウェア要件
| 精度 | VRAM要件 | 最小ハードウェア |
|---|---|---|
| **16ビット ** | 80 GB | 1× A100 (80GB) |
| 8ビット | 40 GB | 2× RTX 4090 (48GB) |
| 4ビット | 20 GB | RTX 4090 |
なぜ API を選ぶのか?
QWQ 32B は印象的なパフォーマンスを提供しますが、非常に高いハードウェア要件が伴います。ローカルで実行するには、A100 80GB サーバー GPU やデュアル RTX 4090 カードなど、ほとんどの開発者の手の届かない強力な構成が必要です。このような状況では、API を使用する方がはるかにスマートで費用対効果の高い選択肢となります。API は、大規模なハードウェア投資や継続的なメンテナンスを必要とせずに、強力なインフラストラクチャへの即時アクセスを提供し、開発者はサーバーの管理ではなくアプリケーションの構築に集中できます。
API の利点
| ⚙️ Automation タスクを自動化し、手作業を減らし、効率を向上させる。 |
🧩 Integration システムを接続し、シームレスな体験を創出する。 |
📈 Scalability 大規模な変更なしに簡単にスケーリング。 |
💡 Innovation より速く、より安く、よりスマートなソリューションを構築。 |
API と他の手法の比較

API プロバイダーの選び方(5つの指標)

QWQ 32B のトップ3 API プロバイダー
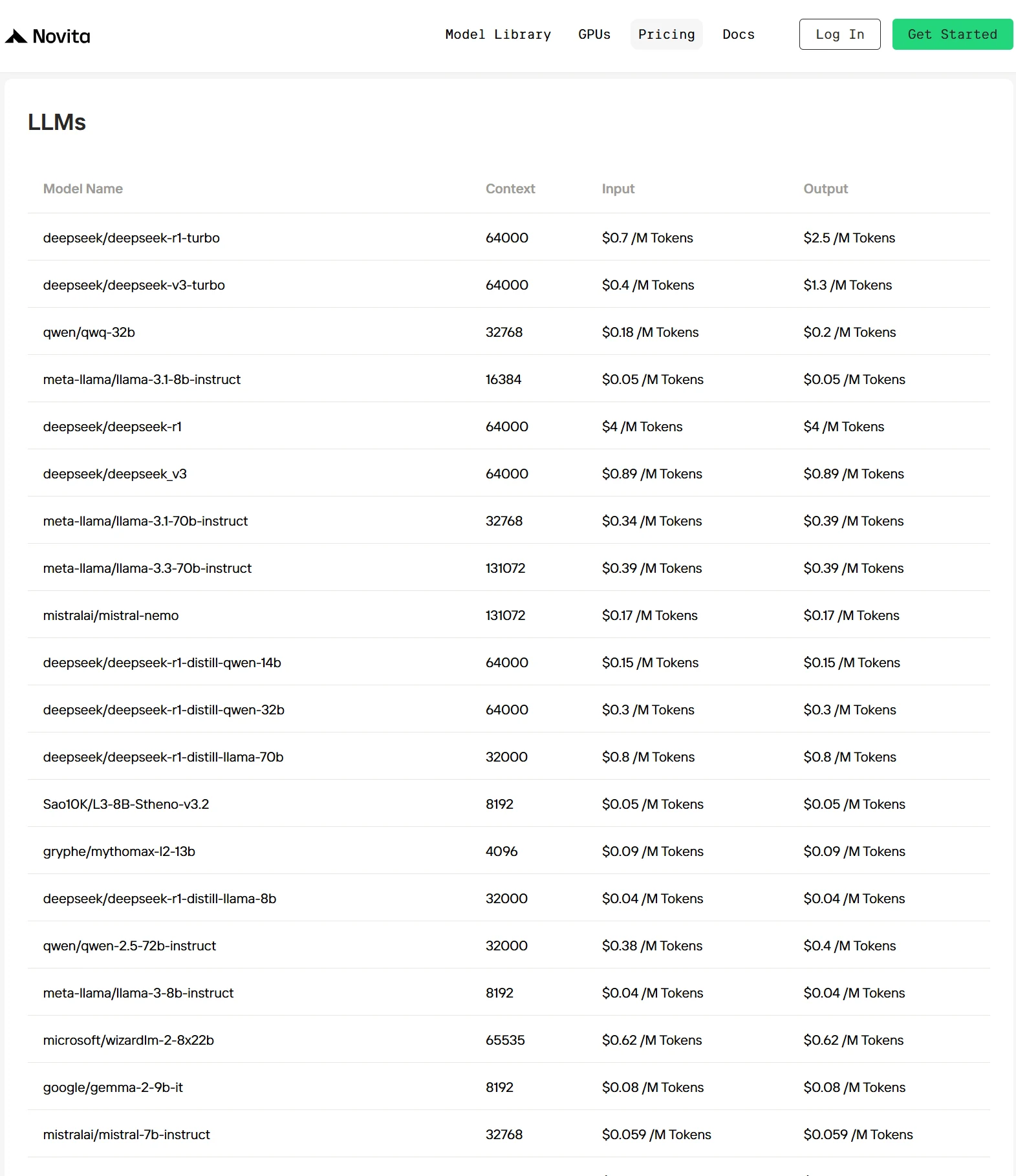
1. Novita AI
Novita AI は、開発者がシンプルな API を介して AI モデルを簡単にデプロイできる高度な AI クラウドプラットフォームです。また、AI ソリューションの構築とスケーリングのための手頃で信頼性の高い GPU クラウドを提供します。

Novita AI を選ぶべき理由は?
開発効率: 事前統合されたマルチモーダルモデル(DeepSeek V3、DeepSeek R1、LLaMA 3.3 70B など)により、追加設定なしで即時デプロイが可能です。
コスト優位性: 独自の最適化技術により、主要プロバイダーと比較して推論コストを30%~50%削減します。
Novita API 経由で QWQ 32B にアクセスする方法
ステップ1: 無料トライアルを開始する
無料トライアルを開始して、選択したモデルの機能を探索します。
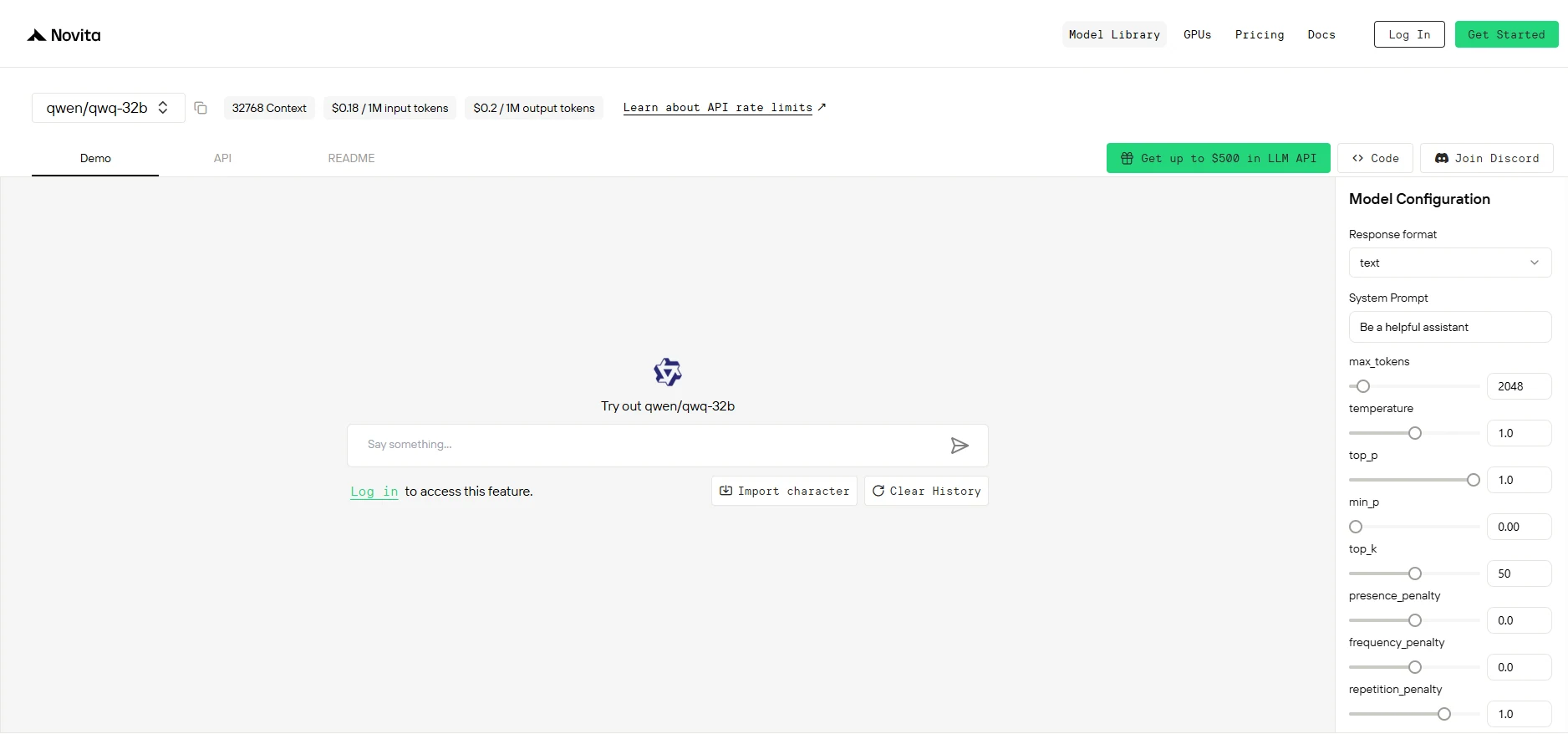
ステップ2: API キーを取得する
API で認証するために、新しい API キーを提供します。「設定」ページに入ると、画像に示された API キーをコピーできます。

ステップ3: API をインストールする
プログラミング言語に適したパッケージマネージャーを使用して API をインストールします。

インストール後、必要なライブラリを開発環境にインポートします。API キーで API を初期化し、Novita AI LLM との対話を開始します。これは Python ユーザー向けのチャット補完 API の使用例です。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "qwen/qwq-32b"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
2. Nebius
Nebius は、プレミアム NVIDIA® GPU 上でシームレスなモデル構築、ファインチューニング、デプロイを提供する包括的な AI 開発プラットフォームであり、業界をリードする効率性とパフォーマンスを実現します。

なぜ選ぶ のか?
強力なインフラストラクチャ: Nebius の AI ネイティブクラウドプラットフォームは、InfiniBand ネットワークで接続された最先端の NVIDIA H100/H200 GPU を活用し、高性能・低遅延のデータ処理とアプリケーションデプロイのための柔軟な API とともに、優れたモデルファインチューニングと拡張機能を提供します。

Deepseek R1 にアクセスする方法
Deepseek R1 のチャットエンドポイントを使用してモデル応答を生成します。
import os
from openai import OpenAI
client = OpenAI(
base_url="https://api.studio.nebius.com/v1/",
api_key=os.environ.get("NEBIUS_API_KEY")
)
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-R1",
max_tokens=8192,
temperature=0.6,
top_p=0.95,
messages=[]
)
print(response.to_json())
3. DeepInfra
DeepInfra は、LLaMA、Mistral、Qwen などの強力なオープンソース AI モデルへの簡単な API アクセスを提供するプラットフォームです。複雑なハードウェアやソフトウェア環境を自分でセットアップする代わりに、DeepInfra を使用すると、シンプルな API 呼び出しを通じてこれらの AI モデルを直接利用できます。
なぜ DeepInfra を選ぶべきか?

QWQ 32B にアクセスする方法
# Assume openai>=1.0.0
from openai import OpenAI
# Create an OpenAI client with your deepinfra token and endpoint
openai = OpenAI(
api_key="$DEEPINFRA_TOKEN",
base_url="https://api.deepinfra.com/v1/openai",
)
chat_completion = openai.chat.completions.create(
model="qwen/qwq-32b",
messages=[{"role": "user", "content": "Hello"}],
)
print(chat_completion.choices[0].message.content)
print(chat_completion.usage.prompt_tokens, chat_completion.usage.completion_tokens)
信頼できる API プロバイダー(Novita AI、Nebius、DeepInfra など)を介して QWQ 32B にアクセスすることで、開発者は簡単に世界クラスの AI パフォーマンスを活用できます。ハードウェアの制約を回避することで、チームはイノベーション、製品開発、アプリケーションのスケーリングに集中でき、運用オーバーヘッドを最小限に抑えられます。
よくある質問
QWQ 32B API プロバイダーとは?
QWQ 32B API プロバイダー(Novita AI、Nebius、DeepInfra など)は、QWQ 32B モデルへのクラウドベースのアクセスを提供し、ユーザーは専用のハードウェアを必要とせずに強力な AI タスクを実行できます。
QWQ 32B API プロバイダーを使用すべき理由は?
QWQ 32B をローカルで実行するには非常に高価な GPU が必要ですが、API を使用すると、同じモデルに即座に、より低コストで、セットアップの手間なくアクセスできます。
迅速な統合に最適なプロバイダーは?
Novita AI は、事前統合されたマルチモーダルモデルと費用対効果の高いデプロイオプションにより、強く推奨されます。
Novita AI は、開発者がシンプルな API を使用して AI モデルを簡単にデプロイできる AI クラウドプラットフォームであり、同時に構築とスケーリングのための手頃で信頼性の高い GPU クラウドを提供します。



