

要点总结
Qwen3-Coder-480B-A35B-Instruct:专用编码模型,拥有 262K token 上下文长度,专为算法卓越性和编程任务的基准性能而优化。
ChatGPT-4.1:多模态基础模型,具备高级推理能力,针对跨领域和应用程序的多功能问题解决和类人对话进行优化。
Novita AI 不仅提供稳定的 API 服务,还提供极具成本效益的定价。例如,Qwen3-Coder-480B-A35B-Instruct 每 100 万输入 token 收费 0.95 美元,每 100 万输出 token 收费 5 美元。
模型基本介绍
Qwen3-Coder-480B-A35B-Instruct
Qwen3-Coder-480B-A35B-Instruct 是阿里巴巴于 2025 年 7 月发布的最先进的大规模因果语言模型,主要设计用于智能体编码和软件开发任务。它采用混合专家(MoE)架构,总参数为 4800 亿,每次前向传播激活 350 亿参数,在模型容量和推理效率之间取得了平衡。该模型原生支持 256K token 的超长上下文,并在开放模型中达到了最先进的性能。
主要特点与架构
- 类型:因果语言模型
- 训练阶段:预训练与后训练
- 参数数量:总计 480B,激活 35B
- 层数:62
- 注意力头数(GQA):96 个 Q 头,8 个 KV 头
- 专家数量:160
- 激活专家数量:8
- 上下文长度:原生 262,144 token。
ChatGPT-4.1
ChatGPT-4.1 由 OpenAI 于 2025 年 4 月 14 日发布,其上下文理解能力有了突破性改进,原生支持 100 万 token 上下文窗口,编码能力比 GPT-4o 提升 21%,并拥有用于文本、图像和文档分析的卓越多模态处理能力。它基于优化的 Transformer 架构和增强的注意力机制构建,在 AIME、GPQA、MMLU 学术基准、SWE-bench 编码评估以及 MMMU/MathVista 视觉任务上均达到了最先进的性能。
主要特点与架构
- 类型:具有多模态能力的高级大型语言模型
- 发布日期:2025 年 4 月 14 日
- 上下文窗口:原生 100 万 token
- 编码性能:软件工程能力比 GPT-4o 提升 21%
- 多模态支持:增强的文本、图像和文档分析能力
- 指令遵循:高级遵循用户格式和任务要求
Qwen3-Coder-480B-A35B-Instruct 与 ChatGPT-4.1 的基准对比
1. 智能基准

2. 智能体性能基准

3. 上下文窗口
Qwen3-Coder-480B-A35B-Instruct:262k token
ChatGPT-4.1:100 万 token
4. API 定价
Qwen3-Coder-480B-A35B-Instruct:输入/输出 每 100 万 token 0.95 美元 / 5 美元
ChatGPT-4.1:输入/输出 每 100 万 token 2 美元 / 8 美元
应用技能测试
1. 代码调试挑战
问题:多层嵌套错误调试
以下 Python 代码试图实现一个数据处理管道,但包含多个隐藏错误。请识别所有错误并提供修复方案,同时解释每个错误的原因和修复逻辑。
import json
from datetime import datetime
import asyncio
class DataProcessor:
def __init__(self, config_file):
self.config = self.load_config(config_file)
self.results = []
def load_config(self, file_path):
with open(file_path, 'r') as f:
return json.load(f)
async def process_batch(self, data_list):
tasks = []
for item in data_list:
task = self.process_item(item)
tasks.append(task)
results = await asyncio.gather(*tasks)
return results
def process_item(self, item):
processed = {
'id': item['id'],
'value': item['value'] * self.config['multiplier'],
'timestamp': datetime.now().isoformat(),
'status': 'processed'
}
if processed['value'] > self.config['threshold']:
processed['category'] = 'high'
else:
processed['category'] = 'low'
self.results.append(processed)
return processed
def save_results(self, filename):
with open(filename, 'w') as f:
json.dump(self.results, f, indent=2)
# Usage example
async def main():
processor = DataProcessor('config.json')
data = [
{'id': 1, 'value': 100},
{'id': 2, 'value': 250},
{'id': 3, 'value': 75}
]
results = await processor.process_batch(data)
processor.save_results('output.json')
print(f"Processed {len(results)} items")
if __name__ == "__main__":
asyncio.run(main())
亲自试用 Qwen3-Coder-480B-A35B-Instruct!
Qwen3-Coder-480B-A35B-Instruct
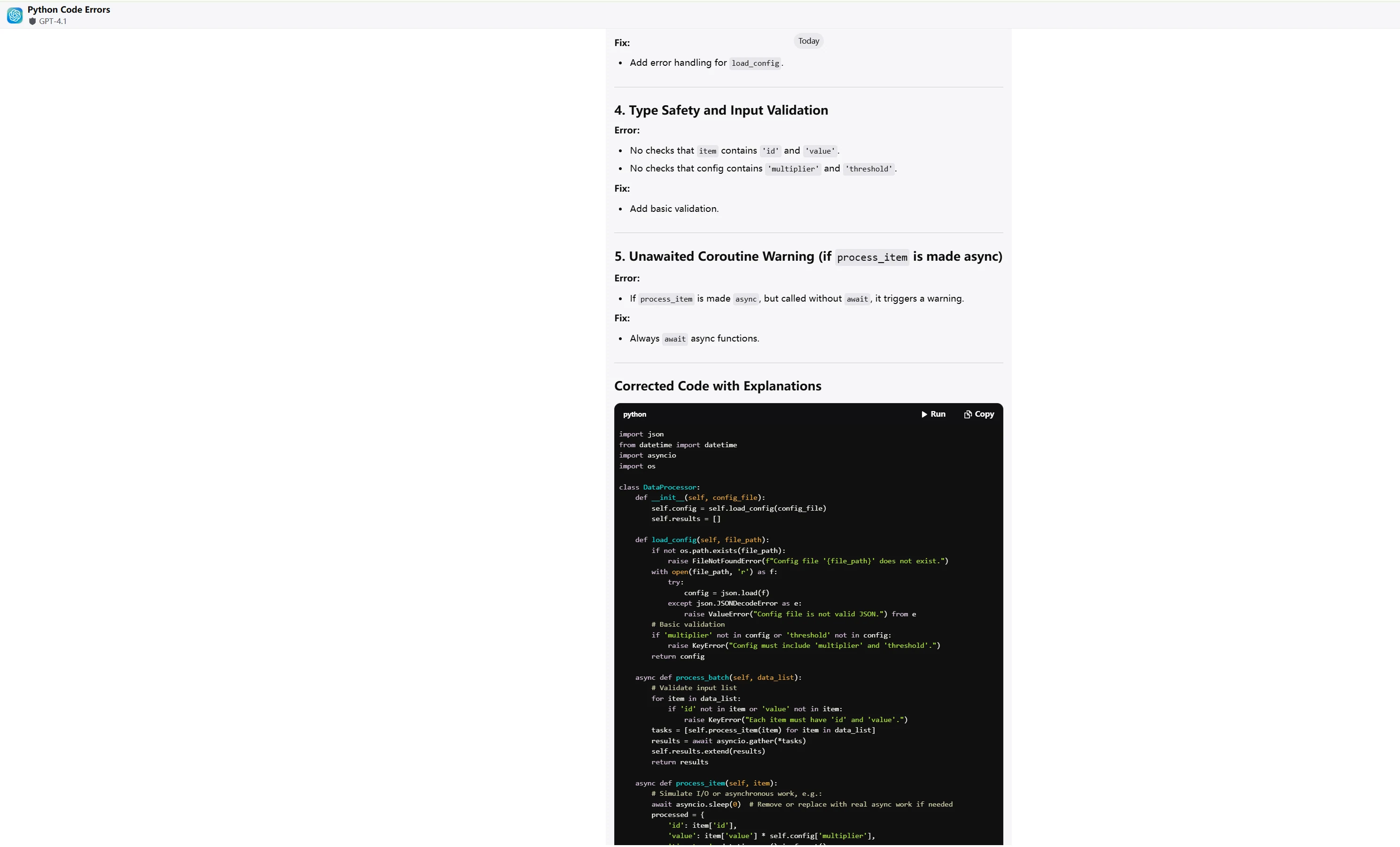
ChatGPT-4.1
代码调试挑战对比
| **评价维度 ** | Qwen3-Coder | ** 得分 ** | ChatGPT-4.1 | ** 得分** |
|---|---|---|---|---|
| **错误识别 ** | 全面检测所有 4 个关键错误;详细的异步/同步分析 | 4/4 | 系统性识别,清晰优先级划分;优秀的分类能力 | 4/4 |
| **解决方案质量 ** | 功能完整但过度工程化;复杂的锁和异常处理模式 | 2/3 | 优雅、最小化修复;巧妙的主线程结果收集方法 | 3/3 |
| **代码质量 ** | 遵循异步最佳实践,但实现过于复杂 | 1/2 | 清晰可读的代码,符合 Python 惯例;适当的验证 | 2/2 |
| **清晰度与结构 ** | 解释冗长;缺乏组织性;摘要过长 | 0.5/1 | 结构良好,包含摘要表格;可以更简洁 | 0.5/1 |
| **技术深度 ** | 深入的并发编程分析;全面的边界情况处理 | ** 强 ** | 技术洞察与实际侧重取得平衡 | ** 良好** |
| **实用性 ** | 过度工程化的解决方案可能妨碍维护 | ** 中等 ** | 清晰、可维护的解决方案,可直接用于生产 | ** 强** |
| **创新性 ** | 高级异步模式和错误传播技术 | ** 良好 ** | 巧妙的解决问题,优雅简洁 | ** 强** |
| **最终评分 ** | ** 技术全面但过于复杂 ** | 7.5/10 | ** 解决方案质量与清晰度均衡优秀 ** | 8.5/10 |
ChatGPT-4.1 在 解决方案的优雅性 和 代码可维护性 方面更胜一筹,而 Qwen3-Coder 展现出 更深入的技术分析,但存在 ** 过度工程化**的问题。
2. Python 编程挑战
问题:带 TTL 和统计信息的智能缓存装饰器
实现一个装饰器 @smart_cache,提供智能缓存功能,具有以下特性:
- 生存时间(TTL):缓存条目在指定持续时间后过期
- 大小限制:当缓存超过最大大小时进行 LRU 驱逐
- 统计信息跟踪:命中率、未命中次数、驱逐次数
- 条件缓存:仅根据自定义谓词缓存结果
- 线程安全:支持并发访问
要求:
@smart_cache(ttl=60, max_size=100, cache_condition=lambda result: len(result) > 5)
def expensive_function(x, y):
time.sleep(1) # 模拟耗时操作
return f"result_{x}_{y}"
# 用法应支持:
result = expensive_function(1, 2) # 缓存未命中
result = expensive_function(1, 2) # 缓存命中
print(expensive_function.cache_stats()) # {'hits': 1, 'misses': 1, 'evictions': 0}
expensive_function.clear_cache()
关键挑战:
- 处理不可哈希的参数(列表、字典)
- 实现高效的 TTL 清理
- 保持线程安全而不影响性能
- 为缓存管理提供干净的 API
评估标准:
- 正确性(3 分):所有特性均按指定方式工作
- 性能(2 分):高效实现,最小开销
- 代码质量(3 分):清晰、可读、结构良好
- 边界情况(2 分):优雅处理异常输入
预期解决方案长度: 核心实现 50-80 行
Qwen3-Coder-480B-A35B-Instruct
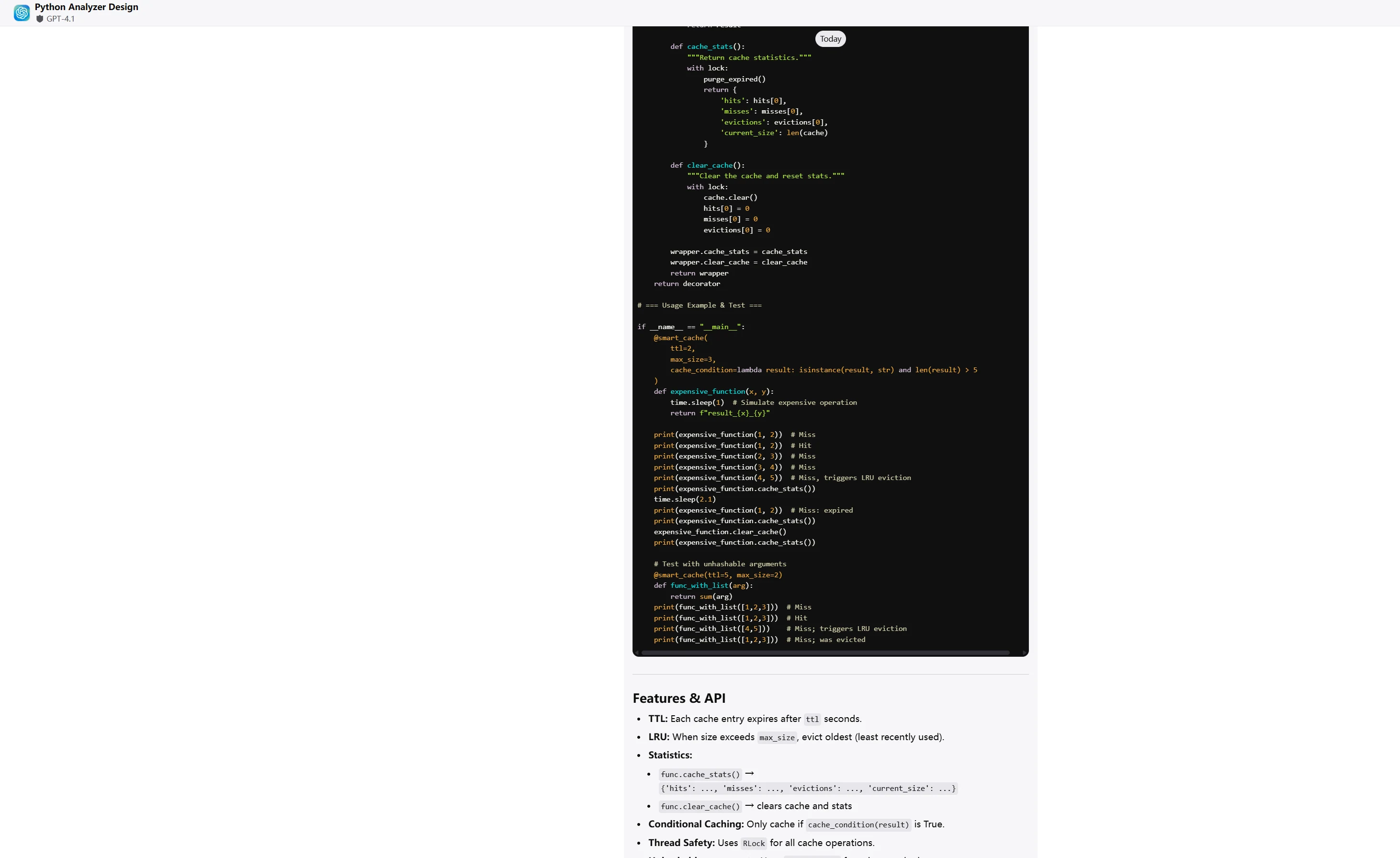
ChatGPT-4.1
Python 编程对比
| **评价维度 ** | Qwen3-Coder | ** 得分 ** | ChatGPT-4.1 | ** 得分** |
|---|---|---|---|---|
| **正确性 ** | 实现完整;所有特性正常工作,TTL/LRU 逻辑正确 | 3/3 | 功能集完整;TTL/LRU/统计实现正确 | 3/3 |
| **性能 ** | 高效的 freeze() 函数;访问时智能清理;最小开销 |
2/2 | pickle.dumps() 为每个缓存键增加了显著的序列化开销 |
1/2 |
| **代码质量 ** | 清晰的基于类的设计;关注点分离合理;包含类型提示 | 3/3 | 函数式方法,统计信息使用可变列表;关注点混杂 | 2/3 |
| **边界情况 ** | 健壮的递归 freeze() 优雅处理嵌套的不可哈希类型 |
2/2 | Pickle 回退方式可行但不够优雅;良好的错误处理 | 1.5/2 |
| **架构 ** | 专业的 OOP 设计,包含专用 SmartCache 类;优秀的封装性 |
** 优秀 ** | 基于闭包的简单方法;更易理解但扩展性较差 | ** 良好** |
| **线程安全 ** | 正确使用 RLock,锁策略一致;高效清理 | ** 优秀 ** | RLock 实现正确,作用域合理 | ** 优秀** |
| **API 设计 ** | 干净的装饰器接口;适当的方法暴露;缓存检查能力 | ** 卓越 ** | 简单的函数式 API;易于使用 | ** 良好** |
| **代码文档 ** | 全面的文档字符串;清晰的类型提示;实现注释详尽 | ** 优秀 ** | 基础文档;功能完整但内容最少 | ** 中等** |
| **最终评分 ** | ** 生产级实现,架构和性能优越 ** | 10/10 | ** 可靠的函数式解决方案,但存在性能权衡 ** | 7.5/10 |
Qwen3-Coder 优势:
- 性能卓越:自定义
freeze()函数 vs 昂贵的pickle.dumps()——对于复杂参数显著更快 - 专业架构:专用
SmartCache类,职责清晰,封装恰当 - 代码质量:类型提示、全面文档、关注点分离清晰
- 高效的 TTL 管理:在访问操作期间清理,而非昂贵的定期清除
- 健壮的键处理:递归冻结算法处理深度嵌套的不可哈希结构
ChatGPT-4.1 局限:
- 性能瓶颈:每次缓存查找都使用
pickle.dumps()造成不必要的开销 - 架构:函数式方法使用可变列表统计信息,可维护性较差
- 键生成:基于 Pickle 的方法效率较低且不够优雅
胜者 :Qwen3-Coder 展示了 ** 企业级软件工程**能力,在性能、架构和可维护性方面更胜一筹。
亲自试用 Qwen3-Coder-480B-A35B-Instruct!
Qwen3-Coder-480B-A35B-Instruct 与 ChatGPT-4.1 的优势与劣势
Qwen3-Coder 优势:
- 工程精准性:专业的 OOP 设计模式和企业级代码结构
- 性能优化:算法高效,计算开销最小
- 代码质量:全面的类型提示、文档和关注点分离
- 生产就绪:稳健的实现,具备适当的错误处理和可扩展性
Qwen3-Coder 劣势:
- 过度工程化倾向:有时会创建不必要的复杂解决方案
- 学习曲线:较高的复杂性可能降低初学者的可及性
- 领域专业化:高度聚焦于编码,其他任务通用性较弱
ChatGPT-4.1 优势:
- 自适应智能:跨领域的灵活问题解决,方法富有创意
- 多模态集成:增强的文本、图像和文档分析能力
- 用户友好性:直观的解决方案,易于理解和修改
- 广泛通用性:在多样化任务类别中表现卓越
ChatGPT-4.1 劣势:
- 性能权衡:有时选择更简单但效率较低的实现
- 架构简洁性:函数式方法可能缺乏复杂系统的可扩展性
- 优化缺口:可能为了可读性而忽略性能优化
如何在 Novita AI 上访问 Qwen3-Coder-480B-A35B-Instruct
1. 使用 Playground(无需编码)
- 即时访问:注册,领取免费积分,几秒钟内即可开始体验 Qwen3-Coder-480B-A35B-Instruct 及其他顶级模型。
- 交互式界面:测试提示词、思维链推理,并实时可视化结果。
- 模型对比:轻松在 Kimi K2、Llama 4、DeepSeek 等之间切换,找到最适合您需求的模型。
立即体验 Qwen3-Coder-480B-A35B-Instruct 演示!
2. 通过 API 集成(面向开发者)
使用 Novita AI 的统一 REST API,轻松将 Qwen3-Coder-480B-A35B-Instruct 连接到您的应用程序、工作流或聊天机器人——无需管理模型权重或基础设施。
直接 API 集成(Python 示例)
要开始使用,只需使用以下代码片段:
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session_cYQSfVMpIb2mRiKf8UOlCSYLuHBjC623pEitotYA8OlPUtMvoE7Z2RUjgDru_x8JpcRARGnvjQGONtIl9VhMuA==",
)
model = "qwen/qwen3-coder-480b-a35b-instruct"
stream = True # or False
max_tokens = 32768
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
常见问题
Qwen3 coder 好用吗?
对于专业开发来说非常出色,架构和性能优越,但对于简单任务可能过于复杂。
什么是 Qwen3 coder?
Qwen3-Coder 是阿里巴巴的大语言模型系列,针对编码和软件开发进行了优化,具有强大的推理能力和极长的上下文支持。
GPT-4.1 适合编码吗?
适合编码,具备改进的能力和用户友好的方法,但有时为了简单性而牺牲性能。
Novita AI 是一个 AI 云平台,为开发者提供使用简单 API 部署 AI 模型的便捷方式,同时提供经济实惠且可靠的 GPU 云,用于构建和扩展规模。



