

重點摘要
Qwen3-Coder-480B-A35B-Instruct:專為程式碼設計的模型,擁有 262K token 的上下文長度,在演算法優化和程式設計基準測試中表現出色。
ChatGPT-4.1:具備多模態能力與進階推理的基礎模型,擅長在各領域中進行多樣化問題解決與類人對話。
Novita AI 不僅提供穩定的 API 服務,還提供極具成本效益的定價。例如,Qwen3-Coder-480B-A35B-Instruct 每 100 萬輸入 tokens 成本為 $0.95,每 100 萬輸出 tokens 成本為 $5。
模型基本介紹
Qwen3-Coder-480B-A35B-Instruct
Qwen3-Coder-480B-A35B-Instruct 是由阿里巴巴於 2025 年 7 月發佈的最新型大規模因果語言模型,主要針對代理式程式碼開發與軟體工程任務設計。它採用混合專家(MoE)架構,總參數達 4800 億,每次前向傳播啟動 350 億參數,在模型容量與推理效率之間取得平衡。原生支援 256K tokens 的超長上下文,在開放模型中達到最先進的效能。
主要功能與架構
- 類型:因果語言模型
- 訓練階段:預訓練與後訓練
- 參數量:總計 480B,活化 35B
- 層數:62
- 注意力頭數(GQA):Query 使用 96 個,Key/Value 使用 8 個
- 專家數:160
- 活化專家數:8
- 上下文長度:原生 262,144 tokens
ChatGPT-4.1
ChatGPT-4.1 由 OpenAI 於 2025 年 4 月 14 日發佈,在上下文理解方面有突破性進展,原生支援 100 萬 token 的上下文視窗,程式碼能力較 GPT-4o 提升 21%,並在文字、圖片、文件分析等處理上具備優異的多模態能力。基於優化的 Transformer 架構與增強注意力機制,ChatGPT-4.1 在 AIME、GPQA、MMLU 學術基準、SWE-bench 程式碼評估以及 MMMU/MathVista 視覺任務上都達到最先進水準。
主要功能與架構
- 類型:具備多模態能力的進階大型語言模型
- 發佈日期:2025 年 4 月 14 日
- 上下文視窗:原生 100 萬 tokens
- 程式碼效能:軟體工程能力較 GPT-4o 提升 21%
- 多模態支援:增強的圖片、文字與文件分析能力
- 指令遵循:對使用者格式與任務需求有優異遵循能力
Qwen3-Coder-480B-A35B-Instruct 與 ChatGPT-4.1 的基準測試比較
1. 智能基準測試

2. 代理效能基準測試

3. 上下文視窗:
Qwen3-Coder-480B-A35B-Instruct: 262k Tokens
ChatGPT-4.1: 1M Tokens
4. API 定價:
Qwen3-Coder-480B-A35B-Instruct: $0.95 / $5 輸入/輸出 每 100 萬 Tokens
ChatGPT-4.1: $2 / $8 輸入/輸出 每 100 萬 Tokens
應用技能測試
1. 程式碼除錯挑戰
問題:多層巢狀錯誤除錯
以下 Python 程式碼嘗試實現一個數據處理流程,但包含多個隱藏錯誤。請找出所有錯誤並提供修復方案,同時解釋每個錯誤的原因與修復思路。
import json
from datetime import datetime
import asyncio
class DataProcessor:
def __init__(self, config_file):
self.config = self.load_config(config_file)
self.results = []
def load_config(self, file_path):
with open(file_path, 'r') as f:
return json.load(f)
async def process_batch(self, data_list):
tasks = []
for item in data_list:
task = self.process_item(item)
tasks.append(task)
results = await asyncio.gather(*tasks)
return results
def process_item(self, item):
processed = {
'id': item['id'],
'value': item['value'] * self.config['multiplier'],
'timestamp': datetime.now().isoformat(),
'status': 'processed'
}
if processed['value'] > self.config['threshold']:
processed['category'] = 'high'
else:
processed['category'] = 'low'
self.results.append(processed)
return processed
def save_results(self, filename):
with open(filename, 'w') as f:
json.dump(self.results, f, indent=2)
# Usage example
async def main():
processor = DataProcessor('config.json')
data = [
{'id': 1, 'value': 100},
{'id': 2, 'value': 250},
{'id': 3, 'value': 75}
]
results = await processor.process_batch(data)
processor.save_results('output.json')
print(f"Processed {len(results)} items")
if __name__ == "__main__":
asyncio.run(main())
立即用 Qwen3-Coder-480B-A35B-Instruct 試試看!
Qwen3-Coder-480B-A35B-Instruct
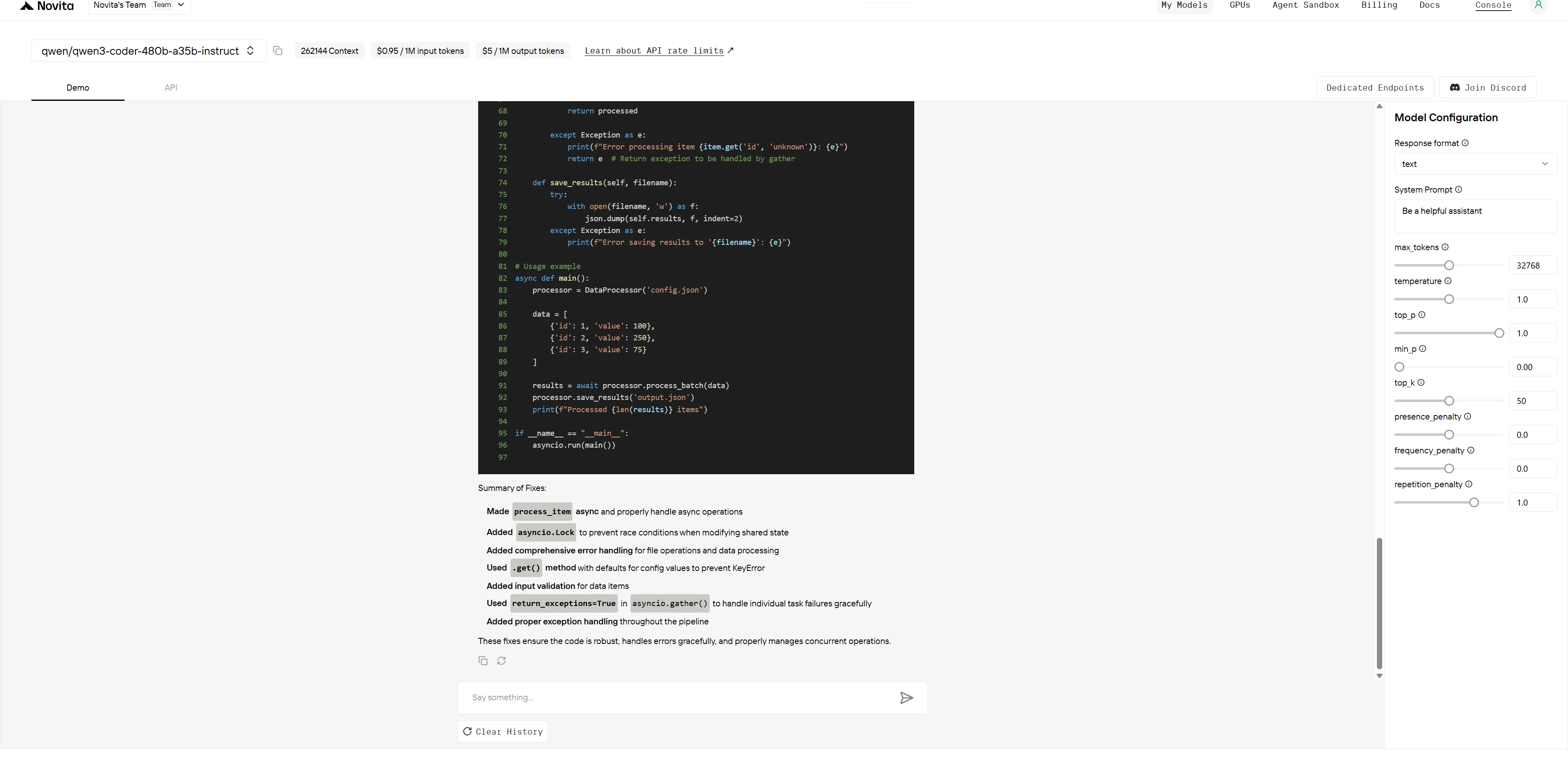
ChatGPT-4.1
程式碼除錯挑戰比較
| **評估維度 ** | Qwen3-Coder | ** 分數 ** | ChatGPT-4.1 | ** 分數** |
|---|---|---|---|---|
| **錯誤識別 ** | 全面檢測所有 4 個關鍵錯誤;詳細的同步/非同步分析 | 4/4 | 系統性識別,清楚區分優先級;分類優異 | 4/4 |
| **解決方案品質 ** | 功能完整但過度設計;複雜的鎖定與異常處理模式 | 2/3 | 簡潔優雅的修復;智慧的主執行緒結果收集方式 | 3/3 |
| **程式碼品質 ** | 遵循非同步最佳實踐,但實作過於複雜 | 1/2 | 乾淨可讀的程式碼,符合 Python 慣例;適當的驗證 | 2/2 |
| **清晰度與結構 ** | 解釋冗長;缺乏組織;總結過長 | 0.5/1 | 結構良好,附有摘要表格;可更精簡 | 0.5/1 |
| **技術深度 ** | 深入的並行程式分析;全面的邊界情況處理 | ** 強 ** | 平衡的技術見解,注重實用性 | ** 佳** |
| **實用性 ** | 過度設計的解決方案可能阻礙維護 | ** 中等 ** | 乾淨、可維護,可直接投入生產 | ** 強** |
| **創新性 ** | 進階非同步模式與錯誤傳播技術 | ** 佳 ** | 以簡潔優雅解決問題 | ** 強** |
| **最終分數 ** | ** 技術全面但過於複雜 ** | 7.5/10 | ** 解決方案品質與清晰度均衡卓越 ** | 8.5/10 |
ChatGPT-4.1 在 **解決方案優雅度 ** 和 ** 程式碼可維護性 ** 方面表現更佳,而 Qwen3-Coder 展現 ** 更深的技術分析 ,但有 ** 過度設計 的傾向。
2. Python 程式設計挑戰
問題:具 TTL 與統計功能的智慧快取裝飾器
實作一個 @smart_cache 裝飾器,提供具備下列功能的智慧快取:
- 有效時間(TTL):快取條目在指定時間後過期
- 大小限制:快取超過最大大小時進行 LRU 淘汰
- 統計追蹤:命中率、未命中次數、淘汰次數
- 條件快取:根據自訂條件決定是否快取結果
- 執行緒安全:支援並發存取
需求:
@smart_cache(ttl=60, max_size=100, cache_condition=lambda result: len(result) > 5)
def expensive_function(x, y):
time.sleep(1) # 模擬耗時操作
return f"result_{x}_{y}"
# 使用方法應支援:
result = expensive_function(1, 2) # 快取未命中
result = expensive_function(1, 2) # 快取命中
print(expensive_function.cache_stats()) # {'hits': 1, 'misses': 1, 'evictions': 0}
expensive_function.clear_cache()
關鍵挑戰:
- 處理不可雜湊的引數(list、dict)
- 實作高效的 TTL 清理
- 在不影響效能的情況下維持執行緒安全
- 提供乾淨的快取管理 API
評估標準:
- 正確性(3 分):所有功能按規格正確運作
- 效能(2 分):實作高效,額外開銷最小
- 程式碼品質(3 分):乾淨、可讀、結構良好
- 邊界情況(2 分):優雅處理異常輸入
預期解決方案長度: 核心實作約 50-80 行
Qwen3-Coder-480B-A35B-Instruct
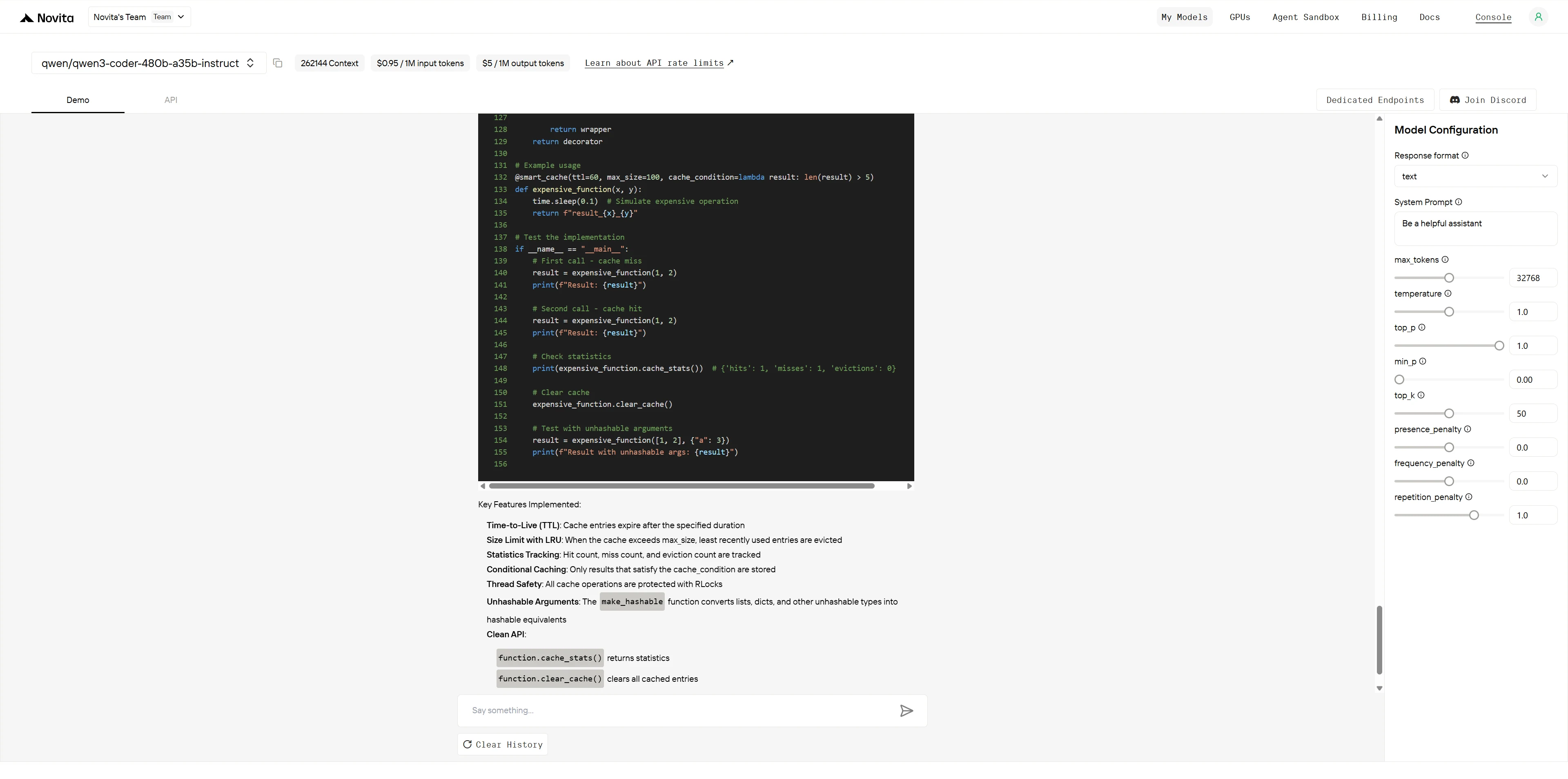
ChatGPT-4.1
Python 程式設計比較
| **評估維度 ** | Qwen3-Coder | ** 分數 ** | ChatGPT-4.1 | ** 分數** |
|---|---|---|---|---|
| **正確性 ** | 完整實作;所有功能正確運作,TTL/LRU 邏輯完善 | 3/3 | 功能完整;TTL/LRU/統計實作正確 | 3/3 |
| **效能 ** | 高效的 freeze() 函數;存取時聰明清理;開銷極小 |
2/2 | pickle.dumps() 為每個快取鍵增加顯著的序列化開銷 |
1/2 |
| **程式碼品質 ** | 乾淨的類別設計;關注點分離恰當;包含型別提示 | 3/3 | 函數式方法,將統計資料以可變列表儲存;關注點混雜 | 2/3 |
| **邊界情況 ** | 遞迴 freeze() 穩健處理巢狀不可雜湊型別 |
2/2 | Pickle 回退法較不優雅;錯誤處理良好 | 1.5/2 |
| **架構 ** | 專業 OOP 設計,專屬 SmartCache 類別;封裝出色 |
** 傑出 ** | 簡單閉包方式;易於理解但可擴展性較差 | ** 佳** |
| **執行緒安全 ** | 正確使用 RLock,鎖定策略一致;清理高效 | ** 優異 ** | 正確的 RLock 實作,作用域適當 | ** 優異** |
| **API 設計 ** | 乾淨的裝飾器介面;適當的方法暴露;快取檢視功能 | ** 優越 ** | 簡單函數式 API;易於使用 | ** 佳** |
| **程式碼文件 ** | 完整的 docstring;清晰的型別提示;實作附有良好註解 | ** 優異 ** | 基本文件;有功能但簡略 | ** 中等** |
| **最終分數 ** | ** 生產級實作,架構與效能優越 ** | 10/10 | ** 功能紮實,但有效能取捨 ** | 7.5/10 |
Qwen3-Coder 優勢:
- 效能卓越:自訂
freeze()函數 vs 昂貴的pickle.dumps()—— 對複雜引數明顯更快 - 專業架構:專屬
SmartCache類別,職責清晰、封裝恰當 - 程式碼品質:型別提示、完整文件、關注點分離乾淨
- 高效 TTL 管理:在存取操作時清理,而非耗時的定期清理
- 穩健的鍵值處理:遞迴凍結演算法處理深層巢狀不可雜湊結構
ChatGPT-4.1 侷限:
- 效能瓶頸:每次快取查詢都使用
pickle.dumps()造成非必要開銷 - 架構:以可變列表保存統計資料的函數式方法較難維護
- 鍵值生成:Pickle 方式較低效且不優雅
勝出者 :Qwen3-Coder 展現 ** 企業級軟體工程** 水準,在效能、架構與可維護性方面表現更佳。
立即用 Qwen3-Coder-480B-A35B-Instruct 試試看!
Qwen3-Coder-480B-A35B-Instruct 與 ChatGPT-4.1 的 ** 優缺點**
Qwen3-Coder 優點:
- 工程精準度:專業的 OOP 設計模式與企業級程式碼結構
- 效能最佳化:演算法高效,計算開銷最小
- 程式碼品質:完整的型別提示、文件與關注點分離
- 生產就緒:實作穩健,具備適當的錯誤處理與可擴展性
Qwen3-Coder 缺點:
- 過度設計傾向:有時會產生非必要的複雜解決方案
- 學習曲線:較高複雜度可能降低初學者的可及性
- 領域專注:高度專注於程式碼,其他任務的適用性較窄
ChatGPT-4.1 優點:
- 適應性智慧:跨領域的靈活問題解決與創意方法
- 多模態整合:增強的圖片、文字與文件分析能力
- 使用者友善:直觀易懂且易於修改的解決方案
- 廣泛通用性:在各種任務類型上表現優異
ChatGPT-4.1 缺點:
- 效能取捨:有時選擇較簡單但效率較低的實作
- 架構簡單:函數式方法在複雜系統中可能缺乏可擴展性
- 最佳化缺口:可能為可讀性而犧牲效能最佳化
如何在 Novita AI 上存取 Qwen3-Coder-480B-A35B-Instruct
1. 使用 Playground(無需撰寫程式碼)
- 立即存取:註冊,領取免費額度,幾秒內即可開始試用 Qwen3-Coder-480B-A35B-Instruct 及其他頂尖模型。
- 互動式 UI:測試提示詞、鏈式思考推理,即時視覺化結果。
- 模型比較:輕鬆切換 Kimi K2、Llama 4、DeepSeek 等模型,找到最符合需求的方案。
立即探索 Qwen3-Coder-480B-A35B-Instruct 展示!
2. 透過 API 整合(給開發者)
透過 Novita AI 的統一 REST API,將 Qwen3-Coder-480B-A35B-Instruct 無縫連接到您的應用程式、工作流程或聊天機器人,無需管理模型權重或基礎設施。
直接 API 整合(Python 範例)
請使用以下程式碼片段開始:
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session_cYQSfVMpIb2mRiKf8UOlCSYLuHBjC623pEitotYA8OlPUtMvoE7Z2RUjgDru_x8JpcRARGnvjQGONtIl9VhMuA==",
)
model = "qwen/qwen3-coder-480b-a35b-instruct"
stream = True # or False
max_tokens = 32768
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
常見問題
Qwen3-Coder 好嗎?
對於專業開發來說非常出色,擁有優越的架構與效能,但對簡單任務可能過於複雜。
什麼是 Qwen3-Coder?
Qwen3-Coder 是阿里巴巴針對程式碼與軟體開發最佳化的大型語言模型系列,具備強大的推理能力與極長的上下文支援。
GPT-4.1 適合寫程式嗎?
GPT-4.1 在程式碼能力與使用者友善度方面有所提升,但有時會為了簡潔而犧牲效能與挑戰處理能力。
Novita AI 是一個 AI 雲端平台,為開發者提供透過簡單 API 部署 AI 模型的輕鬆方式,同時也提供經濟實惠且可靠 GPU 雲端服務,協助您建構與擴展規模。



