

图形处理单元(GPU)世界正因 NVIDIA Blackwell 架构的推出而迎来重大变革。在深入探讨 B100 和 B200 GPU 的细节之前,了解这一新架构的背景和意义至关重要。进入 2025 年,B100 和 B200 GPU 承诺在性能、效率和 AI 能力方面带来显著提升。这些新 GPU 的到来恰逢 AI 模型规模和复杂程度空前增长的关键时期。
什么是 Blackwell 架构?
Blackwell 架构接替了 NVIDIA 的 Hopper 和 Ada Lovelace 架构,带来了诸如双芯片配置、第五代 Tensor Core 和增强的内存能力等变革性特性。Blackwell GPU 采用台积电的 4NP 工艺节点(用于数据中心产品)和 4N 工艺(用于消费类产品)制造,通过架构创新而非制程节点的重大进步实现了性能提升。
主要特性包括:
- 双芯片配置:通过 10 TB/s 的芯片间带宽实现统一操作,提供大规模扩展能力。
- FP4/FP6 精度管理:针对生成式模型和计算机视觉等 AI 工作负载进行优化。
- 机密计算:增强医疗、金融等行业敏感数据的安全性。
- HBM3e 内存:高达 8 TB/s 的带宽,为无缝 AI 训练和推理提供支持。
与前代对比:Hopper vs. Blackwell
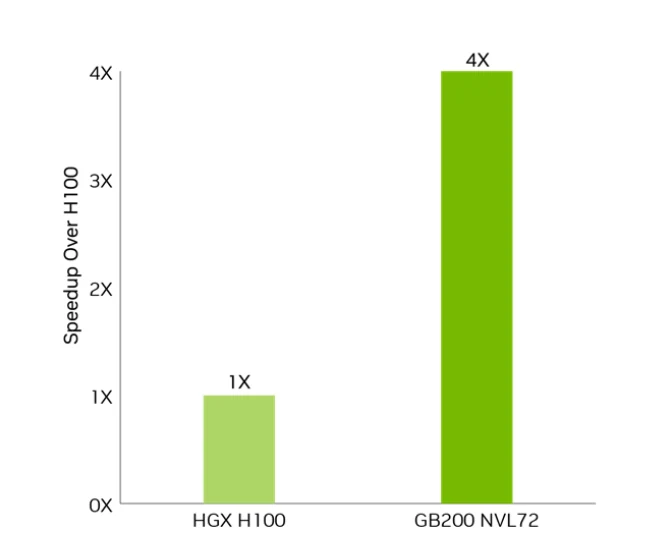
柱状图清晰地展示了 HGX H100 与 GB200 NVL72 之间的显著性能差距,基于 Blackwell 的 GB200 在关键工作负载上的速度是 Hopper 架构 H100 的 4 倍。
性能亮点
- 原始性能差异:关键工作负载上,GB200 NVL72 相比 H100 实现 4 倍加速。
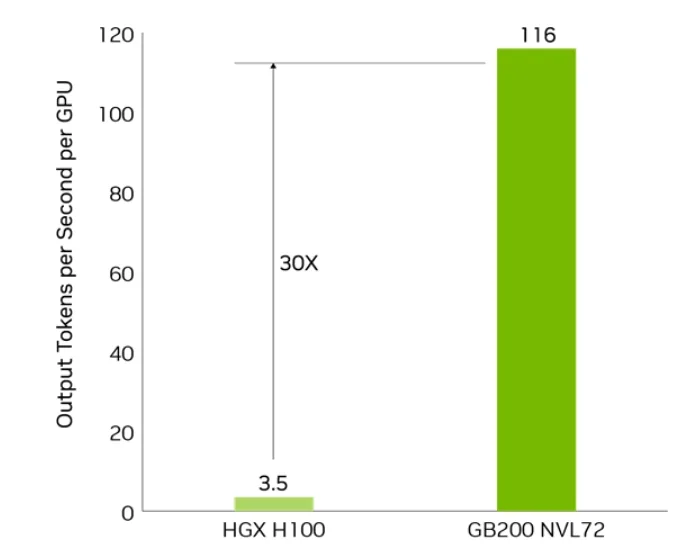
- LLM 推理:针对 GPT-MoE-1.8T 等大语言模型,最高实现 30 倍加速。
- 能效:在等效 GPU 数量下能耗降低 25 倍。
- 总拥有成本:相比 H100 部署,TCO 降低 25 倍。
实现这一飞跃的技术进步
- 第二代 Transformer 引擎,支持新的 FP4 精度。
- 增强的内存子系统:8TB/s HBM3e 带宽(Hopper 为 2TB/s)。
- 先进的 NVLink 技术:1.8 TB/s GPU 间互连。
- 扩展的 GPU 域:72-GPU NVLink 域(Hopper 为 8 路)。
- 液冷散热:管理高密度计算热输出的必要条件。
NVIDIA Blackwell B100 与 B200:主要区别
NVIDIA 最新的 HGX B100 和 B200 系列 GPU 代表了当前 AI 加速计算的顶级水平。这两款基于 Blackwell 架构的高性能计算平台在各种 AI 训练和推理任务中表现出色。下表对比了这两款产品的核心技术规格,包括计算能力、内存带宽和功耗特性。
| 特性 | HGX B100 | HGX B200 |
|---|---|---|
| 外形规格 | 8x NVIDIA Blackwell GPU | 8x NVIDIA Blackwell GPU |
| FP4 Tensor Core | 112 PetaFLOPS | 144 PetaFLOPS |
| FP8/FP6/INT8 | 56 PetaFLOPS | 72 PetaFLOPS |
| 快速内存 | 高达 1.5TB | 高达 1.5TB |
| 总内存带宽 | 高达 64TB/s | 高达 64TB/s |
| 总 NVLink 带宽 | 14.4 TB/s | 14.4 TB/s |
| FP4 Tensor Core(每 GPU) | 14 PetaFLOPS | 18 PetaFLOPS |
| FP8/FP6 Tensor Core(每 GPU) | 7 PetaFLOPS | 9 PetaFLOPS |
| INT8 Tensor Core(每 GPU) | 7 PetaOPS | 9 PetaOPS |
| FP16/BF16 Tensor Core(每 GPU) | 3.5 PetaFLOPS | 4.5 PetaFLOPS |
| TF32 Tensor Core(每 GPU) | 1.8 PetaFLOPS | 2.2 PetaFLOPS |
| FP32(每 GPU) | 60 TeraFLOPS | 80 TeraFLOPS |
| FP64 Tensor Core(每 GPU) | 30 TeraFLOPS | 40 TeraFLOPS |
| FP64 | 30 TeraFLOPS | 40 TeraFLOPS |
| GPU 内存 | 带宽 | 最高 192 GB HBM3e | 最高 8 TB/s | 最高 192 GB HBM3e | 最高 8 TB/s |
| 最大热设计功耗(TDP) | 700W | 1000W |
| 互连 | NVLink:1.8TB/s PCIe Gen6:256GB/s |
NVLink:1.8TB/s PCIe Gen6:256GB/s |
| 服务器选项 | NVIDIA HGX B100 合作伙伴及 NVIDIA 认证系统, 配备 8 GPU |
NVIDIA HGX B200 合作伙伴及 NVIDIA 认证系统, 配备 8 GPU |
B100 和 B200 GPU 的应用
Blackwell B100 和 B200 GPU 专为在 AI、游戏和 HPC 等多个领域发挥出色性能而设计。以下是每个型号如何服务于各自的市场:
- AI 和机器学习:B100 和 B200 均搭载 NVIDIA 强大的 Tensor Core,可加速深度学习和 AI 处理。B200 拥有更大的内存和更高的核心数量,非常适合数据中心中的大规模 AI 模型训练和部署。而 B100 则更易于获得,是研究实验室或小型 AI 应用的理想选择。
- 数据中心和 HPC:B200 凭借更高的内存和处理能力,专为需要海量计算资源的企业环境量身定制。这包括科学模拟、金融建模和大规模云工作负载等应用。
选择 Novita AI 作为您的云 GPU 服务商
在云 GPU 服务方面,Novita AI 是领先的提供商,提供灵活且可扩展的解决方案,充分利用尖端 NVIDIA GPU。无论您需要灵活的按需小时费率,还是希望通过订阅计划在长期承诺中获得更大折扣,我们都有多种选项满足您的需求。我们的计划可提供对强大 GPU 的访问,包括 RTX 4090、RTX 6000 Ada 和 H100,均配备 Tensor Core 以加速您的 AI 和深度学习任务。每个计划都包含专用资源和高级支持,确保最佳性能和专业协助。选择最符合您计算需求和使用偏好的计划。
| **选项 ** | RTX 3090 24 GB | RTX 4090 24 GB | RTX 6000 Ada 48GB | H100 SXM 80 GB |
| 按需 | $0.21/小时 | $0.35/小时 | $0.70/小时 | $2.89/小时 |
| 1-5 个月 | $136.00/月(9折) | $226.80/月(9折) | $453.60/月(9折) | $1872.72/月(9折) |
| 6-11 个月 | $129.00/月(85折) | $206.64/月(82折) | $428.40/月(85折) | $1664.64/月(8折) |
| 12 个月 | $113.40/月(75折) | $189.00/月(75折) | $403.20/月(8折) | $1498.18/月(72折) |
如果您对 Novita AI 感兴趣,请按照以下步骤操作:
步骤 1:创建账户
准备好开始了吗?只需几分钟即可在 Novita AI 平台注册。登录后,前往“GPUs”页面浏览可用实例,比较规格,并选择最适合您的计划。凭借直观的界面,您可以轻松部署第一个 GPU 实例,加速 AI 开发之旅。

[立即尝试 Novita AI](https://novita.ai/?utm_source=blogs_GPU&utm_medium=article&utm_campaign=Next-Gen NVIDIA Blackwell GPUs: Everything We Know About B100 & B200 Specifications)
步骤 2:选择您的 GPU
我们的平台提供多种专业设计的模板,以满足各种用例需求,同时您也可以从头开始构建自己的方案。凭借高性能 GPU(如 NVIDIA H100)以及充足的显存和内存,我们确保即使是要求最苛刻的 AI 模型也能获得流畅、快速且高效的训练。

[尝试 Novita AI 的高性能 GPU](https://novita.ai/gpus-console/?utm_source=blogs_GPU&utm_medium=article&utm_campaign=Next-Gen NVIDIA Blackwell GPUs: Everything We Know About B100 & B200 Specifications)
步骤 3:自定义您的设置
享受根据您需求定制的灵活存储解决方案,从 60 GB 免费容器磁盘空间开始。通过按需付费升级或适合您工作流程和预算的订阅计划,轻松扩展规模。无论是启动新项目还是处理大规模部署,我们的动态存储系统提供即时扩展和可靠的资源调配——让您始终拥有所需空间,即刻可用。

步骤 4:启动实例
选择最适合您的定价模式——按需获得最大灵活性,或订阅获得更大优惠。查看实例规格和成本概览,一键启动。您的高性能 GPU 环境将在几秒内启动并运行,让您无需等待即可直接投入项目。

结论
NVIDIA 的 Blackwell 架构将在 AI、游戏和高性能计算领域产生重大影响。B100 和 B200 GPU 凭借其令人印象深刻的规格和能力,有望在消费和企业应用中引领潮流。无论您是希望提升游戏性能、加速 AI 工作负载,还是构建大规模云基础设施,Blackwell GPU 都能提供所需的强大性能和灵活性。
如果您正在寻找最适合您需求的 GPU 解决方案,Novita AI 提供基于 Blackwell 的云 GPU 服务,确保您始终凭借最新的 GPU 技术保持领先。
常见问题
B100 和 B200 的主要区别是什么?
B200 相比 B100 提供更高的性能规格,拥有更大的内存带宽、更强的互连能力以及在 AI 工作负载(尤其是大语言模型)方面更出色的性能。
Blackwell GPU 最适合哪些工作负载?
Blackwell GPU 在 AI 训练和推理方面表现出色,特别适合大语言模型(LLM)、生成式 AI、科学计算和高性能计算应用。
Blackwell GPU 需要液冷散热吗?
是的,液冷散热对于管理这些高密度计算单元的热输出至关重要,尤其是在数据中心部署中。
[Novita AI](https://novita.ai/?utm_source=blogs_GPU&utm_medium=article&utm_campaign=Next-Gen NVIDIA Blackwell GPUs: Everything We Know About B100 & B200 Specifications) 是一个 AI 云平台,为开发者提供通过简单 API 部署 AI 模型的便捷方式,同时提供经济实惠且可靠的 GPU 云,用于构建和扩展。
推荐阅读
AI 计算的下一个时代:NVIDIA 从 Hopper 到 Blackwell 的旅程



