

عالم وحدات معالجة الرسومات (GPUs) على أعتاب تحول كبير مع إدخال بنية NVIDIA Blackwell. بينما نتعمق في تفاصيل معالجات B100 و B200، من الضروري فهم سياق وأهمية هذه البنية الجديدة. مع دخولنا عام 2025، تعد معالجات B100 و B200 بتحسينات كبيرة في الأداء والكفاءة وقدرات الذكاء الاصطناعي. هذه المعالجات الجديدة مهمة بشكل خاص لأنها تصل خلال فترة من النمو غير المسبوق في حجم ونماذج الذكاء الاصطناعي.
ما هي بنية Blackwell؟
تخلف بنية Blackwell بنيتي NVIDIA Hopper و Ada Lovelace، وتقدم ميزات تحويلية مثل تكوينات القالب المزدوج (dual-die)، وأجيال خامسة من Tensor Cores، وقدرات ذاكرة محسّنة. تم تصنيعها باستخدام عقدة عملية TSMC 4NP لمنتجات مراكز البيانات و 4N للمنتجات الاستهلاكية، تحقق معالجات Blackwell مكاسب في الأداء من خلال الابتكارات الهيكلية بدلاً من التطورات الكبرى في العقدة العملية.
تشمل الميزات الرئيسية:
- تكوينات القالب المزدوج (Dual-die configurations): تشغيل موحد مع نطاق ترددي 10 تيرابايت/ثانية بين الرقائق لتحقيق قابلية توسع هائلة.
- إدارة دقة FP4/FP6: مُحسّنة لأحمال عمل الذكاء الاصطناعي مثل النماذج التوليدية ورؤية الكمبيوتر.
- الحوسبة السرية (Confidential Computing): أمان محسّن للبيانات الحساسة في صناعات مثل الرعاية الصحية والتمويل.
- ذاكرة HBM3e: نطاق ترددي يصل إلى 8 تيرابايت/ثانية لتدريب واستدلال سلس للذكاء الاصطناعي.
مقارنة مع الأجيال السابقة: Hopper مقابل Blackwell
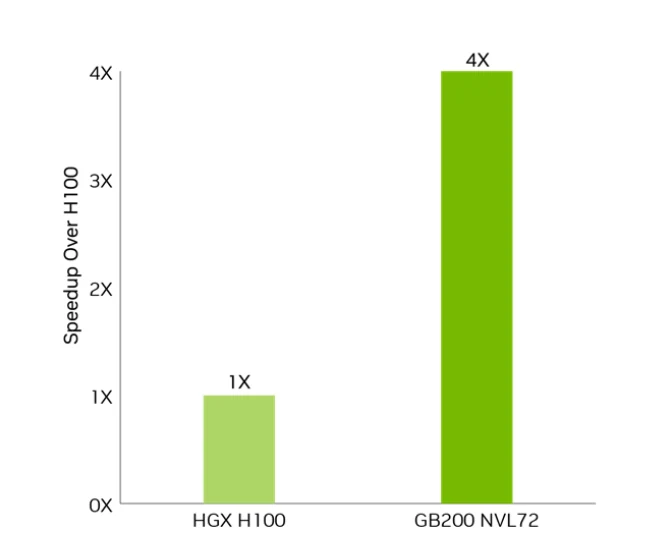
يوضح الرسم البياني الشريطي بوضوح فجوة أداء دراماتيكية بين HGX H100 و GB200 NVL72، حيث يوفر GB200 القائم على Blackwell سرعة 4 أضعاف مقارنة بـ H100 القائم على Hopper.
أبرز ما يتعلق بالأداء
- فارق الأداء الخام: يحقق GB200 NVL72 تسريعًا بمقدار 4 أضعاف مقارنة بـ H100 لأحمال العمل الرئيسية
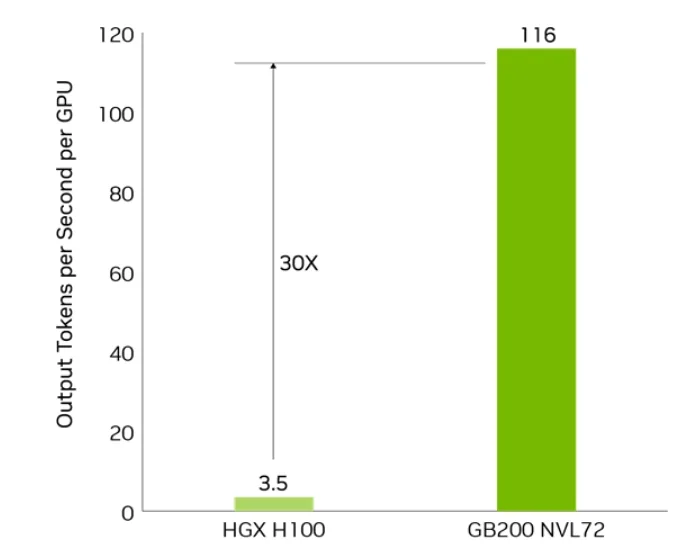
- استدلال LLM: تسريع يصل إلى 30 ضعفًا لنماذج اللغة الكبيرة مثل GPT-MoE-1.8T
- كفاءة الطاقة: استهلاك طاقة أقل بمقدار 25 مرة مع عدد مكافئ من وحدات GPU
- التكلفة الإجمالية للملكية: TCO أقل بمقدار 25 مرة مقارنة بنشر H100
التطورات التقنية التي تمكن هذه القفزة
- محرك المحولات من الجيل الثاني (Second-generation Transformer Engine) مع دعم دقة FP4 الجديدة
- نظام فرعي محسّن للذاكرة: نطاق ترددي 8 تيرابايت/ثانية HBM3e (مقابل 2 تيرابايت/ثانية في Hopper)
- تقنية NVLink المتقدمة: اتصال بين GPU و GPU بسرعة 1.8 تيرابايت/ثانية
- مجال GPU موسع: نطاق NVLink بـ 72 GPU (مقابل 8 طرق في Hopper)
- التبريد السائل: ضروري لإدارة الحرارة الناتجة عن الحوسبة عالية الكثافة
NVIDIA Blackwell B100 مقابل B200: الاختلافات الرئيسية
تمثل معالجات NVIDIA HGX B100 و B200 من السلسلة الجديدة ذروة الحوسبة المتسارعة للذكاء الاصطناعي. تظهر هاتان المنصتان عاليتا الأداء القائمتان على بنية Blackwell أداءً ممتازًا في مهام تدريب واستدلال الذكاء الاصطناعي المختلفة. يقارن الجدول التالي المواصفات التقنية الأساسية لهذين المنتجين، بما في ذلك قوة الحوسبة وعرض النطاق الترددي للذاكرة وخصائص الطاقة.
| Feature | HGX B100 | HGX B200 |
|---|---|---|
| عامل الشكل (Form Factor) | 8x NVIDIA Blackwell GPU | 8x NVIDIA Blackwell GPU |
| FP4 Tensor Core | 112 بيتافلوبس (PetaFLOPS) | 144 بيتافلوبس |
| FP8/FP6/INT8 | 56 بيتافلوبس | 72 بيتافلوبس |
| الذاكرة السريعة (Fast Memory) | حتى 1.5 تيرابايت | حتى 1.5 تيرابايت |
| النطاق الترددي الإجمالي للذاكرة (Aggregate Memory Bandwidth) | حتى 64 تيرابايت/ثانية | حتى 64 تيرابايت/ثانية |
| النطاق الترددي الإجمالي لـ NVLink (Aggregate NVLink Bandwidth) | 14.4 تيرابايت/ثانية | 14.4 تيرابايت/ثانية |
| FP4 Tensor Core (لكل GPU) | 14 بيتافلوبس | 18 بيتافلوبس |
| FP8/FP6 Tensor Core (لكل GPU) | 7 بيتافلوبس | 9 بيتافلوبس |
| INT8 Tensor Core (لكل GPU) | 7 بيتاوبس (PetaOPS) | 9 بيتاوبس |
| FP16/BF16 Tensor Core (لكل GPU) | 3.5 بيتافلوبس | 4.5 بيتافلوبس |
| TF32 Tensor Core (لكل GPU) | 1.8 بيتافلوبس | 2.2 بيتافلوبس |
| FP32 (لكل GPU) | 60 تيرافلوبس (teraFLOPS) | 80 تيرافلوبس |
| FP64 Tensor Core (لكل GPU) | 30 تيرافلوبس | 40 تيرافلوبس |
| FP64 | 30 تيرافلوبس | 40 تيرافلوبس |
| ذاكرة GPU | النطاق الترددي | حتى 192 جيجابايت HBM3e | حتى 8 تيرابايت/ثانية | حتى 192 جيجابايت HBM3e | حتى 8 تيرابايت/ثانية |
| أقصى طاقة حرارية تصميمية (TDP) | 700 واط | 1000 واط |
| الربط البيني (Interconnect) | NVLink: 1.8 تيرابايت/ثانية PCIe Gen6: 256 جيجابايت/ثانية |
NVLink: 1.8 تيرابايت/ثانية PCIe Gen6: 256 جيجابايت/ثانية |
| خيارات الخادم | شريك NVIDIA HGX B100 و أنظمة معتمدة من NVIDIA مع 8 وحدات GPU |
شريك NVIDIA HGX B200 و أنظمة معتمدة من NVIDIA مع 8 وحدات GPU |
المصدر: https://www.nvidia.com
تطبيقات معالجات B100 و B200
صُممت معالجات Blackwell B100 و B200 لتتفوق في مجموعة من المجالات، من الذكاء الاصطناعي إلى الألعاب والحوسبة عالية الأداء (HPC). إليك كيف يخدم كل نموذج سوقه الخاص:
- الذكاء الاصطناعي والتعلم الآلي: تم تجهيز كل من B100 و B200 بـ Tensor Cores القوية من NVIDIA، والتي تسرع عمليات التعلم العميق والذكاء الاصطناعي. يعتبر B200، بسعته المتزايدة وعدد النوى الأعلى، مثاليًا لتدريب نماذج الذكاء الاصطناعي واسعة النطاق ونشرها في مراكز البيانات. أما B100، فهو مثالي لمختبرات الأبحاث أو تطبيقات الذكاء الاصطناعي الأصغر حجمًا.
- مراكز البيانات و HPC: يعتبر B200، بذاكرته الأكبر وقوته الحاسوبية الأعلى، مصممًا خصيصًا للبيئات المؤسسية التي تتطلب موارد حاسوبية هائلة. يشمل ذلك تطبيقات في المحاكاة العلمية والنمذجة المالية وأحمال العمل السحابية واسعة النطاق.
اختر Novita AI لتكون مزود خدمة GPU السحابية الخاصة بك
عندما يتعلق الأمر بخدمات GPU السحابية، تبرز Novita AI كمزود رائد، حيث تقدم حلولاً مرنة وقابلة للتوسع تستفيد من أحدث معالجات NVIDIA GPU. سواء كنت بحاجة إلى أسعار بالساعة حسب الطلب أو خطة اشتراك بخصومات أعمق للالتزامات طويلة الأجل، لدينا مجموعة متنوعة من الخيارات التي تناسب احتياجاتك. توفر خططنا إمكانية الوصول إلى وحدات GPU قوية، بما في ذلك RTX 4090 و RTX 6000 Ada و H100، جميعها مزودة بـ Tensor Cores لتعزيز مهام الذكاء الاصطناعي والتعلم العميق. تأتي كل خطة مع موارد مخصصة ودعم متميز، مما يضمن الأداء الأمثل والمساعدة من الخبراء. اختر الخطة التي تناسب متطلباتك الحاسوبية وتفضيلات الاستخدام الخاصة بك.
| الخيار | RTX 3090 24 GB | RXT 4090 24 GB | RXT 6000 Ada 48GB | H100 SXM 80 GB |
| حسب الطلب | 0.21 دولار/ساعة | 0.35 دولار/ساعة | 0.70 دولار/ساعة | 2.89 دولار/ساعة |
| 1-5 أشهر | 136.00 دولار/شهر (خصم 10%) | 226.80 دولار/شهر (خصم 10%) | 453.60 دولار/شهر (خصم 10%) | 1872.72 دولار/شهر (خصم 10%) |
| 6-11 أشهر | 129.00 دولار/شهر (خصم 15%) | 206.64 دولار/شهر (خصم 18%) | 428.40 دولار/شهر (خصم 15%) | 1664.64 دولار/شهر (خصم 20%) |
| 12 شهرًا | 113.40 دولار/شهر (خصم 25%) | 189.00 دولار/شهر (خصم 25%) | 403.20 دولار/شهر (خصم 20%) | 1498.18 دولار/شهر (خصم 28%) |
إذا كنت مهتمًا بـ Novita AI، يرجى اتباع الخطوات أدناه:
الخطوة 1: إنشاء حساب
هل أنت مستعد للبدء؟ سجل على منصة Novita AI في دقائق معدودة. بعد تسجيل الدخول، انتقل إلى صفحة “GPUs” لتصفح المثيلات المتاحة، ومقارنة المواصفات، واختيار الخطة الأنسب لك. بفضل واجهتنا البديهية، يمكنك نشر أول مثيل GPU لك بسهولة وتسريع رحلة تطوير الذكاء الاصطناعي.

[جرب Novita AI الآن](https://novita.ai/?utm_source=blogs_GPU&utm_medium=article&utm_campaign=Next-Gen NVIDIA Blackwell GPUs: Everything We Know About B100 & B200 Specifications)
الخطوة 2: اختر GPU الخاص بك
توفر منصتنا مجموعة متنوعة من القوالب المصممة بشكل احترافي لتناسب حالات الاستخدام المختلفة، بالإضافة إلى حرية بناء الحلول الخاصة بك من الصفر. مدعومة بوحدات GPU عالية الأداء مثل NVIDIA H100 - مع ذاكرة VRAM و RAM سخية - نضمن تدريبًا سلسًا وسريعًا وفعالًا حتى لنماذج الذكاء الاصطناعي الأكثر تطلبًا.

[جرب وحدات GPU عالية الأداء من Novita AI](https://novita.ai/gpus-console/?utm_source=blogs_GPU&utm_medium=article&utm_campaign=Next-Gen NVIDIA Blackwell GPUs: Everything We Know About B100 & B200 Specifications)
الخطوة 3: تخصيص الإعداد الخاص بك
استمتع بحلول تخزين مرنة مصممة خصيصًا لاحتياجاتك، بدءًا من 60 جيجابايت من مساحة Container Disk المجانية. قم بالتوسع بسهولة مع ترقيات الدفع حسب الاستخدام أو خطط الاشتراك التي تناسب سير عملك وميزانيتك. سواء كنت تطلق مشروعًا جديدًا أو تتعامل مع عمليات نشر واسعة النطاق، يوفر نظام التخزين الديناميكي لدينا توسعًا فوريًا وتوفيرًا موثوقًا - بحيث يكون لديك دائمًا المساحة التي تحتاجها، في الوقت الذي تحتاجه.

الخطوة 4: تشغيل المثيل الخاص بك
اختر نموذج التسعير الذي يناسبك - اختر “حسب الطلب” (On-Demand) لأقصى مرونة أو “اشتراك” (Subscription) لتوفير أكبر. راجع مواصفات المثيل الخاص بك ونظرة عامة على التكلفة، ثم قم بتشغيله بنقرة واحدة فقط. ستعمل بيئة GPU عالية الأداء الخاصة بك في غضون ثوانٍ، حتى تتمكن من الانتقال مباشرة إلى مشاريعك دون تأخير.

الخاتمة
من المقرر أن تحقق بنية NVIDIA Blackwell تأثيرًا كبيرًا في عالم الذكاء الاصطناعي والألعاب والحوسبة عالية الأداء. معالجات B100 و B200، بمواصفاتها وقدراتها المذهلة، في وضع يسمح لها بقيادة الطريق في كل من التطبيقات الاستهلاكية والمؤسسية. سواء كنت تتطلع إلى تحسين أداء الألعاب، أو تسريع أعباء عمل الذكاء الاصطناعي، أو بناء بنى تحتية سحابية واسعة النطاق، فإن معالجات Blackwell توفر القوة والمرونة التي تحتاجها.
إذا كنت تفكر في أفضل حل GPU لاحتياجاتك، فإن Novita AI توفر إمكانية الوصول إلى خدمات GPU السحابية المدعومة بـ Blackwell، مما يضمن أنك دائمًا في صدارة المنحنى بأحدث تقنيات GPU.
الأسئلة الشائعة
ما هي الاختلافات الرئيسية بين B100 و B200؟
يقدم B200 مواصفات أداء أعلى مقارنة بـ B100، مع نطاق ترددي أكبر للذاكرة، وقدرات ربط بيني محسّنة، وأداء أكبر لأحمال عمل الذكاء الاصطناعي، خاصة لنماذج اللغة الكبيرة.
ما هي أعباء العمل الأنسب لمعالجات Blackwell GPU؟
تتفوق معالجات Blackwell في تدريب واستدلال الذكاء الاصطناعي، خاصة لنماذج اللغة الكبيرة (LLMs)، والذكاء الاصطناعي التوليدي، والحوسبة العلمية، وتطبيقات الحوسبة عالية الأداء.
هل أحتاج إلى تبريد سائل لمعالجات Blackwell GPU؟
نعم، التبريد السائل ضروري لإدارة الحرارة الناتجة عن وحدات الحوسبة عالية الكثافة هذه، خاصة في عمليات نشر مراكز البيانات.
[Novita AI](https://novita.ai/?utm_source=blogs_GPU&utm_medium=article&utm_campaign=Next-Gen NVIDIA Blackwell GPUs: Everything We Know About B100 & B200 Specifications) هي منصة سحابية للذكاء الاصطناعي تقدم للمطورين طريقة سهلة لنشر نماذج الذكاء الاصطناعي باستخدام API بسيط، مع توفير سحابة GPU ميسورة التكلفة وموثوقة للبناء والتوسع.
قراءات موصى بها
الجيل التالي من حوسبة الذكاء الاصطناعي: رحلة NVIDIA من Hopper إلى Blackwell



