
引言
如果语言模型能够像人类一样,通过逐步分解的方式来处理复杂问题,那会怎样?在大语言模型(LLM)领域,最简到最繁提示(Least-to-Most Prompting)策略提供了一种有前景的解决方案。本文参考论文《最简到最繁提示法让大语言模型实现复杂推理》(Least-To-Most Prompting Enables Complex Reasoning in Large Language Models),探讨这种创新方法如何增强LLM的推理能力。通过将复杂任务分解为可管理的子问题,最简到最繁提示引导LLM从简单到复杂逐步推进。
什么是最简到最繁提示?
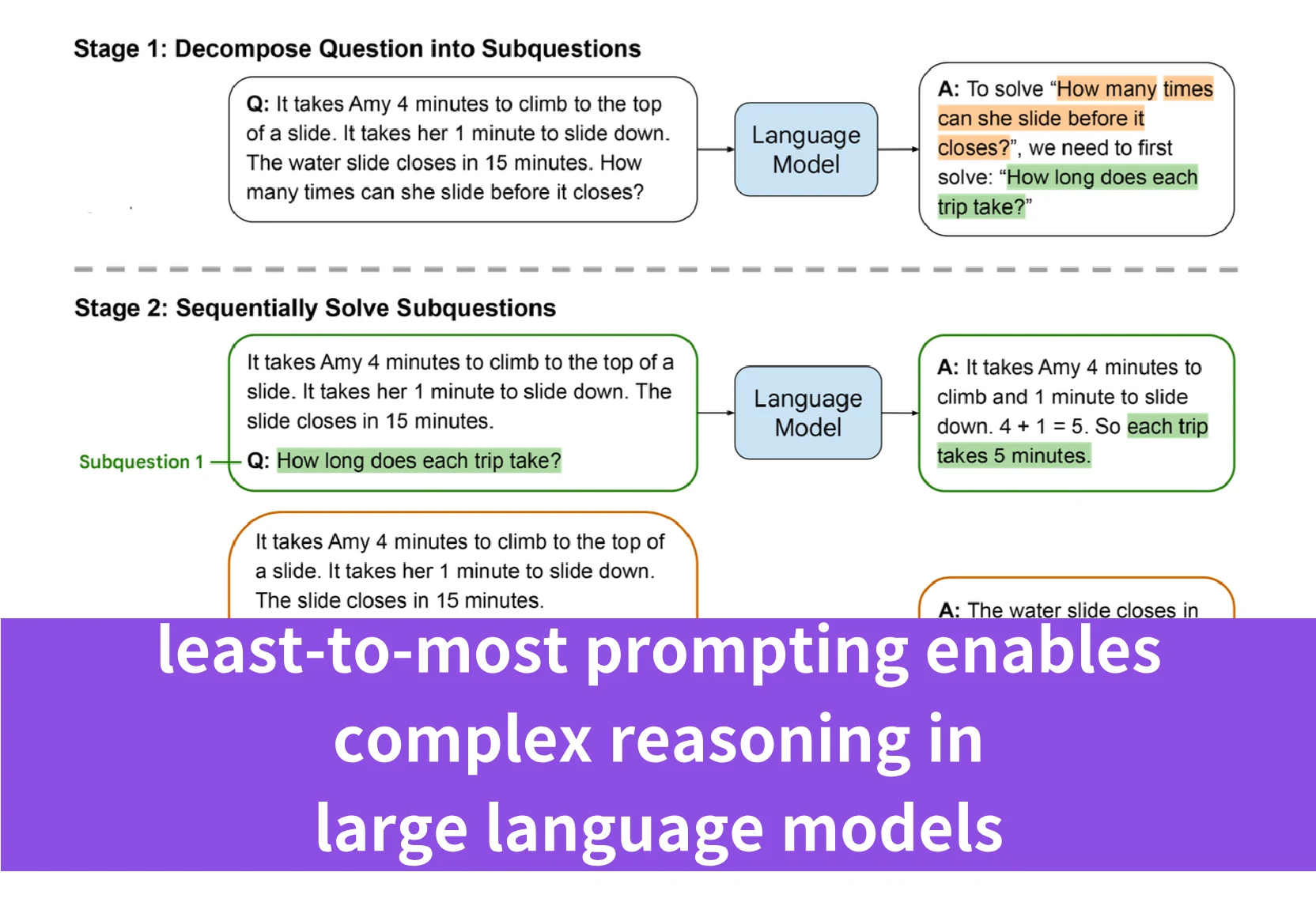
最简到最繁提示是一种创新策略,由论文《最简到最繁提示法让大语言模型实现复杂推理》提出,旨在增强大语言模型的推理能力。该方法通过将复杂问题分解为一系列更简单、更易管理的子问题来帮助LLM,整个过程分为两个主要阶段:

- 分解阶段:将复杂问题分解为一系列更简单的子问题。此阶段使用固定示例来演示分解过程,随后给出需要分解的具体问题。
- 子问题求解阶段:然后提示模型按顺序求解这些子问题。每个子问题的解答都借助之前已解决子问题的答案。此阶段包括子问题求解的示例、已解答子问题及其解法的列表,以及下一个要处理的问题。
提示的构建方式引导模型从问题的最简单方面逐步推进到最复杂方面,因此得名“最简到最繁”。
为什么需要最简到最繁提示?
最简到最繁提示的需求源于现有提示技术(尤其是思维链提示)的局限性。
思维链提示是一种鼓励大语言模型像人类思考问题那样逐步阐述推理过程的方法。该方法要求模型明确陈述从理解问题到得出最终答案所采取的每个逻辑步骤。通过将问题分解为一系列中间推理步骤,模型提供了透明且可证明的解决方案路径。
虽然思维链提示在多种自然语言推理任务中表现出显著的性能提升,但在推广到解决比提示示例更复杂的问题时,它往往会遇到困难。
最简到最繁提示如何让LLM实现复杂推理?
论文《最简到最繁提示法让大语言模型实现复杂推理》中的实验设计可按以下步骤分解:
确定研究目标
目标是使大语言模型能够执行比训练示例中的问题更困难的复杂推理任务。
选择任务
研究人员选择了代表不同类型推理的任务,包括符号操作、组合泛化和数学推理。
任务1:符号操作(末字母拼接任务):
- 问题:给定一个单词列表,输出列表中每个单词末字母的拼接结果。
- 示例:对于输入“think, machine, learning”,正确输出为“keg”。
- 最简到最繁提示:
- 分解问题:将列表分解为顺序子列表(“think”、“think, machine”、“think, machine, learning”)。
- 求解子问题:拼接每个子列表中单词的末字母(“think”得“k”,“machine”得“e”,“learning”得“g”)。
- 合并解答:利用子问题的解答构建最终答案(“k” + “e” = “ke”,再“ke” + “g” = “keg”)。
任务2:组合泛化(SCAN基准):
- 问题:将自然语言命令映射为动作序列。挑战在于泛化到比训练时见过的更长的动作序列。
- 示例:命令“look opposite right thrice after walk”应翻译为动作序列“TURN RIGHT, TURN RIGHT, LOOK, WALK”。
- 最简到最繁提示:
- 分解命令:将复杂命令拆分为更简单的部分(“look opposite right thrice”和“walk”)。
- 映射为动作:将每个部分翻译为动作(“look opposite right thrice”变成三次“TURN RIGHT, TURN RIGHT, LOOK”,“walk”保持“WALK”)。
- 合并动作:按顺序执行动作以形成最终序列。
任务3:数学推理(GSM8K和DROP数据集):
- 问题:求解可能需要多步推理的数学文字题。
- 示例:“Elsa有5个苹果。Anna比Elsa多2个苹果。她们一共有多少个苹果?”
- 最简到最繁提示:
- 分解问题:识别子问题(Anna有多少个苹果?她们一共有多少个苹果?)。
- 求解子问题:计算Anna的苹果数(5 + 2 = 7),再计算总数(5 + 7 = 12)。
- 最终答案:得出Elsa和Anna共有12个苹果。
设计提示策略
比较两种主要提示策略:
- 思维链提示:向模型提供展示逐步推理过程的示例来解决问题。

- 最简到最繁提示:这种新颖策略将复杂问题分解为更简单的子问题,并顺序求解,利用先前子问题的解答来促进下一个子问题的求解。

创建提示示例
对于每种提示策略,研究人员都制作了展示如何解决问题的示例。对于最简到最繁提示,这包括问题分解和子问题求解的示例。
在模型中实施提示
然后将这些提示作为输入提供给语言模型。对于最简到最繁提示,这涉及两个阶段:
- 分解阶段:要求模型将原始问题分解为一系列更简单的子问题。
- 子问题求解阶段:然后要求模型按顺序求解这些子问题,使用前面子问题的答案来指导下一个子问题的求解。
构建测试集
对于每个任务,研究人员创建了不同难度级别的测试集。
任务1:符号操作(末字母拼接任务):
- 测试集涉及生成不同长度的单词列表,以测试模型拼接列表中每个单词末字母的能力。
- 研究人员使用了Wiktionary上最常见的10,000个英语单词列表(排除粗俗词汇),得到9,694个单词。
- 对于每个所需列表大小(从4到12个单词),他们生成了500个随机单词序列。每个序列作为输入,对应的输出是单词末字母序列。
任务2:组合泛化(SCAN基准):
- SCAN基准包含需要映射为动作序列的自然语言命令。测试集挑战模型从较短动作序列泛化到较长动作序列的能力。
- 研究人员使用了SCAN数据集的现有划分,特别关注长度划分,其中包含比训练集更长的动作序列。
- 他们还确保测试集涵盖一系列命令,以评估模型处理不同类型组合泛化的能力。
任务3:数学推理(GSM8K和DROP数据集):
- 对于数学推理,研究人员使用了GSM8K数据集中的文字题和DROP数据集的数值推理子集。
- 测试集包含需要不同数量推理步骤才能解决的问题,使研究人员能够评估模型从简单问题泛化到更复杂问题的能力。
- 问题被选为代表不同难度级别,并确保有些问题需要的步骤比提示中演示的更多。
通过以这种方式构建测试集,研究人员能够严格评估最简到最繁提示策略,并将其效果与不同推理任务上的标准提示技术进行比较。
运行实验并收集结果
研究人员使用GPT-3模型(具体为code-davinci-002版本)运行实验,采用两种提示策略。他们记录了模型在测试集上的回答准确率。
分析结果
研究人员比较了使用不同提示策略时模型的性能。他们观察了整体准确率,并按解决问题所需的推理步骤数量对结果进行了细分。
错误分析
对于最简到最繁提示,研究人员进行了详细的错误分析,以了解常见错误,例如问题分解错误或子问题求解错误。
最简到最繁提示能让LLM的性能提升多少?
论文《最简到最繁提示法让大语言模型实现复杂推理》展示了最简到最繁提示在各种任务上的有效性,并将其性能与思维链提示和标准提示方法进行了比较。以下是论文中每个任务的性能改进总结:
符号操作(末字母拼接任务):
最简到最繁提示显著优于思维链提示,尤其在单词列表长度增加时。
对于长度为4到12个单词的列表,使用GPT-3 code-davinci-002模型的最简到最繁提示准确率在74.0%到94.0%之间,显著高于思维链提示的31.8%到84.2%。

组合泛化(SCAN基准):
最简到最繁提示在长度划分条件下仅使用14个示例就达到了99.7%的准确率,这是一个了不起的成果,因为针对整个数据集(超过15,000个示例)训练的专业神经符号模型在此任务上常常表现不佳。
相比之下,相同模型在长度划分条件下思维链提示仅达到16.2%的准确率。
数学推理(GSM8K和DROP数据集):
在GSM8K数据集上,最简到最繁提示略优于思维链提示,总体准确率为62.39%,而思维链提示为60.87%。
然而,对于需要至少5步才能解决的问题,最简到最繁提示显示出显著改进,准确率为45.23%,而思维链提示为39.07%。
在DROP数据集上,最简到最繁提示大幅优于思维链提示,非足球子集和足球子集的准确率分别为82.45%和74.77%,而思维链提示分别为58.78%和59.56%。
这些结果表明,最简到最繁提示在要求模型从简单示例泛化到更复杂问题的任务中特别有效。将复杂问题分解为一系列更简单的子问题并顺序求解的策略,使模型在不同推理任务上都能获得更高的准确率。
如何将最简到最繁提示集成到自己的LLM中?
基于《最简到最繁提示法让大语言模型实现复杂推理》作者提出的方法,我们为你创建了以下逐步指南:
步骤1:获取LLM API
首先,你需要能够访问一个可用于任务的LLM。Novita AI LLM API 为开发者提供了许多经济高效的LLM选项,包括Llama3-8b、Llama3-70b、Mythomax-13b等。

以下是使用Novita AI LLM API进行Chat Completion API调用的示例:
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
# 获取 Novita AI API Key,参考:https://novita.ai/get-started/Quick_Start.html#_3-create-an-api-key
api_key="<YOUR Novita AI API Key>",
)
model = "Nous-Hermes-2-Mixtral-8x7B-DPO"
stream = True # or False
max_tokens = 512
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": "Act like you are a helpful assistant.",
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
步骤2:准备分解提示
创建一组示例提示,演示如何将复杂问题分解为一系列更简单的子问题。示例应展示分解的结构,但无需包含子问题的具体内容。
步骤3:准备子问题求解提示
创建一组示例提示,演示如何求解各个子问题。这些示例应展示如何使用先前已解决子问题的结果逐步构建解决方案。
步骤4:实现最简到最繁提示算法
最简到最繁提示算法的关键步骤如下:
a. 将原始问题传入分解提示,获取子问题列表。
b. 对于每个子问题,构建一个包含先前子问题解答(如果有)和当前子问题的提示,传入LLM以获取解答。
c. 合并子问题的解答以得到原始问题的最终解答。
步骤5:与你的应用集成
将最简到最繁提示算法整合到应用程序的工作流程中。这可能涉及预处理输入、构建提示、调用LLM API以及后处理输出。
步骤6:评估与迭代
在各种任务和问题难度上测试你的实现。分析错误并根据需要优化提示设计或提示算法。
以下是由LLM创建的高级示例,你可能需要根据具体用例和LLM进行调整。
import openai
# 设置 Novita AI API key
openai.api_key = "<YOUR Novita AI API Key>"
openai.base_url = "https://api.novita.ai/v3/openai"
def decomp_prompt(original_problem):
"""
生成将原始问题分解为一系列子问题的提示。
Args:
original_problem (str): 要分解的原始问题。
Returns:
str: 用于分解问题的提示。
"""
return f"""
请将以下问题分解为一系列可以逐步解决的子问题:
{original_problem}
子问题:
{{{decomp_steps}}}
"""
def solve_prompt(prev_solutions, subproblem):
"""
在给定先前已解决子问题的情况下,生成解决特定子问题的提示。
Args:
prev_solutions (str): 先前已解决的子问题。
subproblem (str): 要解决的子问题。
Returns:
str: 用于解决子问题的提示。
"""
return f"""
给定以下先前已解决的子问题:
{prev_solutions}
请解决以下子问题:
{subproblem}
"""
def solve_problem(original_problem):
"""
使用最简到最繁提示算法解决原始问题。
Args:
original_problem (str): 要解决的原始问题。
Returns:
list: 子问题的解答列表。
"""
# 将原始问题分解为子问题
decomp_result = openai.Completion.create(
engine="text-davinci-002",
prompt=decomp_prompt(original_problem),
max_tokens=1024,
n=1,
stop=None,
temperature=0.7,
)
decomp_steps = decomp_result.choices[0].text.strip()
# 逐个解决子问题
solutions = []
for step in decomp_steps.split("\
"):
step = step.strip()
if step:
solve_result = openai.Completion.create(
engine="text-davinci-002",
prompt=solve_prompt("\
".join(solutions), step),
max_tokens=1024,
n=1,
stop=None,
temperature=0.7,
)
solutions.append(solve_result.choices[0].text.strip())
return solutions
# 示例用法
original_problem = "逐步解决一个复杂的数学问题。"
solutions = solve_problem(original_problem)
print("\
".join(solutions))
最简到最繁提示有哪些局限性?
领域特异性:
分解提示通常针对特定领域,可能无法很好地泛化到不同类型的问题。适用于数学文字题的提示可能对常识推理问题或其他领域的问题无效。
领域内泛化挑战:
即使在同一领域内,泛化分解过程也可能很困难。提示需要精心设计,以展示正确的分解方式,从而使模型达到最佳性能。
分解的复杂性:
某些复杂问题可能需要深刻理解如何拆解为更简单的子问题。设计有效引导模型完成这一过程的提示可能具有挑战性。
顺序依赖性:
最简到最繁提示生成的子问题通常是相互依赖的,需要按特定顺序解决。这种顺序性要求使提示过程比独立子问题更加复杂。
错误传播:
如果模型在问题分解或子问题求解的早期阶段出错,该错误可能会传播到后续步骤,导致最终解答不正确。
模型特异性性能:
最简到最繁提示的性能在不同模型或同一模型的不同版本之间可能存在差异。有些模型可能更适合处理任务中的迭代和递归特性。
提示工程:
最简到最繁提示的有效性可能高度依赖于提示工程的质量。创建能够准确生成分解和解答的有效提示需要仔细考虑和专业知识。
可扩展性:
尽管最简到最繁提示可能有效,但由于设计适当提示的难度增加以及错误传播的可能性,它可能无法很好地扩展到非常大或高度复杂的问题。
缺乏双向交互:
作者认为,提示法总体上可能不是教授LLM推理技能的最佳方法,因为它是一种单向沟通形式。更自然的进展可能是将提示演变为完全双向的对话,从而允许即时反馈和更高效的学习。
结论
通过将复杂问题分解为更简单的步骤并顺序求解,采用最简到最繁提示的LLM不仅增强了推理能力,还在各种任务(从符号操作到组合泛化和数学推理)中展现了卓越的性能。
然而,必须承认这种方法伴随的挑战。领域特异性、领域内泛化困难以及分解的复杂性都可能带来障碍。此外,子问题的顺序依赖性和潜在的错误传播凸显了精心设计提示和考虑模型特异性的必要性。
随着我们继续探索AI开发的新前沿,最简到最繁提示作为一项关键策略脱颖而出,它以前所未有的准确性和效率赋能LLM应对复杂推理任务的挑战,同时推动对其在不同问题领域应用优化的持续研究。
参考文献
Zhou, D., Schärli, N., Hou, L., Wei, J., Scales, N., Wang, X., Schuurmans, D., Cui, C., Bousquet, O., & Chi, E. (2023). Least-to-Most Prompting Enables Complex Reasoning in Large Language Models. In Proceedings of the International Conference on Learning Representations.
Novita AI 是一个一体化云平台,助力您的AI梦想。通过无缝集成的API、无服务器计算和GPU加速,我们提供经济高效的工具,助您快速构建和扩展AI驱动业务。告别基础设施烦恼,免费开始——Novita AI 让您的AI梦想成真。



