
Introduction
Et si les modèles de langage pouvaient aborder des problèmes complexes avec la même approche pas à pas que les humains ? Dans le domaine des grands modèles de langage (LLM), la stratégie du prompting du plus simple au plus complexe (Least-to-Most Prompting) offre une solution prometteuse. En se référant à l’article « Least-To-Most Prompting Enables Complex Reasoning in Large Language Models », ce blog explore comment cette méthode innovante améliore les capacités de raisonnement des LLM. En décomposant les tâches complexes en sous-problèmes gérables, le prompting du plus simple au plus complexe guide les LLM à travers une séquence progressive allant de la simplicité à la complexité.
Qu’est-ce que le prompting du plus simple au plus complexe ?
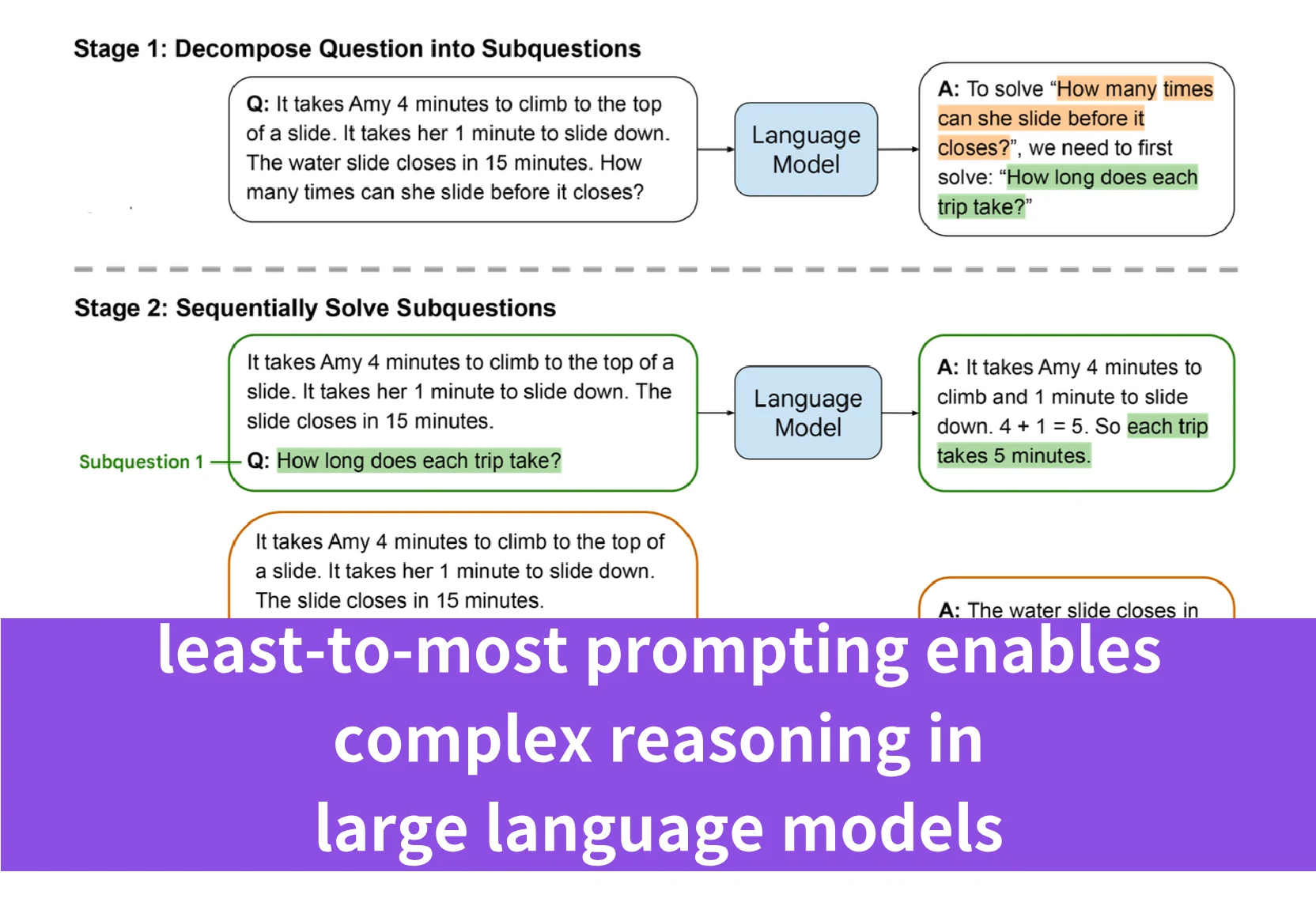
Le prompting du plus simple au plus complexe est une stratégie innovante introduite dans l’article « Least-To-Most Prompting Enables Complex Reasoning in Large Language Models » pour améliorer les capacités de raisonnement des grands modèles de langage (LLM). Cette méthode est conçue pour aider les LLM à s’attaquer à des problèmes complexes en les décomposant en une série de sous-problèmes plus simples et plus faciles à gérer. Le processus comprend deux étapes principales :

- Décomposition : Le problème complexe est décomposé en une liste de sous-problèmes plus simples. Cette étape utilise des exemples constants qui montrent le processus de décomposition, suivis de la question spécifique à décomposer.
- Résolution des sous-problèmes : Le modèle est ensuite invité à résoudre ces sous-problèmes de manière séquentielle. La solution de chaque sous-problème est facilitée par les réponses aux sous-problèmes précédemment résolus. Cette étape inclut des exemples de résolution de sous-problèmes, une liste de sous-questions précédemment répondues et leurs solutions, ainsi que la question suivante à traiter.
Les prompts sont construits de manière à guider le modèle à travers une séquence progressive, des aspects les plus simples du problème aux plus complexes, d’où le nom « du plus simple au plus complexe ».
Pourquoi avons-nous besoin du prompting du plus simple au plus complexe ?
Le besoin de prompting du plus simple au plus complexe découle des limitations observées dans les techniques de prompting existantes, en particulier le prompting par chaîne de pensée (chain-of-thought prompting).
Le prompting par chaîne de pensée est une approche qui encourage les grands modèles de langage à articuler leur processus de raisonnement étape par étape, à la manière dont un humain réfléchirait à un problème. Cette méthode implique que le modèle énonce explicitement chaque étape logique qu’il franchit pour passer de la compréhension de la question à l’obtention de la réponse finale. En décomposant le problème en une série d’étapes de raisonnement intermédiaires, le modèle fournit un chemin de solution transparent et justifiable.
Bien que le prompting par chaîne de pensée ait montré des améliorations significatives de performance pour diverses tâches de raisonnement en langage naturel, il a tendance à avoir du mal à généraliser pour résoudre des problèmes plus complexes que les exemples fournis dans les prompts.
Comment le prompting du plus simple au plus complexe permet-il un raisonnement complexe dans les LLM ?
La conception expérimentale de l’article « Least-To-Most Prompting Enables Complex Reasoning in Large Language Models » peut être décomposée en le processus étape par étape suivant :
Identifier l’objectif de la recherche
L’objectif est de permettre aux grands modèles de langage d’effectuer des tâches de raisonnement complexes qui nécessitent de résoudre des problèmes plus difficiles que ceux démontrés dans les exemples d’entraînement.
Sélectionner les tâches
Les chercheurs ont choisi des tâches représentatives de différents types de raisonnement, notamment la manipulation symbolique, la généralisation compositionnelle et le raisonnement mathématique.
Tâche 1 : Manipulation symbolique (tâche de concaténation de la dernière lettre) :
- Problème : Étant donné une liste de mots, la tâche consiste à sortir la concaténation des dernières lettres de chaque mot de la liste.
- Exemple : Pour l’entrée « think, machine, learning », la sortie correcte est « keg ».
- Prompting du plus simple au plus complexe :
- Décomposer le problème : Décomposer la liste en sous-listes séquentielles (« think », « think, machine », « think, machine, learning »).
- Résoudre les sous-problèmes : Concaténer les dernières lettres des mots de chaque sous-liste (« think » donne « k », « machine » donne « e », « learning » donne « g »).
- Combiner les solutions : Utiliser les solutions des sous-problèmes pour construire la réponse finale (« k » + « e » = « ke » et « ke » + « g » = « keg »).
Tâche 2 : Généralisation compositionnelle (benchmark SCAN) :
- Problème : Mapper des commandes en langage naturel à des séquences d’actions. Le défi est de généraliser à des séquences d’actions plus longues que celles vues pendant l’entraînement.
- Exemple : La commande « look opposite right thrice after walk » doit être traduite en la séquence d’actions « TURN RIGHT, TURN RIGHT, LOOK, WALK ».
- Prompting du plus simple au plus complexe :
- Décomposer la commande : Décomposer la commande complexe en parties plus simples (« look opposite right thrice » et « walk »).
- Mapper vers des actions : Traduire chaque partie en actions (« look opposite right thrice » devient « TURN RIGHT, TURN RIGHT, LOOK » répété trois fois, et « walk » reste « WALK »).
- Combiner les actions : Exécuter séquentiellement les actions pour former la séquence finale.
Tâche 3 : Raisonnement mathématique (jeux de données GSM8K et DROP) :
- Problème : Résoudre des problèmes mathématiques en mots pouvant nécessiter plusieurs étapes de raisonnement.
- Exemple : « Elsa a 5 pommes. Anna a 2 pommes de plus qu’Elsa. Combien de pommes ont-elles ensemble ? »
- Prompting du plus simple au plus complexe :
- Décomposer le problème : Identifier les sous-problèmes (Combien de pommes Anna a-t-elle ? Combien de pommes ont-elles ensemble ?).
- Résoudre les sous-problèmes : Calculer les pommes d’Anna (5 + 2 = 7) puis le total (5 + 7 = 12).
- Réponse finale : Conclure qu’Elsa et Anna ont 12 pommes ensemble.
Concevoir les stratégies de prompting
Deux stratégies principales de prompting sont comparées :
- Prompting par chaîne de pensée : Cela consiste à fournir au modèle des exemples qui montrent un processus de raisonnement étape par étape pour résoudre un problème.

- Prompting du plus simple au plus complexe : Cette nouvelle stratégie consiste à décomposer un problème complexe en sous-problèmes plus simples et à les résoudre séquentiellement, en utilisant les solutions des sous-problèmes précédents pour faciliter la solution du suivant.

Créer des exemples de prompts
Pour chaque stratégie de prompting, les chercheurs ont élaboré des exemples montrant comment aborder les tâches. Pour le prompting du plus simple au plus complexe, cela inclut des exemples à la fois de décomposition de problèmes et de résolution de sous-problèmes.
Implémenter le prompting dans le modèle
Le modèle de langage reçoit ensuite ces prompts en entrée. Pour le prompting du plus simple au plus complexe, cela implique deux étapes :
- Étape de décomposition : On demande au modèle de décomposer le problème original en une série de sous-problèmes plus simples.
- Étape de résolution des sous-problèmes : On demande ensuite au modèle de résoudre ces sous-problèmes séquentiellement, en utilisant les réponses des sous-problèmes précédents pour éclairer la solution du suivant.
Construire les ensembles de test
Pour chaque tâche, les chercheurs ont créé des ensembles de test avec différents niveaux de difficulté.
Tâche 1 : Manipulation symbolique (tâche de concaténation de la dernière lettre) :
- L’ensemble de test pour cette tâche impliquait la génération de listes de mots de longueurs variables pour tester la capacité du modèle à concaténer les dernières lettres de chaque mot de la liste.
- Les chercheurs ont utilisé une liste des 10 000 mots anglais les plus courants du Wiktionary, en excluant les mots obscènes, ce qui a donné une liste de 9 694 mots.
- Pour chaque taille de liste souhaitée (allant de 4 à 12 mots), ils ont généré 500 séquences aléatoires de ces mots. Chaque séquence servait d’entrée, et la sortie correspondante était la séquence des dernières lettres des mots.
Tâche 2 : Généralisation compositionnelle (benchmark SCAN) :
- Le benchmark SCAN consiste en des commandes en langage naturel qui doivent être mappées en séquences d’actions. L’ensemble de test met le modèle au défi de généraliser des séquences d’actions plus courtes aux plus longues.
- Les chercheurs ont utilisé les divisions existantes du jeu de données SCAN, en se concentrant particulièrement sur la division par longueur, qui contient des séquences d’actions plus longues que celles de l’ensemble d’entraînement.
- Ils ont également veillé à ce que l’ensemble de test couvre une gamme de commandes pour évaluer la capacité du modèle à traiter différents types de généralisation compositionnelle.
Tâche 3 : Raisonnement mathématique (jeux de données GSM8K et DROP) :
- Pour le raisonnement mathématique, les chercheurs ont utilisé des problèmes en mots du jeu de données GSM8K et du sous-ensemble de raisonnement numérique du jeu de données DROP.
- L’ensemble de test comprenait des problèmes nécessitant un nombre variable d’étapes de raisonnement pour être résolus, permettant aux chercheurs d’évaluer dans quelle mesure le modèle pouvait généraliser des problèmes plus simples aux plus complexes.
- Les problèmes ont été sélectionnés pour représenter une gamme de niveaux de difficulté et pour garantir que certains problèmes nécessitaient plus d’étapes que celles montrées dans les prompts.
En construisant les ensembles de test de cette manière, les chercheurs ont pu évaluer rigoureusement la stratégie de prompting du plus simple au plus complexe et comparer son efficacité par rapport aux techniques de prompting standard sur différentes tâches de raisonnement.
Lancer les expériences et collecter les résultats
Les chercheurs ont mené des expériences en utilisant le modèle GPT-3 (spécifiquement la version code-davinci-002) avec les deux stratégies de prompting. Ils ont enregistré la précision des réponses du modèle sur les ensembles de test.
Analyser les résultats
Les chercheurs ont comparé les performances du modèle en utilisant différentes stratégies de prompting. Ils ont examiné la précision globale et ont également décomposé les résultats par nombre d’étapes de raisonnement nécessaires pour résoudre les problèmes.
Analyse des erreurs
Pour le prompting du plus simple au plus complexe, les chercheurs ont mené une analyse détaillée des erreurs pour comprendre les erreurs courantes, telles que la décomposition incorrecte des problèmes ou la résolution incorrecte des sous-problèmes.
Dans quelle mesure les performances des LLM sont-elles meilleures avec le prompting du plus simple au plus complexe ?
L’article « Least-To-Most Prompting Enables Complex Reasoning in Large Language Models » démontre l’efficacité du prompting du plus simple au plus complexe sur diverses tâches et compare ses performances avec le prompting par chaîne de pensée et les méthodes de prompting standard. Voici un résumé des améliorations de performances pour chaque tâche tel que détaillé dans l’article :
Manipulation symbolique (tâche de concaténation de la dernière lettre) :
Le prompting du plus simple au plus complexe a nettement surpassé le prompting par chaîne de pensée, en particulier lorsque la longueur des listes de mots augmentait.
Pour les listes de longueurs allant de 4 à 12 mots, la précision du prompting du plus simple au plus complexe avec le modèle GPT-3 code-davinci-002 allait de 74,0 % à 94,0 %, ce qui était considérablement plus élevé que la précision du prompting par chaîne de pensée, qui allait de 31,8 % à 84,2 %.

Généralisation compositionnelle (benchmark SCAN) :
Le prompting du plus simple au plus complexe a atteint une précision de 99,7 % dans la condition de division par longueur en utilisant seulement 14 exemplaires, ce qui est un résultat remarquable étant donné que les modèles neuro-symboliques spécialisés entraînés sur l’ensemble du jeu de données de plus de 15 000 exemples ont souvent du mal avec cette tâche.
En revanche, le prompting par chaîne de pensée n’a atteint que 16,2 % de précision avec le même modèle dans la condition de division par longueur.
Raisonnement mathématique (jeux de données GSM8K et DROP) :
Sur le jeu de données GSM8K, le prompting du plus simple au plus complexe a légèrement amélioré le prompting par chaîne de pensée, avec une précision globale de 62,39 % contre 60,87 % pour le prompting par chaîne de pensée.
Cependant, pour les problèmes nécessitant au moins 5 étapes pour être résolus, le prompting du plus simple au plus complexe a montré une amélioration significative, avec une précision de 45,23 % contre 39,07 % pour le prompting par chaîne de pensée.
Sur le jeu de données DROP, le prompting du plus simple au plus complexe a surpassé le prompting par chaîne de pensée avec une large marge, avec des précisions de 82,45 % et 74,77 % pour les sous-ensembles non-football et football respectivement, contre 58,78 % et 59,56 % pour le prompting par chaîne de pensée.
Ces résultats indiquent que le prompting du plus simple au plus complexe est particulièrement efficace dans les tâches qui exigent du modèle de généraliser à partir d’exemples plus simples vers des problèmes plus complexes. La stratégie consistant à décomposer les problèmes complexes en une série de sous-problèmes plus simples et à les résoudre séquentiellement permet au modèle d’atteindre des taux de précision plus élevés sur différentes tâches de raisonnement.
Comment intégrer le prompting du plus simple au plus complexe dans mon propre LLM ?
Basé sur les approches présentées par les auteurs de « Least-To-Most Prompting Enables Complex Reasoning in Large Language Models », nous créons ce guide étape par étape pour vous :
Étape 1 : Obtenir une API LLM
Tout d’abord, vous devez avoir accès à un LLM que vous pouvez utiliser pour votre tâche. Novita AI LLM API fournit aux développeurs de nombreuses options LLM économiques, notamment Llama3–8b, Llama3–70b, Mythomax-13b, etc.

Voici un exemple d’appel API de Chat Completion avec Novita AI LLM API :
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
# Get the Novita AI API Key by referring: https://novita.ai/get-started/Quick_Start.html#_3-create-an-api-key
api_key="<YOUR Novita AI API Key>",
)
model = "Nous-Hermes-2-Mixtral-8x7B-DPO"
stream = True # or False
max_tokens = 512
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": "Act like you are a helpful assistant.",
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Étape 2 : Préparer le prompt pour la décomposition
Créez un ensemble d’exemples de prompts qui montrent comment décomposer un problème complexe en une série de sous-problèmes plus simples. Les exemples doivent montrer la structure de la décomposition, mais pas nécessairement le contenu spécifique des sous-problèmes.
Étape 3 : Préparer le prompt pour la résolution des sous-problèmes
Créez un ensemble d’exemples de prompts qui montrent comment résoudre les sous-problèmes individuels. Ces exemples doivent montrer le processus de construction de la solution étape par étape, en utilisant les résultats des sous-problèmes précédemment résolus.
Étape 4 : Implémenter l’algorithme de prompting du plus simple au plus complexe
Les étapes clés de l’algorithme de prompting du plus simple au plus complexe sont : a. Passer le problème original au prompt de décomposition et obtenir la liste des sous-problèmes. b. Pour chaque sous-problème, construire un prompt qui inclut les solutions des sous-problèmes précédents (le cas échéant) et le sous-problème actuel, et le passer au LLM pour obtenir la solution. c. Combiner les solutions des sous-problèmes pour obtenir la solution finale au problème original.
Étape 5 : Intégrer à votre application
Incorporez l’algorithme de prompting du plus simple au plus complexe dans le flux de travail de votre application. Cela peut impliquer le prétraitement de l’entrée, la construction des prompts, l’appel de l’API LLM et le post-traitement des sorties.
Étape 6 : Évaluer et itérer
Testez votre implémentation sur une variété de tâches et de difficultés de problèmes. Analysez les erreurs et affinez la conception de vos prompts ou l’algorithme de prompting si nécessaire.
Ceci est un exemple de haut niveau créé par LLM, et vous devrez peut-être l’adapter à votre cas d’utilisation et à votre LLM spécifiques.
import openai
# Set the Novita AI API key
openai.api_key = "<YOUR Novita AI API Key>"
openai.base_url = "https://api.novita.ai/v3/openai"
def decomp_prompt(original_problem):
"""
Generates a prompt to decompose the original problem into a series of subproblems.
Args:
original_problem (str): The original problem to be decomposed.
Returns:
str: The prompt for decomposing the problem.
"""
return f"""
Please decompose the following problem into a series of subproblems that can be solved step-by-step:
{original_problem}
Subproblems:
{{{decomp_steps}}}
"""
def solve_prompt(prev_solutions, subproblem):
"""
Generates a prompt to solve a specific subproblem, given the previously solved subproblems.
Args:
prev_solutions (str): The previously solved subproblems.
subproblem (str): The subproblem to be solved.
Returns:
str: The prompt for solving the subproblem.
"""
return f"""
Given the following previously solved subproblems:
{prev_solutions}
Please solve the following subproblem:
{subproblem}
"""
def solve_problem(original_problem):
"""
Solves the original problem using the Least-to-Most Prompting algorithm.
Args:
original_problem (str): The original problem to be solved.
Returns:
list: A list of solutions for the subproblems.
"""
# Decompose the original problem into subproblems
decomp_result = openai.Completion.create(
engine="text-davinci-002",
prompt=decomp_prompt(original_problem),
max_tokens=1024,
n=1,
stop=None,
temperature=0.7,
)
decomp_steps = decomp_result.choices[0].text.strip()
# Solve the subproblems one by one
solutions = []
for step in decomp_steps.split("\
"):
step = step.strip()
if step:
solve_result = openai.Completion.create(
engine="text-davinci-002",
prompt=solve_prompt("\
".join(solutions), step),
max_tokens=1024,
n=1,
stop=None,
temperature=0.7,
)
solutions.append(solve_result.choices[0].text.strip())
return solutions
# Example usage
original_problem = "Solve a complex math problem step-by-step."
solutions = solve_problem(original_problem)
print("\
".join(solutions))
Quelles sont les limites du prompting du plus simple au plus complexe ?
Spécificité de domaine :
Les prompts de décomposition sont souvent adaptés à des domaines spécifiques et peuvent ne pas bien généraliser à travers différents types de problèmes. Un prompt qui fonctionne bien pour les problèmes mathématiques en mots peut ne pas être efficace pour les problèmes de raisonnement de sens commun ou ceux d’autres domaines.
Défi de généralisation intra-domaine :
Même au sein d’un même domaine, il peut être difficile de généraliser le processus de décomposition. Les prompts doivent être soigneusement conçus pour montrer la décomposition correcte afin que le modèle atteigne des performances optimales.
Complexité de la décomposition :
Certains problèmes complexes peuvent nécessiter une compréhension sophistiquée de la manière de les décomposer en sous-problèmes plus simples. Concevoir des prompts qui guident efficacement le modèle à travers ce processus peut être difficile.
Dépendance séquentielle :
Les sous-problèmes générés dans le prompting du plus simple au plus complexe sont souvent dépendants et doivent être résolus dans un ordre spécifique. Cette exigence séquentielle peut rendre le processus de prompting plus complexe par rapport à des sous-problèmes indépendants.
Propagation des erreurs :
Si le modèle fait une erreur dans les premières étapes de la décomposition du problème ou de la résolution des sous-problèmes, cette erreur peut se propager à travers les étapes suivantes, conduisant à une solution finale incorrecte.
Performance spécifique au modèle :
Les performances du prompting du plus simple au plus complexe peuvent varier entre différents modèles ou versions d’un même modèle. Certains modèles peuvent être mieux adaptés pour gérer la nature itérative et récursive de la tâche.
Ingénierie des prompts :
L’efficacité du prompting du plus simple au plus complexe peut dépendre fortement de la qualité de l’ingénierie des prompts. Créer des prompts efficaces qui conduisent à une décomposition et une génération de solutions précises nécessite une attention particulière et une expertise.
Évolutivité :
Bien que le prompting du plus simple au plus complexe puisse être efficace, il peut ne pas s’adapter aussi bien à des problèmes très volumineux ou très complexes en raison de la difficulté accrue à concevoir des prompts appropriés et du potentiel de propagation des erreurs.
Manque d’interaction bidirectionnelle :
Les auteurs suggèrent que le prompting, en général, pourrait ne pas être la méthode optimale pour enseigner des compétences de raisonnement aux LLM car il s’agit d’une forme de communication unidirectionnelle. Une progression plus naturelle pourrait impliquer de faire évoluer le prompting vers des conversations entièrement bidirectionnelles permettant un retour d’information immédiat et un apprentissage plus efficace.
Conclusion
En décomposant les problèmes complexes en étapes plus simples et en les résolvant séquentiellement, les LLM avec le prompting du plus simple au plus complexe améliorent non seulement leur raisonnement, mais démontrent également des performances remarquables sur diverses tâches – de la manipulation symbolique à la généralisation compositionnelle et au raisonnement mathématique.
Cependant, il est important de reconnaître les défis qui accompagnent cette méthode. La spécificité de domaine, les difficultés de généralisation intra-domaine et la complexité de la décomposition peuvent présenter des obstacles. De plus, la dépendance séquentielle des sous-problèmes et la propagation potentielle des erreurs soulignent la nécessité d’une ingénierie minutieuse des prompts et de considérations spécifiques au modèle.
Alors que nous continuons à explorer de nouvelles frontières dans le développement de l’IA, le prompting du plus simple au plus complexe se distingue comme une stratégie clé qui permet aux LLM de relever les défis des tâches de raisonnement complexes avec une précision et une efficacité sans précédent, tout en encourageant la recherche continue sur l’optimisation de son application dans divers domaines de problèmes.
Références
Zhou, D., Schärli, N., Hou, L., Wei, J., Scales, N., Wang, X., Schuurmans, D., Cui, C., Bousquet, O., & Chi, E. (2023). Least-to-Most Prompting Enables Complex Reasoning in Large Language Models. In Proceedings of the International Conference on Learning Representations.
Novita AI est la plateforme cloud tout-en-un qui propulse vos ambitions en IA. Grâce à des API intégrées de manière transparente, l’informatique sans serveur et l’accélération GPU, nous fournissons les outils rentables dont vous avez besoin pour créer et faire évoluer rapidement votre entreprise pilotée par l’IA. Éliminez les problèmes d’infrastructure et commencez gratuitement — Novita AI fait de vos rêves d’IA une réalité.



