
はじめに
言語モデルが人間と同じステップバイステップのアプローチで複雑な問題に取り組むことができたらどうでしょうか?大規模言語モデル(LLM)の分野では、Least-to-Most Prompting の戦略が有望な解決策を提供します。論文「Least-To-Most Prompting Enables Complex Reasoning in Large Language Models」を参考に、この革新的な手法がLLMの推論能力をどのように向上させるかを探ります。複雑なタスクを管理しやすいサブ問題に分解することで、Least-to-Most PromptingはLLMを単純なものから複雑なものへと段階的に導きます。
Least-to-Most Promptingとは何か?
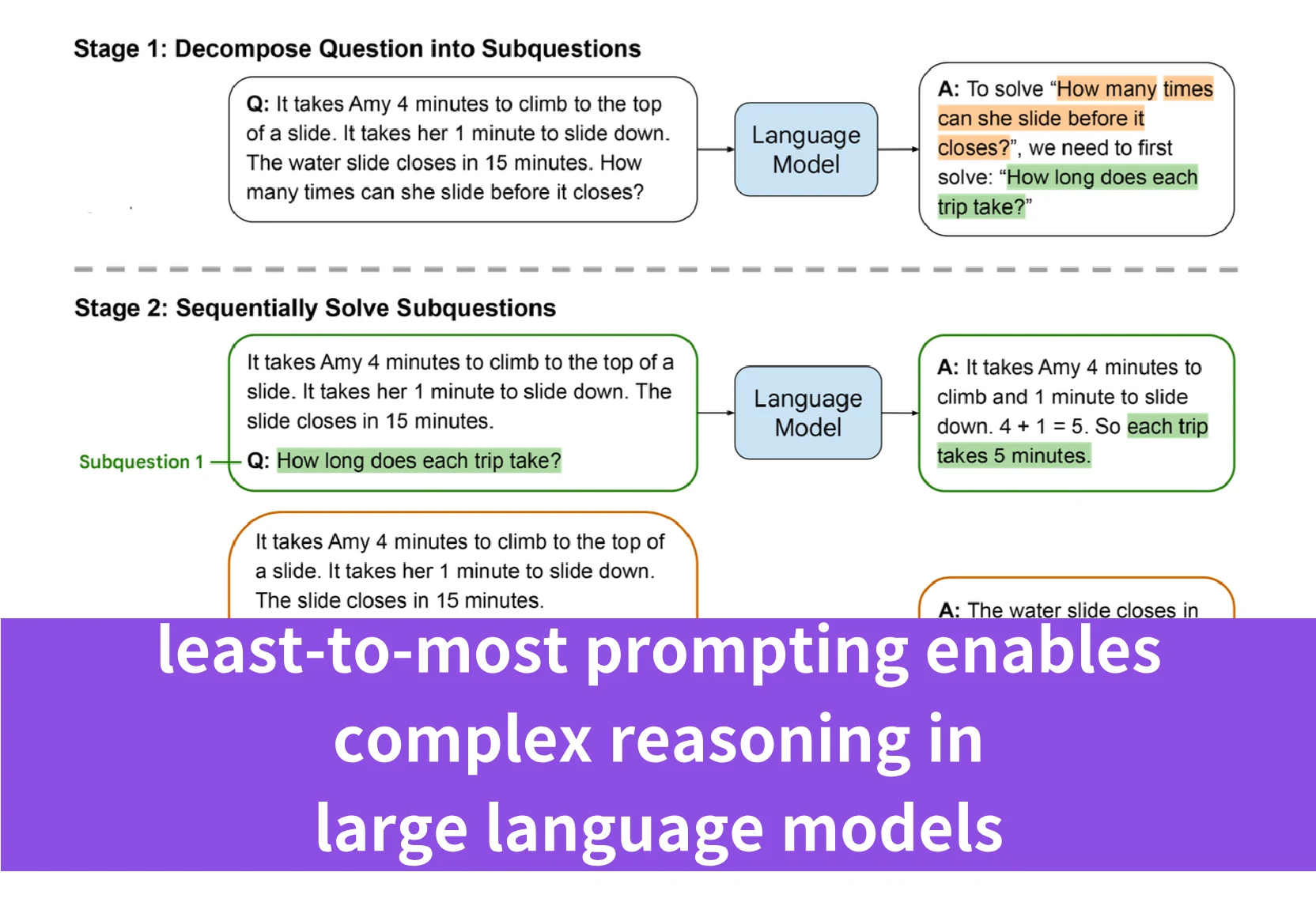
Least-to-Most Promptingは、論文「Least-To-Most Prompting Enables Complex Reasoning in Large Language Models」で導入された、大規模言語モデル(LLM)の推論能力を強化する革新的な戦略です。この手法は、複雑な問題をより簡単で管理しやすい一連のサブ問題に分解することで、LLMが複雑な問題に取り組むのを助けるように設計されています。このプロセスは主に2つの段階を含みます:

- 分解(Decomposition): 複雑な問題を、より簡単なサブ問題のリストに分解します。この段階では、分解プロセスを示す定数例と、分解が必要な特定の質問を続けて提示します。
- サブ問題解決(Subproblem Solving): 次に、モデルはこれらのサブ問題を順番に解決するよう促されます。各サブ問題の解決は、以前に解決されたサブ問題の回答によって促進されます。この段階には、サブ問題の解決方法の例、以前に回答されたサブ質問とその解決策のリスト、および次に取り組む質問が含まれます。
プロンプトは、問題の最も単純な側面から最も複雑な側面へと progressive sequence (プログレッシブ・シーケンス)を通してモデルを導くように構築されています。これが「least-to-most(最小から最大へ)」という名前の由来です。
なぜLeast-to-Most Promptingが必要なのか?
Least-to-Most Promptingの必要性は、既存のプロンプト手法、特に chain-of-thought prompting に観察される限界から生じています。
Chain-of-Thought Prompting は、人間が問題を考えるように、大規模言語モデルに推論プロセスをステップバイステップで明確に表現させる手法です。この方法では、モデルが質問理解から最終回答に至るまでの各論理ステップを明示的に述べます。問題を一連の中間推論ステップに分解することで、モデルは透明で正当化可能な解決経路を提供します。
Chain-of-Thought Promptingは様々な自然言語推論タスクで顕著な性能向上を示しましたが、プロンプトに示された例よりも複雑な問題を解く際に一般化が難しい傾向があります。
Least-to-Most PromptingはどのようにLLMの複雑な推論を可能にするのか?
論文「Least-to-Most Prompting Enables Complex Reasoning in Large Language Models」の実験設計は、以下のステップバイステップのプロセスに分解できます:
研究目標の特定
目標は、大規模言語モデルがトレーニング例で示されたものよりも困難な問題を解く必要がある複雑な推論タスクを実行できるようにすることです。
タスクの選択
研究者は、記号操作、構成的一般化、数学的推論など、様々な推論タイプを代表するタスクを選択しました。
タスク1: 記号操作(最後の文字連結タスク):
- 問題: 単語のリストが与えられたら、各単語の最後の文字を連結したものを出力します。
- 例: 入力「think, machine, learning」に対して、正しい出力は「keg」です。
- Least-to-Most Prompting:
- 問題を分解:リストを逐次的なサブリスト(「think」、「think, machine」、「think, machine, learning」)に分解します。
- サブ問題を解決:各サブリストの単語の最後の文字を連結します(「think」→「k」、「machine」→「e」、「learning」→「g」)。
- 解を統合:サブ問題の解を使って最終回答を構築します(「k」+「e」=「ke」、「ke」+「g」=「keg」)。
タスク2: 構成的一般化(SCANベンチマーク):
- 問題: 自然言語のコマンドをアクションシーケンスにマッピングします。課題は、トレーニングで見られたものよりも長いアクションシーケンスに一般化することです。
- 例: コマンド「look opposite right thrice after walk」は、アクションシーケンス「TURN RIGHT, TURN RIGHT, LOOK, WALK」に変換されるべきです。
- Least-to-Most Prompting:
- コマンドを分解:複雑なコマンドをより単純な部分(「look opposite right thrice」と「walk」)に分解します。
- アクションにマッピング:各部分をアクションに変換します(「look opposite right thrice」は「TURN RIGHT, TURN RIGHT, LOOK」を3回繰り返し、「walk」は「WALK」のままです)。
- アクションを統合:アクションを順次実行して最終シーケンスを形成します。
タスク3: 数学的推論(GSM8KおよびDROPデータセット):
- 問題: 複数の推論ステップを必要とする可能性のある数学の文章問題を解きます。
- 例: 「エルサは5つのリンゴを持っています。アンナはエルサより2つ多くのリンゴを持っています。二人合わせて何個のリンゴを持っていますか?」
- Least-to-Most Prompting:
- 問題を分解:サブ問題を特定します(アンナはリンゴを何個持っているか?二人合わせて何個か?)。
- サブ問題を解決:アンナのリンゴ(5+2=7)を計算し、次に合計(5+7=12)を計算します。
- 最終回答:エルサとアンナは合わせて12個のリンゴを持っていると結論づけます。
プロンプト戦略の設計
2つの主要なプロンプト戦略が比較されます:
- Chain-of-Thought Prompting: 問題を解くためのステップバイステップの推論プロセスを示す例をモデルに提供します。

- Least-to-Most Prompting: 複雑な問題をより単純なサブ問題に分解し、以前のサブ問題の解を使って次のサブ問題の解決を促進しながら順次解決する新しい戦略です。

プロンプト例の作成
各プロンプト戦略について、研究者はタスクへのアプローチ方法を示す例を作成しました。Least-to-Most Promptingの場合、問題分解とサブ問題解決の両方の例が含まれます。
モデルへのプロンプト実装
次に、言語モデルにこれらのプロンプトが入力として与えられます。Least-to-Most Promptingの場合、2つの段階があります:
- 分解段階: モデルは元の問題を一連のより単純なサブ問題に分解するように求められます。
- サブ問題解決段階: 次に、モデルはこれらのサブ問題を順次解決し、前のサブ問題の回答を次のサブ問題の解決に利用するように求められます。
テストセットの構築
各タスクについて、研究者は様々な難易度のテストセットを作成しました。
タスク1: 記号操作(最後の文字連結タスク):
- このタスクのテストセットは、単語リストの長さを変えて生成し、リスト内の各単語の最後の文字を連結するモデルの能力をテストしました。
- 研究者は、Wiktionaryから一般的な英語単語上位10,000語(卑語を除く)を使用し、9,694語のリストを得ました。
- 各リストサイズ(4〜12語)に対して、500のランダムな単語シーケンスを生成しました。各シーケンスが入力となり、対応する出力は単語の最後の文字のシーケンスです。
タスク2: 構成的一般化(SCANベンチマーク):
- SCANベンチマークは、アクションシーケンスにマッピングする必要がある自然言語コマンドで構成されています。テストセットは、モデルがより短いアクションシーケンスからより長いものに一般化する能力に挑戦します。
- 研究者はSCANデータセットの既存の分割を使用し、特にトレーニングセットよりも長いアクションシーケンスを含む長さ分割に焦点を当てました。
- また、テストセットが様々なコマンドをカバーし、モデルが異なるタイプの構成的一般化を処理できる能力を評価できるようにしました。
タスク3: 数学的推論(GSM8KおよびDROPデータセット):
- 数学的推論では、GSM8Kデータセットの文章問題とDROPデータセットの数値推論サブセットを使用しました。
- テストセットには、解くために様々な数の推論ステップを必要とする問題が含まれており、研究者はモデルがより単純な問題からより複雑な問題へどの程度一般化できるかを評価できました。
- 問題は難易度の範囲を表し、いくつかの問題がプロンプトで示されたものよりも多くのステップを必要とすることを確実にするために選択されました。
このようにテストセットを構築することで、研究者はLeast-to-Most Prompting戦略を厳密に評価し、標準的なプロンプト手法と比較して、様々な推論タスクでの有効性を比較することができました。
実験の実行と結果の収集
研究者はGPT-3モデル(具体的にはcode-davinci-002バージョン)を使用して、両方のプロンプト戦略で実験を実行しました。テストセットに対するモデルの応答の正確性を記録しました。
結果の分析
研究者は異なるプロンプト戦略を使用したモデルのパフォーマンスを比較しました。全体の正確性を調べ、さらに問題解決に必要な推論ステップ数で結果を分類しました。
エラー分析
Least-to-Most Promptingについて、研究者は詳細なエラー分析を実施し、問題の誤った分解やサブ問題の誤った解決など、一般的な間違いを理解しました。
Least-to-Most PromptingによるLLMのパフォーマンスはどの程度向上するのか?
論文「Least-To-Most Prompting Enables Complex Reasoning in Large Language Models」は、様々なタスクにおけるLeast-to-Most Promptingの有効性を示し、そのパフォーマンスをchain-of-thought promptingや標準的なプロンプト手法と比較しています。以下は、論文で詳述されている各タスクのパフォーマンス向上の概要です:
記号操作(最後の文字連結タスク):
Least-to-Most Promptingは、特に単語リストの長さが増加した場合に、Chain-of-Thought Promptingを大幅に上回りました。
単語リストの長さが4〜12語の場合、GPT-3 code-davinci-002モデルを使用したLeast-to-Most Promptingの精度は74.0%〜94.0%の範囲であり、Chain-of-Thought Promptingの精度(31.8%〜84.2%)よりも大幅に高かったです。

構成的一般化(SCANベンチマーク):
Least-to-Most Promptingは、わずか14の例示を用いて、長さ分割条件で99.7%の精度を達成しました。これは、15,000以上の例からなるデータセット全体でトレーニングされた特殊なニューラルシンボリックモデルでさえもこのタスクに苦戦することが多いことを考えると、注目すべき結果です。
対照的に、同じモデルを使用したChain-of-Thought Promptingは、長さ分割条件でわずか16.2%の精度でした。
数学的推論(GSM8KおよびDROPデータセット):
GSM8Kデータセットでは、Least-to-Most PromptingはChain-of-Thought Promptingよりもわずかに改善し、全体的な精度は60.87%(CoT)に対して62.39%でした。
しかし、少なくとも5ステップ必要とする問題については、Least-to-Most Promptingは顕著な改善を示し、精度は39.07%(CoT)に対して45.23%でした。
DROPデータセットでは、Least-to-Most PromptingはChain-of-Thought Promptingを大きな差で上回り、非フットボールサブセットで82.45%、フットボールサブセットで74.77%の精度(CoTはそれぞれ58.78%、59.56%)でした。
これらの結果は、Least-to-Most Promptingが、モデルに単純な例からより複雑な問題への一般化を要求するタスクにおいて特に効果的であることを示しています。複雑な問題を一連のより単純なサブ問題に分解し、それらを順次解決する戦略により、モデルは様々な推論タスクでより高い精度を達成できます。
自分のLLMにLeast-to-Most Promptingを統合するには?
「Least-To-Most Prompting Enables Complex Reasoning in Large Language Models」の著者が提示したアプローチに基づいて、ステップバイステップのガイドを作成しました:
ステップ1: LLM APIを取得する
まず、タスクに使用できるLLMにアクセスする必要があります。Novita AI LLM APIは、Llama3–8b、Llama3–70b、Mythomax-13bなど、多くの費用対効果の高いLLMオプションを開発者に提供します。

以下は、Novita AI LLM APIを使用したチャット補完API呼び出しの例です:
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
# Get the Novita AI API Key by referring: https://novita.ai/get-started/Quick_Start.html#_3-create-an-api-key
api_key="<YOUR Novita AI API Key>",
)
model = "Nous-Hermes-2-Mixtral-8x7B-DPO"
stream = True # or False
max_tokens = 512
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": "Act like you are a helpful assistant.",
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
ステップ2: 分解用プロンプトを準備する
複雑な問題を一連のより単純なサブ問題に分解する方法を示す一連の例プロンプトを作成します。例は分解の構造を示すべきですが、必ずしもサブ問題の具体的な内容を含む必要はありません。
ステップ3: サブ問題解決用プロンプトを準備する
個々のサブ問題を解決する方法を示す一連の例プロンプトを作成します。これらの例は、以前に解決されたサブ問題の結果を使用して、ステップバイステップで解を構築するプロセスを示す必要があります。
ステップ4: Least-to-Most Promptingアルゴリズムを実装する
Least-to-Most Promptingアルゴリズムの主要なステップは次のとおりです: a. 元の問題を分解プロンプトに渡し、サブ問題のリストを取得します。 b. 各サブ問題について、前のサブ問題の解(ある場合)と現在のサブ問題を含むプロンプトを構築し、LLMに渡して解を取得します。 c. サブ問題の解を組み合わせて、元の問題の最終解を取得します。
ステップ5: アプリケーションと統合する
Least-to-Most Promptingアルゴリズムをアプリケーションのワークフローに組み込みます。これには、入力の前処理、プロンプトの構築、LLM APIの呼び出し、出力の後処理が含まれる場合があります。
ステップ6: 評価と反復
様々なタスクと問題の難易度で実装をテストします。エラーを分析し、必要に応じてプロンプト設計やプロンプトアルゴリズムを改良します。
これはLLMによって作成された高レベルの例であり、特定のユースケースとLLMに適応させる必要があるかもしれません。
import openai
# Set the Novita AI API key
openai.api_key = "<YOUR Novita AI API Key>"
openai.base_url = "https://api.novita.ai/v3/openai"
def decomp_prompt(original_problem):
"""
Generates a prompt to decompose the original problem into a series of subproblems.
Args:
original_problem (str): The original problem to be decomposed.
Returns:
str: The prompt for decomposing the problem.
"""
return f"""
Please decompose the following problem into a series of subproblems that can be solved step-by-step:
{original_problem}
Subproblems:
{{{decomp_steps}}}
"""
def solve_prompt(prev_solutions, subproblem):
"""
Generates a prompt to solve a specific subproblem, given the previously solved subproblems.
Args:
prev_solutions (str): The previously solved subproblems.
subproblem (str): The subproblem to be solved.
Returns:
str: The prompt for solving the subproblem.
"""
return f"""
Given the following previously solved subproblems:
{prev_solutions}
Please solve the following subproblem:
{subproblem}
"""
def solve_problem(original_problem):
"""
Solves the original problem using the Least-to-Most Prompting algorithm.
Args:
original_problem (str): The original problem to be solved.
Returns:
list: A list of solutions for the subproblems.
"""
# Decompose the original problem into subproblems
decomp_result = openai.Completion.create(
engine="text-davinci-002",
prompt=decomp_prompt(original_problem),
max_tokens=1024,
n=1,
stop=None,
temperature=0.7,
)
decomp_steps = decomp_result.choices[0].text.strip()
# Solve the subproblems one by one
solutions = []
for step in decomp_steps.split("\
"):
step = step.strip()
if step:
solve_result = openai.Completion.create(
engine="text-davinci-002",
prompt=solve_prompt("\
".join(solutions), step),
max_tokens=1024,
n=1,
stop=None,
temperature=0.7,
)
solutions.append(solve_result.choices[0].text.strip())
return solutions
# Example usage
original_problem = "Solve a complex math problem step-by-step."
solutions = solve_problem(original_problem)
print("\
".join(solutions))
Least-to-Most Promptingの限界は何か?
ドメイン特異性:
分解プロンプトは多くの場合、特定のドメインに合わせて調整されており、異なるタイプの問題にうまく一般化できない可能性があります。数学の文章問題にうまく機能するプロンプトが、常識推論問題や他のドメインの問題には効果的でないかもしれません。
ドメイン内一般化の課題:
同じドメイン内であっても、分解プロセスを一般化することは困難な場合があります。プロンプトは、モデルが最適なパフォーマンスを達成するために正しい分解を示すように注意深く設計する必要があります。
分解の複雑さ:
いくつかの複雑な問題では、それらをより単純なサブ問題に分解する方法について高度な理解が必要になる場合があります。このプロセスを通してモデルを効果的に導くプロンプトを設計することは困難な場合があります。
逐次的依存性:
Least-to-Most Promptingで生成されるサブ問題は多くの場合依存関係があり、特定の順序で解決する必要があります。この逐次的な要件により、プロンプトプロセスは独立したサブ問題と比較してより複雑になる可能性があります。
エラーの伝播:
モデルが問題分解の初期段階またはサブ問題解決でエラーを起こした場合、このエラーは後続のステップに伝播し、誤った最終解につながる可能性があります。
モデル固有のパフォーマンス:
Least-to-Most Promptingのパフォーマンスは、異なるモデルや同じモデルのバージョン間で変わる可能性があります。一部のモデルは、タスクの反復的で再帰的な性質を処理するのに適している場合があります。
プロンプトエンジニアリング:
Least-to-Most Promptingの効果は、プロンプトエンジニアリングの品質に大きく依存する可能性があります。正確な分解と解の生成につながる効果的なプロンプトを作成するには、慎重な考慮と専門知識が必要です。
スケーラビリティ:
Least-to-Most Promptingは効果的ですが、適切なプロンプトの設計がより困難になり、エラーの伝播の可能性が高まるため、非常に大規模または高度に複雑な問題にはうまくスケールしない可能性があります。
双方向対話の欠如:
著者は、一般的にプロンプトは一方向のコミュニケーション形式であるため、LLMに推論スキルを教える最適な方法ではないかもしれないと示唆しています。より自然な発展は、即時フィードバックとより効率的な学習を可能にする完全に双方向の会話へとプロンプトを進化させることかもしれません。
結論
複雑な問題をより単純なステップに分解し、それを順次解決することにより、Least-to-Most Promptingを備えたLLMは、推論能力を向上させるだけでなく、記号操作から構成的一般化、数学的推論に至るまで、様々なタスクで顕著なパフォーマンスを発揮します。
しかし、この方法に伴う課題を認識することも重要です。ドメイン特異性、ドメイン内一般化の困難さ、分解の複雑さは障害となる可能性があります。さらに、サブ問題の逐次的依存性とエラー伝播の可能性は、注意深いプロンプトエンジニアリングとモデル固有の考慮が必要であることを強調しています。
AI開発の新たなフロンティアを探求し続ける中で、Least-to-Most Promptingは、LLMが前例のない精度と効率で複雑な推論タスクの課題を乗り越えることを可能にする極めて重要な戦略として際立っており、同時に様々な問題領域での適用を最適化するための継続的な研究を促進しています。
参考文献
Zhou, D., Schärli, N., Hou, L., Wei, J., Scales, N., Wang, X., Schuurmans, D., Cui, C., Bousquet, O., & Chi, E. (2023). Least-to-Most Prompting Enables Complex Reasoning in Large Language Models. In Proceedings of the International Conference on Learning Representations.
Novita AI は、AIの野心を実現するためのオールインワンのクラウドプラットフォームです。シームレスに統合されたAPI、サーバーレスコンピューティング、GPUアクセラレーションにより、AI駆動のビジネスを迅速に構築・拡大するための費用対効果の高いツールを提供します。インフラストラクチャの悩みを解消し、無料で始めましょう — Novita AI があなたのAIの夢を現実にします。



