

关键亮点
Llama 3.3 70B: Meta 推出的 700 亿参数语言模型,注重性能与效率的平衡。在指令遵循和多语言应用方面表现出色。
DeepSeek R1: DeepSeek AI 开发的推理专注型模型,通过强化学习提升推理能力。在编码相关任务中展现了专家级性能。
核心差异: Llama 3.3 平衡了通用性能与效率,而 DeepSeek R1 则优先考虑高级推理和编码任务。
如果你希望在具体用例中评估 DeepSeek R1 与 Llama 3.3 70B 的表现——注册 Novita AI 后,你将获得 $0.5 的免费额度 以便开始使用!
Meta 的 Llama 3.3 70B 和 DeepSeek AI 的 DeepSeek R1 代表了大语言模型领域的重大突破。这两款模型在开源社区备受关注,各自展现出独特的技术优势和广阔的应用潜力。本文提供全面的技术对比,帮助开发者和研究人员深入理解这些模型的核心优势与局限,从而在实际应用中做出更明智的选择。
模型基础介绍
在开始对比之前,我们先了解每款模型的基本特性。
DeepSeek R1
- 发布日期:2025 年 1 月 21 日
- 模型规模:
- 主要特性:
- 模型规模:671B 参数(每个 token 激活 37B)
- 分词器:增强型分词器,支持自反思标签
- 支持语言:多语言,支持文化适配
- 多模态:仅文本
- 上下文窗口:128K tokens
- 存储格式:支持 Q8/Q5 量化
- 架构:混合专家模型 (MoE) + 强化学习增强训练流程
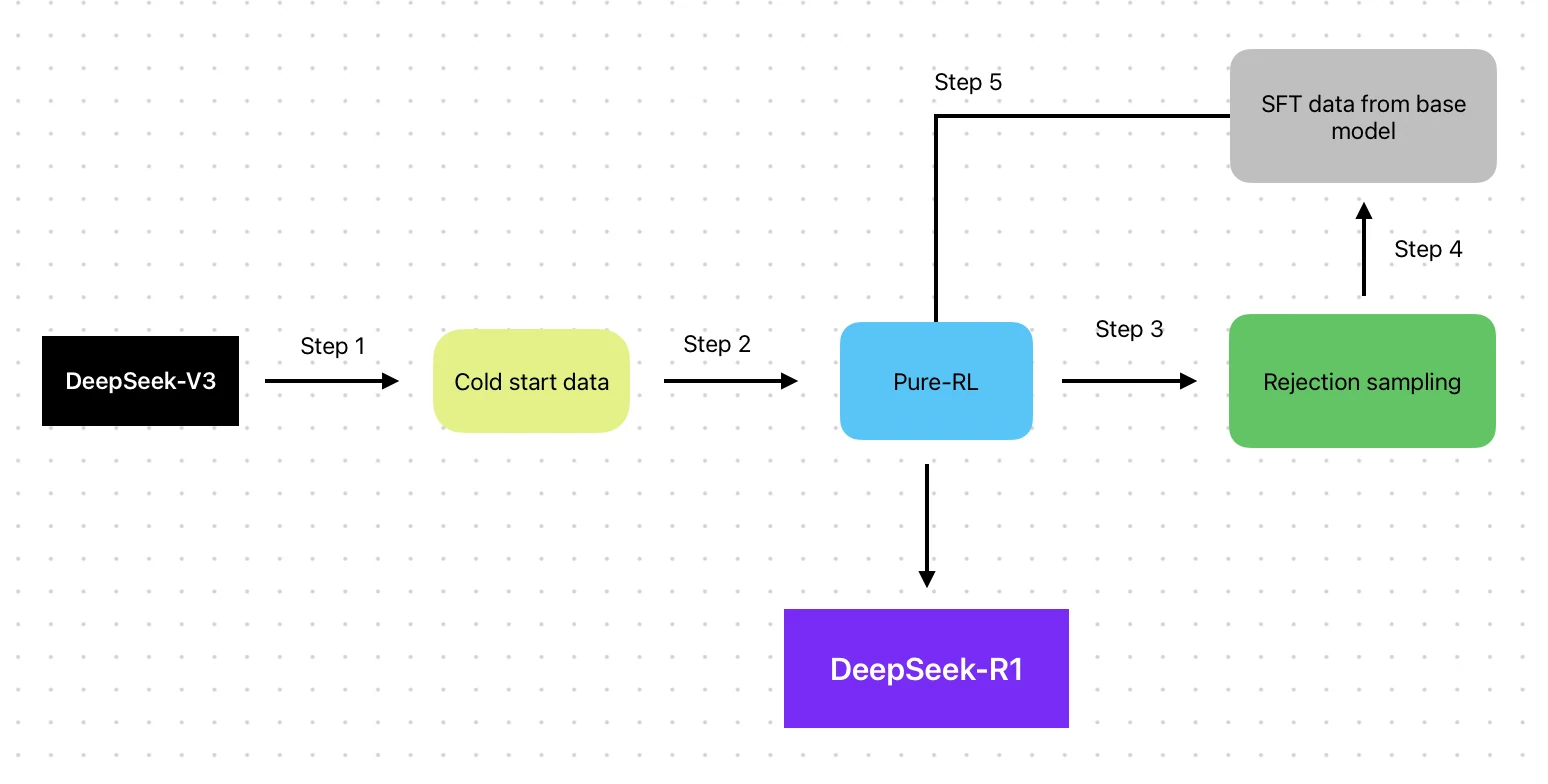
- 训练方法:基于 V3 基础模型,结合 RL 流程(SFT → RL → SFT → RL)
- 训练数据:V3 基础数据 + RL 优化数据
Llama 3.3 70B
- 发布日期:2024 年 12 月 6 日
- 模型规模:
- 主要特性:
- 模型规模:70B 参数
- 支持语言 : 英语、德语、法语、意大利语、葡萄牙语、印地语、西班牙语和泰语。
- 多模态:仅文本
- 上下文窗口:131K tokens
- 架构:分组查询注意力 (GQA),提高处理效率和推理可扩展性
- **训练数据 **:包含 15 万亿 token 的海量数据集
- 训练方法:采用监督微调 (SFT) 和基于人类反馈的强化学习 (RLHF)。
DeepSeek R1 与 Llama 3.3 70B 的主要区别在于它们的强化学习方式。Llama 3.3 70B 使用基于人类反馈的强化学习 (RLHF),引入直接人工评估以对齐人类偏好;而 DeepSeek R1 则采用迭代的机器驱动强化循环(SFT → RL → SFT → RL),较少依赖人工干预。
速度对比
如果你想自行测试,可以在 Novita AI 网站免费试用。
速度对比
数据来源:artificialanalysis
成本对比
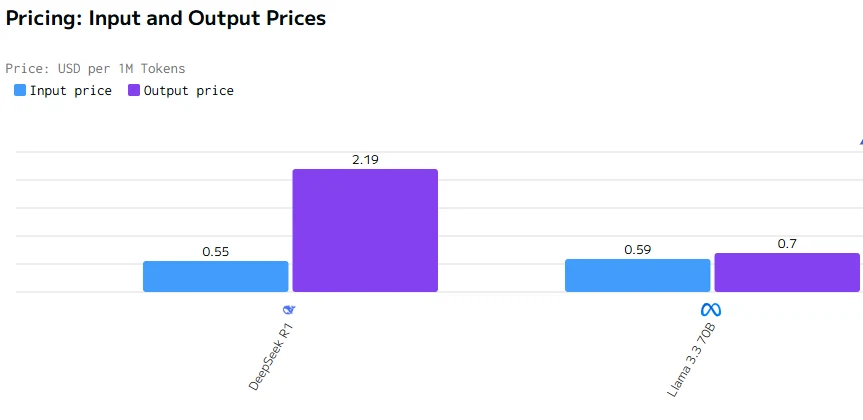
数据来源:artificialanalysis
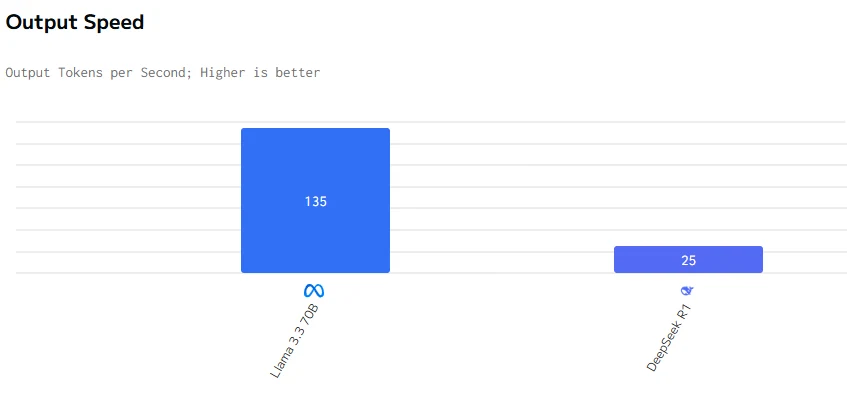
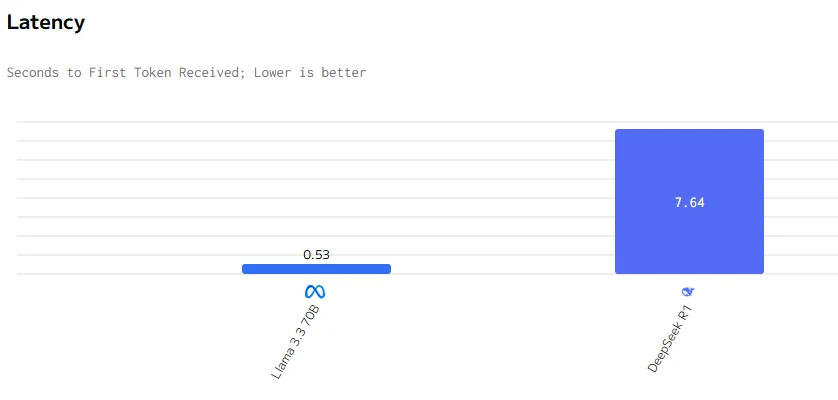
Llama 3.3 70B 在输出速度和延迟方面均优于 DeepSeek R1。DeepSeek R1 的输入输出价格显著高于 Llama 3.3 70B。
不过,Novita AI 推出了 Turbo 版本,吞吐量提升 3 倍,限时 6 折优惠!

基准测试对比
了解每款模型的基本特性后,我们来深入分析它们在不同基准测试中的表现。以下对比有助于说明各自在不同领域的优势。
| 基准测试 | DeepSeek-R1 (%) | Llama 3.3 70B (%) |
|---|---|---|
| LiveCodeBench(编码) | 62 | 29 |
| GPQA Diamond | 71 | 50 |
| MATH-500 | 96 | 77 |
| MMLU-Pro | 84 | 71 |
这些结果表明,DeepSeek R1 采用机器驱动的迭代强化学习方法,可能特别有助于在需要精确推理和结构化问题解决能力的专业技术领域发展更强能力。
如需查看更多对比,可查阅以下文章:
硬件需求
| **模型 ** | ** 参数规模 ** | GPU 配置 |
|---|---|---|
| DeepSeek-R1-Distill-Llama-8B | 4.9B | 1 x NVIDIA RTX 4090(24GB 显存),支持模型分片 |
| DeepSeek-R1-Distill-Qwen-14B | 9.0B | 1 x NVIDIA A100(40GB 显存)或 2 x RTX 4090(24GB 显存),支持张量并行 |
| DeepSeek-R1-Distill-Qwen-32B | 32B | 2 x NVIDIA A100(40GB 显存)或 1 x NVIDIA H100(80GB 显存)或 4 x RTX 4090(24GB 显存),支持张量并行 |
| DeepSeek-R1-Distill-Llama-70B | 70B | 4 x NVIDIA A100(40GB 显存)或 2 x NVIDIA H100(80GB 显存)或 8 x RTX 4090(24GB 显存),重度并行 |
| DeepSeek-R1:671B | 671B(370 亿激活参数) | 16 x NVIDIA A100(40GB 显存)或 8 x NVIDIA H100(80GB 显存),需要配备 InfiniBand 的分布式 GPU 集群 |
| Llama 3.3 70B | 70B | 1 x NVIDIA A100(40GB 显存),大约需要 40GB GPU 显存。本地使用建议至少 24GB 显存,40-48GB 为最佳性能。 |
应用场景
DeepSeek R1
- 长文档分析与理解:凭借 128K token 上下文窗口,可深入分析科学论文、法律文件和技术规范,在长文本中保持优异的信息保留能力。
- 高质量内容创作:生成细腻的创意写作、技术文档和学术内容,在长篇内容中保持卓越的连贯性和逻辑结构。
- 复杂推理任务:擅长需要多步推理、因果分析和领域专业知识的复杂问答场景,尤其在科学和数学领域表现出色。
- 信息综合与转换:在复杂信息压缩与重构方面表现卓越,适用于专业领域的摘要、知识提取和内容改写任务。
Llama 3.3 70B
- Llama 3.3 70B 凭借强大的多语言能力和广泛的知识库,在多种部署场景中表现优异:
- 先进的多语言应用:为八种支持语言的对话系统和客户服务平台提供企业级能力,帮助组织在国际市场部署统一解决方案。
- 开发者生产力工具:为软件开发工作流提供全面的编码辅助,包括代码生成、调试支持和文档创建,但相比专用编码模型性能中等。
- 高级合成数据生成:助力创建多样化的机器学习训练数据集、模拟用户交互及场景规划,保持较强的上下文一致性。
- 跨文化内容策略:支持全球营销活动和国际通信中的高效内容本地化、翻译和文化适配,精准传达微妙的跨文化敏感度。
基于 Novita AI 的获取与部署
Novita AI 是一个 AI 云平台,为开发者提供通过简单 API 轻松部署 AI 模型的能力,同时提供经济可靠的 GPU 云服务用于构建和扩展。
步骤 1:登录并访问模型库
登录您的账户,点击 模型库 按钮。

步骤 2:选择模型
浏览可用选项,选择适合您需求的模型。

步骤 3:开始免费试用
开始免费试用,探索所选模型的能力。
步骤 4:获取 API 密钥
为了通过 API 进行身份验证,我们将为您提供一个新 API 密钥。进入 设置 页面,您可以根据图片指引复制 API 密钥。

步骤 5:安装 API
根据编程语言的包管理器安装 API。

安装后,在开发环境中导入所需库。使用您的 API 密钥初始化 API,即可开始与 Novita AI LLM 交互。以下是 Python 用户使用聊天补全 API 的示例:
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<Your Novita AI API Key>",
)
model = "deepseek/deepseek_r1"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
注册后,Novita AI 会提供 $0.5 的免费额度 供您使用!
如果免费额度用完,您可以付费继续使用。
Llama 3.3 70B 与 DeepSeek R1 通过互补优势面向不同的市场需求。Llama 3.3 70B 提供了平衡的通用性和计算效率,适合主流应用场景;而 DeepSeek R1 则在复杂推理和技术领域展现出卓越能力,尤其在编码密集型环境中表现出色。
常见问题
Llama 3.3 支持哪些语言?
Llama 3.3 全面支持八种语言:英语、法语、德语、印地语、意大利语、葡萄牙语、西班牙语和泰语。
这些模型需要特殊硬件吗?
是的,这两款模型都较大,需要高性能硬件,特别是拥有较大显存的 GPU。
Llama 3.3 是否兼容标准开发环境?
是的,Llama 3.3 专门设计为在常用 GPU 和开发者级硬件配置上高效运行,从而降低了实现的门槛。
Novita AI 是一个一体化云平台,助力实现您的 AI 愿景。集成 API、无服务器、GPU 实例——您所需的高性价比工具。无需基础设施,免费开始,让您的 AI 愿景成为现实。



