

النقاط الرئيسية
Llama 3.3 70B: نموذج لغوي بـ 70 مليار معلمة من Meta، يركز على التوازن بين الأداء والكفاءة. يتميز باتباع التعليمات والتطبيقات متعددة اللغات.
DeepSeek R1: نموذج يركز على التفكير من DeepSeek AI، صُمم لتحسين قدرات التفكير من خلال التعلم المعزز. يُظهر أداءً على مستوى الخبراء في المهام المتعلقة بالبرمجة.
الفروق الأساسية: يوازن Llama 3.3 بين الأداء العام والكفاءة، بينما يعطي DeepSeek R1 الأولوية للتفكير المتقدم ومهام البرمجة.
إذا كنت تبحث عن تقييم DeepSeek R1 وLlama 3.3 70B في حالات الاستخدام الخاصة بك — عند التسجيل، تمنحك Novita AI رصيدًا بقيمة 0.5 دولار للبدء!
يمثل نموذجا Llama 3.3 70B من Meta وDeepSeek R1 من DeepSeek AI إنجازات كبيرة في مجال نماذج اللغة الكبيرة. وقد حظي هذان النموذجان باهتمام كبير في مجتمع المصادر المفتوحة، حيث يُظهر كل منهما مزايا تقنية فريدة وإمكانات تطبيقية. تقدم هذه المقالة مقارنة تقنية شاملة لمساعدة المطورين والباحثين على اكتساب رؤى عميقة حول مواطن القوة والقيود الأساسية لهذه النماذج، مما يمكنهم من اتخاذ قرارات أكثر استنارة للتطبيقات العملية.
مقدمة أساسية عن النموذج
لبدء المقارنة، نفهم أولاً الخصائص الأساسية لكل نموذج.
DeepSeek R1
- تاريخ الإصدار: 21 يناير 2025
- حجم النموذج:
- الميزات الرئيسية:
- حجم النموذج: 671 مليار معلمة (37 مليار نشطة/رمز)
- المُرمِّز (Tokenizer): مُرمِّز محسّن مع علامات تأمل ذاتي
- اللغات المدعومة: متعدد اللغات مع تكيف ثقافي
- متعدد الوسائط: نص فقط
- سياق النافذة: 128 ألف رمز
- صيغ التخزين: دعم التكميم Q8/Q5
- المعمارية: Mixture of Experts (MoE) + خط أنابيب تدريب معزز بالتعلم المعزز
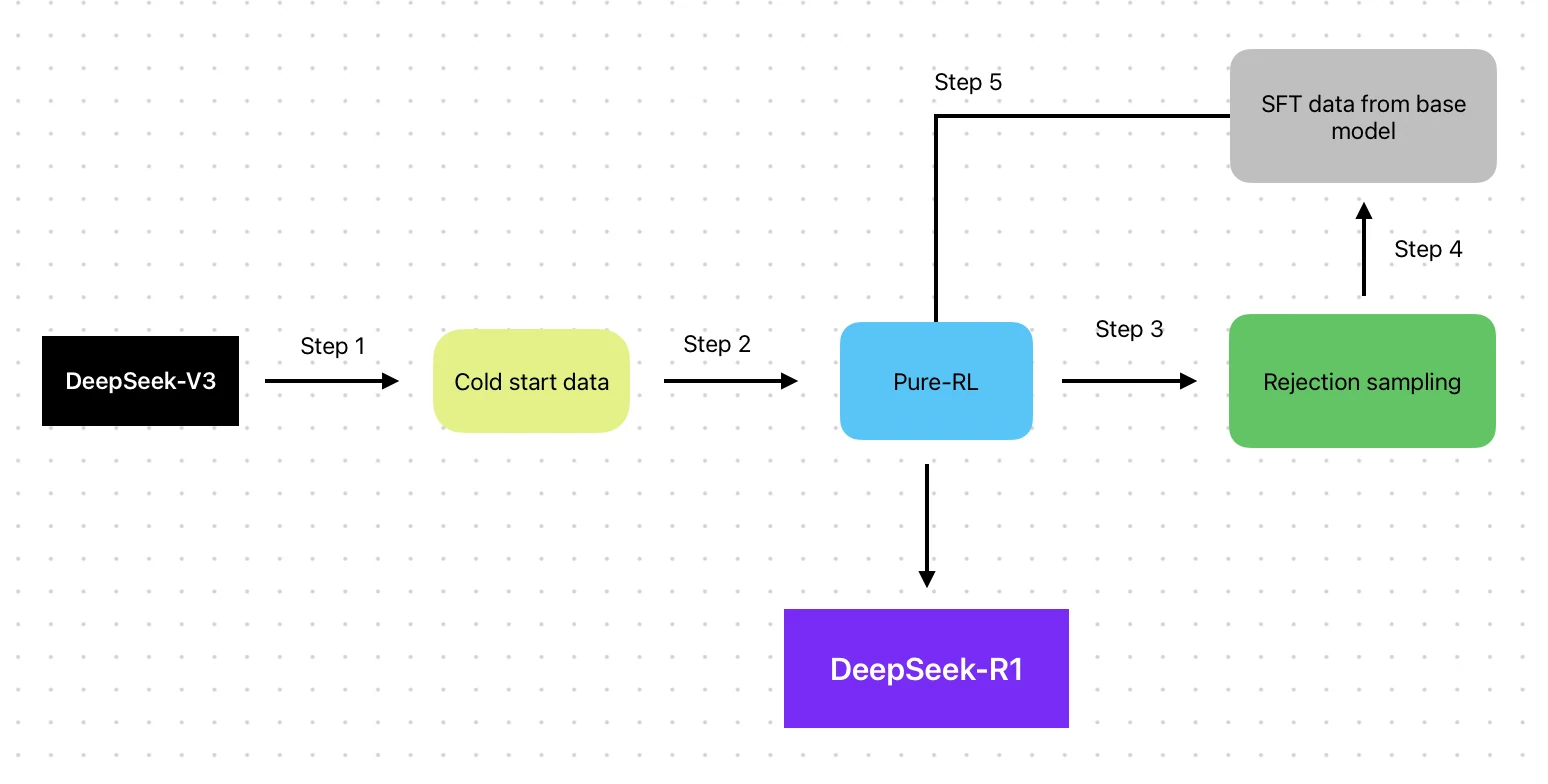
- طريقة التدريب: مبني على قاعدة V3 مع خط أنابيب RL (SFT → RL → SFT → RL)
- بيانات التدريب: قاعدة V3 + بيانات تحسين RL
Llama 3.3 70B
- تاريخ الإصدار: 6 ديسمبر 2024
- حجم النموذج:
- الميزات الرئيسية:
- حجم النموذج: 70 مليار معلمة
- اللغات المدعومة: الإنجليزية، الألمانية، الفرنسية، الإيطالية، البرتغالية، الهندية، الإسبانية، والتايلاندية.
- متعدد الوسائط: نص فقط
- سياق النافذة: 131 ألف رمز
- المعمارية: Grouped-Query Attention (GQA) لتحسين كفاءة المعالجة وقابلية توسيع الاستدلال
- بيانات التدريب: مجموعة بيانات ضخمة تبلغ 15 تريليون رمز
- طريقة التدريب: يستخدم الضبط الدقيق الخاضع للإشراف (SFT) والتعلم المعزز من التغذية الراجعة البشرية (RLHF).
الفرق الرئيسي بين DeepSeek R1 وLlama 3.3 70B يكمن في منهجيات التعلم المعزز. بينما يستخدم Llama 3.3 70B التعلم المعزز من التغذية الراجعة البشرية (RLHF)، الذي يتضمن تقييمًا بشريًا مباشرًا للتوافق مع التفضيلات البشرية، يطبق DeepSeek R1 دورة تعزيز آلية متكررة (SFT → RL → SFT → RL) تعتمد بشكل أقل على التدخل البشري.
مقارنة السرعة
إذا كنت ترغب في اختبار ذلك بنفسك، يمكنك بدء نسخة تجريبية مجانية على موقع Novita AI.
جرب DeepSeek R1 التجريبي الآن!
مقارنة السرعة
المصدر من artificialanalysis
مقارنة التكلفة
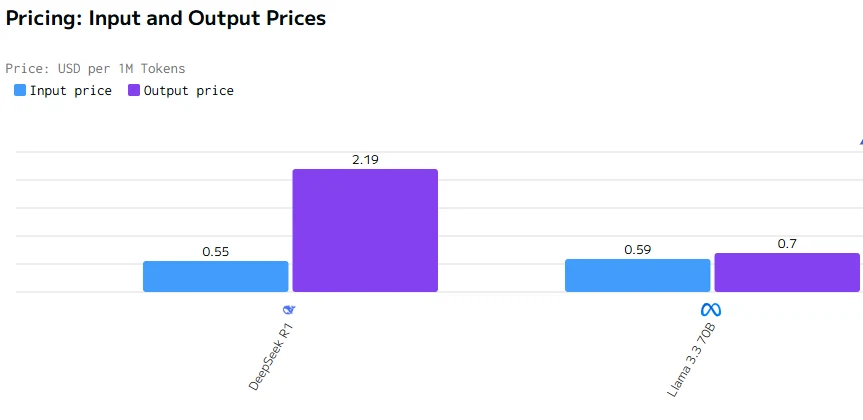
المصدر من artificialanalysis
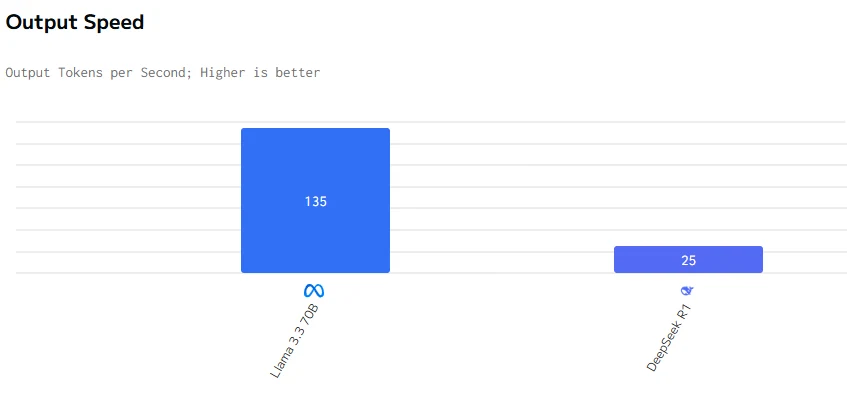
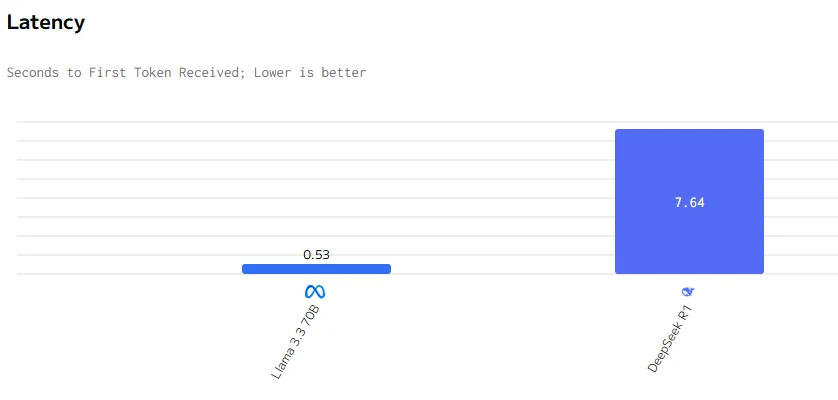
يتفوق Llama 3.3 70B على DeepSeek R1 في سرعة الإخراج وزمن الاستجابة. أسعار الإدخال والإخراج لـ DeepSeek R1 أعلى بكثير من أسعار Llama 3.3 70B.
ومع ذلك، تطلق Novita AI إصدار Turbo مع إنتاجية 3 أضعاف وخصم 60% لفترة محدودة!

مقارنة المعايير
الآن بعد أن حددنا الخصائص الأساسية لكل نموذج، دعنا نتعمق في أدائهم عبر مختلف المعايير. ستساعد هذه المقارنة في توضيح نقاط قوتهم في مجالات مختلفة.
| المعيار | DeepSeek-R1 (%) | Llama 3.3 70B (%) |
|---|---|---|
| LiveCodeBench (برمجة) | 62 | 29 |
| GPQA Diamond | 71 | 50 |
| MATH-500 | 96 | 77 |
| MMLU-Pro | 84 | 71 |
تشير هذه النتائج إلى أن أسلوب التعلم المعزز الآلي المتكرر لـ DeepSeek R1 قد يكون فعالاً بشكل خاص لتطوير قدرات أقوى في المجالات التقنية المتخصصة التي تتطلب تفكيرًا دقيقًا ومهارات حل مشكلات منظمة.
إذا كنت تريد رؤية المزيد من المقارنات، يمكنك الاطلاع على هذه المقالات:
- Deepseek v3 vs Llama 3.3 70b: مهام اللغة مقابل الكود والرياضيات
- DeepSeek R1 vs OpenAI o1: معماريات متميزة لـ GRPO و PPO
متطلبات الأجهزة
| النموذج | حجم المعلمات | تكوين GPU |
|---|---|---|
| DeepSeek-R1-Distill-Llama-8B | 4.9 مليار | 1 x NVIDIA RTX 4090 (24GB VRAM) مع تجزئة النموذج |
| DeepSeek-R1-Distill-Qwen-14B | 9.0 مليار | 1 x NVIDIA A100 (40GB VRAM) أو 2 x RTX 4090 (24GB VRAM) مع توازي الموتر |
| DeepSeek-R1-Distill-Qwen-32B | 32 مليار | 2 x NVIDIA A100 (40GB VRAM) أو 1 x NVIDIA H100 (80GB VRAM) أو 4 x RTX 4090 (24GB VRAM) مع توازي الموتر |
| DeepSeek-R1-Distill-Llama-70B | 70 مليار | 4 x NVIDIA A100 (40GB VRAM) أو 2 x NVIDIA H100 (80GB VRAM) أو 8 x RTX 4090 (24GB VRAM) مع توازي ثقيل |
| DeepSeek-R1:671B | 671 مليار (37 مليار معلمة نشطة) | 16 x NVIDIA A100 (40GB VRAM) أو 8 x NVIDIA H100 (80GB VRAM)، يتطلب مجموعة GPU موزعة مع InfiniBand |
| Llama 3.3 70B | 70 مليار | 1 x NVIDIA A100 (40GB VRAM)، يتطلب حوالي 40 جيجابايت من ذاكرة GPU. يُوصى بحد أدنى 24 جيجابايت VRAM للاستخدام المحلي، بينما 40-48 جيجابايت مثالي للأداء الأمثل. |
التطبيقات وحالات الاستخدام
DeepSeek R1
- تحليل المستندات الطويلة والفهم: يستخدم نافذة السياق البالغة 128 ألف رمز لتحليل متعمق للأوراق العلمية والوثائق القانونية والمواصفات الفنية مع احتفاظ فائق بالمعلومات عبر النصوص الطويلة.
- إنشاء محتوى عالي الجودة: ينتج كتابة إبداعية دقيقة، ووثائق تقنية، ومحتوى أكاديمي مع تماسك استثنائي وبنية منطقية عبر التراكيب الممتدة.
- مهام التفكير المعقدة: يتفوق في سيناريوهات الإجابة على الأسئلة المتطورة التي تتطلب تفكيرًا متعدد الخطوات، وتحليلًا سببيًا، وخبرة في مجالات محددة، خاصة في المجالات العلمية والرياضية.
- تجميع المعلومات وتحويلها: يقدم أداءً متميزًا في تكثيف وإعادة هيكلة المعلومات المعقدة من خلال مهام التلخيص، واستخراج المعرفة، وإعادة صياغة المحتوى عبر المجالات التقنية المتخصصة.
Llama 3.3 70B
- يتفوق Llama 3.3 70B في سيناريوهات النشر المتنوعة التي تستفيد من قدراته القوية متعددة اللغات وقاعدة المعرفة الواسعة:
- التطبيقات متعددة اللغات المتطورة: يشغل وكلاء المحادثة على مستوى المؤسسات وأنظمة دعم العملاء عبر ثماني لغات مدعومة، مما يمكن المؤسسات من نشر حلول موحدة عبر الأسواق الدولية.
- أدوات إنتاجية المطورين: يقدم مساعدة شاملة في البرمجة لسير عمل تطوير البرمجيات، بما في ذلك توليد الكود، ودعم التصحيح، وإنشاء الوثائق، وإن كان بأداء معتدل مقارنة بنماذج البرمجة المتخصصة.
- توليد البيانات الاصطناعية المتقدمة: يسهل إنشاء مجموعات بيانات تدريب متنوعة لتطبيقات التعلم الآلي، والمحاكاة التفاعلية للمستخدمين، وتخطيط السيناريوهات مع تناسق سياقي قوي.
- استراتيجية المحتوى عبر الثقافات: يتيح خدمات الترجمة المحلية للمحتوى، والترجمة، والتكيف الثقافي بكفاءة للحملات التسويقية العالمية والاتصالات الدولية التي تحافظ على حساسيات ثقافية دقيقة.
الوصول والنشر عبر Novita AI
Novita AI هي منصة سحابية للذكاء الاصطناعي تقدم للمطورين طريقة سهلة لنشر نماذج الذكاء الاصطناعي باستخدام واجهة برمجة التطبيقات (API) البسيطة لدينا، مع توفير GPU سحابي ميسور التكلفة وموثوق للبناء والتوسع.
الخطوة 1: تسجيل الدخول والوصول إلى مكتبة النماذج
سجل الدخول إلى حسابك وانقر على زر مكتبة النماذج.

جرب DeepSeek R1 التجريبي الآن!
الخطوة 2: اختر نموذجك
تصفح الخيارات المتاحة وحدد النموذج الذي يناسب احتياجاتك.

الخطوة 3: ابدأ النسخة التجريبية المجانية
ابدأ نسختك التجريبية المجانية لاستكشاف إمكانيات النموذج المحدد.
الخطوة 4: احصل على مفتاح API الخاص بك
للمصادقة مع API، سنقدم لك مفتاح API جديد. ادخل إلى صفحة “الإعدادات”، يمكنك نسخ مفتاح API كما هو موضح في الصورة.

الخطوة 5: تثبيت API
قم بتثبيت API باستخدام مدير الحزم الخاص بلغة البرمجة الخاصة بك.

بعد التثبيت، قم باستيراد المكتبات اللازمة إلى بيئة التطوير الخاصة بك. قم بتهيئة API باستخدام مفتاح API الخاص بك لبدء التفاعل مع Novita AI LLM. هذا مثال لاستخدام API chat completions لمستخدمي Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "deepseek/deepseek_r1"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
عند التسجيل، تمنحك Novita AI رصيدًا بقيمة 0.5 دولار للبدء!
إذا نفد الرصيد المجاني، يمكنك الدفع لمواصلة الاستخدام.
يلبي كل من Llama 3.3 70B وDeepSeek R1 احتياجات سوقية متميزة من خلال نقاط قوة متكاملة. يوفر Llama 3.3 70B تنوعًا متوازنًا وكفاءة حسابية مثالية للتطبيقات السائدة، بينما يُظهر DeepSeek R1 قدرات فائقة في التفكير المعقد والمجالات التقنية، ويتفوق بشكل خاص في البيئات كثيفة البرمجة.
الأسئلة الشائعة
ما هي اللغات التي يدعمها Llama 3.3؟
يدعم Llama 3.3 ثماني لغات بشكل شامل: الإنجليزية، الفرنسية، الألمانية، الهندية، الإيطالية، البرتغالية، الإسبانية، والتايلاندية.
هل تحتاج هذه النماذج إلى أجهزة خاصة؟
نعم، كلا النموذجين كبيران ويتطلبان أجهزة عالية الأداء، خاصة GPUs مع ذاكرة VRAM كبيرة.
هل يتوافق Llama 3.3 مع بيئات التطوير القياسية؟
نعم، تم تصميم Llama 3.3 خصيصًا ليعمل بكفاءة على GPUs المتاحة على نطاق واسع وتكوينات الأجهزة على مستوى المطورين، مما يعزز الوصول لمجموعة أوسع من التطبيقات.
Novita AI هي المنصة السحابية الشاملة التي تمكن طموحاتك في الذكاء الاصطناعي. واجهات API متكاملة، بدون خوادم، GPU Instance — الأدوات الفعالة من حيث التكلفة التي تحتاجها. تخلص من البنية التحتية، ابدأ مجانًا، واجعل رؤيتك للذكاء الاصطناعي حقيقة.



