

主なハイライト
Llama 3.3 70B: Metaによる700億パラメータの言語モデルで、パフォーマンスと効率性のバランスを重視。指示追従と多言語アプリケーションに優れています。
DeepSeek R1: DeepSeek AIによる推論重視モデルで、強化学習を通じて推論能力を向上させる設計。コーディング関連タスクで専門家レベルのパフォーマンスを発揮します。
主な違い: Llama 3.3は汎用パフォーマンスと効率性のバランスを取る一方、DeepSeek R1は高度な推論とコーディングタスクを優先します。
独自のユースケースでDeepSeek R1とLlama 3.3 70Bを評価したい場合 — 登録すると、Novita AI が $0.5 のクレジットを提供します!
MetaのLlama 3.3 70BとDeepSeek AIのDeepSeek R1は、大規模言語モデルの分野における重要なブレークスルーを表しています。これらの2つのモデルはオープンソースコミュニティで大きな注目を集めており、それぞれ独自の技術的優位性と応用可能性を示しています。この記事では包括的な技術比較を提供し、開発者や研究者がこれらのモデルのコアな強みと限界を深く理解し、実用的なアプリケーションにおいてより情報に基づいた判断を下せるようにします。
モデルの基本紹介
比較を始めるにあたり、まず各モデルの基本的な特性を理解しましょう。
DeepSeek R1
- リリース日: 2025年1月21日
- モデルスケール:
- 主な機能:
- モデルサイズ: 671Bパラメータ(1トークンあたり37Bアクティブ)
- トークナイザー: 自己内省タグを備えた強化トークナイザー
- 対応言語: 多言語対応、文化的適応
- マルチモーダル: テキストのみ
- コンテキストウィンドウ: 128Kトークン
- ストレージ形式: Q8/Q5量子化対応
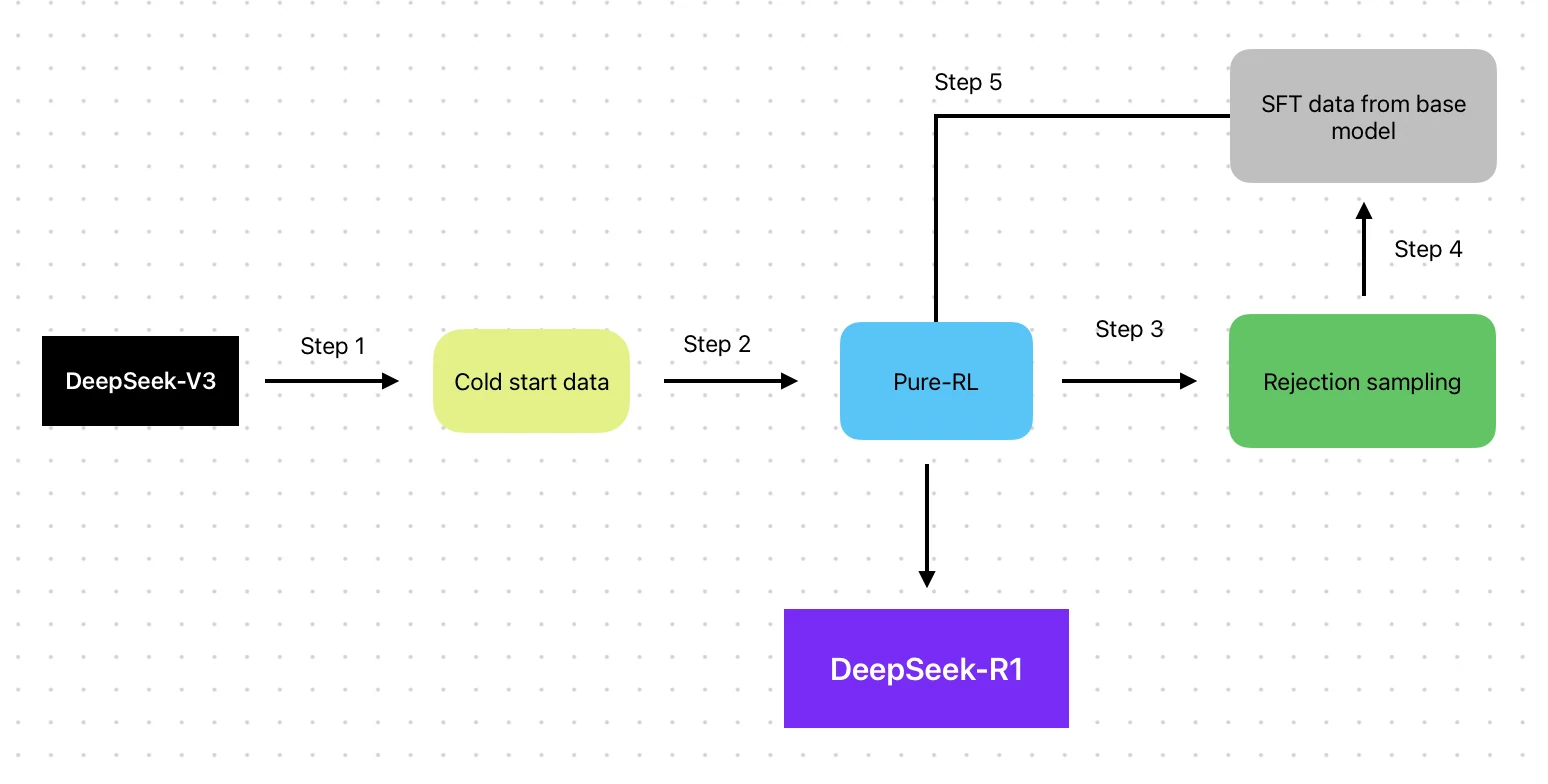
- アーキテクチャ: Mixture of Experts (MoE) + RL強化トレーニングパイプライン
- トレーニング方法: V3ベースにRLパイプライン(SFT → RL → SFT → RL)を適用
- トレーニングデータ: V3ベース + RL最適化データ
Llama 3.3 70B
- リリース日: 2024年12月6日
- モデルスケール:
- 主な機能:
- モデルサイズ: 70Bパラメータ
- **対応言語 : ** 英語、ドイツ語、フランス語、イタリア語、ポルトガル語、ヒンディー語、スペイン語、タイ語
- マルチモーダル: テキストのみ
- コンテキストウィンドウ: 131Kトークン
- アーキテクチャ: Grouped-Query Attention (GQA) により処理効率と推論スケーラビリティを向上
- **トレーニングデータ **: 15兆トークン の大規模データセット
- トレーニング方法: 教師ありファインチューニング (SFT) と人間のフィードバックによる強化学習 (RLHF) を採用
DeepSeek R1とLlama 3.3 70Bの主な違いは、強化学習の方法論にあります。Llama 3.3 70Bは人間のフィードバックによる強化学習 (RLHF) を採用し、直接的な人間の評価を組み込んで人間の好みに合わせるのに対し、DeepSeek R1は反復的な機械駆動の強化学習サイクル (SFT → RL → SFT → RL) を実装し、人間の介入をより少なくしています。
速度比較
自分でテストしたい場合は、Novita AI Webサイトで無料トライアルを開始できます。
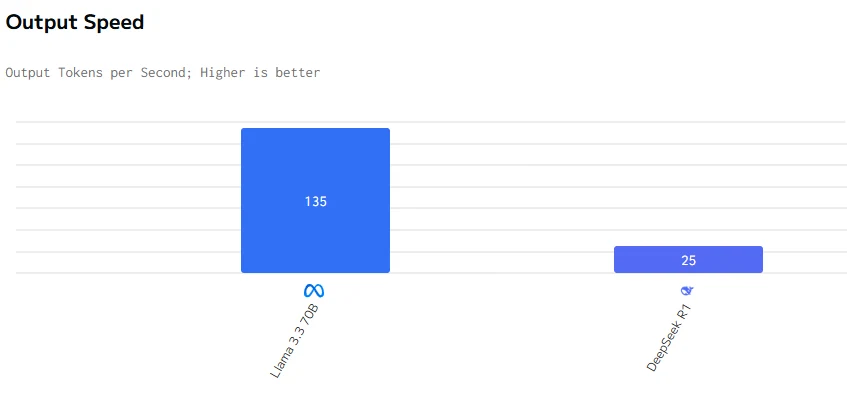
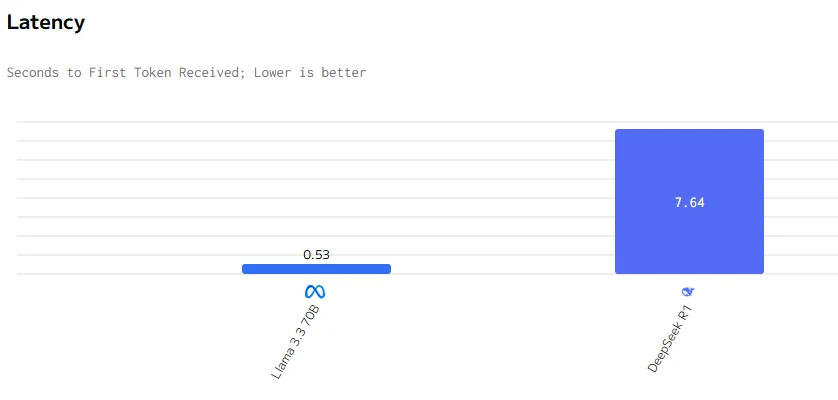
速度比較
コスト比較
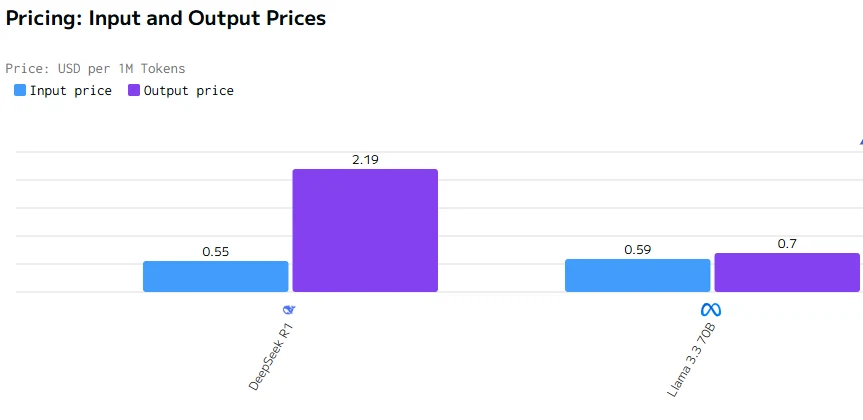
Llama 3.3 70Bは出力速度とレイテンシーにおいてDeepSeek R1を上回っています。DeepSeek R1の入力および出力価格はLlama 3.3 70Bよりも大幅に高くなっています。
ただし、Novita AIは 3倍のスループット ** と期間限定60%割引** のTurboバージョンを提供しています!

ベンチマーク比較
各モデルの基本的な特性を確認したところで、さまざまなベンチマークにおけるパフォーマンスを詳しく見ていきましょう。この比較は、それぞれの強みが異なる分野でどのように現れるかを示すのに役立ちます。
| ベンチマーク | DeepSeek-R1 (%) | Llama 3.3 70B (%) |
|---|---|---|
| LiveCodeBench (コーディング) | 62 | 29 |
| GPQA Diamond | 71 | 50 |
| MATH-500 | 96 | 77 |
| MMLU-Pro | 84 | 71 |
これらの結果は、DeepSeek R1の機械駆動型反復強化学習アプローチが、正確な推論と構造化された問題解決能力を必要とする専門技術領域において、特に強力な能力を開発するのに効果的である可能性を示唆しています。
さらに比較を見たい場合は、以下の記事をご覧ください:
ハードウェア要件
| **モデル ** | ** パラメータサイズ ** | GPU構成 |
|---|---|---|
| DeepSeek-R1-Distill-Llama-8B | 4.9B | 1 x NVIDIA RTX 4090 (24GB VRAM)、モデルシャーディング使用 |
| DeepSeek-R1-Distill-Qwen-14B | 9.0B | 1 x NVIDIA A100 (40GB VRAM) または 2 x RTX 4090 (24GB VRAM)、テンソル並列処理使用 |
| DeepSeek-R1-Distill-Qwen-32B | 32B | 2 x NVIDIA A100 (40GB VRAM) または 1 x NVIDIA H100 (80GB VRAM) または 4 x RTX 4090 (24GB VRAM)、テンソル並列処理使用 |
| DeepSeek-R1-Distill-Llama-70B | 70B | 4 x NVIDIA A100 (40GB VRAM) または 2 x NVIDIA H100 (80GB VRAM) または 8 x RTX 4090 (24GB VRAM)、高度な並列処理 |
| DeepSeek-R1:671B | 671B (370億アクティブパラメータ) | 16 x NVIDIA A100 (40GB VRAM) または 8 x NVIDIA H100 (80GB VRAM)、InfiniBand対応の分散GPUクラスターが必要 |
| Llama 3.3 70B | 70B | 1 x NVIDIA A100 (40GB VRAM)、約40GBのGPU VRAMが必要。ローカル使用には最低24GB VRAM、最適パフォーマンスには40-48 GBを推奨。 |
アプリケーションとユースケース
DeepSeek R1
- 長文書の分析と理解: 128Kトークンのコンテキストウィンドウを活用し、科学論文、法的文書、技術仕様書の詳細な分析を長文にわたって優れた情報保持力で実現。
- 高品質コンテンツ作成: ニュアンスに富んだクリエイティブライティング、技術ドキュメント、学術コンテンツを、長い構成においても卓越した一貫性と論理構造で生成。
- 複雑な推論タスク: 多段階推論、因果分析、ドメイン固有の専門知識を必要とする高度な質問応答シナリオ、特に科学・数学分野で優れる。
- 情報統合と変換: 専門技術分野における要約、知識抽出、コンテンツ再構成タスクにおいて、複雑な情報の圧縮と再構築で優れたパフォーマンスを発揮。
Llama 3.3 70B
- Llama 3.3 70Bは、強力な多言語機能と広範な知識ベースを活用した多様な展開シナリオで優れています:
- 高度な多言語アプリケーション: 8つの対応言語でエンタープライズグレードの会話エージェントとカスタマーサポートシステムを強化し、国際市場全体で統合ソリューションを展開可能に。
- 開発者生産性ツール: コード生成、デバッグサポート、ドキュメント作成を含むソフトウェア開発ワークフロー向けの包括的なコーディング支援を提供。ただし、専門のコーディングモデルと比較すると中程度のパフォーマンス。
- 高度な合成データ生成: 機械学習アプリケーション向けの多様なトレーニングデータセット、シミュレートされたユーザーインタラクション、シナリオプランニングの作成を強力なコンテキスト一貫性で促進。
- クロスカルチャーコンテンツ戦略: グローバルマーケティングキャンペーンや国際コミュニケーション向けに、効率的なコンテンツローカライゼーション、翻訳、文化適応サービスを実現し、微妙な文化的感覚を維持。
Novita AIによるアクセスとデプロイ
Novita AIは、開発者がシンプルなAPIを使用してAIモデルを簡単にデプロイできるAIクラウドプラットフォームであり、構築とスケーリングのための手頃で信頼性の高いGPUクラウドも提供します。
ステップ1: ログインしてモデルライブラリにアクセス
アカウントにログインし、 Model Library ボタンをクリックします。

ステップ2: モデルを選択
利用可能なオプションを参照し、ニーズに合ったモデルを選択します。

ステップ3: 無料トライアルを開始
選択したモデルの機能を探索するために、無料トライアルを開始します。
ステップ4: APIキーを取得
APIで認証するために、新しいAPIキーを提供します。「Settings」ページに移動し、画像に示されているようにAPIキーをコピーします。

ステップ5: APIをインストール
使用するプログラミング言語に応じたパッケージマネージャーを使用してAPIをインストールします。

インストール後、必要なライブラリを開発環境にインポートします。APIキーを使用してAPIを初期化し、Novita AI LLMとのやり取りを開始します。以下はPythonユーザー向けのchat completions APIの使用例です。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "deepseek/deepseek_r1"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
登録すると、Novita AIが $0.5 のクレジットを提供します!
無料クレジットを使い切った場合は、支払いをして引き続き使用できます。
Llama 3.3 70BとDeepSeek R1は、補完的な強みを通じて異なる市場ニーズに対応します。Llama 3.3 70Bは汎用的な汎用性と計算効率のバランスを提供し、主流のアプリケーションに理想的です。一方、DeepSeek R1は複雑な推論と技術領域で優れた能力を示し、特にコーディング集約型環境で卓越しています。
よくある質問
Llama 3.3はどの言語をサポートしていますか?
Llama 3.3は英語、フランス語、ドイツ語、ヒンディー語、イタリア語、ポルトガル語、スペイン語、タイ語の8言語を包括的にサポートします。
これらのモデルには特別なハードウェアが必要ですか?
はい、両モデルとも大規模であり、特に大きなVRAMを備えた高性能GPUが必要です。
Llama 3.3は標準的な開発環境と互換性がありますか?
はい、Llama 3.3は広く利用可能なGPUや開発者向けハードウェア構成で効率的に動作するよう特別に設計されており、より幅広い実装へのアクセス性を高めています。
Novita AI は、AIの野心を実現するオールインワンのクラウドプラットフォームです。統合API、サーバーレス、GPUインスタンス — 必要なコスト効率の高いツール。インフラストラクチャを排除し、無料で開始し、AIのビジョンを現実にしましょう。



