

Points clés
Llama 3.3 70B : Un modèle de langage de 70 milliards de paramètres développé par Meta, mettant l’accent sur un équilibre entre performance et efficacité. Il excelle dans le suivi d’instructions et les applications multilingues.
DeepSeek R1 : Un modèle axé sur le raisonnement conçu par DeepSeek AI, visant à améliorer les capacités de raisonnement grâce à l’apprentissage par renforcement. Il démontre un niveau expert dans les tâches liées au codage.
Différences fondamentales : Llama 3.3 équilibre performance générale et efficacité, tandis que DeepSeek R1 privilégie le raisonnement avancé et les tâches de codage.
Si vous souhaitez évaluer vous-même DeepSeek R1 et Llama 3.3 70B sur vos propres cas d’usage — lors de l’inscription, Novita AI offre un crédit de 0,5 $ pour vous lancer !
Les modèles Llama 3.3 70B de Meta et DeepSeek R1 de DeepSeek AI représentent des avancées significatives dans le domaine des grands modèles de langage. Ces deux modèles ont suscité une attention considérable dans la communauté open-source, chacun démontrant des avantages techniques uniques et un potentiel d’application distinct. Cet article propose une comparaison technique complète pour aider les développeurs et chercheurs à comprendre en profondeur les forces et limites principales de ces modèles, leur permettant ainsi de prendre des décisions plus éclairées pour des applications concrètes.
Présentation de base du modèle
Pour commencer notre comparaison, comprenons d’abord les caractéristiques fondamentales de chaque modèle.
DeepSeek R1
- Date de publication : 21 janvier 2025
- Échelles de modèle :
- Caractéristiques principales :
- Taille du modèle : 671B paramètres (37B actifs/token)
- Tokeniseur : Tokeniseur amélioré avec balises d’auto-réflexion
- Langues supportées : Multilingue avec adaptation culturelle
- Multimodal : Texte uniquement
- Fenêtre de contexte : 128K tokens
- Formats de stockage : Support de quantification Q8/Q5
- Architecture : Mixture of Experts (MoE) + pipeline d’entraînement renforcé par RL
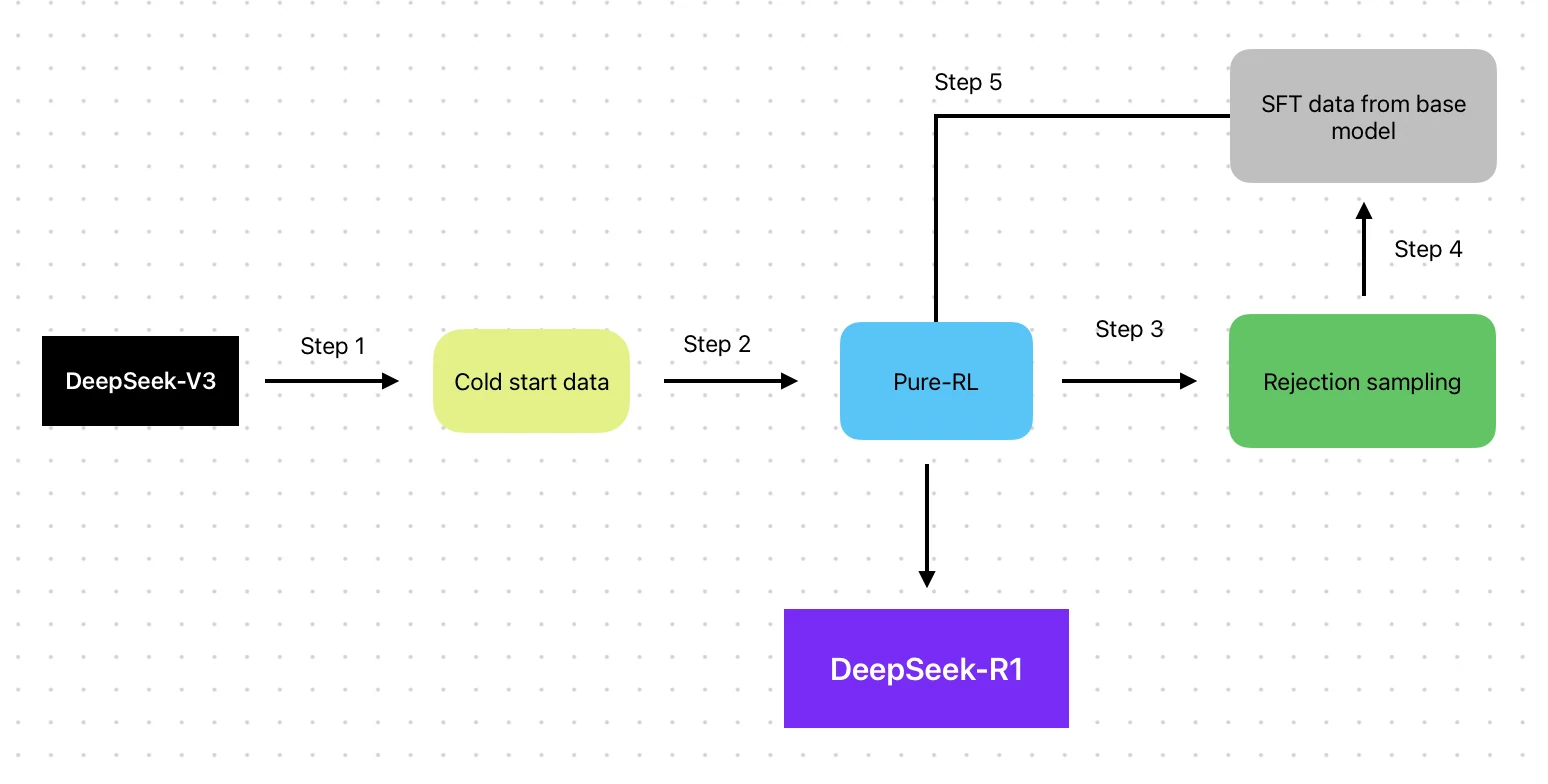
- Méthode d’entraînement : Basée sur V3 avec pipeline RL (SFT → RL → SFT → RL)
- Données d’entraînement : Base V3 + données d’optimisation RL
Llama 3.3 70B
- Date de publication : 6 décembre 2024
- Échelle de modèle :
- Caractéristiques principales :
- Taille du modèle : 70B paramètres
- Langues supportées : Anglais, allemand, français, italien, portugais, hindi, espagnol et thaï.
- Multimodal : Texte uniquement
- Fenêtre de contexte : 131K tokens
- Architecture : Grouped-Query Attention (GQA) pour améliorer l’efficacité du traitement et la scalabilité de l’inférence
- Données d’entraînement : Un ensemble de données massif de 15 billions de tokens
- Méthode d’entraînement : Utilise Supervised Fine-Tuning (SFT) et Reinforcement Learning from Human Feedback (RLHF).
La principale distinction entre DeepSeek R1 et Llama 3.3 70B réside dans leurs méthodologies d’apprentissage par renforcement. Alors que Llama 3.3 70B utilise le Reinforcement Learning from Human Feedback (RLHF), intégrant une évaluation humaine directe pour s’aligner sur les préférences humaines, DeepSeek R1 met en œuvre un cycle de renforcement itératif piloté par machine (SFT → RL → SFT → RL) qui dépend moins de l’intervention humaine.
Comparaison de vitesse
Si vous souhaitez tester vous-même, vous pouvez lancer un essai gratuit sur le site de Novita AI.
Essayez la démo de DeepSeek R1 maintenant !
Comparaison de vitesse
source : artificialanalysis
Comparaison de coût
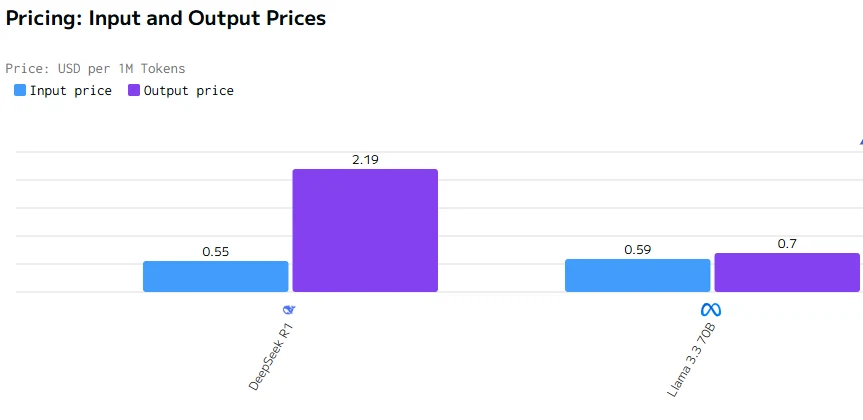
source : artificialanalysis
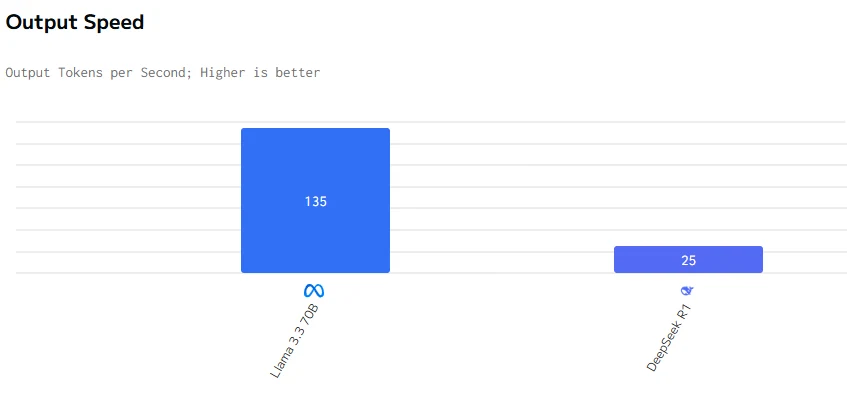
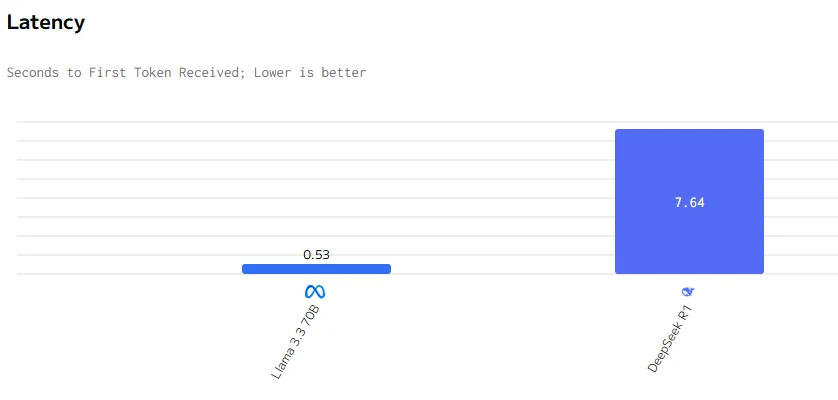
Llama 3.3 70B surpasse DeepSeek R1 en vitesse de sortie et en latence. Les prix d’entrée et de sortie de DeepSeek R1 sont significativement plus élevés que ceux de Llama 3.3 70B.
Cependant, Novita AI propose une version Turbo avec un débit 3x supérieur et une réduction temporaire de 60 % !

Comparaison des benchmarks
Maintenant que nous avons établi les caractéristiques de base de chaque modèle, examinons leurs performances sur différents benchmarks. Cette comparaison aidera à illustrer leurs forces respectives dans divers domaines.
| Benchmark | DeepSeek-R1 (%) | Llama 3.3 70B (%) |
|---|---|---|
| LiveCodeBench (Codage) | 62 | 29 |
| GPQA Diamond | 71 | 50 |
| MATH-500 | 96 | 77 |
| MMLU-Pro | 84 | 71 |
Ces résultats suggèrent que l’approche d’apprentissage par renforcement itératif piloté par machine de DeepSeek R1 pourrait être particulièrement efficace pour développer des capacités renforcées dans des domaines techniques spécialisés nécessitant un raisonnement précis et des compétences structurées de résolution de problèmes.
Si vous souhaitez voir davantage de comparaisons, consultez ces articles :
- Deepseek v3 vs Llama 3.3 70b : Tâches linguistiques vs code et mathématiques
- DeepSeek R1 vs OpenAI o1 : Architectures distinctes de GRPO et PPO
Exigences matérielles
| Modèle | Taille des paramètres | Configuration GPU |
|---|---|---|
| DeepSeek-R1-Distill-Llama-8B | 4,9B | 1 x NVIDIA RTX 4090 (24 Go VRAM) avec partitionnement de modèle |
| DeepSeek-R1-Distill-Qwen-14B | 9,0B | 1 x NVIDIA A100 (40 Go VRAM) ou 2 x RTX 4090 (24 Go VRAM) avec parallélisme de tenseurs |
| DeepSeek-R1-Distill-Qwen-32B | 32B | 2 x NVIDIA A100 (40 Go VRAM) ou 1 x NVIDIA H100 (80 Go VRAM) ou 4 x RTX 4090 (24 Go VRAM) avec parallélisme de tenseurs |
| DeepSeek-R1-Distill-Llama-70B | 70B | 4 x NVIDIA A100 (40 Go VRAM) ou 2 x NVIDIA H100 (80 Go VRAM) ou 8 x RTX 4090 (24 Go VRAM) avec parallélisme lourd |
| DeepSeek-R1:671B | 671B (37 milliards de paramètres actifs) | 16 x NVIDIA A100 (40 Go VRAM) ou 8 x NVIDIA H100 (80 Go VRAM), nécessite un cluster GPU distribué avec InfiniBand |
| Llama 3.3 70B | 70B | 1 x NVIDIA A100 (40 Go VRAM), nécessite environ 40 Go de VRAM GPU. Un minimum de 24 Go VRAM est recommandé pour une utilisation locale, tandis que 40-48 Go est idéal pour des performances optimales. |
Applications et cas d’usage
DeepSeek R1
- Analyse et compréhension de longs documents : Exploite sa fenêtre de contexte de 128K tokens pour une analyse approfondie d’articles scientifiques, de documents juridiques et de spécifications techniques avec une rétention supérieure des informations sur de longs textes.
- Création de contenu de haute qualité : Produit des écrits créatifs nuancés, des documentations techniques et du contenu académique avec une cohérence et une structure logique exceptionnelles tout au long de compositions étendues.
- Tâches de raisonnement complexes : Excelle dans les scénarios de question-réponse sophistiqués nécessitant un raisonnement en plusieurs étapes, une analyse causale et une expertise spécifique au domaine, en particulier dans les domaines scientifiques et mathématiques.
- Synthèse et transformation d’informations : Offre des performances supérieures dans la condensation et la restructuration d’informations complexes via des tâches de résumé, d’extraction de connaissances et de reformulation de contenu dans des domaines techniques spécialisés.
Llama 3.3 70B
- Llama 3.3 70B excelle dans divers scénarios de déploiement qui exploitent ses robustes capacités multilingues et sa vaste base de connaissances :
- Applications multilingues sophistiquées : Alimente des agents conversationnels et des systèmes de support client de niveau professionnel dans huit langues supportées, permettant aux organisations de déployer des solutions unifiées sur les marchés internationaux.
- Outils de productivité pour développeurs : Offre une assistance complète de codage pour les flux de travail de développement logiciel, y compris la génération de code, le support de débogage et la création de documentation, avec des performances modérées par rapport aux modèles de codage spécialisés.
- Génération avancée de données synthétiques : Facilite la création d’ensembles de données d’entraînement variés pour les applications d’apprentissage automatique, les interactions utilisateur simulées et la planification de scénarios avec une forte cohérence contextuelle.
- Stratégie de contenu interculturel : Permet une localisation, une traduction et une adaptation culturelle efficaces du contenu pour les campagnes marketing mondiales et les communications internationales qui maintiennent des sensibilités culturelles nuancées.
Accessibilité et déploiement via Novita AI
Novita AI est une plateforme cloud d’IA qui offre aux développeurs un moyen simple de déployer des modèles d’IA via notre API simple, tout en fournissant également un GPU cloud abordable et fiable pour construire et passer à l’échelle.
Étape 1 : Connectez-vous et accédez à la bibliothèque de modèles
Connectez-vous à votre compte et cliquez sur le bouton Model Library.

Essayez la démo de DeepSeek R1 maintenant !
Étape 2 : Choisissez votre modèle
Parcourez les options disponibles et sélectionnez le modèle qui correspond à vos besoins.

Étape 3 : Commencez votre essai gratuit
Démarrez votre essai gratuit pour explorer les capacités du modèle sélectionné.
Étape 4 : Obtenez votre clé API
Pour vous authentifier avec l’API, nous vous fournirons une nouvelle clé API. En entrant dans la page « Settings », vous pouvez copier la clé API comme indiqué dans l’image.

Étape 5 : Installez l’API
Installez l’API à l’aide du gestionnaire de paquets spécifique à votre langage de programmation.

Après l’installation, importez les bibliothèques nécessaires dans votre environnement de développement. Initialisez l’API avec votre clé API pour commencer à interagir avec Novita AI LLM. Ceci est un exemple d’utilisation de l’API chat completions pour les utilisateurs Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "deepseek/deepseek_r1"
stream = True # ou False
max_tokens = 2048
system_content = """Soyez un assistant utile"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Bonjour !",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Lors de l’inscription, Novita AI offre un crédit de 0,5 $ pour vous lancer !
Si le crédit gratuit est épuisé, vous pouvez payer pour continuer à l’utiliser.
Llama 3.3 70B et DeepSeek R1 répondent à des besoins distincts du marché grâce à des forces complémentaires. Llama 3.3 70B offre une polyvalence équilibrée et une efficacité de calcul idéale pour les applications grand public, tandis que DeepSeek R1 démontre des capacités supérieures dans le raisonnement complexe et les domaines techniques, excellant particulièrement dans les environnements intensifs en codage.
Questions fréquemment posées
Quelles langues Llama 3.3 prend-il en charge ?
Llama 3.3 offre une prise en charge complète de huit langues : anglais, français, allemand, hindi, italien, portugais, espagnol et thaï.
Ces modèles nécessitent-ils du matériel spécial ?
Oui, les deux modèles sont volumineux et nécessitent du matériel haute performance, en particulier des GPU avec une VRAM importante.
Llama 3.3 est-il compatible avec les environnements de développement standard ?
Oui, Llama 3.3 est spécialement conçu pour fonctionner efficacement sur les GPU largement disponibles et les configurations matérielles de niveau développeur, améliorant l’accessibilité pour un plus large éventail d’implémentations.
Novita AI est la plateforme cloud tout-en-un qui alimente vos ambitions en IA. API intégrées, serverless, instance GPU — les outils économiques dont vous avez besoin. Éliminez l’infrastructure, commencez gratuitement et faites de votre vision IA une réalité.



