What is RAG: A Comprehensive Introduction to Retrieval Augmented Generation

Explore the evolution and advancements of Retrieval-Augmented Generation (RAG) systems. Learn how RAG enhances Large Language Models (LLMs) with external knowledge.
Introduction
Retrieval Augmented Generation (RAG) emerges as a promising solution to address challenges inherent in working with Large Language Models (LLMs), including domain knowledge gaps, factuality issues, and hallucination. By integrating external knowledge sources such as databases, RAG enhances LLMs, making them particularly valuable in knowledge-rich environments or domain-specific applications that demand up-to-date knowledge. Unlike other methods, RAG doesn’t require retraining LLMs for specific tasks, which is a significant advantage. Its recent popularity, especially in conversational agents, underscores its relevance.
A recent survey by Gao et al. (2023) provides valuable insights into RAG’s key findings, practical implications, and state-of-the-art approaches. The survey delves into various components of RAG systems, including retrieval, generation, and augmentation techniques, examining their evaluation methodologies, applications, and associated technologies.
What is RAG
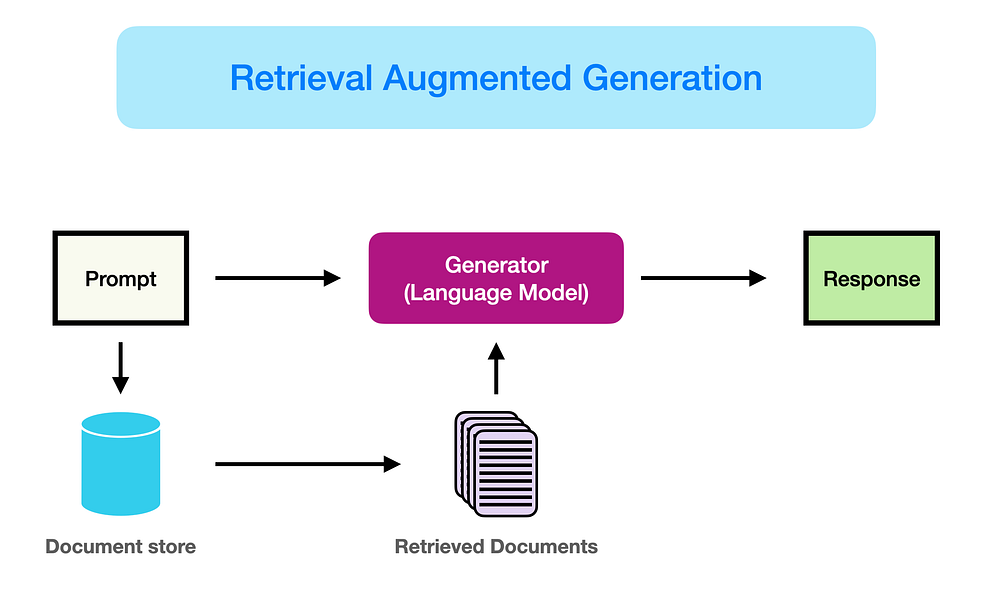
Retrieval-Augmented Generation (RAG) enhances the performance of large language models by incorporating references from authoritative external knowledge bases, complementing the model’s extensive training data. Large Language Models (LLMs) leverage vast datasets and billions of parameters to generate responses for tasks such as question answering, language translation, and text completion. RAG expands upon the capabilities of LLMs by tailoring them to specific domains or internal organizational knowledge bases, all without necessitating model retraining. This approach offers a cost-effective means of enhancing LLM output to ensure its relevance, accuracy, and utility across diverse contexts.
Key Components of RAG
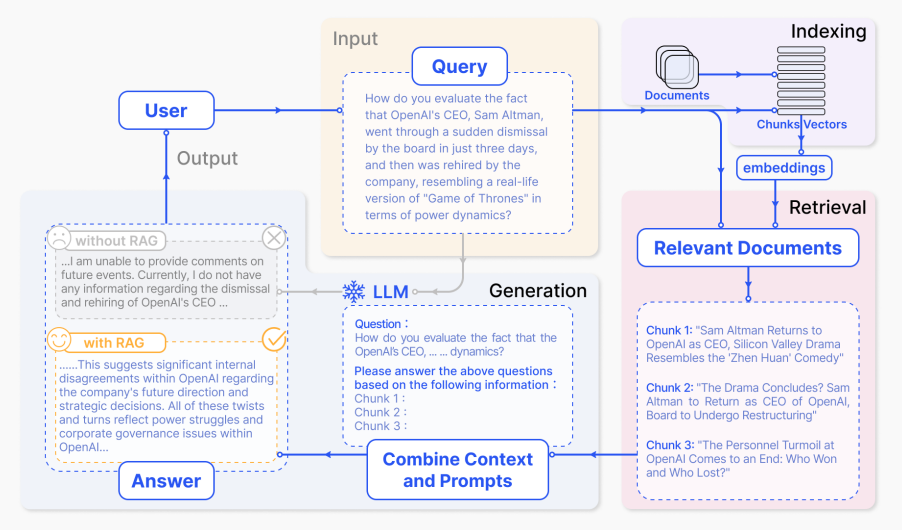
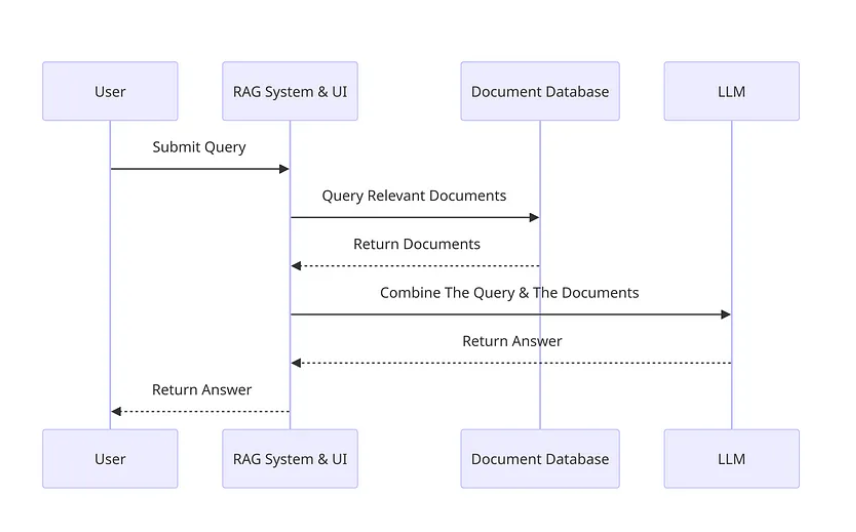
We can break down the process into the following steps/components:
- Input: This refers to the question posed to the LLM system. Without RAG, the LLM directly responds to this question.
- Indexing: When RAG is employed, a set of related documents undergoes indexing. This involves chunking the documents, creating embeddings for these chunks, and then indexing them into a vector store. During inference, the query is similarly embedded.
- Retrieval: Relevant documents are retrieved by comparing the query against the indexed vectors, resulting in a selection of “Relevant Documents”.
- Generation: The retrieved documents are merged with the original prompt to provide additional context. This combined text and prompt are then inputted into the model for response generation, resulting in the final output provided to the user.
In a given example, relying solely on the model without RAG may fail to adequately respond due to a lack of up-to-date knowledge. Conversely, utilizing RAG enables the system to access the necessary information to answer the question accurately.
RAG Paradigms
In recent years, there has been an evolution in RAG systems, progressing from Naive RAG to Advanced RAG and Modular RAG. This advancement has aimed to overcome specific challenges related to performance, cost, and efficiency.
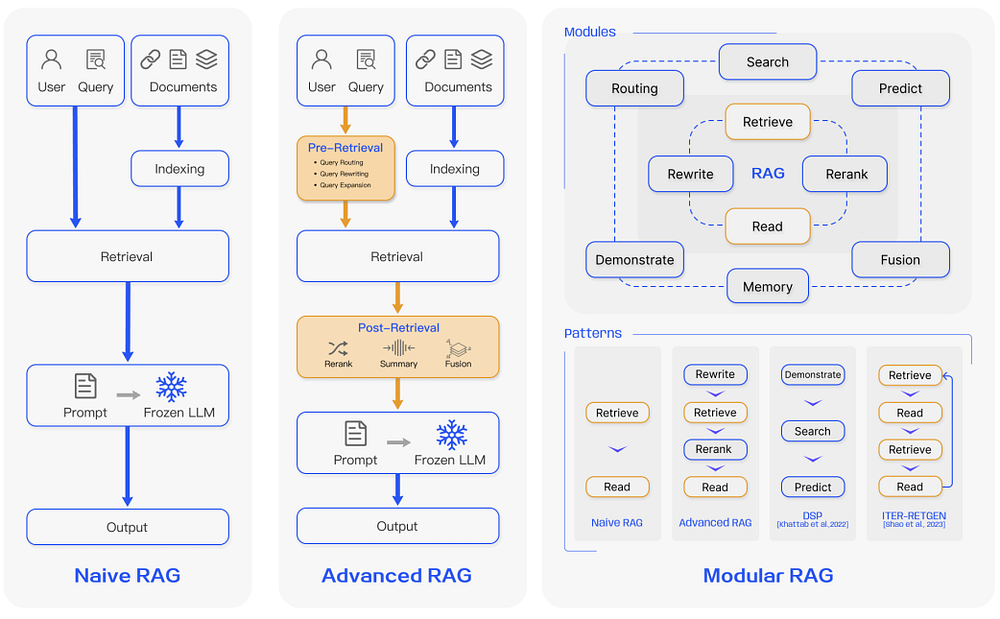
Naive RAG
Naive RAG operates through the conventional process of indexing, retrieval, and generation as outlined earlier. In essence, it utilizes user input to query relevant documents, which are then amalgamated with a prompt and provided to the model for generating a final response. If the application involves multi-turn dialogue interactions, conversational history can be integrated into the prompt.
However, Naive RAG has its limitations, including issues with low precision (resulting in misaligned retrieved chunks) and low recall (failing to retrieve all relevant chunks). There’s also a risk of the LLM being fed outdated information, a primary concern that RAG systems aim to address initially. This can lead to hallucination problems and the generation of poor and inaccurate responses.
Additionally, when augmentation is implemented, concerns may arise regarding redundancy and repetition. Handling multiple retrieved passages involves considerations of ranking and reconciling style and tone. Furthermore, a significant challenge lies in ensuring that the generation task doesn’t excessively rely on augmented information, potentially causing the model to merely reiterate the retrieved content.
Advanced RAG
Advanced RAG offers solutions to the shortcomings observed in Naive RAG, particularly by enhancing the quality of retrieval. This improvement encompasses optimization across the pre-retrieval, retrieval, and post-retrieval processes.
The pre-retrieval phase involves refining data indexing through five key stages: enhancing data granularity, optimizing index structures, adding metadata, alignment optimization, and mixed retrieval. These measures aim to elevate the quality of indexed data.
Further enhancement in the retrieval stage can be achieved by optimizing the embedding model itself. This optimization directly influences the quality of context chunks. Strategies may include fine-tuning embeddings to improve retrieval relevance or employing dynamic embeddings that better capture contextual nuances (e.g., OpenAI’s embeddings-ada-02 model).
Post-retrieval optimization focuses on circumventing context window limitations and managing noisy or distracting information. Re-ranking is a common approach to address these challenges, involving techniques such as relocating relevant context to the edges of the prompt or recalculating semantic similarity between the query and relevant text chunks. Prompt compression techniques may also aid in managing these issues.
Modular RAG
Modular RAG, as its name suggests, enhances functional modules within the retrieval-augmented generation framework. It involves integrating modules such as a search module for similarity retrieval and applying fine-tuning in the retriever. Both Naive RAG and Advanced RAG can be viewed as specific instances of Modular RAG, comprising fixed modules. However, Extended RAG introduces additional modules like search, memory, fusion, routing, predict, and task adapter, each addressing distinct challenges. These modules can be reconfigured to adapt to specific task contexts, offering Modular RAG greater diversity and flexibility. This flexibility enables the addition, replacement, or adjustment of modules based on task requirements.
With the increased flexibility in constructing RAG systems, various optimization techniques have been proposed to refine RAG pipelines:
- Hybrid Search Exploration: This approach combines search techniques such as keyword-based search and semantic search to retrieve relevant and context-rich information, particularly beneficial for addressing diverse query types and information needs.
- Recursive Retrieval and Query Engine: This involves a recursive retrieval process that begins with small semantic chunks and progressively retrieves larger chunks to enrich the context, striking a balance between efficiency and context richness.
- StepBack-prompt: This prompting technique allows LLMs to abstract concepts and principles, guiding reasoning towards more grounded responses. Adopting this technique within a RAG framework enables LLMs to move beyond specific instances and reason more broadly when necessary.
- Sub-Queries: Different query strategies, such as tree queries or sequential querying of chunks, can be employed for various scenarios. For instance, LlamaIndex offers a sub-question query engine, breaking down a query into multiple questions that utilize different relevant data sources.
- Hypothetical Document Embeddings (HyDE): HyDE generates a hypothetical answer to a query, embeds it, and leverages it to retrieve documents similar to the hypothetical answer instead of using the query directly.
Framework of RAG
This section provides a summary of the significant advancements in the components comprising a RAG system: Retrieval, Generation, and Augmentation.
Retrieval
Retrieval within a RAG system involves retrieving highly relevant context from a retriever, which can be enhanced through various means:
Enhancing Semantic Representations:
Improving chunking strategies is crucial for selecting the most appropriate chunking strategy based on the content and application requirements. Different models may excel with different block sizes, such as sentence transformers for single sentences and text-embedding-ada-002 for blocks containing 256 or 512 tokens. Experimentation with different chunking strategies is common to optimize retrieval in a RAG system, considering factors like user question length, application, and token limits.
Fine-tuning embedding models may be necessary for specialized domains to ensure user queries are accurately understood. Embedding models like BGE-large-EN developed by BAAI can be fine-tuned for domain knowledge or specific downstream tasks to optimize retrieval relevance.
Aligning Queries and Documents:
Query rewriting techniques, such as Query2Doc, ITER-RETGEN, and HyDE, focus on refining queries that lack semantic information or contain imprecise phrasing.
Embedding transformation optimizes query embeddings to align them with a latent space more closely related to the task at hand.
Aligning Retriever and LLM:
Fine-tuning retrievers utilizes feedback signals from LLMs to refine retrieval models. Examples include augmentation adapted retriever (AAR), REPLUG, and UPRISE.
Incorporating external adapters, such as PRCA, RECOMP, and PKG, assists in the alignment process between retrievers and LLMs.
Generation
The generator within a RAG system plays a pivotal role in transforming retrieved information into coherent text, ultimately forming the model’s final output. This process often involves diverse input data, necessitating efforts to refine the adaptation of the language model to the input derived from queries and documents. These refinements can be achieved through post-retrieval processes and fine-tuning:
Post-retrieval with Frozen LLM: This approach focuses on enhancing the quality of retrieval results without modifying the LLM itself. Operations such as information compression and result reranking are utilized. Information compression aids in reducing noise, addressing context length restrictions, and enhancing generation effects, while reranking reorders documents to prioritize the most relevant items at the top.
Fine-tuning LLM for RAG: Further optimization or fine-tuning of the generator ensures that the generated text is both natural and effectively leverages the retrieved documents, thereby improving the overall performance of the RAG system.
Augmentation
Augmentation encompasses the process of seamlessly integrating context from retrieved passages with the ongoing generation task. Before delving deeper into the augmentation process, including its stages and data, let’s first establish a taxonomy of the core components of RAG.
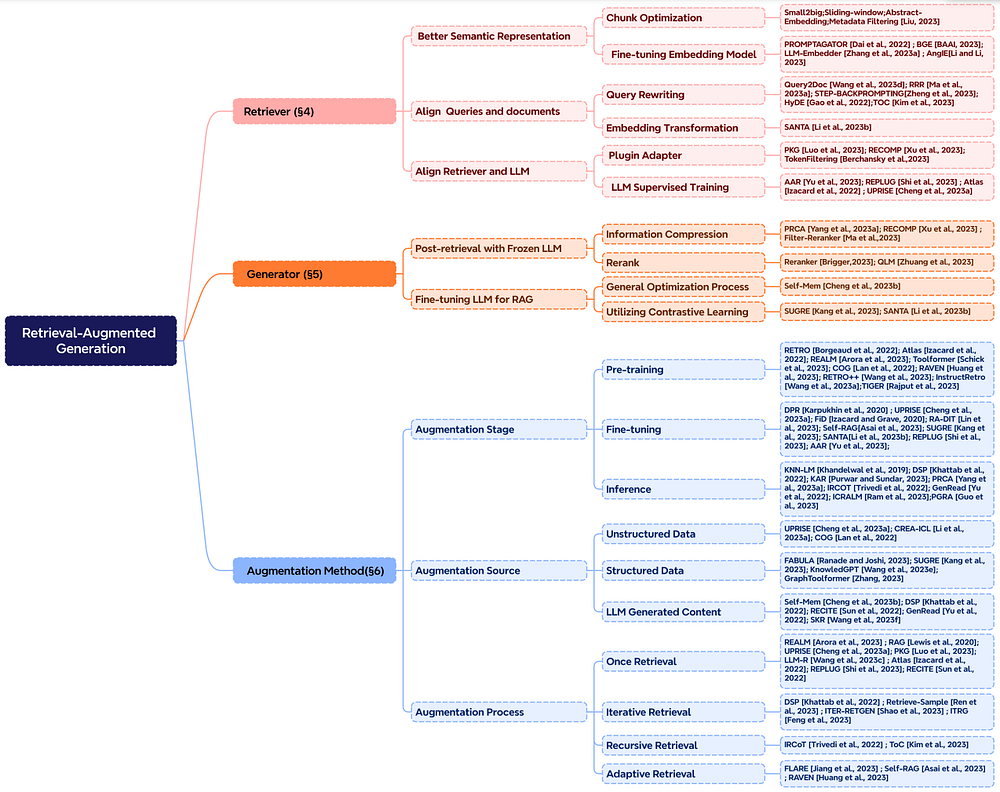
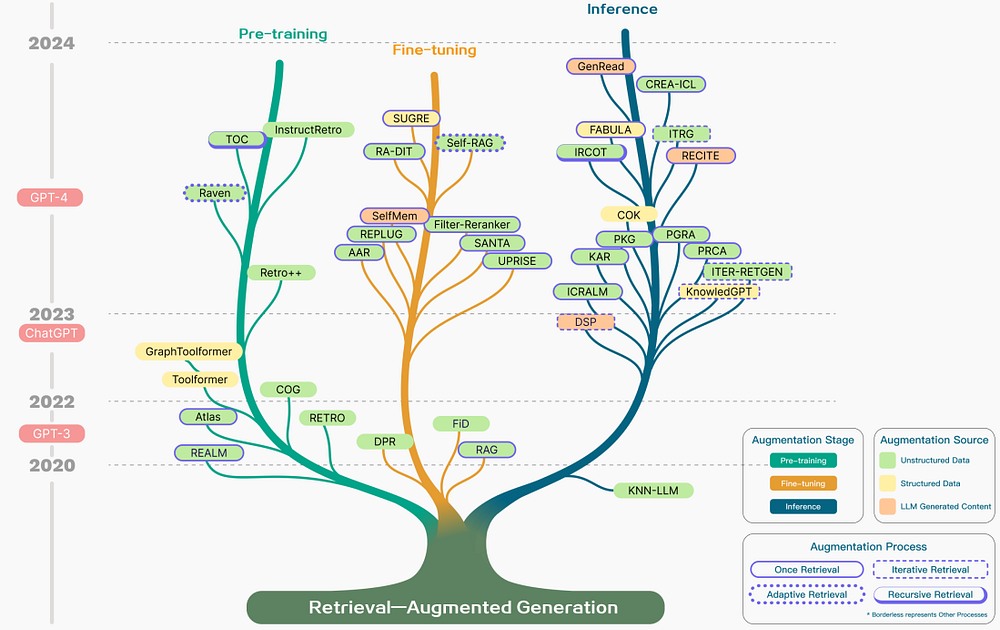
Retrieval augmentation can be applied across various stages, including pre-training, fine-tuning, and inference.
Augmentation Stages: For instance, RETRO exemplifies a system employing retrieval augmentation for large-scale pre-training from scratch by incorporating an additional encoder based on external knowledge. Fine-tuning can also be integrated with RAG to enhance and refine RAG systems. During the inference stage, numerous techniques are employed to effectively integrate retrieved content to fulfill specific task requirements and further refine the RAG process.
Augmentation Source: The effectiveness of a RAG model heavily relies on the selection of augmentation data sources. These sources can be categorized into unstructured, structured, and LLM-generated data.
Augmentation Process: To address complex problems such as multi-step reasoning, various methods have been proposed:
- Iterative retrieval involves performing multiple retrieval cycles to enrich the depth and relevance of information. Notable approaches leveraging this method include RETRO and GAR-meets-RAG.
- Recursive retrieval iteratively builds on the output of one retrieval step as the input to another, enabling deeper exploration of relevant information for complex queries (e.g., academic research and legal case analysis). Notable approaches include IRCoT and Tree of Clarifications.
- Adaptive retrieval customizes the retrieval process to specific demands by identifying optimal moments and content for retrieval. Notable approaches leveraging this method include FLARE and Self-RAG.
The figure below provides a comprehensive representation of RAG research, illustrating various augmentation aspects, including stages, sources, and processes.
RAG Evaluation
Assessing the performance of RAG models across various application scenarios is crucial for understanding and optimizing their effectiveness. Traditionally, the evaluation of RAG systems has focused on measuring their performance in downstream tasks using task-specific metrics like F1 and EM. RaLLe stands out as a notable framework utilized for evaluating retrieval-augmented large language models in knowledge-intensive tasks.
Evaluation targets in RAG encompass both retrieval and generation, aiming to assess the quality of both retrieved context and generated content. Metrics commonly employed to evaluate retrieval quality draw from domains like recommendation systems and information retrieval, including NDCG and Hit Rate. Meanwhile, evaluating generation quality involves assessing aspects such as relevance and harmfulness for unlabeled content or accuracy for labeled content. RAG evaluation methods may encompass both manual and automatic approaches.
The evaluation of a RAG framework typically focuses on three primary quality scores and four abilities. Quality scores encompass measuring context relevance (precision and specificity of retrieved context), answer faithfulness (faithfulness of answers to retrieved context), and answer relevance (relevance of answers to posed questions). Additionally, four abilities help gauge the adaptability and efficiency of a RAG system: noise robustness, negative rejection, information integration, and counterfactual robustness. Below is a summary of metrics utilized to evaluate different facets of a RAG system:
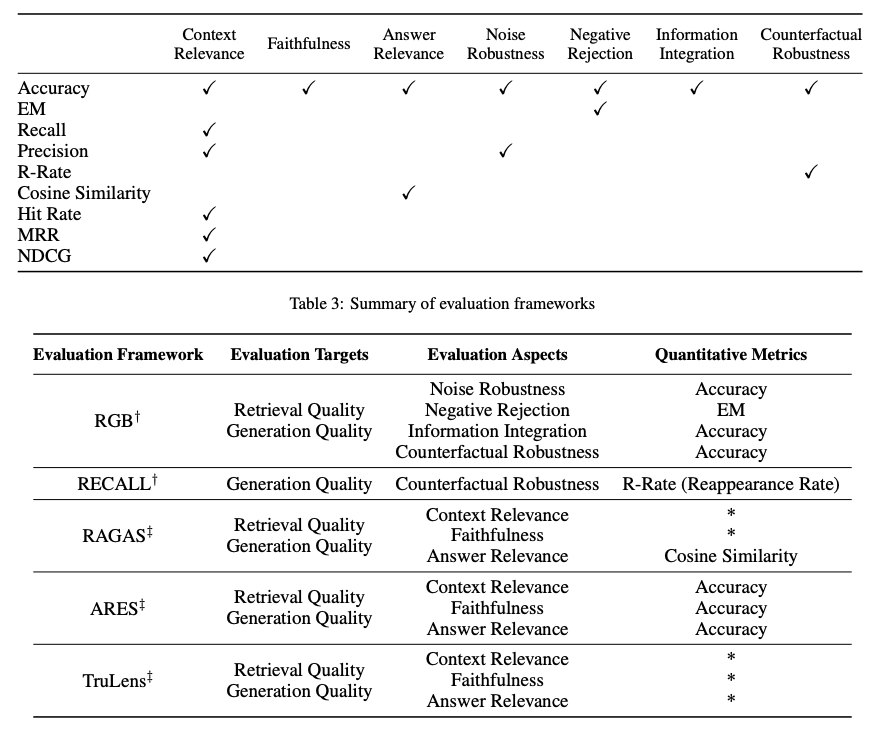
Various benchmarks, such as RGB and RECALL, are employed to assess RAG models. Tools like RAGAS, ARES, and TruLens have been created to automate the evaluation process of RAG systems. Some of these systems utilize LLMs to determine certain quality scores as defined above.
Challenges & Future of RAG
In this overview, we’ve explored various research aspects of RAG and different strategies for enhancing its retrieval, augmentation, and generation components. Here are several challenges highlighted by Gao et al., 2023, as we continue to develop and improve RAG systems:
- Context Length: With LLMs continually expanding context window size, adapting RAG to ensure the capture of highly relevant and crucial context poses challenges.
- Robustness: Addressing counterfactual and adversarial information is crucial for measuring and enhancing the robustness of RAG systems.
- Hybrid Approaches: Ongoing research aims to better understand how to optimize the use of both RAG and fine-tuned models.
- Expanding LLM Roles: There’s a growing interest in increasing the role and capabilities of LLMs to further enhance RAG systems.
- Scaling Laws: Investigating LLM scaling laws and their application to RAG systems remains an area needing further understanding.
- Production-Ready RAG: Developing production-grade RAG systems requires engineering excellence across various domains, including performance, efficiency, data security, and privacy.
- Multimodal RAG: While RAG research has primarily focused on text-based tasks, there’s increasing interest in extending modalities to support a wider range of domains such as image, audio, video, and code.
- Evaluation: Building complex applications with RAG necessitates nuanced metrics and assessment tools for evaluating contextual relevance, creativity, content diversity, factuality, and more. Additionally, there’s a need for improved interpretability research and tools for RAG.
How to integrate RAG with Large Language Models
Implementing Retrieval-Augmented Generation (RAG) with large language models (LLMs) involves several steps, including dataset preparation and integration into the LLM setup. This process enables the LLM to leverage retrieval techniques and generate more accurate and contextually relevant answers.
See how to integrate your LLM with RAG Technic in our blog: Step-by-Step Tutorial on Integrating Retrieval-Augmented Generation (RAG) with Large Language Models
Conclusion
In summary, the evolution of RAG systems has been rapid, marked by the emergence of advanced paradigms that offer customization and enhance performance and utility across various domains. The increasing demand for RAG applications has driven the development of methods to improve its different components. From hybrid methodologies to self-retrieval, a wide array of research areas is currently being explored in modern RAG models.
novita.ai, the one-stop platform for limitless creativity that gives you access to 100+ APIs. From image generation and language processing to audio enhancement and video manipulation,cheap pay-as-you-go , it frees you from GPU maintenance hassles while building your own products. Try it for free.
Recommended reading
What is the difference between LLM and GPT
LLM Leaderboard 2024 Predictions Revealed
Novita AI LLM Inference Engine: the largest throughput and cheapest inference available