

Узнайте, что такое LLM и как большие языковые модели меняют область искусственного интеллекта.
Введение
Большие языковые модели (LLM) за последние годы привлекли значительное внимание благодаря своей способности обрабатывать и понимать естественный язык. Эти алгоритмы глубокого обучения произвели революцию в области обработки естественного языка (NLP) и открыли новые возможности для таких приложений, как чат-боты, сервисы перевода, анализ тональности и создание контента.
LLM разработаны так, чтобы имитировать способность человеческого мозга понимать и генерировать язык. Для этого они используют передовые технологии, такие как трансформерные модели и обучение на огромных наборах данных. Эволюция LLM открыла путь к прогрессу в исследованиях ИИ и может изменить то, как мы взаимодействуем с технологиями.
В этом блоге мы погрузимся в мир больших языковых моделей, разберем их основные компоненты, принципы работы и приложения, которые делают их такими ценными. Мы также рассмотрим влияние LLM на общество, будущие направления их развития, а также ограничения и проблемы, с которыми они сталкиваются. К концу этого руководства вы получите всестороннее понимание LLM и их значения в области обработки естественного языка.
Вот видеоклип о том, что такое большая языковая модель:

Что такое большие языковые модели (LLM)
Большие языковые модели (LLM) находятся на переднем крае исследований и разработок в области обработки естественного языка (NLP). Эти модели способны понимать, переводить, предсказывать и генерировать текст или другие типы контента. LLM — это тип нейронной сети, вычислительной системы, вдохновленной человеческим мозгом, а их процесс обучения включает использование огромных наборов данных для изучения языковых закономерностей и взаимосвязей. LLM стали неотъемлемой частью различных NLP-приложений, обеспечивая прогресс в таких областях, как здравоохранение, финансы и развлечения.

История эволюции языковых моделей
Языковые модели значительно эволюционировали за последние годы благодаря достижениям в области глубокого обучения и генеративного ИИ. Традиционные языковые модели использовали статистические методы и подходы, основанные на правилах, для обработки и генерации текста. Однако появление больших языковых моделей (LLM) ознаменовало смену парадигмы в области обработки естественного языка (NLP).
LLM используют возможности глубокого обучения и нейронных сетей для обработки и понимания естественного языка. Эволюция LLM продвинула область NLP вперед, создав возможности для прогресса в исследованиях ИИ и приложений в различных областях.
Основные компоненты LLM
Большие языковые модели (LLM) состоят из нескольких ключевых компонентов, которые работают вместе для обработки и генерации текста. К этим компонентам относятся архитектура и дизайн модели, обучающие наборы данных, используемые для обучения модели, и нейронная сеть, обеспечивающая функциональность модели.
Архитектура и дизайн
Архитектура и дизайн больших языковых моделей (LLM) играют решающую роль в их функциональности и производительности. LLM часто используют трансформерные модели — тип архитектуры нейронных сетей, который произвел революцию в области обработки естественного языка (NLP). Трансформерные модели используют механизмы внимания для захвата взаимосвязей между словами и генерации предсказаний.
Модель трансформера состоит из кодера и декодера. Кодер обрабатывает входной текст и преобразует его в числовое представление, а декодер генерирует выходное предсказание на основе закодированной информации. Такая архитектура позволяет LLM эффективно обрабатывать и понимать естественный язык, учитывая контекст и взаимосвязи между словами. Механизмы внимания в трансформерных моделях позволяют модели сосредотачиваться на релевантных частях входного текста и генерировать точные предсказания.
Обучающие наборы данных и подготовка
Обучающие наборы данных, используемые в больших языковых моделях (LLM), имеют решающее значение для их производительности и способности обрабатывать естественный язык. Эти наборы данных обширны и разнообразны, они состоят из огромных объемов текстовых данных из таких источников, как Wikipedia, GitHub и других онлайн-платформ. Качество и разнообразие обучающих данных существенно влияют на способность языковой модели изучать закономерности и взаимосвязи в тексте.
Процесс обучения LLM включает неконтролируемое обучение, при котором модель обрабатывает наборы данных без конкретных инструкций. В ходе этого процесса алгоритм искусственного интеллекта (ИИ) LLM изучает значение слов, взаимосвязи между словами и различные лингвистические закономерности. Этот этап предварительного обучения позволяет LLM решать широкий спектр текстовых задач, таких как классификация текста, ответы на вопросы, суммаризация документов и генерация текста. Обучающие наборы данных и подход неконтролируемого обучения необходимы для того, чтобы наделить LLM широким пониманием языка и контекста.
Как работают LLM
Большие языковые модели (LLM) работают через процесс обучения, который позволяет им обрабатывать и генерировать текст. Процесс обучения включает предварительное обучение и тонкую настройку.
Понимание процесса обучения
Предварительное обучение: LLM подвергаются воздействию огромных объемов текстовых данных из различных источников. Этот этап неконтролируемого обучения позволяет модели изучать значения слов, взаимосвязи между словами и языковые закономерности. Масштабный процесс предварительного обучения позволяет LLM развить широкое понимание естественного языка и контекста.
Тонкая настройка: Тонкая настройка оптимизирует производительность LLM для конкретных приложений, таких как перевод, анализ тональности или генерация текста. Этот этап включает обучение модели на размеченных данных или предоставление ей конкретных инструкций для дальнейшего улучшения ее возможностей. Сочетание предварительного обучения и тонкой настройки позволяет LLM выполнять широкий спектр задач обработки естественного языка с высокой точностью.
Декодирование выходных данных: как LLM генерируют текст
Большие языковые модели (LLM) генерируют текст, декодируя входные данные на основе изученных закономерностей и взаимосвязей. Получив входной текст, LLM используют свои обученные знания, чтобы предсказать следующее слово или фразу, которые с наибольшей вероятностью последуют.
Процесс декодирования включает использование трансформерной архитектуры и механизмов внимания внутри LLM. Модель трансформера позволяет LLM учитывать весь контекст предложения или последовательности текста, захватывая взаимосвязи между словами и генерируя точные предсказания. Механизмы внимания позволяют модели сосредотачиваться на релевантных частях входного текста и выбирать наиболее важную информацию для генерации выходных данных.
Декодируя входные данные и используя свои обученные знания, LLM могут генерировать связный и контекстуально релевантный текст. Эта способность делает их незаменимыми для таких задач, как генерация текста, перевод языка и другие приложения обработки естественного языка.

Ключевые технологии, стоящие за LLM
Несколько ключевых технологий способствуют разработке и функционированию больших языковых моделей (LLM). К этим технологиям относятся архитектура трансформера, нейронные сети и алгоритмы машинного обучения.
Трансформерные модели

Трансформерные модели — это ключевая технология, лежащая в основе больших языковых моделей (LLM), позволяющая им обрабатывать и понимать естественный язык. Эти модели произвели революцию в области обработки естественного языка (NLP), представив концепцию механизмов самовнимания, которые захватывают взаимосвязи между словами и генерируют точные предсказания.
Трансформерные модели состоят из кодера и декодера. Кодер обрабатывает входной текст, токенизируя его в числовые представления и захватывая взаимосвязи между словами. Декодер берет закодированную информацию и генерирует выходное предсказание на основе изученных закономерностей и взаимосвязей.
Механизмы внимания внутри трансформерных моделей позволяют им учитывать различные части последовательности или весь контекст предложения, обеспечивая точные предсказания. Эта архитектура и дизайн делают трансформерные модели мощным инструментом в NLP и основой для больших языковых моделей.
Нейронные сети и алгоритмы машинного обучения
Нейронные сети и алгоритмы машинного обучения являются фундаментальными технологиями, лежащими в основе больших языковых моделей (LLM). Нейронные сети — это вычислительные системы, вдохновленные человеческим мозгом, и они играют решающую роль в функциональности LLM. Эти сети состоят из нескольких слоев взаимосвязанных узлов, которые обрабатывают и генерируют текст на основе изученных закономерностей и взаимосвязей.
Алгоритмы машинного обучения управляют процессом обучения и тонкой настройки LLM. Эти алгоритмы позволяют моделям обучаться на огромных наборах данных, распознавать закономерности в текстовых данных и оптимизировать свою производительность для конкретных задач. Техники машинного обучения, такие как неконтролируемое обучение, позволяют LLM обрабатывать обучающие данные без конкретных инструкций, раскрывая значения слов и взаимосвязи между ними.
Сочетание нейронных сетей и алгоритмов машинного обучения дает LLM возможность понимать и генерировать текст с высокой точностью, что делает их ценными инструментами в обработке естественного языка и приложениях ИИ.
Применение больших языковых моделей
Большие языковые модели (LLM) имеют широкий спектр применений в области обработки естественного языка (NLP). LLM используются в таких отраслях, как здравоохранение, финансы, маркетинг и обслуживание клиентов, для улучшения коммуникации и автоматизации процессов. Они обеспечивают разработку чат-ботов, ИИ-ассистентов и других диалоговых интерфейсов. LLM также могут революционизировать создание контента, позволяя генерировать персонализированный и контекстуально релевантный контент.
Задачи обработки естественного языка (NLP)
Большие языковые модели (LLM) преуспевают в различных задачах обработки естественного языка (NLP), таких как анализ тональности, перевод языка и суммаризация текста. Анализ тональности — это процесс определения тональности или мнения, выраженного в куске текста. LLM могут анализировать и классифицировать текст на основе тональности, позволяя компаниям получать информацию об отзывах и настроениях клиентов.

Перевод языка — еще одна важная задача NLP, в которой LLM добились значительных успехов. Эти модели могут переводить текст с одного языка на другой с впечатляющей точностью, улучшая межкультурную коммуникацию и доступность.
Суммаризация текста — это процесс извлечения основных моментов из текста. LLM могут генерировать краткие резюме, которые отражают суть исходного контента, что делает их ценными инструментами для поиска информации и курирования контента.
За пределами текста: LLM в других областях
Хотя большие языковые модели (LLM) в основном используются для задач, связанных с текстом, их возможности выходят за рамки обработки текста. LLM применяются в таких областях, как генерация изображений, распознавание речи и поиск информации.
В генерации изображений LLM могут создавать реалистичные изображения на основе текстовых описаний или подсказок. Эта технология находит применение в таких областях, как компьютерная графика, виртуальная реальность и творческий дизайн.
Распознавание речи — еще одна область, в которой LLM добились успехов. Эти модели могут транскрибировать устную речь в письменный текст, обеспечивая работу таких технологий, как голосовые помощники и сервисы транскрипции.
LLM также используются в поиске информации, помогая пользователям находить релевантную информацию в больших наборах данных или поисковых системах. Понимая контекст и намерение поискового запроса, LLM предоставляют точные и контекстуально релевантные результаты поиска.
Влияние LLM на общество
Большие языковые модели (LLM) могут значительно повлиять на общество различными способами. Их достижения в области исследований ИИ и обработки естественного языка (NLP) открыли новые возможности для приложений в здравоохранении, финансах, развлечениях и других сферах. LLM способны автоматизировать процессы, улучшить коммуникацию и улучшить принятие решений в различных отраслях. Однако их широкое распространение также вызывает этические проблемы и вызовы, такие как проблемы конфиденциальности, предвзятость в данных и выходах модели, а также потенциальные нарушения на рынке труда. Крайне важно учитывать социальное влияние LLM и решать эти проблемы, чтобы обеспечить ответственное использование этой технологии.
Достижения в исследованиях ИИ
Эти модели раздвинули границы возможного в обработке естественного языка (NLP) и генерации языка. LLM, такие как GPT-3 и ChatGPT, продемонстрировали замечательную способность понимать и генерировать человекоподобный текст. Открытая природа LLM также способствовала сотрудничеству и инновациям в сообществе исследователей ИИ. Фундаментальные модели, которые служат основой для многих LLM, предоставили исследователям отправную точку для создания более специализированных моделей. LLM ускорили прогресс в исследованиях ИИ и заложили основу для будущих достижений в этой области.
Этические соображения и вызовы
Эти модели могут усиливать предвзятость, присутствующую в данных, на которых они обучаются, что приводит к предвзятым выходам и укреплению существующего социального неравенства. LLM также могут вызывать проблемы конфиденциальности, поскольку для их обучения требуются огромные объемы данных, что потенциально ставит под угрозу конфиденциальность пользователей. Кроме того, автоматизация задач с помощью LLM может привести к нарушениям на рынке труда и необходимости переквалификации или повышения квалификации работников. Крайне важно решать эти проблемы и обеспечивать ответственное использование LLM, чтобы минимизировать их негативное воздействие и максимизировать пользу для общества.
Будущие направления развития LLM
Большие языковые модели (LLM) постоянно развиваются, и их будущее развитие открывает захватывающие возможности. Инновации в области обработки естественного языка (NLP) и методов глубокого обучения, вероятно, будут стимулировать прогресс в LLM. Исследования и разработки сосредоточены на масштабировании LLM, улучшении их эффективности и устранении их ограничений. Инновации, такие как более эффективные архитектуры трансформеров, новые методы обучения и достижения в вычислительной инфраструктуре, будут определять будущее развитие LLM. Эти разработки позволят LLM решать более сложные задачи, улучшать свою производительность и расширять сферу применения в различных областях.
Инновации на горизонте
Исследователи активно работают над созданием более эффективных архитектур трансформеров, которые могут обрабатывать более крупные модели и более эффективно обрабатывать текст. Кроме того, достижения в методах глубокого обучения, таких как неконтролируемое обучение и обучение с подкреплением, еще больше улучшат возможности LLM. Область обработки естественного языка (NLP) также исследует новые методы обучения, которые могут повысить эффективность и производительность LLM. Эти инновации приведут к разработке LLM, которые смогут выполнять более сложные задачи, более тонко понимать контекст и генерировать более точный и контекстуально релевантный текст.
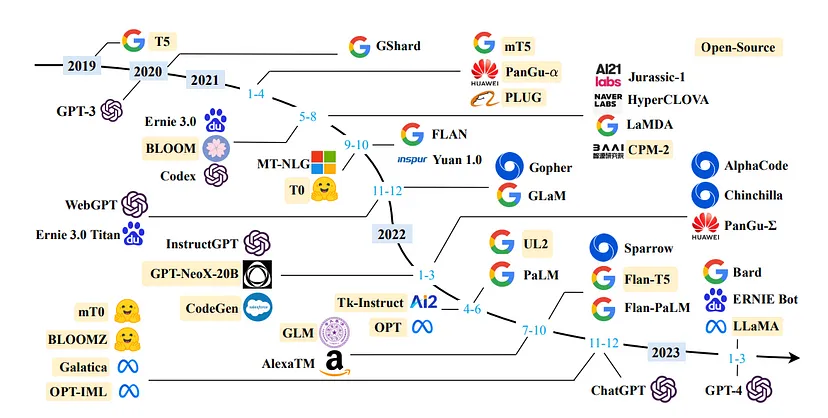
Масштабирование и повышение эффективности
Поскольку LLM продолжают увеличиваться в размерах, исследователи ищут способы сделать их обучение и обработку более эффективными. Это включает оптимизацию вычислительных требований, снижение использования памяти и улучшение возможностей параллельной обработки. Масштабирование LLM для обработки огромных объемов данных и повышение их вычислительной эффективности позволит им более эффективно обрабатывать и генерировать текст. Эти улучшения окажут значительное влияние на производительность и применимость LLM в различных областях, от перевода языка до создания контента. Улучшения в масштабировании и эффективности LLM откроют новые возможности для их использования в реальных приложениях и будут стимулировать прогресс в области обработки естественного языка.
Изучение ограничений LLM
Хотя большие языковые модели (LLM) добились значительных успехов в обработке естественного языка (NLP), они не лишены ограничений. Понимание этих ограничений имеет решающее значение для оптимизации их использования и решения потенциальных проблем. LLM сильно зависят от огромных объемов данных для обучения и могут испытывать трудности с обработкой узкоспециализированных или специализированных контекстов. Статистические взаимосвязи, изученные LLM, могут приводить к «галлюцинациям», когда модель выдает ложные или неверные результаты. Кроме того, LLM могут сталкиваться с проблемами, связанными с безопасностью, предвзятостью в данных и выходах, а также с нарушениями авторских прав. Изучение и устранение этих ограничений необходимо для ответственной разработки и использования LLM.
Понимание ограничений
Одним из ключевых ограничений является доступность и качество обучающих данных. LLM полагаются на огромные объемы текстовых данных для обучения, и качество и разнообразие этих данных существенно влияют на их способность точно понимать и генерировать текст. Другим ограничением является статистическая природа LLM, означающая, что они учатся на закономерностях и взаимосвязях в данных, на которых обучаются. Это ограничение может приводить к трудностям в понимании нюансов или специфического для предметной области языка. Кроме того, LLM могут сталкиваться с вычислительными ограничениями из-за огромного размера и сложности их моделей, что требует значительных вычислительных ресурсов для обучения и обработки.
Устранение ограничений
Исследователи и разработчики работают над стратегиями смягчения проблем, связанных с ограничениями в обучающих данных, статистическими взаимосвязями и вычислительными ресурсами. Такие методы, как тонкая настройка, проектирование подсказок и обратная связь от человека, используются для улучшения производительности LLM и устранения ограничений. Тонкая настройка позволяет LLM адаптироваться к конкретным задачам или областям, улучшая их точность и релевантность. Проектирование подсказок включает оптимизацию инструкций или запросов, задаваемых LLM, для генерации более точных и контекстуально релевантных результатов. Обратная связь от человека также имеет решающее значение для улучшения LLM и выявления и устранения предвзятости или ограничений. Активно устраняя эти ограничения, исследователи и разработчики стремятся повысить возможности и производительность LLM в реальных приложениях.
Заключение
Большие языковые модели (LLM) представляют собой значительный скачок в области искусственного интеллекта, трансформируя то, как мы взаимодействуем с технологиями. Их сложная архитектура и передовые механизмы обучения позволяют им понимать и генерировать сложный текст, как никогда раньше. По мере того, как эти модели продолжают развиваться, они обладают огромным потенциалом для революции в различных секторах, выходящих за рамки обработки естественного языка. Однако, наряду с их преимуществами, крайне важно учитывать этические аспекты и проблемы масштабируемости, чтобы обеспечить ответственное и эффективное развертывание. Принимая будущее LLM, необходимо изучать инновационные приложения, одновременно активно смягчая ограничения для создания более инклюзивного и устойчивого ландшафта ИИ.
Часто задаваемые вопросы
Чем LLM отличаются от традиционных моделей?
LLM имеют значительно большее количество параметров и могут выполнять множество задач благодаря обучению на огромных наборах данных. Они также используют трансформерные модели и механизмы внимания, что позволяет им генерировать более точные предсказания в широком спектре задач обработки естественного языка.
Могут ли LLM понимать контекст за пределами текста?
Большие языковые модели (LLM) в некоторой степени способны понимать контекст за пределами текста. Благодаря обучению на огромных наборах данных и механизмам внимания LLM могут захватывать взаимосвязи между словами и генерировать предсказания на основе контекста предложения или последовательности текста.
novita.ai — универсальная платформа для безграничного творчества, предоставляющая доступ к 100+ API. От генерации изображений и обработки языка до улучшения аудио и редактирования видео — дешевая оплата по мере использования освобождает вас от хлопот по обслуживанию GPU, пока вы создаете свои собственные продукты. Попробуйте бесплатно.
Рекомендуемое чтение
Novita AI LLM Inference Engine: самая большая пропускная способность и самый дешевый вывод



