
Qwen 3 para RAG (LLM, embedding, reclassificação) é uma solução de IA de código aberto projetada para Geração Aumentada por Recuperação. Ela combina três modelos principais: modelos de embedding para encontrar documentos relevantes, modelos de reclassificação para classificar os melhores resultados e um LLM poderoso para gerar respostas claras e precisas. O Qwen 3 oferece suporte a contexto longo, vários idiomas e é fácil de usar, sendo ideal para construir sistemas inteligentes de busca e perguntas e respostas.
Como LLM, Modelos de Embedding e Modelos de Reclassificação Trabalham Juntos?
1. Modelos de Embedding: Entendendo a Recuperação
Propósito:
Encontrar informações relevantes em uma grande coleção de documentos.
Como funciona:
- Cada documento (ou fragmento de texto) é convertido em um vetor (um conjunto de números) usando um modelo de embedding (ex.: Ada da OpenAI, Sentence Transformers).
- A consulta do usuário também é transformada em um vetor.
- O sistema busca vetores de documentos mais semelhantes ao vetor da consulta (usando métricas de similaridade como similaridade de cosseno).
- Os N documentos mais semelhantes são recuperados.
2. Modelos de Reclassificação: Melhorando a Relevância
Propósito:
Refinar os resultados obtidos na etapa de recuperação por embedding, classificando-os com mais precisão com base em sua relevância para a consulta.
Como funciona:
- O conjunto inicial de documentos recuperados (por exemplo, os 20 principais) é avaliado novamente usando um reclassificador.
- Reclassificadores frequentemente usam modelos de codificador cruzado (como BERT, RoBERTa) que recebem tanto a consulta quanto cada documento como entrada e produzem uma pontuação de relevância.
- Os documentos mais bem classificados são selecionados para a próxima etapa.
3. LLM (Modelo de Linguagem de Grande Escala): Gerando Respostas
Propósito:
Gerar uma resposta coerente e informativa com base no contexto recuperado.
Como funciona:
- Os documentos mais bem classificados são concatenados ou resumidos como “contexto”.
- O LLM recebe a pergunta do usuário e o contexto recuperado como entrada.
- O LLM gera uma resposta, idealmente citando ou utilizando as informações recuperadas.
Como Todos Trabalham Juntos (Pipeline RAG)
- Usuário envia consulta.
- Modelo de embedding recupera documentos relevantes.
- Reclassificador ordena esses documentos por relevância.
- LLM usa os documentos principais para gerar uma resposta.
Quais São os Modelos Qwen 3 para RAG?
Modelo de Embedding Qwen 3
| Modelo | Tamanho | Camadas | Comprimento da Sequência | Dimensão do Embedding | Suporte MRL | Consciente de Instrução |
|---|---|---|---|---|---|---|
| Qwen3 Embedding 0.6B | 0.6B | 28 | 32K | 1024 | Sim | Sim |
| Qwen3 Embedding 4B | 4B | 36 | 32K | 2560 | Sim | Sim |
| Qwen3 Embedding 8B | 8B | 36 | 32K | 4096 | Sim | Sim |
Modelo de Reclassificação Qwen 3
| Modelo | Tamanho | Camadas | Comprimento da Sequência | Consciente de Instrução |
| Qwen3-Reranker-0.6B | 0.6B | 32 | 32K | Sim |
| Qwen3-Reranker-4B | 4B | 36 | 32K | Sim |
| Qwen3-Reranker-8B | 8B | 36 | 32K | Sim |
Modelo LLM Qwen 3
| Modelo | Arquitetura | Parâmetros (Total / Ativados) | Camadas | Cabeças de Atenção (Q / KV) | Experts (Total / Ativos) | Janela de Contexto (tokens) |
|---|---|---|---|---|---|---|
| Qwen3-235B-A22B | MoE | 235B / 22B | 94 | 64 / 4 | 128 / 8 | 32.768 (131.072 c/ YaRN) |
| Qwen3-30B-A3B | MoE | 30.5B / 3.3B | 48 | 32 / 4 | 128 / 8 | 32.768 (131.072 c/ YaRN) |
| Qwen3-32B | Denso | 32.8B | 64 | 64 / 8 | - | 32.768 (131.072 c/ YaRN) |
| Qwen3-14B | Denso | 14.8B | 40 | 40 / 8 | - | 32.768 (131.072 c/ YaRN) |
| Qwen3-8B | Denso | 8.2B | 36 | 32 / 8 | - | 32.768 (131.072 c/ YaRN) |
| Qwen3-4B | Denso | 4.0B | 36 | 32 / 8 | - | 32.768 (131.072 c/ YaRN) |
| Qwen3-1.7B | Denso | 1.7B | 28 | 16 / 8 | - | 32.768 |
| Qwen3-0.6B | Denso | 0.6B | 28 | 16 / 8 | - | 32.768 |
Por que os Desenvolvedores Estão Migrando para o Qwen3 em RAG?
| Característica | Qwen 3 |
|---|---|
| Janela de Contexto Longa | 32.000 tokens |
| Múltiplos Tamanhos de Modelo | 0.6B / 4B / 8B |
| Suporte Multilíngue | 100+ idiomas |
| Arquiteturas Avançadas | Modelos de reclassificação usam configuração de codificador cruzado / Modelos de embedding usam configuração de bi-codificador |
| Código Aberto | Apache-2.0 |
| Consciência de Instrução | Suporta compreensão e seguimento de instruções específicas |
O Desempenho dos Modelos Qwen 3
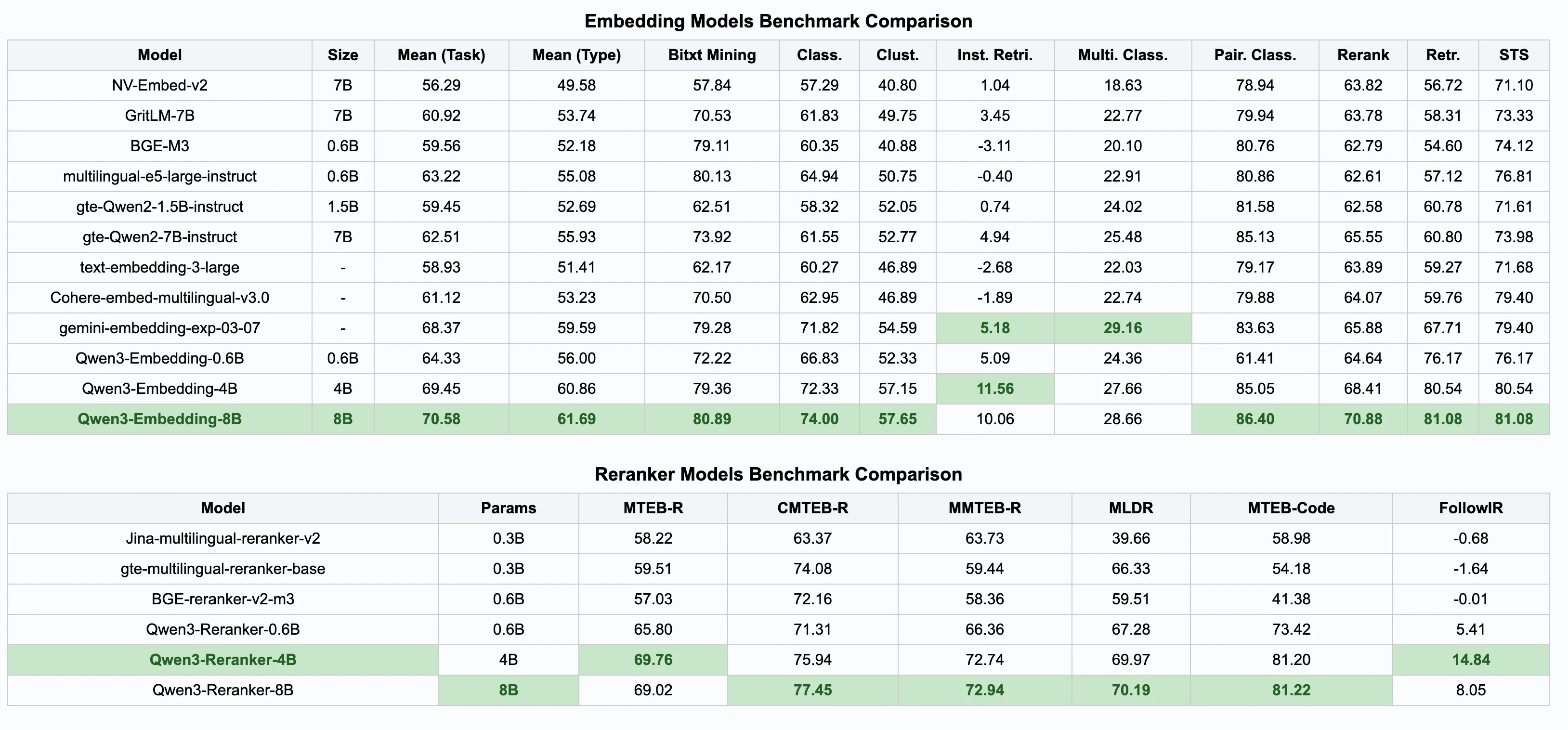
Você pode conferir a avaliação dos modelos de embedding neste leaderboard!
Como Acessar os Modelos Qwen 3?
Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma maneira fácil de implantar modelos de IA usando nossa API simples, além de fornecer GPU em nuvem acessível e confiável para construir e escalar.
Além do Qwen 3 Reranker 8B e Embedding 8B, a Novita AI também oferece o bge-m3 gratuito para apoiar o desenvolvimento da comunidade de código aberto!
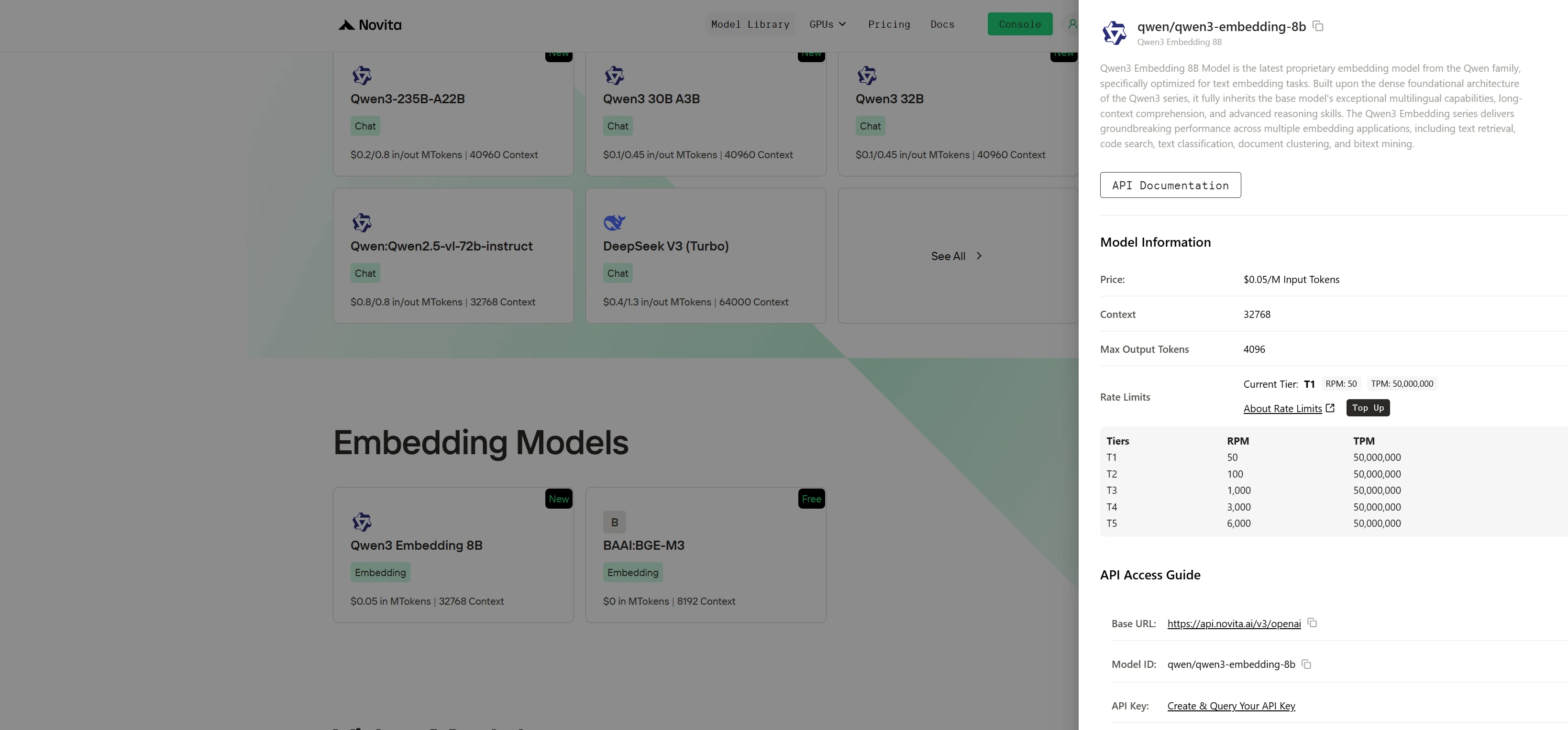
Passo 1: Faça Login e Acesse a Biblioteca de Modelos
Faça login na sua conta e clique no botão Model Library.

Experimente os Modelos Qwen 3 Agora!
Passo 2: Escolha Seu Modelo e Inicie um Teste Gratuito
Navegue pelas opções disponíveis e selecione o modelo que atende às suas necessidades.
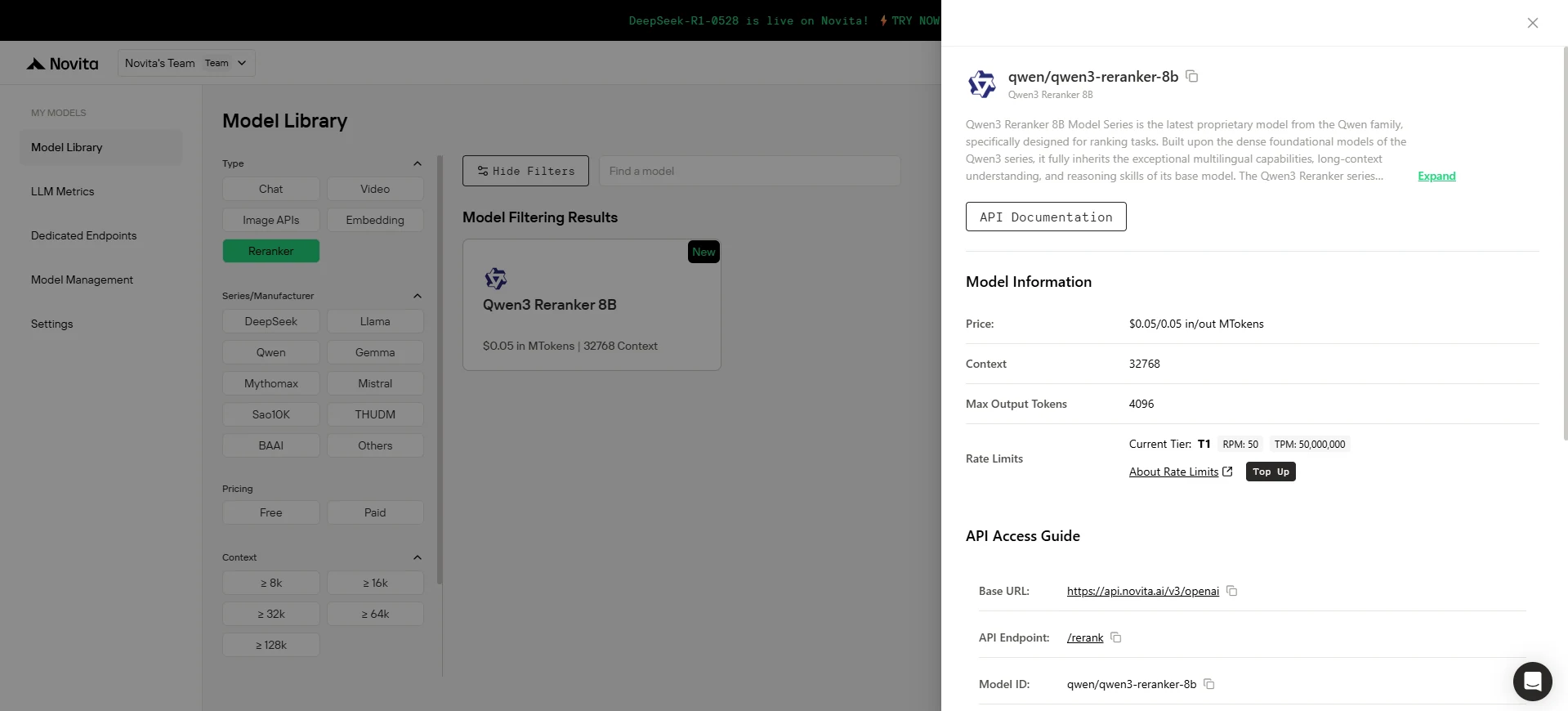
Passo 3: Obtenha Sua Chave de API
Para autenticar na API, forneceremos uma nova chave de API. Acessando a página “Settings”, você pode copiar a chave de API conforme indicado na imagem.

Passo 4: Instale a API (Exemplo: Modelo Qwen 3 Ranker)
Instale a API usando o gerenciador de pacotes específico da sua linguagem de programação.
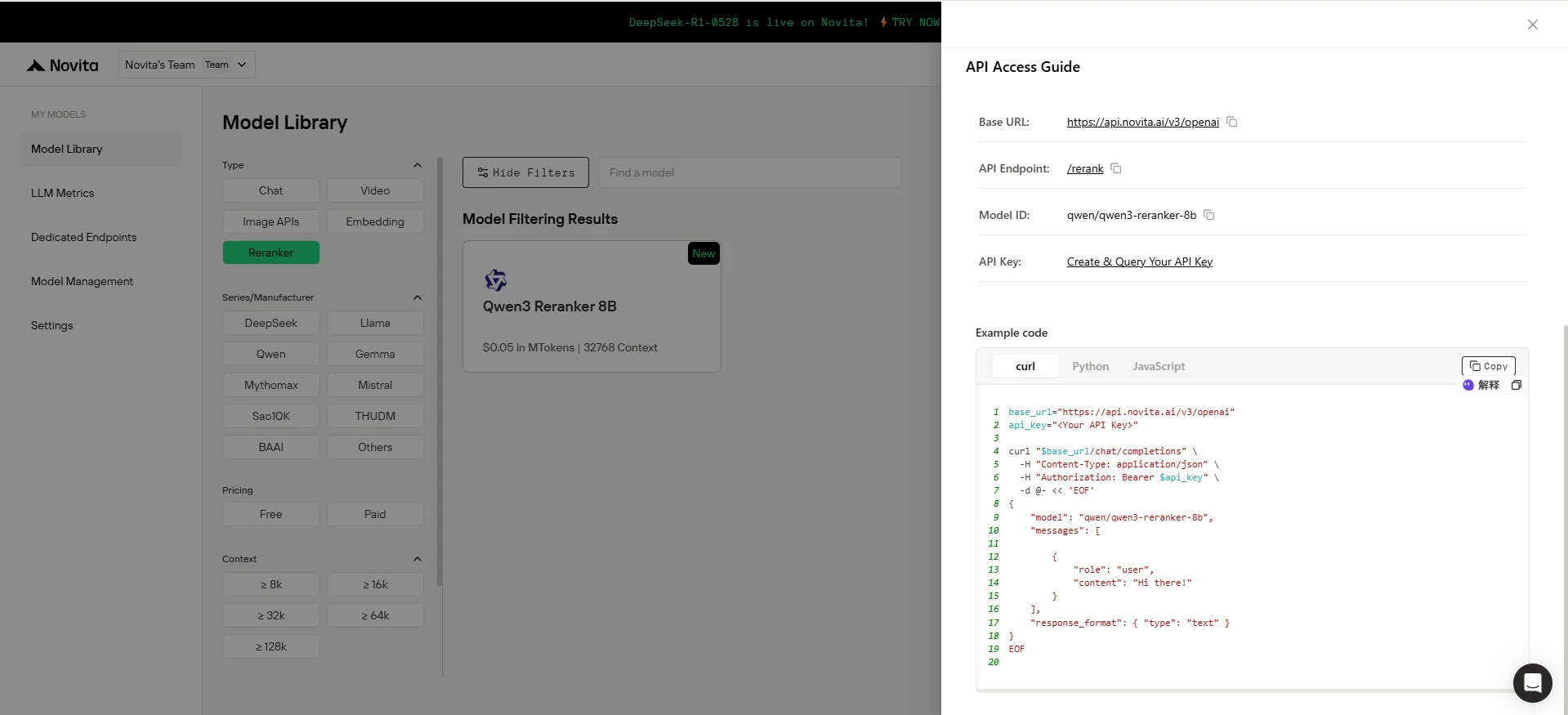
Após a instalação, importe as bibliotecas necessárias para o seu ambiente de desenvolvimento. Inicialize a API com sua chave de API para começar a interagir com os modelos da Novita AI. Este é um exemplo de uso da API de chat completions para usuários Python.
from openai import OpenAI
base_url = "https://api.novita.ai/v3/openai"
api_key = "<Your API Key>"
model = "qwen/qwen3-reranker-8b"
client = OpenAI(
base_url=base_url,
api_key=api_key,
)
stream = True # or False
max_tokens = 1000
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
extra_body={
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
À medida que as aplicações de IA exigem uma compreensão mais precisa da intenção do usuário, os modelos de reclassificação se tornaram ferramentas essenciais para entregar resultados de busca mais inteligentes. Atuando como uma segunda camada de inteligência após a recuperação inicial, os reclassificadores ajustam as classificações dos documentos usando uma análise contextual mais profunda. A série Qwen 3 Reranker estabelece um novo padrão nesse espaço, oferecendo desempenho impressionante em vários idiomas, documentos longos e até mesmo tarefas de recuperação de código. Com a implantação simplificada através da Novita AI, os desenvolvedores podem aproveitar esses modelos avançados sem infraestrutura pesada — tornando a recuperação de alta precisão mais acessível do que nunca.
Perguntas Frequentes
O que é um modelo de reclassificação?
Um reclassificador reordena uma lista de documentos recuperados, pontuando sua relevância para uma consulta, melhorando a precisão em sistemas de busca baseados em IA.
Qual a diferença entre um reclassificador e um modelo de embedding?
Modelo de Embedding: Converte cada texto em um vetor e os compara usando similaridade.
Modelo de Reclassificação: Lê tanto a consulta quanto o documento juntos e fornece uma pontuação inteligente de relevância.
Qual o desempenho do Qwen 3 Reranker?
Qwen3-Reranker-8B alcança pontuações de alto nível:
MTEB-R: 69,02,
CMTEB-R: 77,45,
MTEB-Code: 81,22
Supera modelos populares como BGE e GTE em várias categorias.
Novita AI é a plataforma de nuvem tudo-em-um que impulsiona suas ambições de IA. APIs integradas, serverless, Instância GPU — as ferramentas econômicas que você precisa. Elimine infraestrutura, comece gratuitamente e transforme sua visão de IA em realidade.



