
Qwen 3 para RAG (llm, incrustación, reordenamiento) es una solución de IA de código abierto diseñada para Generación Aumentada por Recuperación. Combina tres modelos principales: modelos de incrustación para encontrar documentos relevantes, modelos de reordenamiento para ordenar los mejores resultados y un poderoso LLM para generar respuestas claras y precisas. Qwen 3 admite contexto largo, varios idiomas y es fácil de usar, lo que lo hace ideal para construir sistemas inteligentes de búsqueda y respuesta a preguntas.
¿Cómo funcionan juntos LLM, los modelos de incrustación y los modelos de reordenamiento?
1. Modelos de incrustación: comprensión de la recuperación
Propósito:
Encontrar información relevante de una gran colección de documentos.
Cómo funciona:
- Cada documento (o fragmento de texto) se convierte en un vector (un arreglo de números) usando un modelo de incrustación (por ejemplo, Ada de OpenAI, Sentence Transformers).
- La consulta del usuario también se convierte en un vector.
- El sistema busca vectores de documentos que sean más similares al vector de consulta (usando métricas de similitud como la similitud coseno).
- Se recuperan los N documentos más similares.
2. Modelos de reordenamiento: mejora de la relevancia
Propósito:
Refinar los resultados del paso de recuperación de incrustación clasificándolos más precisamente según su relevancia para la consulta.
Cómo funciona:
- El conjunto inicial de documentos recuperados (digamos, los 20 mejores) se evalúa nuevamente usando un reordenador.
- Los reordenadores suelen usar modelos de codificador cruzado (como BERT, RoBERTa) que toman tanto la consulta como cada documento como entrada y generan una puntuación de relevancia.
- Los documentos mejor clasificados se seleccionan para el siguiente paso.
3. LLM (Modelo de Lenguaje Grande): generación de respuestas
Propósito:
Generar una respuesta coherente e informativa basada en el contexto recuperado.
Cómo funciona:
- Los documentos mejor clasificados se concatenan o resumen como “contexto”.
- Se le indica al LLM la pregunta del usuario y el contexto recuperado.
- El LLM genera una respuesta, idealmente citando o usando la información recuperada.
Cómo funcionan todos juntos (Pipeline RAG)
- El usuario envía una consulta.
- El modelo de incrustación recupera documentos relevantes.
- El reordenador clasifica estos documentos por relevancia.
- El LLM usa los documentos principales para generar una respuesta.
¿Cuáles son los modelos Qwen 3 para RAG?
Modelo de incrustación Qwen 3
| Modelo | Tamaño | Capas | Longitud de secuencia | Dimensión de incrustación | Soporte MRL | Atención a instrucciones |
|---|---|---|---|---|---|---|
| Qwen3 Embedding 0.6B | 0.6B | 28 | 32K | 1024 | Sí | Sí |
| Qwen3 Embedding 4B | 4B | 36 | 32K | 2560 | Sí | Sí |
| Qwen3 Embedding 8B | 8B | 36 | 32K | 4096 | Sí | Sí |
Modelo de reordenamiento Qwen 3
| Modelo | Tamaño | Capas | Longitud de secuencia | Atención a instrucciones |
| Qwen3-Reranker-0.6B | 0.6B | 32 | 32K | Sí |
| Qwen3-Reranker-4B | 4B | 36 | 32K | Sí |
| Qwen3-Reranker-8B | 8B | 36 | 32K | Sí |
Modelo LLM Qwen 3
| Modelo | Arquitectura | Parámetros (Total / Activados) | Capas | Cabezas de atención (Q / KV) | Expertos (Total / Activos) | Ventana de contexto (tokens) |
|---|---|---|---|---|---|---|
| Qwen3-235B-A22B | MoE | 235B / 22B | 94 | 64 / 4 | 128 / 8 | 32,768 (131,072 con YaRN) |
| Qwen3-30B-A3B | MoE | 30.5B / 3.3B | 48 | 32 / 4 | 128 / 8 | 32,768 (131,072 con YaRN) |
| Qwen3-32B | Denso | 32.8B | 64 | 64 / 8 | - | 32,768 (131,072 con YaRN) |
| Qwen3-14B | Denso | 14.8B | 40 | 40 / 8 | - | 32,768 (131,072 con YaRN) |
| Qwen3-8B | Denso | 8.2B | 36 | 32 / 8 | - | 32,768 (131,072 con YaRN) |
| Qwen3-4B | Denso | 4.0B | 36 | 32 / 8 | - | 32,768 (131,072 con YaRN) |
| Qwen3-1.7B | Denso | 1.7B | 28 | 16 / 8 | - | 32,768 |
| Qwen3-0.6B | Denso | 0.6B | 28 | 16 / 8 | - | 32,768 |
¿Por qué los desarrolladores están cambiando a Qwen3 para RAG?
| Característica | Qwen 3 |
|---|---|
| Ventana de contexto larga | 32,000 tokens |
| Múltiples tamaños de modelo | 0.6B / 4B / 8B |
| Soporte multilingüe | 100+ idiomas |
| Arquitecturas avanzadas | Los modelos de reordenamiento usan configuración de codificador cruzado / Los modelos de incrustación usan configuración de bi-codificador |
| Código abierto | Apache-2.0 |
| Atención a instrucciones | Capacidad de entender y seguir instrucciones específicas |
El rendimiento de los modelos Qwen 3
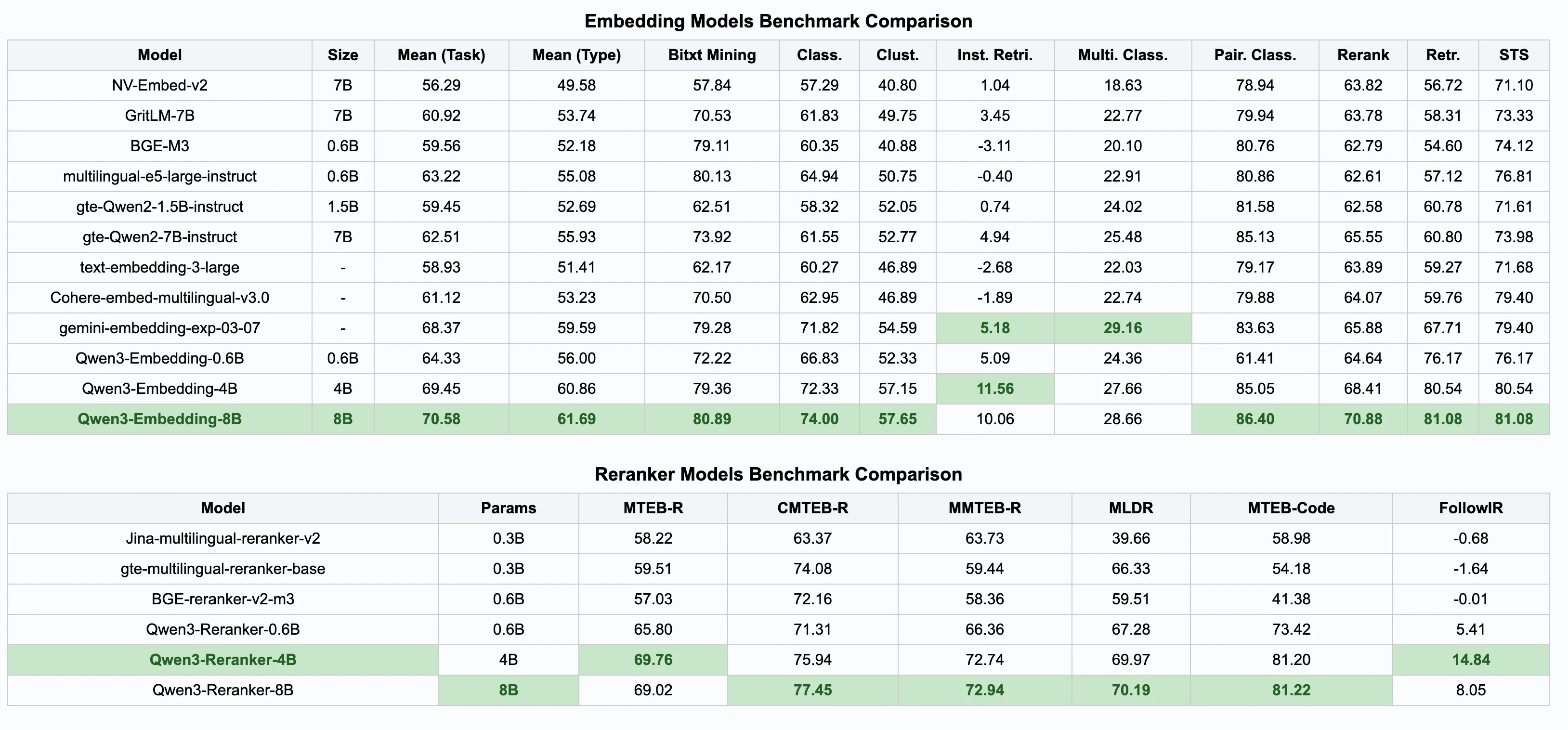
Puedes consultar la evaluación de los modelos de incrustación en este leaderboard !
¿Cómo acceder a los modelos Qwen 3?
Novita AI es una plataforma en la nube de IA que ofrece a los desarrolladores una manera fácil de implementar modelos de IA usando nuestra API simple, además de proporcionar GPU en la nube asequible y confiable para construir y escalar.
Además de Qwen 3 Reranker 8B y Embedding 8B, Novita AI también ofrece bge-m3 de forma gratuita para apoyar el desarrollo de la comunidad de código abierto.
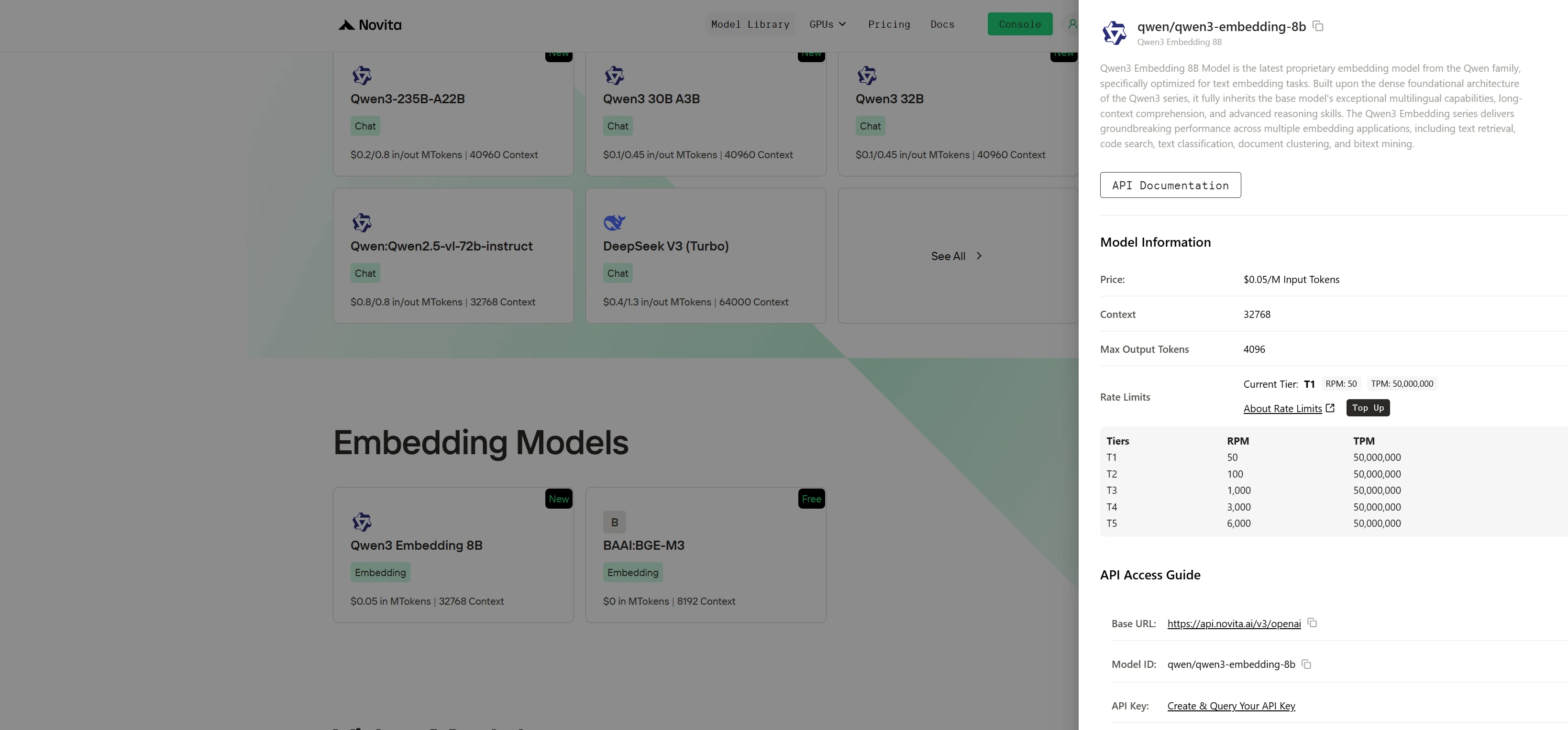
Paso 1: Inicia sesión y accede a la Biblioteca de modelos
Inicia sesión en tu cuenta y haz clic en el botón Biblioteca de modelos.

¡Prueba los modelos Qwen 3 ahora!
Paso 2: Elige tu modelo y comienza una prueba gratuita
Navega por las opciones disponibles y selecciona el modelo que se adapte a tus necesidades.
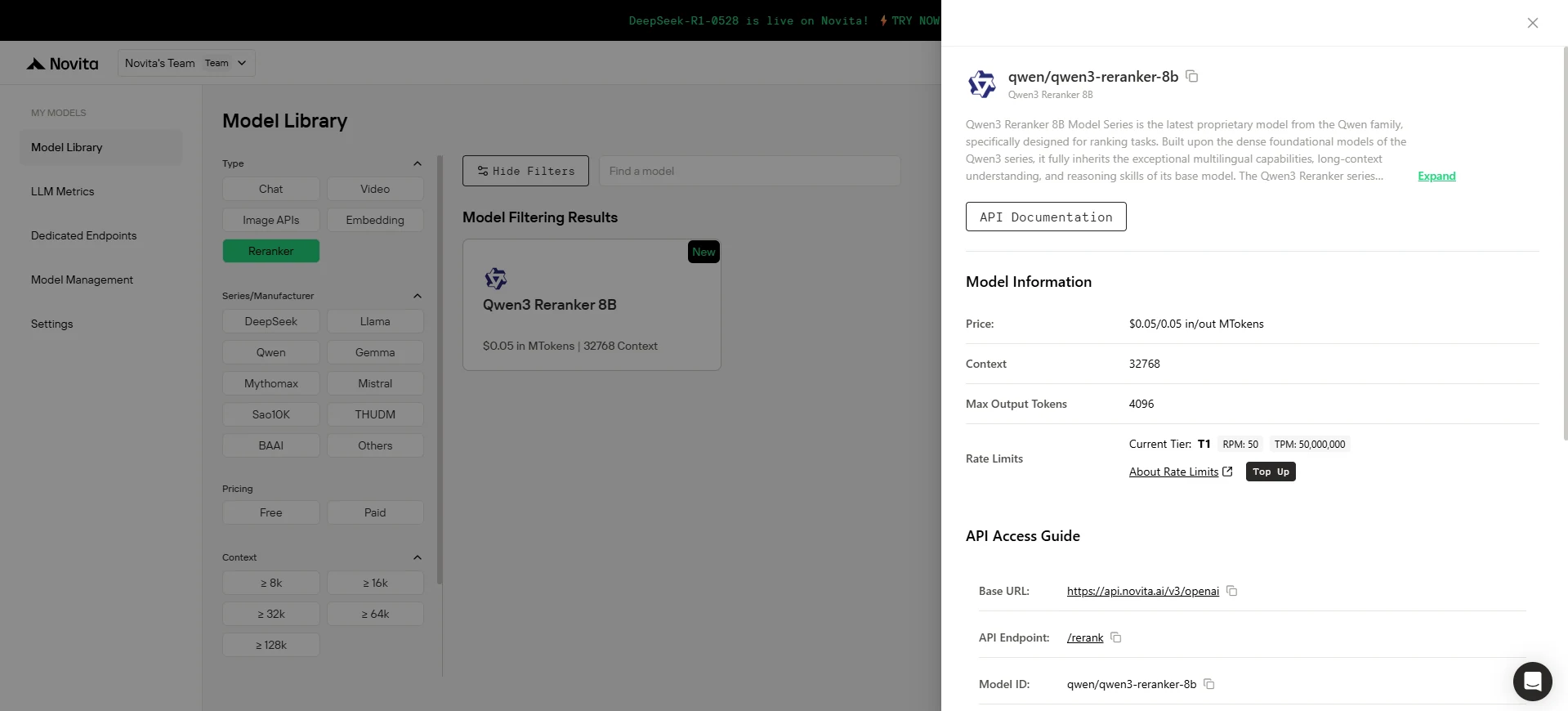
Paso 3: Obtén tu clave API
Para autenticarte con la API, te proporcionaremos una nueva clave API. Ingresa a la página de “Configuración” y copia la clave API como se indica en la imagen.

Paso 4: Instala la API (Ejemplo: Modelo de reordenamiento Qwen 3)
Instala la API usando el gestor de paquetes específico para tu lenguaje de programación.
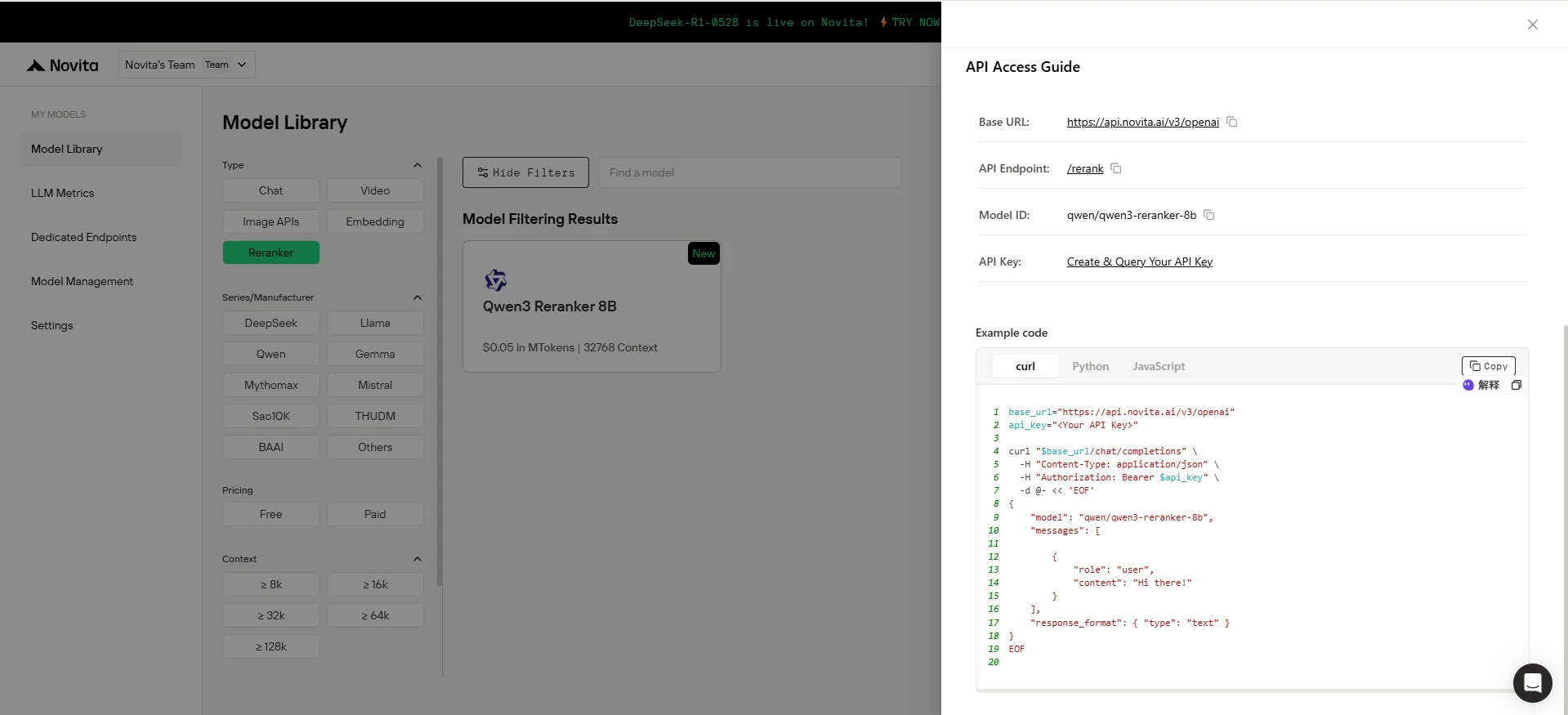
Después de la instalación, importa las bibliotecas necesarias en tu entorno de desarrollo. Inicializa la API con tu clave API para comenzar a interactuar con los modelos de Novita AI. Este es un ejemplo de uso de la API de chat completions para usuarios de Python.
from openai import OpenAI
base_url = "https://api.novita.ai/v3/openai"
api_key = "<Your API Key>"
model = "qwen/qwen3-reranker-8b"
client = OpenAI(
base_url=base_url,
api_key=api_key,
)
stream = True # or False
max_tokens = 1000
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
extra_body={
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
A medida que las aplicaciones de IA demandan una comprensión más precisa de la intención del usuario, los modelos de reordenamiento se han convertido en herramientas esenciales para ofrecer resultados de búsqueda más inteligentes. Actuando como una segunda capa de inteligencia después de la recuperación inicial, los reordenadores ajustan la clasificación de documentos mediante un análisis contextual más profundo. La serie Qwen 3 Reranker establece un nuevo estándar en este espacio, ofreciendo un rendimiento impresionante en varios idiomas, documentos largos e incluso tareas de recuperación de código. Con una implementación simplificada a través de Novita AI, los desarrolladores pueden aprovechar estos modelos avanzados sin una infraestructura pesada, haciendo que la recuperación de alta precisión sea más accesible que nunca.
Preguntas frecuentes
¿Qué es un modelo de reordenamiento?
Un reordenador reordena una lista de documentos recuperados puntuando su relevancia para una consulta, mejorando la precisión en los sistemas de búsqueda de IA.
¿En qué se diferencia un reordenador de un modelo de incrustación?
Modelo de incrustación: Convierte cada texto en un vector y los compara usando similitud.
Modelo de reordenamiento: Lee tanto la consulta como el documento juntos y asigna una puntuación inteligente de relevancia.
¿Cómo se desempeña Qwen 3 Reranker?
Qwen3-Reranker-8B alcanza puntuaciones de primer nivel:
MTEB-R: 69.02,
CMTEB-R: 77.45,
MTEB-Code: 81.22
Supera a modelos populares como BGE y GTE en múltiples categorías.
Novita AI es la plataforma en la nube todo en uno que impulsa tus ambiciones de IA. APIs integradas, serverless, GPU Instance: las herramientas rentables que necesitas. Elimina la infraestructura, comienza gratis y haz realidad tu visión de IA.



