
Qwen 3 لـ RAG (llm, embedding, reranking) هو حل ذكاء اصطناعي مفتوح المصدر مصمم للتوليد المعزز بالاسترجاع (Retrieval-Augmented Generation). يجمع بين ثلاثة نماذج رئيسية: نماذج التضمين (embedding) للعثور على المستندات ذات الصلة، ونماذج إعادة الترتيب (reranking) لفرز أفضل النتائج، و LLM قوي لتوليد إجابات واضحة ودقيقة. يدعم Qwen 3 السياق الطويل، واللغات المتعددة، وسهل الاستخدام، مما يجعله مثالياً لبناء أنظمة بحث ذكية وأنظمة أسئلة وأجوبة.
كيف تعمل نماذج LLM والتضمين وإعادة الترتيب معاً؟
1. نماذج التضمين: فهم الاسترجاع (Retrieval)
الغرض:
العثور على المعلومات ذات الصلة من مجموعة كبيرة من المستندات.
كيف تعمل:
- يتم تحويل كل مستند (أو جزء من النص) إلى متجه (مصفوفة أرقام) باستخدام نموذج تضمين (مثل OpenAI’s Ada, Sentence Transformers).
- يتم أيضاً تضمين استعلام المستخدم في متجه.
- يبحث النظام عن متجهات المستندات الأكثر تشابهاً مع متجه الاستعلام (باستخدام مقاييس التشابه مثل تشابه جيب التمام cosine similarity).
- يتم استرجاع أفضل N من المستندات الأكثر تشابهاً.
2. نماذج إعادة الترتيب: تحسين الصلة (Improving Relevance)
الغرض:
تحسين نتائج خطوة استرجاع التضمين من خلال ترتيبها بشكل أكثر دقة بناءً على صلتها بالاستعلام.
كيف تعمل:
- يتم تقييم المجموعة الأولية من المستندات المسترجعة (على سبيل المثال، أفضل 20) بشكل إضافي باستخدام معيد ترتيب (reranker).
- غالباً ما تستخدم معيدات الترتيب نماذج cross-encoder (مثل BERT, RoBERTa) التي تأخذ كلاً من الاستعلام وكل مستند كمدخل وتخرج درجة صلة relevance score.
- يتم اختيار المستندات الأعلى ترتيباً للخطوة التالية.
3. LLM (نموذج اللغة الكبير): توليد الإجابات (Generating Answers)
الغرض:
توليد إجابة متماسكة وغنية بالمعلومات بناءً على السياق المسترجع.
كيف يعمل:
- يتم دمج المستندات الأعلى ترتيباً أو تلخيصها كـ “سياق” (context).
- يتم تزويد LLM بسؤال المستخدم والسياق المسترجع.
- يقوم LLM بتوليد رد، مستشهداً بالمعلومات المسترجعة أو مستخدماً لها بشكل مثالي.
كيف يعملون جميعاً معاً (خط أنابيب RAG – RAG Pipeline)
- يقدم المستخدم استعلاماً.
- نموذج التضمين يسترجع المستندات ذات الصلة.
- معيد الترتيب يفرز هذه المستندات حسب الصلة.
- LLM يستخدم أفضل المستندات لتوليد إجابة.
ما هي نماذج Qwen 3 لـ RAG؟
نموذج تضمين Qwen 3
| النموذج | الحجم | الطبقات | طول التسلسل | بُعد التضمين | دعم MRL | الوعي بالتعليمات |
|---|---|---|---|---|---|---|
| Qwen3 Embedding 0.6B | 0.6 مليار | 28 | 32 ألف | 1024 | نعم | نعم |
| Qwen3 Embedding 4B | 4 مليار | 36 | 32 ألف | 2560 | نعم | نعم |
| Qwen3 Embedding 8B | 8 مليار | 36 | 32 ألف | 4096 | نعم | نعم |
نموذج إعادة ترتيب Qwen 3
| النموذج | الحجم | الطبقات | طول التسلسل | الوعي بالتعليمات |
| Qwen3-Reranker-0.6B | 0.6 مليار | 32 | 32 ألف | نعم |
| Qwen3-Reranker-4B | 4 مليار | 36 | 32 ألف | نعم |
| Qwen3-Reranker-8B | 8 مليار | 36 | 32 ألف | نعم |
نموذج LLM Qwen 3
| النموذج | البنية | المعلمات (الإجمالي / المُفعّلة) | الطبقات | رؤوس الانتباه (Q / KV) | الخبراء (الإجمالي / النشط) | نافذة السياق (رمز token) |
|---|---|---|---|---|---|---|
| Qwen3-235B-A22B | MoE | 235 مليار / 22 مليار | 94 | 64 / 4 | 128 / 8 | 32,768 (131,072 مع YaRN) |
| Qwen3-30B-A3B | MoE | 30.5 مليار / 3.3 مليار | 48 | 32 / 4 | 128 / 8 | 32,768 (131,072 مع YaRN) |
| Qwen3-32B | Dense | 32.8 مليار | 64 | 64 / 8 | - | 32,768 (131,072 مع YaRN) |
| Qwen3-14B | Dense | 14.8 مليار | 40 | 40 / 8 | - | 32,768 (131,072 مع YaRN) |
| Qwen3-8B | Dense | 8.2 مليار | 36 | 32 / 8 | - | 32,768 (131,072 مع YaRN) |
| Qwen3-4B | Dense | 4.0 مليار | 36 | 32 / 8 | - | 32,768 (131,072 مع YaRN) |
| Qwen3-1.7B | Dense | 1.7 مليار | 28 | 16 / 8 | - | 32,768 |
| Qwen3-0.6B | Dense | 0.6 مليار | 28 | 16 / 8 | - | 32,768 |
لماذا يتحول المطورون إلى Qwen3 لـ RAG؟
| الميزة | Qwen 3 |
|---|---|
| نافذة سياق طويلة | 32,000 رمز token |
| أحجام نماذج متعددة | 0.6B / 4B / 8B |
| دعم متعدد اللغات | أكثر من 100 لغة |
| بنى متقدمة | نماذج إعادة الترتيب تستخدم إعداد cross-encoder / نماذج التضمين تستخدم إعداد bi-encoder |
| مفتوح المصدر | Apache-2.0 |
| الوعي بالتعليمات | يدعم الوعي بالتعليمات وفهم واتباع تعليمات محددة |
أداء نماذج Qwen 3
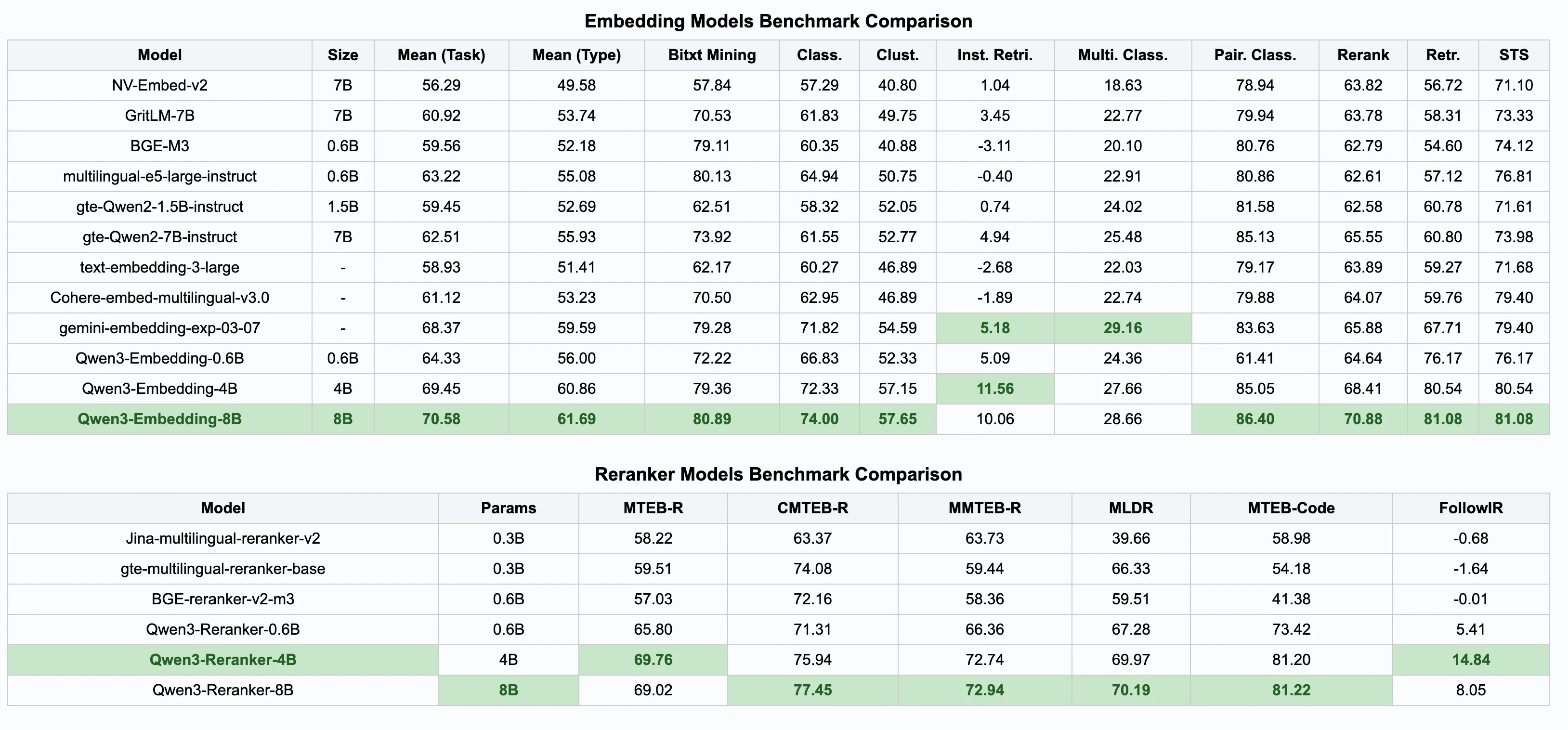
يمكنك الاطلاع على تقييم نماذج التضمين على لوحة المتصدرين هذه!
كيفية الوصول إلى نماذج Qwen 3؟
Novita AI هي منصة سحابية للذكاء الاصطناعي توفر للمطورين طريقة سهلة لنشر نماذج الذكاء الاصطناعي باستخدام واجهة برمجة التطبيقات (API) البسيطة لدينا، مع توفير سحابة GPU موثوقة وبأسعار معقولة للبناء والتوسع.
بالإضافة إلى Qwen 3 Reranker 8B و Embedding 8B، توفر Novita AI أيضاً bge-m3 مجاناً لدعم تطوير مجتمع المصادر المفتوحة!
الخطوة 1: تسجيل الدخول والوصول إلى مكتبة النماذج
سجّل الدخول إلى حسابك وانقر على زر مكتبة النماذج.

الخطوة 2: اختر نموذجك وابدأ تجربة مجانية
تصفح الخيارات المتاحة واختر النموذج الذي يناسب احتياجاتك.
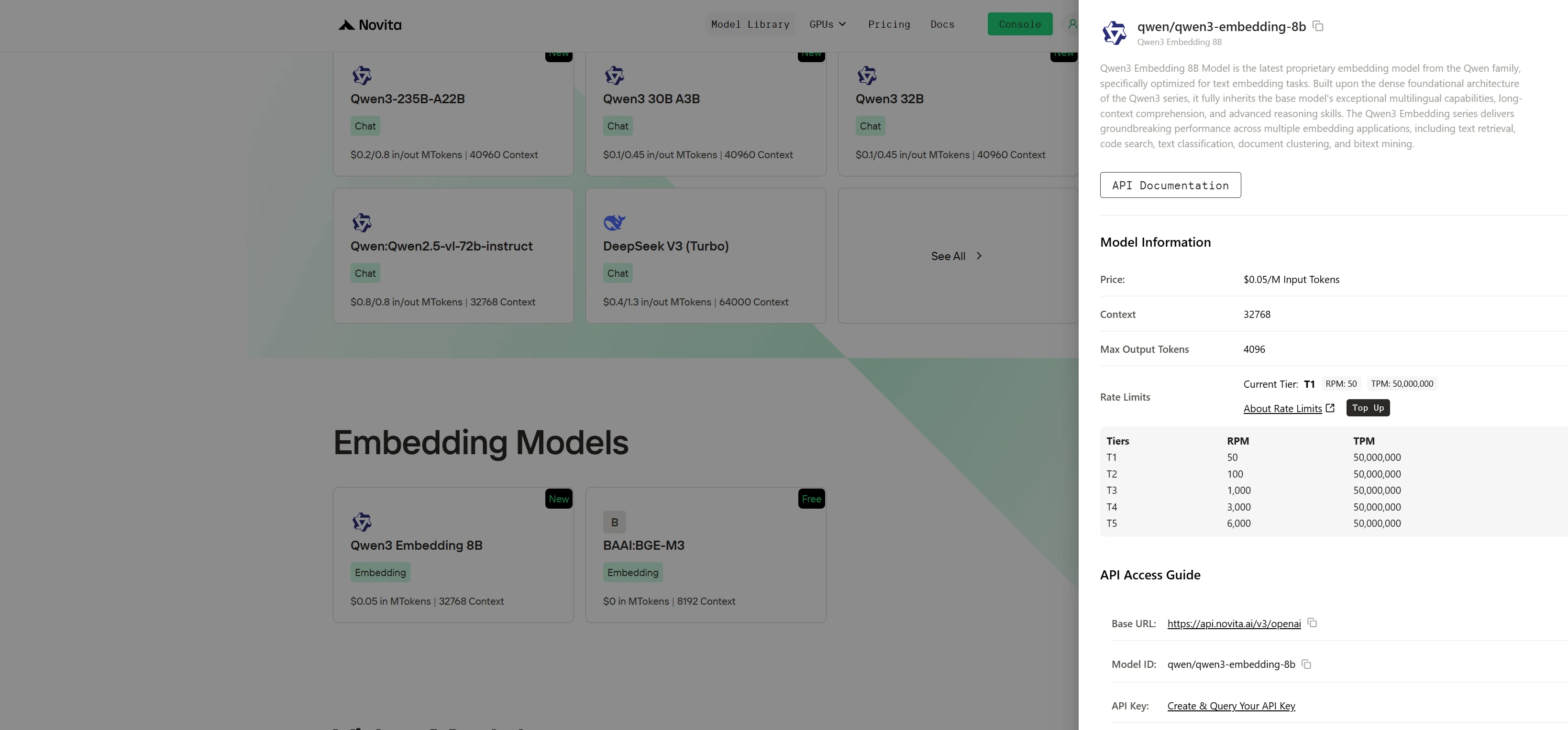
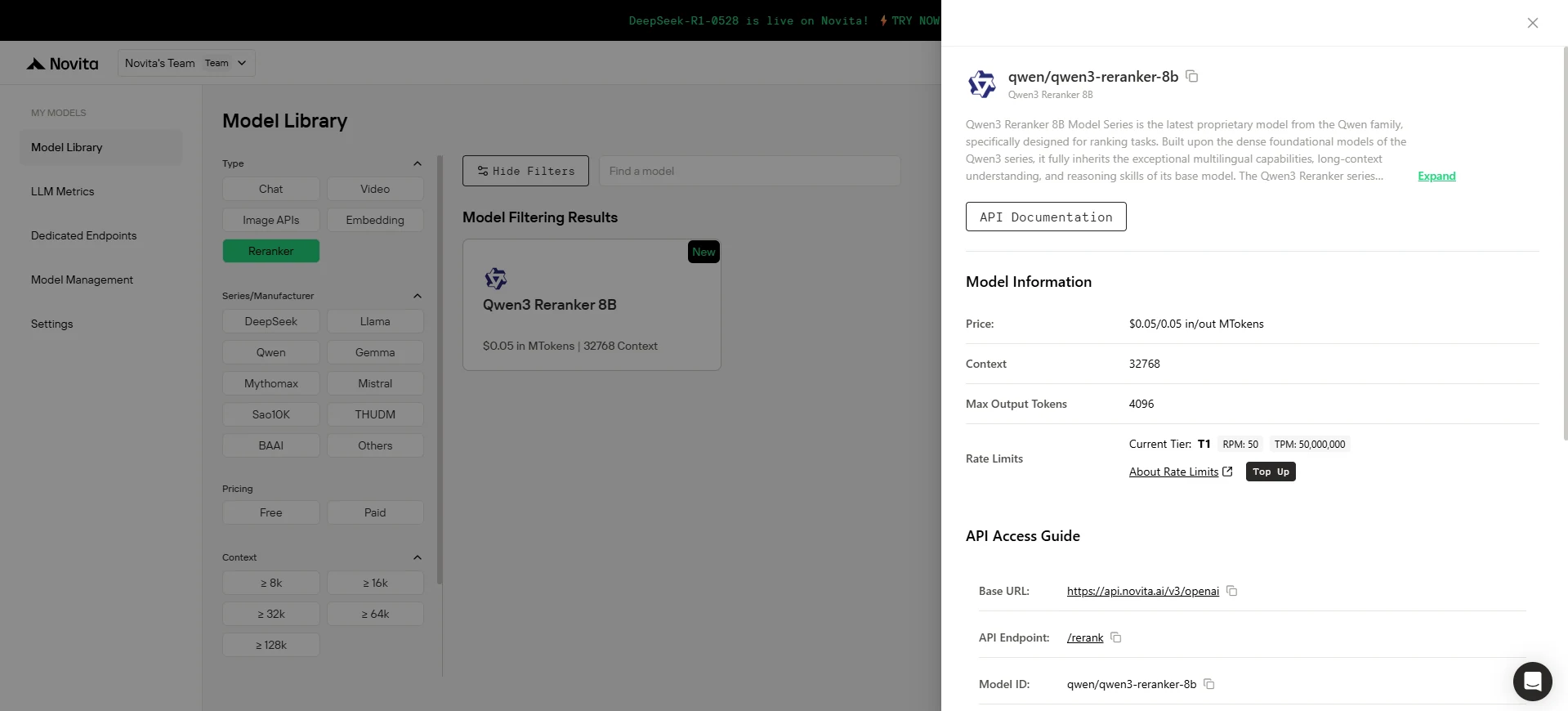
الخطوة 3: احصل على مفتاح API الخاص بك
للمصادقة مع واجهة API، سنزودك بمفتاح API جديد. بالدخول إلى صفحة “الإعدادات“، يمكنك نسخ مفتاح API كما هو موضح في الصورة.

الخطوة 4: تثبيت API (مثال: نموذج Qwen 3 Ranker)
قم بتثبيت API باستخدام مدير الحزم الخاص بلغة البرمجة التي تستخدمها.
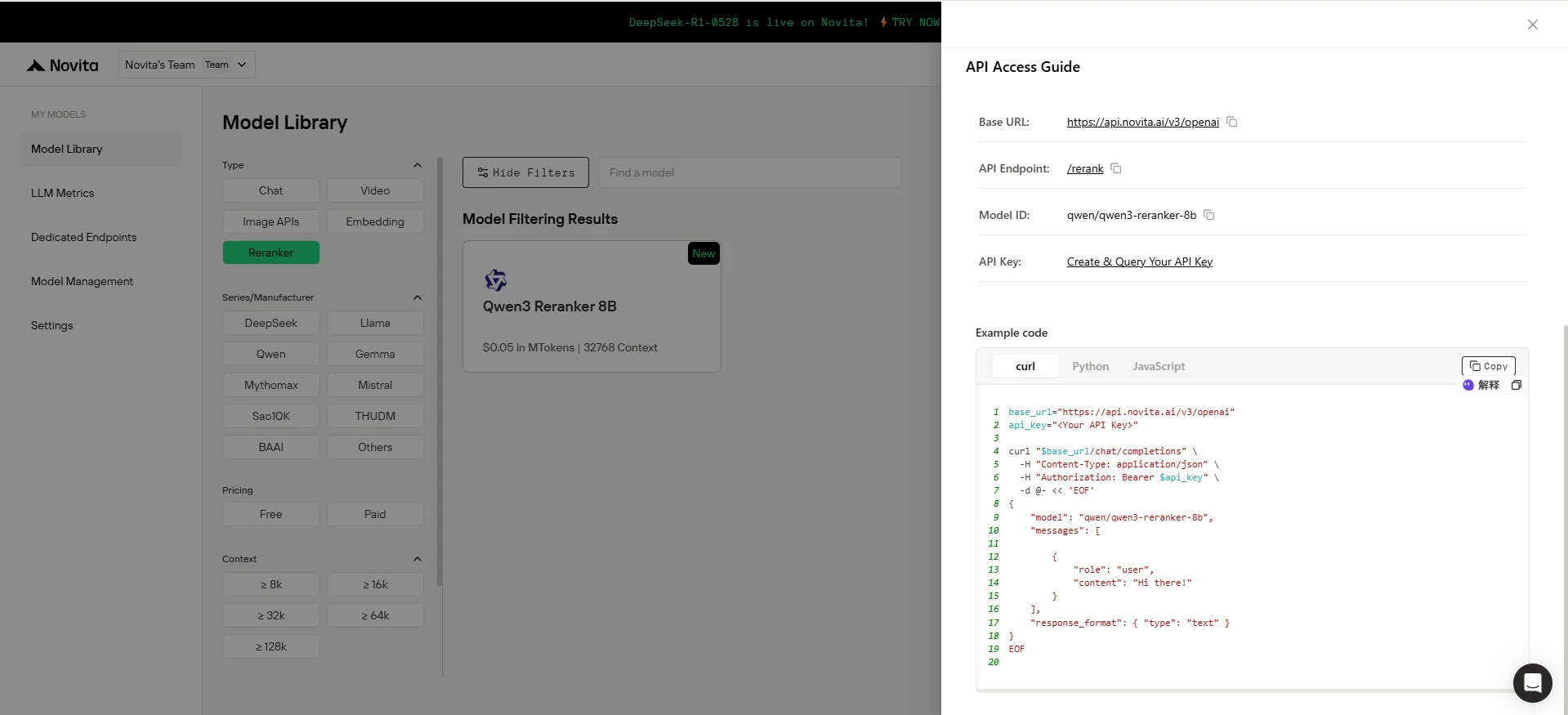
بعد التثبيت، قم باستيراد المكتبات اللازمة في بيئة التطوير الخاصة بك. قم بتهيئة API باستخدام مفتاح API الخاص بك لبدء التفاعل مع نماذج Novita AI. هذا مثال على استخدام chat completions API لمستخدمي بايثون.
from openai import OpenAI
base_url = "https://api.novita.ai/v3/openai"
api_key = "<Your API Key>"
model = "qwen/qwen3-reranker-8b"
client = OpenAI(
base_url=base_url,
api_key=api_key,
)
stream = True # or False
max_tokens = 1000
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
extra_body={
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
مع تزايد حاجة تطبيقات الذكاء الاصطناعي إلى فهم أكثر دقة لنية المستخدم، أصبحت نماذج إعادة الترتيب أدوات أساسية لتقديم نتائج بحث أكثر ذكاءً. تعمل معيدات الترتيب كطبقة ثانية من الذكاء بعد الاسترجاع الأولي، حيث تقوم بضبط ترتيب المستندات باستخدام تحليل سياقي أعمق. تضع سلسلة Qwen 3 Reranker معياراً جديداً في هذا المجال، حيث تقدم أداءً مذهلاً عبر اللغات والمستندات الطويلة وحتى مهام استرجاع الأكواد البرمجية. ومع التبسيط الذي توفره Novita AI للنشر، يمكن للمطورين تسخير هذه النماذج المتقدمة دون بنية تحتية ثقيلة، مما يجعل الاسترجاع عالي الدقة أكثر سهولة من أي وقت مضى.
الأسئلة الشائعة
ما هو نموذج إعادة الترتيب؟
نموذج إعادة الترتيب يعيد ترتيب قائمة المستندات المسترجعة عن طريق تسجيل صلتها بالاستعلام، مما يحسن الدقة في أنظمة البحث بالذكاء الاصطناعي.
كيف يختلف معيد الترتيب عن نموذج التضمين؟
نموذج التضمين: يحول كل نص إلى متجه ويقارنها باستخدام التشابه.
نموذج إعادة الترتيب: يقرأ كلاً من الاستعلام والمستند معاً ويعطي درجة ذكية للصلة.
كيف أداء Qwen 3 Reranker؟
حقق Qwen3-Reranker-8B أعلى الدرجات:
MTEB-R: 69.02،
CMTEB-R: 77.45،
MTEB-Code: 81.22
يتفوق على النماذج الشائعة مثل BGE و GTE في فئات متعددة.
Novita AI هي المنصة السحابية الشاملة التي تمكّن طموحاتك في الذكاء الاصطناعي. واجهات برمجة تطبيقات متكاملة، بدون خادم (serverless)، مثيلات GPU — الأدوات الفعالة من حيث التكلفة التي تحتاجها. تخلص من البنية التحتية، ابدأ مجاناً، واجعل رؤيتك للذكاء الاصطناعي حقيقة واقعة.



