

Novita AIが、Seedream 3.0 を発表しました。これは、画像1枚あたりわずか $0.03 という手頃な価格で、クリエイティブな可能性を再定義する画期的なテキスト画像生成AIモデルです。ByteDanceの「Seed」シリーズの主力製品として、Seedream 3.0は最先端技術とアクセシビリティを組み合わせ、英語と中国語のプロンプトをサポートするバイリンガル対応を実現しています。
Seedream 3.0: テキスト画像生成機能
Seedream 3.0 は、ByteDanceのAIチームによって開発された最先端のテキスト画像生成AIモデルです。このバイリンガルシステム(中国語と英語のプロンプト両方をサポート)は、テキストによる説明から直接高品質な画像を生成します。ByteDanceの「Seed」画像生成シリーズの第3世代として、Seedream 3.0は2025年4月にデビューし、ByteDanceのAI画像生成分野への本格参入を示しています。
Seedream 3.0 バージョン3.0の新機能

Seedream 3.0 技術革新
1. データ層: より大規模でスマートなデータセット
- トレーニングデータセットを約 100% 拡大。
- 新しい動的サンプリングメカニズム が以下をバランス:
- 画像クラスター分布(多様な画像タイプ)
- テキストの意味的一貫性(より意味のある、適切にマッチしたテキスト-画像ペア)
- 影響: このより豊かでバランスのとれたデータセットにより、多様で忠実度の高い画像を生成し、さまざまなプロンプトをより正確に追従するモデルの能力が向上します。
2. 事前トレーニングの改善
- バージョン2.0に対していくつかの強化を導入:
- 混合解像度トレーニング: モデルが低解像度と高解像度の両方の画像をネイティブに処理・生成できるようにし、真の2K出力を実現。
- クロスモダリティRoPE(回転位置埋め込み): 視覚情報とテキスト情報の間の位置合わせを改善し、プロンプトの理解とテキストレンダリングを向上。
- 表現アライメント損失: 画像とテキストの特徴がより適切にマッチするようにし、リアルな画像構成と正確なテキスト埋め込みを支援。
- 解像度認識タイムステップサンプリング: 異なる解像度に合わせて拡散プロセスを調整し、速度と画質の両方を向上。
- 影響: これらの事前トレーニングの変更により、Seedream 3.0はよりスケーラブルで汎化可能になり、細かい視覚言語アライメントが可能になります。
3. 事後トレーニング最適化
- 多様化された美的キャプション ** と ** 視覚言語モデル(VLM)ベースの報酬システム を活用。
- 影響: モデルが視覚的な魅力と意味の正確さを優先するように微調整され、より魅力的で文脈に即した画像が生成されます。
4. モデル高速化
- 一貫したノイズ期待値による 安定サンプリング を実装し、推論中に必要な関数評価の回数を削減。
- 影響: この革新がモデルの高速画像生成の鍵であり、リアルタイムフィードバックとより速いクリエイティブな反復を可能にします。
T2IのためのSeedream 3.0の代替案
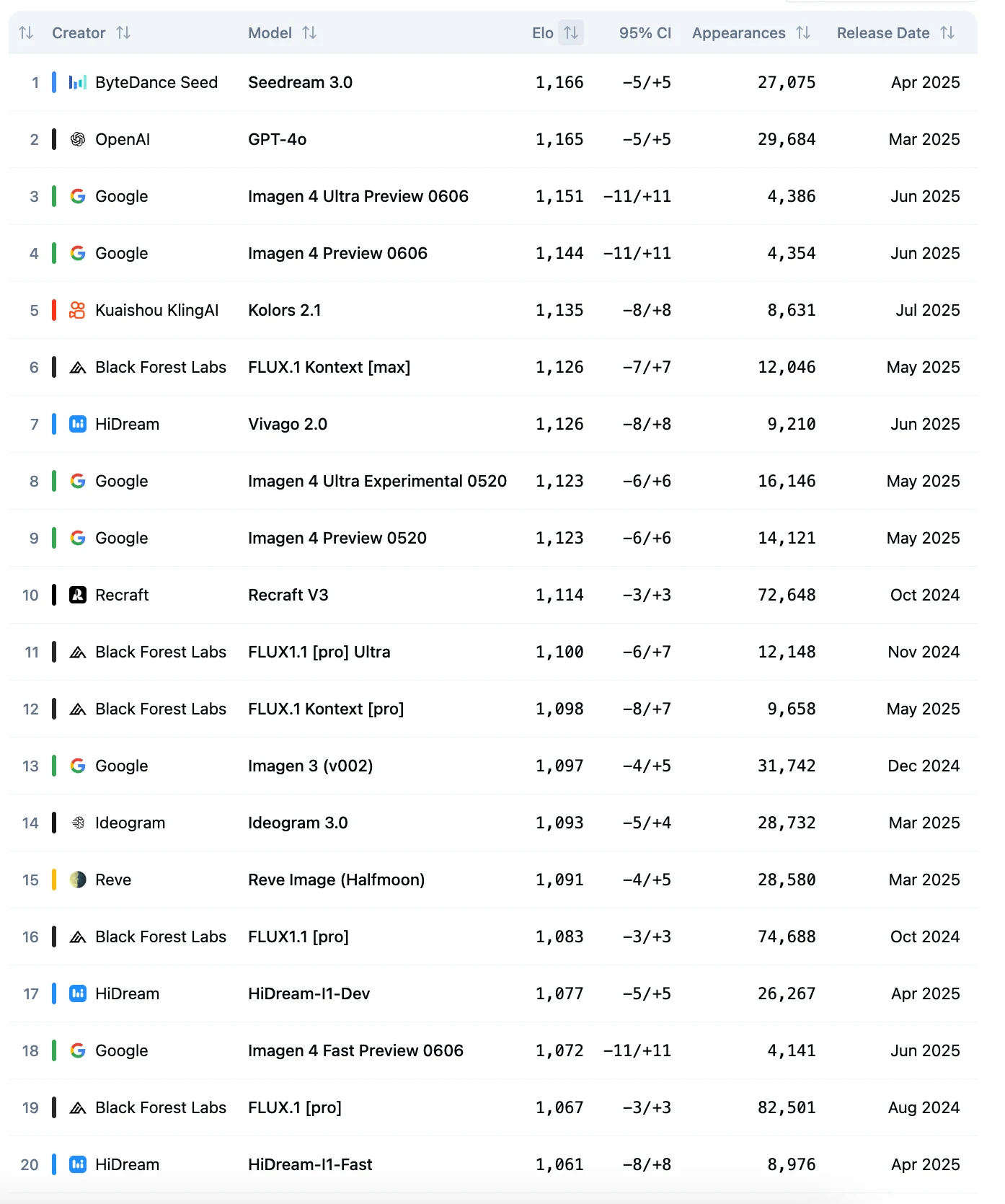
Seedream 3.0は、Artificial Analysis Image Arena リーダーボードで1位を獲得しています。
Seedream 3.0 vs Stable Diffusion
Seedream 3.0は、強力なスタイルプロンプトと優れた画質を備えたオールインワンの汎用モデルであり、技術的な設定なしで迅速でプロフェッショナルな結果を求めるユーザーに最適です。使いやすさ、スピード、多彩なスタイルを1つのパッケージで重視するなら、Seedream 3.0(Seedance Pro経由)は優れた選択肢です。
対照的に、Stable Diffusionはオープン性とモジュール性を重視しており、複数の手法を組み合わせたり、専門モデルを使用・訓練したり、豊富なツールや拡張機能のエコシステムを活用して高度にカスタマイズされた実験的なワークフローを実現できます。深いカスタマイズ、ニッチなスタイル、高度な編集パイプラインが必要な場合、Stable Diffusionのオープンなエコシステムは比類がありません。

Seedream 3.0

Stable Diffusion
Seedream 3.0 vs GPT 4o
Seedream 3.0とGPT-4oは、それぞれ「プロンプトイラストレーター」と「会話型デザイナー」と見なすことができます。Seedream 3.0は、適切に作成されたプロンプトから高速で高品質な画像を生成したい場合に優れており、強力で効率的、そして使いやすいです。GPT-4oは、よりガイド付きの反復的なクリエイティブワークフローで輝き、会話を通じて画像を段階的に洗練し、正確な要件を満たすことができます。
どちらのツールも、複雑または想像力豊かなアイデアをビジュアルに変換し、画像内のテキストや細部を処理し、最先端の画像忠実度を提供するのに優れています。ワークフローがチャットベースのアプローチ(画像を段階的に説明する、反復的に洗練する、クリエイティブプロセス全体でAIのコンテキスト記憶を活用するなど)の恩恵を受ける場合、GPT-4oは真に比類がありません。


Seedream 3.0 の使い方
ステップ1: ログインして モデルライブラリ にアクセス
アカウントにログインし、モデルライブラリ ボタンをクリックします。

ステップ2: モデルを選択
利用可能なオプションからニーズに合ったモデルを選択します。
ステップ3: API をインストール
プログラミング言語に適したパッケージマネージャーを使用してAPIをインストールします。
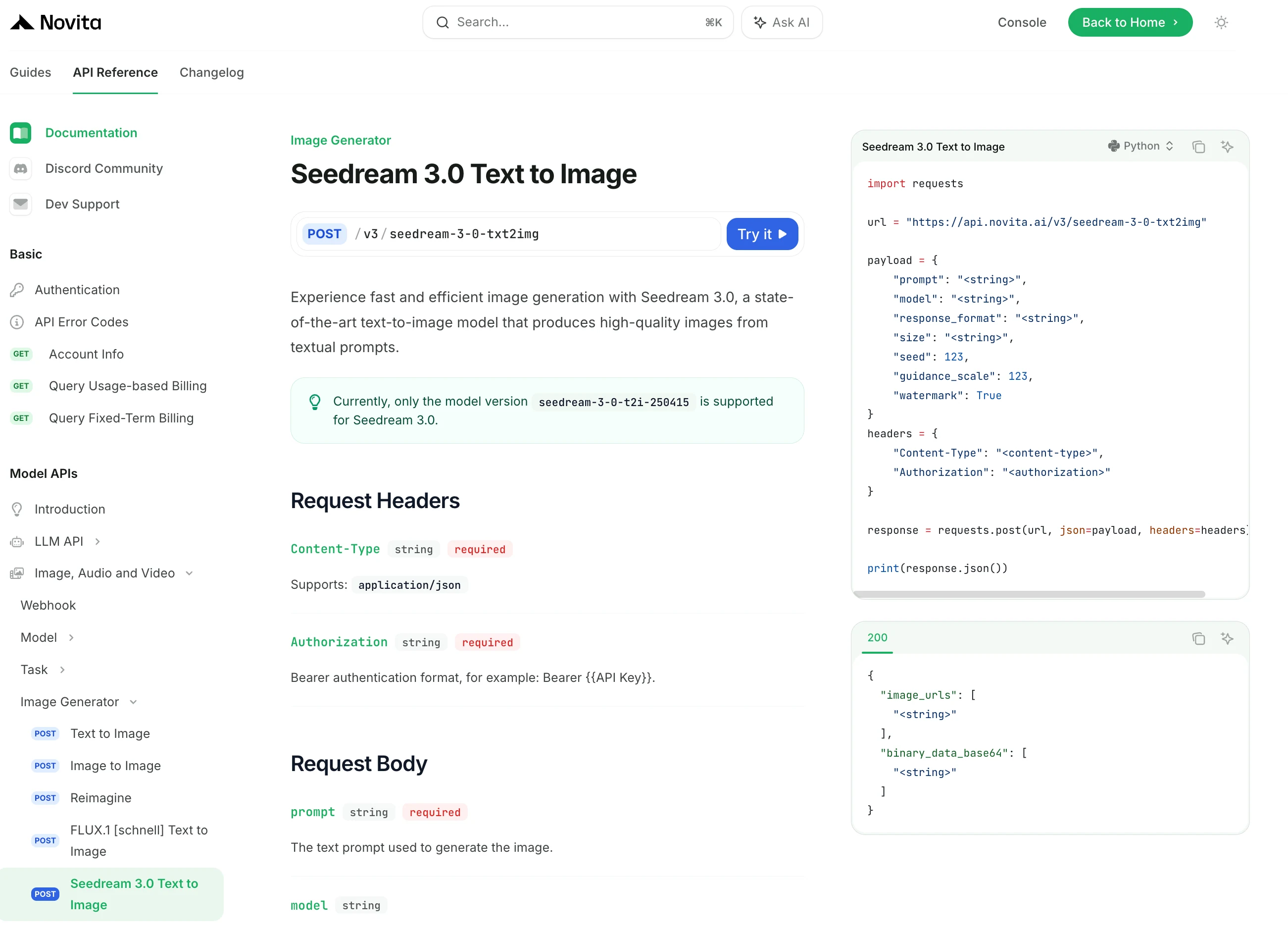
インストール後、必要なライブラリを開発環境にインポートします。APIキーを使用してAPIを初期化し、Novita AI LLMとの対話を開始します。これはPythonユーザー向けのチャット補完APIの使用例です。
リクエストヘッダー
1. Content-Type (文字列、必須)
- 説明: リクエストのコンテンツタイプを指定します。
application/jsonに設定する必要があります。 - 目的: サーバーがリクエストで送信されたデータ形式を正しく解析できるようにします。
2. Authorization (文字列、必須)
- 説明: 認証に使用され、Bearer トークン形式に従います。例:
Bearer {{API Key}}。 - 目的: リクエストがAPIにアクセスするために必要な権限を持っていることを確認します。
リクエストボディ
1. prompt (文字列、必須)
- 説明: 画像を生成するためのプロンプトとして使用されるテキスト入力。
- 目的: 画像生成の開始点として機能します。
2. model (文字列)
- 説明: リクエストのモデルIDまたは推論エンドポイント(エンドポイントID)を指定します。現在は
seedream-3-0-t2i-250415(Seedream 3.0)のみサポートされています。 - 目的: 画像生成に使用するAIモデルを決定します。
3. response_format (文字列)
- 説明: レスポンスで返される生成画像の形式を定義します。デフォルトは
url。- サポートされる値:
"url": ダウンロード可能なJPEG画像リンクを返します。"b64_json": 画像データをBase64エンコードされたJSON文字列として返します。
- サポートされる値:
- 目的: 生成画像の出力形式を指定します。
4. size (文字列)
- 説明: 生成画像の寸法を
幅 x 高さ(ピクセル)の形式で指定します。[512x512, 2048x2048]の範囲内である必要があります。デフォルトは1024x1024。- 推奨解像度とアスペクト比:
- 1:1 比率:
1024x1024 - 3:4 比率:
864x1152 - 4:3 比率:
1152x864 - 16:9 比率:
1280x720 - 9:16 比率:
720x1280 - 2:3 比率:
832x1248 - 3:2 比率:
1248x832 - 21:9 比率:
1512x648
- 1:1 比率:
- 推奨解像度とアスペクト比:
- 目的: 生成画像の解像度とアスペクト比を定義します。
5. seed (整数)
- 説明: 画像生成のランダム性を制御するための乱数シードを設定します。範囲:
[-1, 2147483647]。- デフォルト:
-1。自動でシードが生成されます。 - 同じシードを使用すると、同一の結果を再現できます。
- デフォルト:
- 目的: 出力のランダム性と再現性を制御します。
6. guidance_scale (数値)
- 説明: 生成画像が入力プロンプトにどの程度厳密に従うかを制御します。範囲:
[1, 10]。- デフォルト:
2.5。 - 値が高いほどプロンプトに厳密に従います(創造的自由度が低くなります)。
- デフォルト:
- 目的: モデルが入力説明にどれだけ強く従うかを調整します。
7. watermark (ブール値)
- 説明: 生成画像に透かしを追加するかどうかを指定します。
- デフォルト:
true。 - オプション:
false: 透かしなし。true: 右下隅に「AI生成」とラベルされた透かしを追加します。
- デフォルト:
- 目的: 生成コンテンツにAI生成であることをオプションでラベル付けすることで透明性を確保します。
レスポンス
1. image_urls (文字列[])
- 説明:
response_formatが"url"に設定されている場合、この配列には生成画像のダウンロード可能なリンクが含まれます。 - 目的: 生成画像へのオンラインアクセスパスを提供します。
2. binary_data_base64 (文字列[])
- 説明:
response_formatが"b64_json"に設定されている場合、この配列には生成画像がBase64エンコードされたJSON文字列として含まれます。 - 目的: ダウンロードなしで使用できる埋め込み画像データを提供します。
ステップ4: コード例
import requests
url = "https://api.novita.ai/v3/seedream-3-0-txt2img"
payload = {
"prompt": "<string>",
"model": "<string>",
"response_format": "<string>",
"size": "<string>",
"seed": 123,
"guidance_scale": 123,
"watermark": True
}
headers = {
"Content-Type": "<content-type>",
"Authorization": "<authorization>"
}
response = requests.post(url, json=payload, headers=headers)
print(response.json())
Seedream 3.0 は、高度な技術革新、手頃な価格、そして比類のない使いやすさを組み合わせることで、AI搭載画像生成の新たな基準を打ち立てました。1画像あたりわずか $0.03 で、技術的な専門知識に関わらず、誰でもアイデアを視覚的に見事なクリエイションに変えることができます。高速で高品質なビジュアル、またはシームレスなクリエイティブワークフローをお探しなら、Seedream 3.0 が最適なツールです。今すぐ Novita AI の Seedream 3.0 で、創造性の未来を体験してください!
よくある質問
Seedream 3.0 とは何ですか?
Seedream 3.0 は、Novita AI から提供される、英語と中国語のテキストプロンプトから 1画像あたりわずか $0.03 で高品質な画像を生成できる高度なテキスト画像生成AIモデルです。
Seedream 3.0 を開発したのは誰ですか?
Seedream 3.0 は、ByteDance の「Seed」画像生成シリーズの一部であり、Novita AI によって最新のテキスト画像生成機能を提供するために導入されました。
Seedream 3.0 の主な機能は何ですか?
バイリンガル対応: 英語と中国語のプロンプトの両方で動作します。
手頃な価格: 1画像あたりわずか $0.03 で生成できます。
技術革新: 強化されたデータセット、混合解像度トレーニング、最適化された事前トレーニングにより、速度、精度、画質が向上。
カスタマイズ: 柔軟な解像度オプション、プロンプト追従の制御、オプションの透かし設定。
Novita AI は、あなたのAIの野望を実現するオールインワンのクラウドプラットフォームです。統合API、サーバーレス、GPUインスタンス — コスト効率の良いツールを提供します。インフラストラクチャを排除し、無料で始めて、AIビジョンを現実にしましょう。



