

كشفت Novita AI النقاب عن Seedream 3.0، وهو نموذج ثوري لتحويل النص إلى صورة (T2I) يعيد تعريف الإمكانيات الإبداعية بتكلفة زهيدة تبلغ 0.03 دولار فقط لكل صورة. بصفته منتجًا رائدًا في سلسلة “Seed” من ByteDance، يجمع Seedream 3.0 بين التكنولوجيا المتطورة وسهولة الوصول، مع دعم ثنائي اللغة للإنجليزية والصينية.
Seedream 3.0: قدرات تحويل النص إلى صورة
Seedream 3.0 هو نموذج ذكاء اصطناعي متطور لتحويل النص إلى صورة تم تطويره بواسطة فريق الذكاء الاصطناعي في ByteDance. هذا النظام ثنائي اللغة (يدعم كلاً من المطالبات الصينية والإنجليزية) يُنشئ صورًا عالية الجودة مباشرة من الأوصاف النصية. وباعتباره الجيل الثالث من سلسلة “Seed” لتوليد الصور من ByteDance، ظهر Seedream 3.0 لأول مرة في أبريل 2025، مما يشير إلى دخول ByteDance الجدي في مجال توليد الصور بالذكاء الاصطناعي.
الميزات الجديدة في Seedream 3.0 (الإصدار 3.0)

الابتكارات التقنية في Seedream 3.0
1. طبقة البيانات: مجموعة بيانات أكبر وأكثر ذكاءً
- تم توسيع مجموعة بيانات التدريب بنسبة 100% تقريبًا.
- آلية أخذ عينات ديناميكية جديدة توازن بين:
- توزيع مجموعات الصور (أنواع صور متنوعة)
- التماسك الدلالي النصي (أزواج نص-صورة أكثر معنى وتناسقًا)
- التأثير: تعمل مجموعة البيانات الأكثر ثراءً وتوازنًا على تحسين قدرة النموذج على إنشاء صور متنوعة وعالية الدقة، واتباع مطالبات متنوعة بدقة أكبر.
2. تحسينات ما قبل التدريب
- تم إدخال تحسينات متعددة مقارنة بالإصدار 2.0:
- التدريب متعدد الدقة: يُمكن النموذج من التعامل مع الصور منخفضة وعالية الدقة بشكل أصلي، مما يدعم إخراج 2K حقيقي.
- تضمينات الوضع الدوارة (RoPE) عبر الأنماط: تحسن التوافق بين المعلومات البصرية والنصية، مما يدعم فهمًا أفضل للمطالبات وعرض النص.
- فقدان محاذاة التمثيل (Representation Alignment Loss): يضمن تطابق ميزات الصورة والنص بشكل أفضل، مما يساعد في تركيب الصور الواقعي وتضمين النص بدقة.
- أخذ عينات زمنية واعية بالدقة (Resolution-aware Timestep Sampling): يُصمم عملية الانتشار (diffusion) لمختلف الدقات، مما يعزز السرعة وجودة الصورة.
- التأثير: تجعل تحسينات ما قبل التدريب هذه Seedream 3.0 أكثر قابلية للتوسع والتعميم، وقادرًا على محاذاة بصرية-لغوية دقيقة.
3. تحسين ما بعد التدريب
- يستخدم تعليقات جمالية متنوعة ونظام مكافأة قائم على نموذج لغة-رؤية (VLM).
- التأثير: يُضبط النموذج بدقة ليعطي الأولوية للجاذبية البصرية والدقة الدلالية، مما يؤدي إلى صور أكثر جاذبية ودقة من حيث السياق.
4. تسريع النموذج
- يُطبق أخذ عينات مستقرة (stable sampling) عبر توقع ضوضاء ثابت، مما يقلل عدد تقييمات الدوال (function evaluations) المطلوبة أثناء الاستدلال.
- التأثير: هذا الابتكار هو المفتاح لتوليد الصور السريع، مما يتيح ردود فعل في الوقت الفعلي وتكرارًا إبداعيًا أسرع.
بدائل لـ Seedream 3.0 في تحويل النص إلى صورة
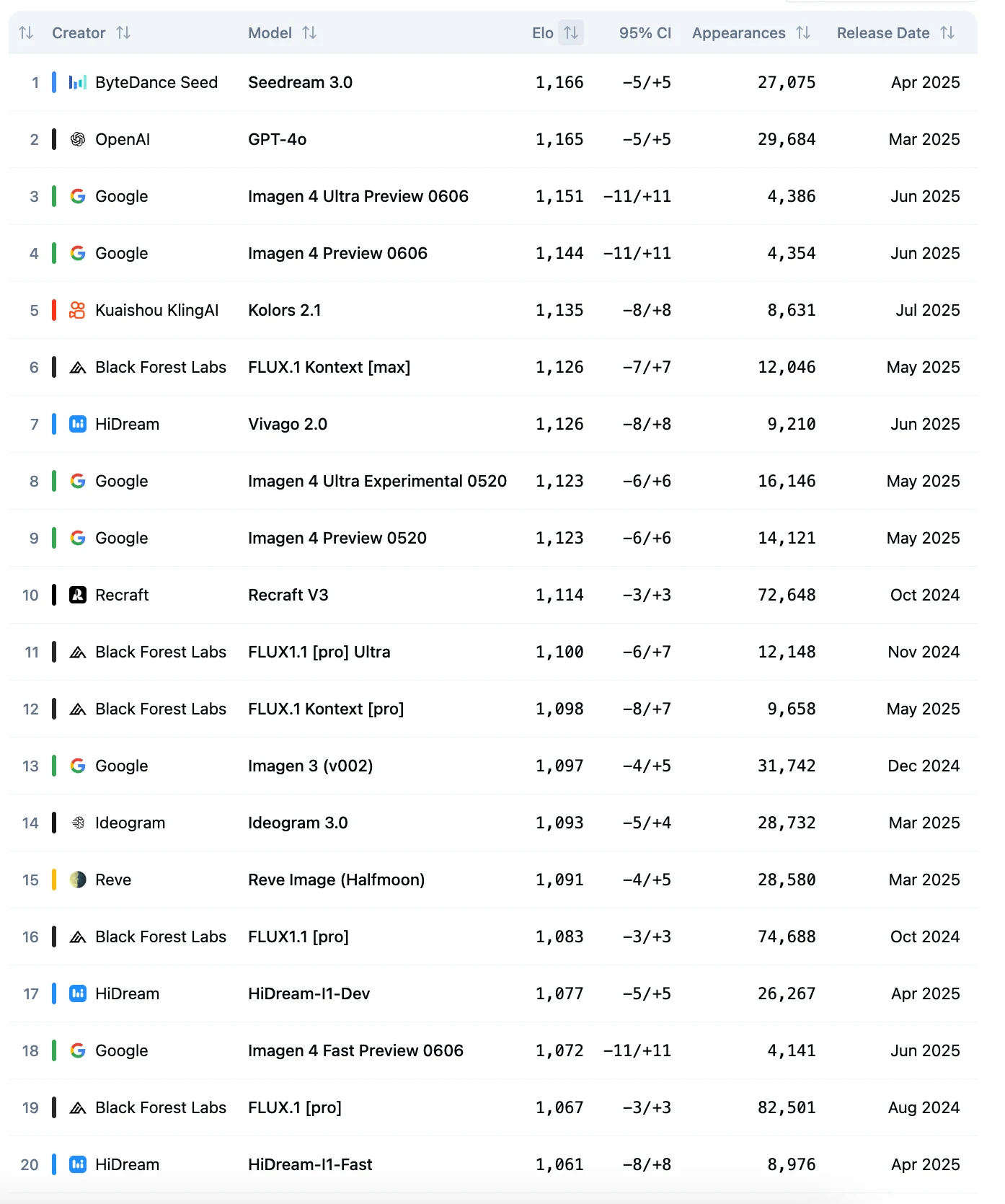
يحتل Seedream 3.0 المرتبة الأولى في لوحة متصدرات حلبة تحليل الصور الاصطناعية.
Seedream 3.0 مقابل Stable Diffusion
يُوفر Seedream 3.0 نموذجًا متكاملًا وشاملًا مع إمكانيات قوية في تصميم المطالبات وجودة صور مذهلة - مثالي للمستخدمين الذين يريدون نتائج سريعة واحترافية دون أي إعداد تقني. إذا كنت تُعطي الأولوية لسهولة الاستخدام والسرعة والأنماط المتنوعة في حزمة واحدة، فإن Seedream 3.0 (عبر Seedance Pro) هو خيار ممتاز.
في المقابل، يزدهر Stable Diffusion بفضل الانفتاح والوحدة النمطية، مما يسمح للمستخدمين بدمج تقنيات متعددة، واستخدام أو تدريب نماذج متخصصة، والوصول إلى نظام بيئي واسع من الأدوات والإضافات لسير عمل مخصصة للغاية أو تجريبية. إذا كنت بحاجة إلى تخصيص عميق أو أنماط متخصصة أو خطوط إنتاج تحرير متقدمة، فإن النظام البيئي المفتوح لـ Stable Diffusion لا يُضاهى.

Seedream 3.0

Stable Diffusion
Seedream 3.0 مقابل GPT-4o
يمكن اعتبار Seedream 3.0 و GPT-4o بمثابة رسّام مطالبات ومصمم حواري، على التوالي. يتفوق Seedream 3.0 عندما تريد صورًا سريعة وعالية الجودة من مطالبات مُصاغة جيدًا - إنه قوي وفعال وسهل الاستخدام. يتألق GPT-4o في سير العمل الإبداعي المُوجه والتكراري، مما يسمح لك بتحسين الصور خطوة بخطوة من خلال المحادثة والتأكد من أنها تلبي متطلباتك الدقيقة.
كلا الأداتين استثنائيتان في تحويل الأفكار المعقدة أو الخيالية إلى صور مرئية، والتعامل مع النص والتفاصيل الدقيقة في الصور، وتقديم دقة صور فائقة. إذا كانت سير عملك تستفيد من الأسلوب القائم على الدردشة - مثل وصف الصور على مراحل، أو تحسينها بشكل تكراري، أو الاستفادة من قدرة الذكاء الاصطناعي على تذكر السياق طوال العملية الإبداعية - فإن GPT-4o لا يُضاهى حقًا.


كيفية استخدام Seedream 3.0؟
الخطوة 1: تسجيل الدخول والوصول إلى مكتبة النماذج
سجل الدخول إلى حسابك وانقر على زر مكتبة النماذج.

الخطوة 2: اختر نموذجك
تصفح الخيارات المتاحة واختر النموذج الذي يناسب احتياجاتك.
الخطوة 3: تثبيت API
قم بتثبيت API باستخدام مدير الحزم الخاص بلغة البرمجة التي تستخدمها.
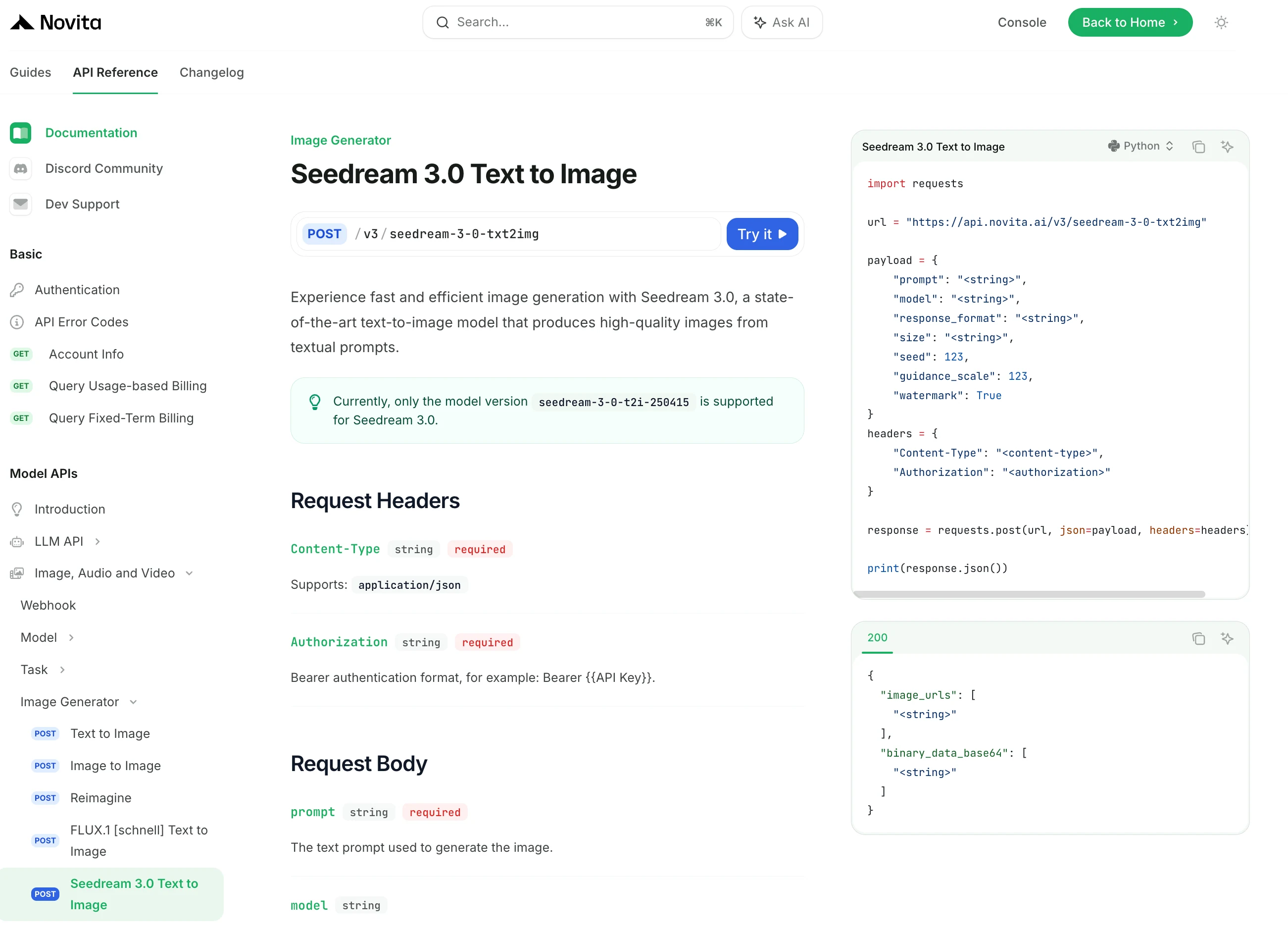
بعد التثبيت، قم باستيراد المكتبات اللازمة إلى بيئة التطوير الخاصة بك. قم بتهيئة API باستخدام مفتاح API الخاص بك لبدء التفاعل مع Novita AI LLM. هذا مثال لاستخدام chat completions API لمستخدمي بايثون.
رؤوس الطلب
1. Content-Type (string, مطلوب)
- الوصف: يُحدد نوع محتوى الطلب. يجب تعيينه إلى
application/json. - الغرض: يضمن قدرة الخادم على تحليل تنسيق البيانات المرسلة في الطلب بشكل صحيح.
2. Authorization (string, مطلوب)
- الوصف: يُستخدم للمصادقة، باتباع تنسيق رمز Bearer. مثال:
Bearer {{API Key}}. - الغرض: يتحقق من أن الطلب لديه الأذونات اللازمة للوصول إلى API.
جسم الطلب
1. prompt (string, مطلوب)
- الوصف: الإدخال النصي المستخدم كمطالبة لتوليد الصورة.
- الغرض: يعمل كنقطة بداية لتوليد الصورة.
2. model (string)
- الوصف: يُحدد معرف النموذج أو نقطة نهاية الاستدلال (Endpoint ID) للطلب. يُدعم حاليًا فقط
seedream-3-0-t2i-250415(Seedream 3.0). - الغرض: يُحدد نموذج الذكاء الاصطناعي المستخدم لتوليد الصورة.
3. response_format (string)
- الوصف: يُحدد تنسيق الصورة المُنشأة المرتجعة في الرد. الافتراضي هو
url.- القيم المدعومة:
"url": يُرجع رابط صورة JPEG قابلة للتنزيل."b64_json": يُرجع بيانات الصورة كسلسلة JSON مشفرة بـ Base64.
- القيم المدعومة:
- الغرض: يُحدد تنسيق إخراج الصورة المُنشأة.
4. size (string)
- الوصف: يُحدد أبعاد الصورة المُنشأة بتنسيق
العرض × الارتفاع(بالبكسل). يجب أن تكون بين[512x512, 2048x2048]. الافتراضي هو1024x1024.- الدقات ونسب الأبعاد الموصى بها:
- نسبة 1:1:
1024x1024 - نسبة 3:4:
864x1152 - نسبة 4:3:
1152x864 - نسبة 16:9:
1280x720 - نسبة 9:16:
720x1280 - نسبة 2:3:
832x1248 - نسبة 3:2:
1248x832 - نسبة 21:9:
1512x648
- نسبة 1:1:
- الدقات ونسب الأبعاد الموصى بها:
- الغرض: يُحدد دقة ونسبة أبعاد الصورة المُنشأة.
5. seed (integer)
- الوصف: يُحدد البذرة العشوائية للتحكم في العشوائية في توليد الصورة. النطاق:
[-1, 2147483647].- الافتراضي:
-1، مما يعني إنشاء بذرة تلقائيًا. - استخدم نفس البذرة لإعادة إنتاج نتائج متطابقة.
- الافتراضي:
- الغرض: يتحكم في العشوائية وقابلية إعادة إنتاج المخرجات.
6. guidance_scale (number)
- الوصف: يتحكم في مدى توافق الصورة المُنشأة مع المطالبة المدخلة. النطاق:
[1, 10].- الافتراضي:
2.5. - القيم الأعلى = التزام أكثر صرامة بالمطالبة (حرية إبداعية أقل).
- الافتراضي:
- الغرض: يُعدل قوة متابعة النموذج للوصف المدخل.
7. watermark (boolean)
- الوصف: يُحدد ما إذا كان يجب إضافة علامة مائية إلى الصورة المُنشأة.
- الافتراضي:
true. - الخيارات:
false: بدون علامة مائية.true: يُضيف علامة مائية مكتوب عليها “AI generated” في الزاوية اليمنى السفلية.
- الافتراضي:
- الغرض: يضمن الشفافية في المحتوى المُنشأ عن طريق وضع علامة اختيارية عليه كمنتج ذكاء اصطناعي.
الرد
1. image_urls (string[])
- الوصف: عندما يتم تعيين
response_formatإلى"url"، تحتوي هذه المصفوفة على روابط صور قابلة للتنزيل للصور المُنشأة. - الغرض: يُوفر مسار وصول عبر الإنترنت إلى الصور المُنشأة.
2. binary_data_base64 (string[])
- الوصف: عندما يتم تعيين
response_formatإلى"b64_json"، تحتوي هذه المصفوفة على الصور المُنشأة كسلاسل JSON مشفرة بـ Base64. - الغرض: يُوفر بيانات صورة مضمنة لاستخدامها دون تنزيل.
الخطوة 4: مثال على الكود
import requests
url = "https://api.novita.ai/v3/seedream-3-0-txt2img"
payload = {
"prompt": "<string>",
"model": "<string>",
"response_format": "<string>",
"size": "<string>",
"seed": 123,
"guidance_scale": 123,
"watermark": True
}
headers = {
"Content-Type": "<content-type>",
"Authorization": "<authorization>"
}
response = requests.post(url, json=payload, headers=headers)
print(response.json())
يُحدد Seedream 3.0 معيارًا جديدًا لتوليد الصور بالذكاء الاصطناعي من خلال الجمع بين الابتكارات التقنية المتقدمة والقدرة على تحمل التكاليف وسهولة الاستخدام التي لا مثيل لها. بسعر 0.03 دولار فقط لكل صورة، فإنه يُمكن أي شخص من تحويل الأفكار إلى إبداعات بصرية مذهلة، بغض النظر عن الخبرة الفنية. سواء كنت تبحث عن صور سريعة وعالية الجودة أو سير عمل إبداعي سلس، فإن Seedream 3.0 هو أداتك المثلى. اختبر مستقبل الإبداع مع Novita AI’s Seedream 3.0 اليوم!
الأسئلة الشائعة
ما هو Seedream 3.0؟
Seedream 3.0 هو نموذج ذكاء اصطناعي متقدم لتحويل النص إلى صورة، يُمكن المستخدمين من إنشاء صور عالية الجودة من مطالبات نصية باللغتين الإنجليزية والصينية مقابل 0.03 دولار فقط لكل صورة من Novita AI.
من طور Seedream 3.0؟
Seedream 3.0 هو جزء من سلسلة توليد الصور “Seed” من ByteDance، تم تقديمه بواسطة Novita AI لتقديم إمكانيات متطورة لتحويل النص إلى صورة.
ما هي الميزات الرئيسية لـ Seedream 3.0؟
دعم ثنائي اللغة: يعمل مع المطالبات باللغتين الإنجليزية والصينية.
أسعار معقولة: يُنشئ صورًا مقابل 0.03 دولار فقط لكل صورة.
ابتكارات تقنية: مجموعات بيانات محسّنة، تدريب متعدد الدقة، وتحسين ما قبل التدريب لسرعة ودقة وجودة صورة أفضل.
تخصيص: خيارات دقة مرنة، التحكم في الالتزام بالمطالبة، وعلامة مائية اختيارية.
Novita AI هي منصة سحابية شاملة تُعزز طموحاتك في الذكاء الاصطناعي. واجهات برمجة تطبيقات متكاملة، بدون خادم، مثيل GPU — الأدوات الفعالة من حيث التكلفة التي تحتاجها. تخلص من البنية التحتية، ابدأ مجانًا، واجعل رؤيتك للذكاء الاصطناعي حقيقة واقعة.



