

Novita AI a dévoilé Seedream 3.0, un modèle d’IA de texte vers image révolutionnaire qui redéfinit les possibilités créatives à un coût abordable de seulement 0,03 $ par image. En tant que produit phare de la série « Seed » de ByteDance, Seedream 3.0 combine une technologie de pointe avec une accessibilité, offrant un support bilingue pour les invites en anglais et en chinois.
Seedream 3.0 : Capacités de texte vers image
Seedream 3.0 est un modèle d’IA de texte vers image de pointe développé par l’équipe IA de ByteDance. Ce système bilingue (prenant en charge les invites en chinois et en anglais) génère des images de haute qualité directement à partir de descriptions textuelles. En tant que troisième génération de la série « Seed » de ByteDance pour la génération d’images, Seedream 3.0 a fait ses débuts en avril 2025, marquant l’entrée sérieuse de ByteDance dans le domaine de la génération d’images par IA.
Nouvelles fonctionnalités de Seedream 3.0 dans la version 3.0

Innovations techniques de Seedream 3.0
1. Couche de données : Un jeu de données plus grand et plus intelligent
- Le jeu de données d’entraînement a été élargi d’environ 100 %.
- Un nouveau mécanisme d’échantillonnage dynamique équilibre :
- La distribution des clusters d’images (types d’images diversifiés)
- La cohérence sémantique textuelle (paires texte-image plus significatives et bien adaptées)
- Impact : Ce jeu de données plus riche et mieux équilibré améliore la capacité du modèle à générer des images variées et de haute fidélité, ainsi qu’à suivre des invites diverses avec plus de précision.
2. Améliorations du pré-entraînement
- Plusieurs améliorations par rapport à la version 2.0 :
- Entraînement à résolution mixte : Permet au modèle de traiter et de générer des images basse et haute résolution de manière native, offrant une véritable sortie 2K.
- RoPE (Rotary Position Embeddings) inter-modalités : Améliore l’alignement entre les informations visuelles et textuelles, permettant une meilleure compréhension des invites et un rendu de texte amélioré.
- Perte d’alignement de représentation : Assure que les caractéristiques des images et du texte sont mieux adaptées, facilitant une composition d’image réaliste et un encodage précis du texte.
- Échantillonnage de pas de temps tenant compte de la résolution : Adapte le processus de diffusion à différentes résolutions, améliorant à la fois la vitesse et la qualité d’image.
- Impact : Ces modifications du pré-entraînement rendent Seedream 3.0 plus évolutif, généralisable et capable d’un alignement fin visuel-langage.
3. Optimisation post-entraînement
- Utilise des légendes esthétiques diversifiées et un système de récompense basé sur un modèle de langage visuel (VLM).
- Impact : Ajuste le modèle pour prioriser l’attrait visuel et la précision sémantique, conduisant à des images plus attrayantes et contextuellement exactes.
4. Accélération du modèle
- Implémente un échantillonnage stable via une attente de bruit cohérente, ce qui réduit le nombre d’évaluations de fonction nécessaires lors de l’inférence.
- Impact : Cette innovation est essentielle pour la génération rapide d’images du modèle, permettant un retour en temps réel et une itération créative plus rapide.
Alternatives à Seedream 3.0 pour le T2I
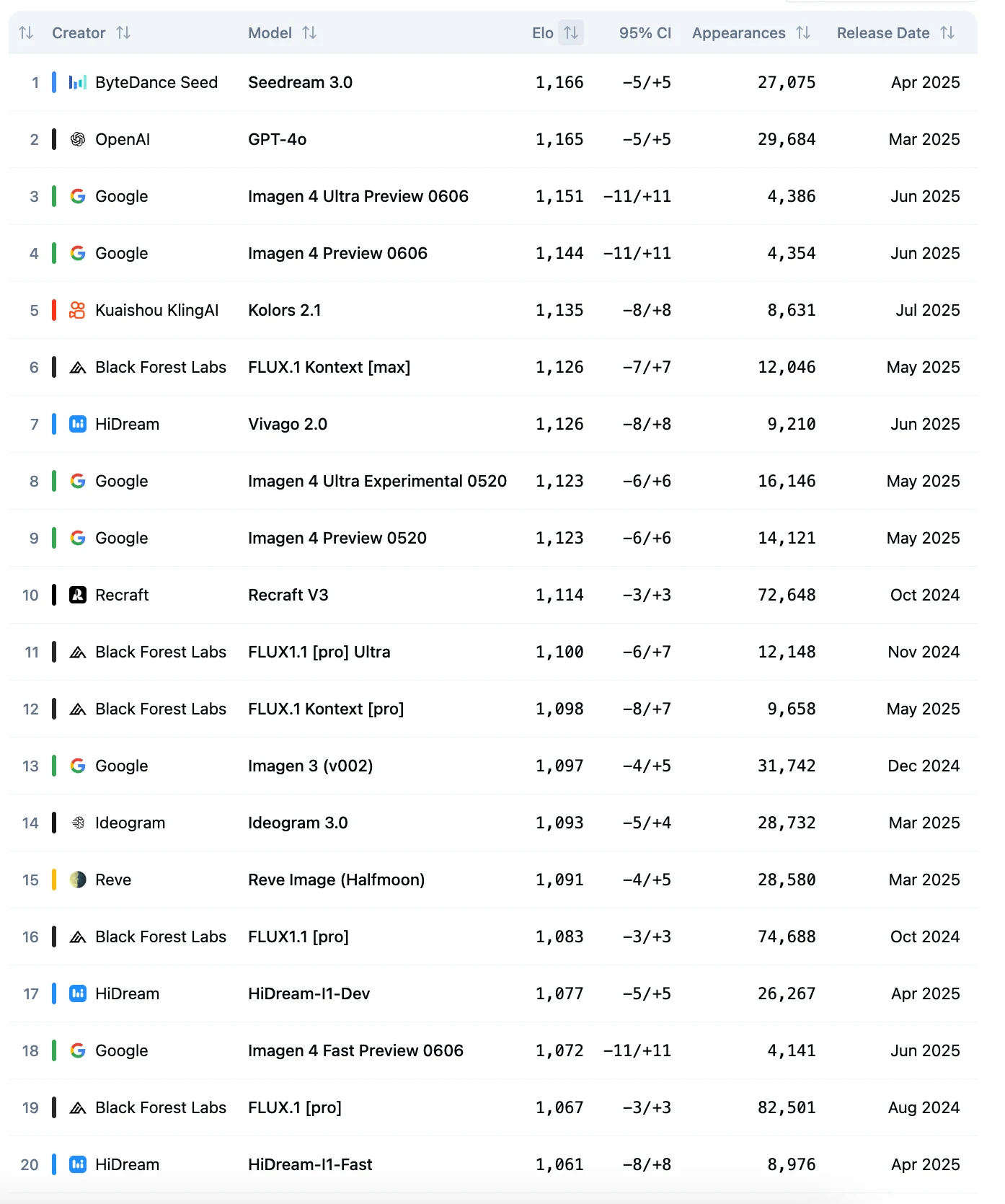
Seedream 3.0 se classe premier dans le classement Artificial Analysis Image Arena.
Seedream 3.0 vs Stable Diffusion
Seedream 3.0 offre un modèle tout-en-un et généralisé avec un puissant guidage par style et une qualité d’image exceptionnelle — parfait pour les utilisateurs qui souhaitent des résultats rapides et professionnels sans aucune configuration technique. Si vous privilégiez la facilité d’utilisation, la rapidité et la polyvalence des styles dans un seul package, Seedream 3.0 (via Seedance Pro) est un excellent choix.
En revanche, Stable Diffusion repose sur l’ouverture et la modularité, permettant aux utilisateurs de combiner plusieurs techniques, d’utiliser ou d’entraîner des modèles spécialisés, et d’exploiter un vaste écosystème d’outils et d’extensions pour des flux de travail hautement personnalisés ou expérimentaux. Si vous avez besoin d’une personnalisation poussée, de styles de niche ou de pipelines d’édition avancés, l’écosystème ouvert de Stable Diffusion est inégalé.

Seedream 3.0

Stable Diffusion
Seedream 3.0 vs GPT 4o
Seedream 3.0 et GPT-4o peuvent être considérés respectivement comme un illustrateur d’invites et un concepteur conversationnel. Seedream 3.0 excelle lorsque vous souhaitez des images rapides et de haute qualité à partir d’invites bien formulées — il est puissant, efficace et facile à utiliser. GPT-4o brille dans des flux de travail créatifs plus guidés et itératifs, vous permettant d’affiner les images étape par étape par la conversation et de garantir qu’elles répondent à vos besoins précis.
Les deux outils sont exceptionnels pour transformer des idées complexes ou imaginatives en visuels, gérer le texte et les détails fins dans les images, et offrir une fidélité d’image de pointe. Si votre flux de travail bénéficie d’une approche basée sur la conversation — comme décrire les images par étapes, les affiner de manière itérative, ou exploiter la capacité de l’IA à se souvenir du contexte tout au long du processus créatif — GPT-4o est vraiment inégalé.


Comment utiliser Seedream 3.0 ?
Étape 1 : Connectez-vous et accédez à la bibliothèque de modèles
Connectez-vous à votre compte et cliquez sur le bouton Bibliothèque de modèles.

Essayez Seedream 3.0 maintenant !
Étape 2 : Choisissez votre modèle
Parcourez les options disponibles et sélectionnez le modèle qui correspond à vos besoins.
Étape 3 : Installez l’API
Installez l’API à l’aide du gestionnaire de paquets spécifique à votre langage de programmation.
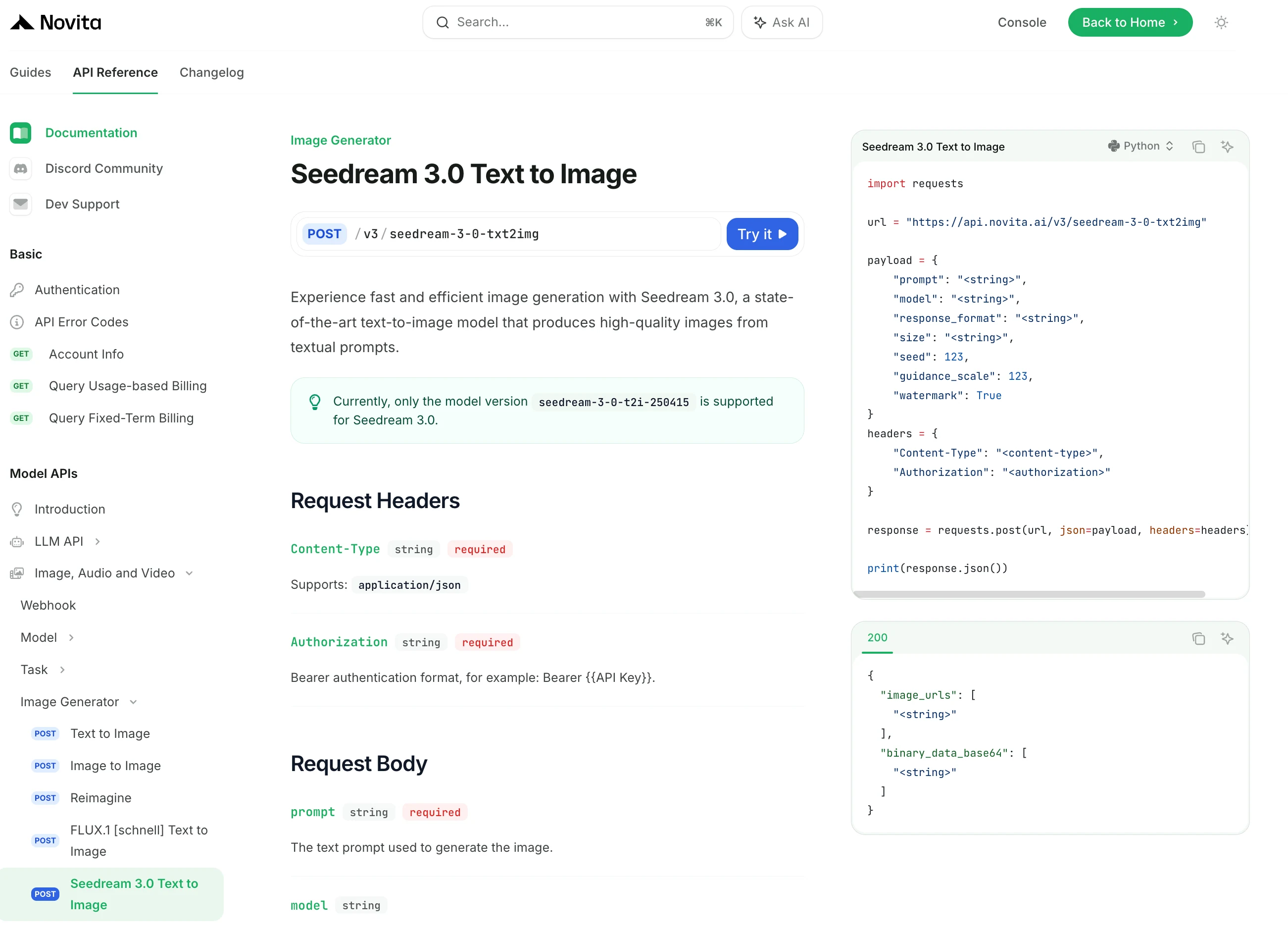
Après l’installation, importez les bibliothèques nécessaires dans votre environnement de développement. Initialisez l’API avec votre clé API pour commencer à interagir avec Novita AI LLM. Voici un exemple d’utilisation de l’API de complétion de chat pour les utilisateurs Python.
En-têtes de requête
1. Content-Type (chaîne, obligatoire)
- Description : Spécifie le type de contenu de la requête. Doit être défini sur
application/json. - Objectif : Garantit que le serveur peut analyser correctement le format de données envoyé dans la requête.
2. Authorization (chaîne, obligatoire)
- Description : Utilisé pour l’authentification, suit le format jeton Bearer. Exemple :
Bearer {{API Key}}. - Objectif : Vérifie que la requête dispose des autorisations nécessaires pour accéder à l’API.
Corps de la requête
1. prompt (chaîne, obligatoire)
- Description : L’entrée textuelle utilisée comme invite pour générer l’image.
- Objectif : Sert de point de départ pour la génération de l’image.
2. model (chaîne)
- Description : Spécifie l’ID du modèle ou le point de terminaison d’inférence (Endpoint ID) pour la requête. Actuellement, seul
seedream-3-0-t2i-250415(Seedream 3.0) est pris en charge. - Objectif : Détermine le modèle d’IA utilisé pour la génération d’images.
3. response_format (chaîne)
- Description : Définit le format de l’image générée renvoyée dans la réponse. Par défaut :
url.- Valeurs prises en charge :
"url": Renvoie un lien d’image JPEG téléchargeable."b64_json": Renvoie les données de l’image sous forme de chaîne JSON encodée en Base64.
- Valeurs prises en charge :
- Objectif : Spécifie le format de sortie de l’image générée.
4. size (chaîne)
- Description : Spécifie les dimensions de l’image générée au format
largeur x hauteur(en pixels). Doit être comprise entre[512x512, 2048x2048]. Par défaut :1024x1024.- Résolutions et rapports d’aspect recommandés :
- Rapport 1:1 :
1024x1024 - Rapport 3:4 :
864x1152 - Rapport 4:3 :
1152x864 - Rapport 16:9 :
1280x720 - Rapport 9:16 :
720x1280 - Rapport 2:3 :
832x1248 - Rapport 3:2 :
1248x832 - Rapport 21:9 :
1512x648
- Rapport 1:1 :
- Résolutions et rapports d’aspect recommandés :
- Objectif : Définit la résolution et le rapport d’aspect de l’image générée.
5. seed (entier)
- Description : Définit la graine aléatoire pour contrôler la stochasticité dans la génération d’images. Plage :
[-1, 2147483647].- Par défaut :
-1, ce qui signifie qu’une graine sera automatiquement générée. - Utilisez la même graine pour reproduire des résultats identiques.
- Par défaut :
- Objectif : Contrôle le caractère aléatoire et la reproductibilité de la sortie.
6. guidance_scale (nombre)
- Description : Contrôle la fidélité de l’image générée par rapport à l’invite de saisie. Plage :
[1, 10].- Par défaut :
2.5. - Des valeurs plus élevées = adhésion plus stricte à l’invite (moins de liberté créative).
- Par défaut :
- Objectif : Ajuste la force avec laquelle le modèle suit la description d’entrée.
7. watermark (booléen)
- Description : Spécifie s’il faut ajouter un filigrane à l’image générée.
- Par défaut :
true. - Options :
false: Pas de filigrane.true: Ajoute un filigrane marqué « AI generated » dans le coin inférieur droit.
- Par défaut :
- Objectif : Garantit la transparence du contenu généré en étiquetant éventuellement l’image comme générée par IA.
Réponse
1. image_urls (string[])
- Description : Lorsque
response_formatest défini sur"url", ce tableau contient des liens d’image téléchargeables pour les images générées. - Objectif : Fournit un chemin d’accès en ligne aux images générées.
2. binary_data_base64 (string[])
- Description : Lorsque
response_formatest défini sur"b64_json", ce tableau contient les images générées sous forme de chaînes JSON encodées en Base64. - Objectif : Fournit des données d’image intégrées pour une utilisation sans téléchargement.
Étape 4 : Exemple de code
import requests
url = "https://api.novita.ai/v3/seedream-3-0-txt2img"
payload = {
"prompt": "<string>",
"model": "<string>",
"response_format": "<string>",
"size": "<string>",
"seed": 123,
"guidance_scale": 123,
"watermark": True
}
headers = {
"Content-Type": "<content-type>",
"Authorization": "<authorization>"
}
response = requests.post(url, json=payload, headers=headers)
print(response.json())
Seedream 3.0 établit une nouvelle norme pour la génération d’images par IA en combinant innovations techniques avancées, accessibilité financière et facilité d’utilisation inégalée. À seulement 0,03 $ par image, il permet à chacun de transformer des idées en créations visuellement saisissantes, quel que soit son niveau d’expertise technique. Que vous cherchiez des visuels rapides et de haute qualité ou un flux de travail créatif fluide, Seedream 3.0 est votre outil ultime. Vivez l’avenir de la créativité avec Novita AI Seedream 3.0 dès aujourd’hui !
Foire aux questions
Qu’est-ce que Seedream 3.0 ?
Seedream 3.0 est un modèle d’IA avancé de texte vers image, permettant aux utilisateurs de générer des images de haute qualité à partir d’invites textuelles en anglais et en chinois pour seulement 0,03 $ par image depuis Novita AI.
Qui a développé Seedream 3.0 ?
Seedream 3.0 fait partie de la série « Seed » de ByteDance pour la génération d’images, introduite par Novita AI pour offrir des capacités de texte vers image de pointe.
Quelles sont les principales fonctionnalités de Seedream 3.0 ?
Support bilingue : Fonctionne avec des invites en anglais et en chinois.
Tarification abordable : Générez des images pour seulement 0,03 $ chacune.
Innovations techniques : Jeux de données améliorés, entraînement à résolution mixte et pré-entraînement optimisé pour une meilleure vitesse, précision et qualité d’image.
Personnalisation : Options de résolution flexibles, contrôle de l’adhésion à l’invite et filigrane optionnel.
Novita AI est la plateforme cloud tout-en-un qui propulse vos ambitions IA. API intégrées, serverless, instances GPU — les outils rentables dont vous avez besoin. Éliminez l’infrastructure, commencez gratuitement et faites de votre vision IA une réalité.



