

主なポイント
A6000 = 成熟、安定、レガシーワークロードに適している。
L40S = 将来性があり、FP8対応、LLMや生成AI、高度なシミュレーションに最適。
Novita AI では現在、L40Sをわずか $0.55/時間 で提供しています。これはRunPodの約半分の価格です。今すぐNovita AIをお試しください!

Novita AI

Runpod
Novita AIでL40Sを使用するコストは、RunPodの約半分です。
巨大なTransformerモデルをトレーニングしたり、高忠実度の3Dシーンをレンダリングしたり、本番環境で低レイテンシの推論を実行していると想像してください。NVIDIAのサイトにアクセスすると、CUDAコア、Tensorコア、RTコア、メモリ帯域幅、消費電力などの仕様の壁に直面します。混乱しますよね?
GPUを間違えると、プロジェクトが遅延し、多額の費用を無駄にする可能性があります。この記事では、NVIDIA A6000とL40Sをわかりやすく比較し、賢く選んで推測ではなく構築に集中できるようにします。
A6000 vs L40s:アーキテクチャ比較
CUDAコア – GPUの筋肉
ポイント: コアが多いほど並列処理性能が高く、トレーニングやレンダリングが高速化します。
- A6000: 10,752コア(Ampere)。FP32ワークロードに優れ、汎用的なタスクに信頼性があります。
- L40S: 18,176コア(Ada Lovelace)。より多く、より優れています。特に新しいTensorコアと組み合わせると効果的です。
Tensorコア – AI専用エンジン
ポイント: FP8により、L40Sは現代のAIワークロードで大きな優位性を持ちます。
- A6000: 第3世代Tensorコア、FP16およびTF32をサポート。
- L40S: 第4世代コア、FP8サポートと効率的なスパーシティを追加。FP8はLLMや拡散モデルのトレーニングに不可欠です。
RTコア – リアルなレンダリング
ポイント: リアリズムが重要な場合、L40Sが勝利。
- A6000: 84個の第2世代RTコア。
- L40S: 142個の第3世代RTコア。VR、アニメーション、シミュレーションに優れています。
メモリ
ポイント: 容量は同じですが、L40Sはデータ転送が高速で、大規模モデルに最適です。
どちらも 48 GB GDDR6 を搭載していますが、L40Sは ** 帯域幅が高い**(1 TB/s 対 768 GB/s)。
L40s vs A6000:コスト比較
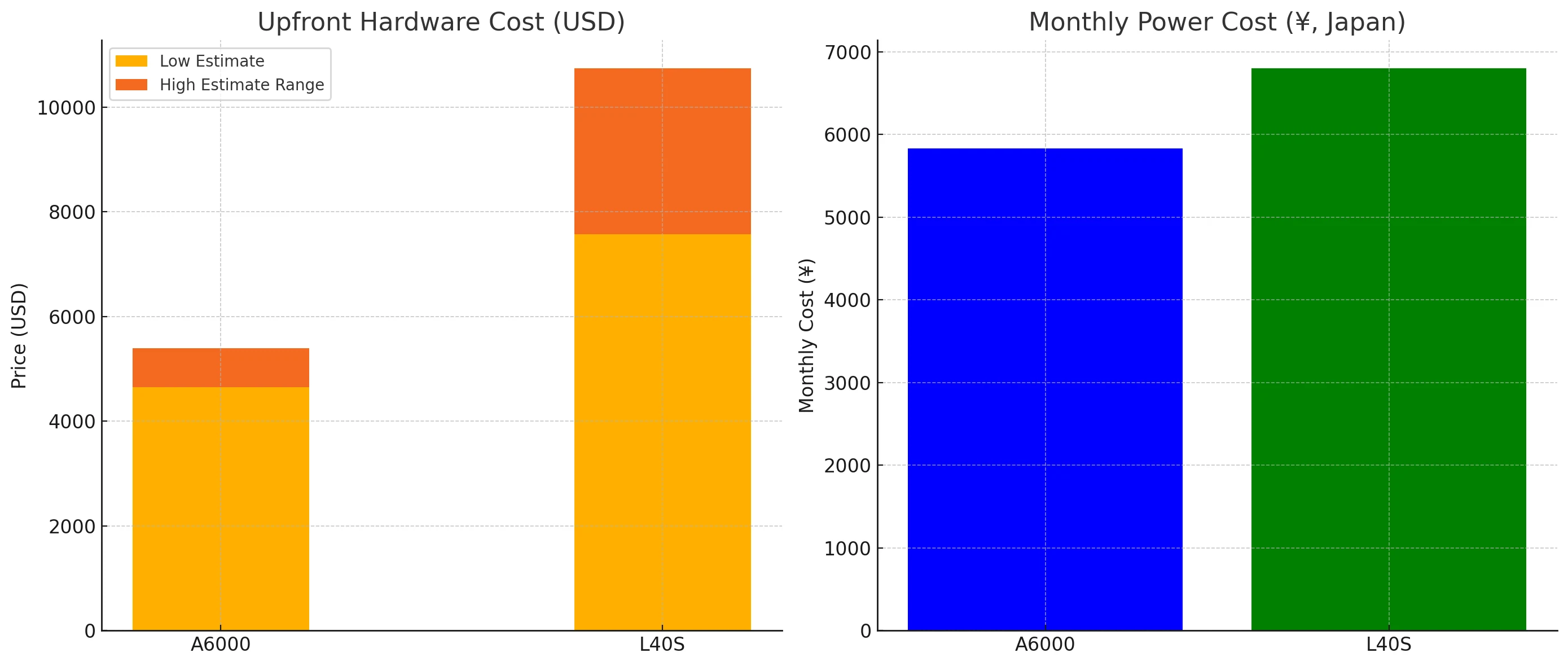
冷却とインフラストラクチャのコスト
- L40S は発熱量が多く、アップグレードされたサーバーラック、電源、冷却システムが必要です。
- A6000 は従来のワークステーションに最小限のアップグレードで導入しやすいです。
導入とメンテナンス
- L40S は、NVLinkブリッジ、ドライバのチューニング、最適化されたネットワーキングなど、データセンタークラスの統合が必要になることが多いです。
- A6000 はデスクトップワークステーションにスムーズにインストールでき、単独開発者や小規模チームにとって扱いやすいです。
A6000 vs L40s:アプリケーションシナリオ
1. 大規模言語モデル(LLM)のトレーニング
L40Sを選択
- L40Sは、LLMや生成モデル(GPTスタイルのアーキテクチャ、拡散モデルなど)といった現代のAIニーズに特化して設計されています。
- ネイティブの **FP8サポート 、 より高いメモリ帯域幅 **、より多くの Tensorコア により、トレーニング時間と計算コストを大幅に削減します。
2. リアルタイムレンダリング、ゲーム、メタバース開発
L40Sを選択
- L40Sは 第3世代RTコア を搭載し、リアルタイムレイトレーシング、高忠実度VFX、没入型VR/AR環境に最適です。
- より高速なレンダリングとスムーズなシーンシミュレーションを実現します。
3. 医用画像処理と科学シミュレーション
両方を検討
- A6000 は、ヘルスケアや科学計算におけるメモリ集約型のワークロードに対して、依然として強力で安定した選択肢です。
- L40S は、CUDAコア数の多さとメモリスループットの速さにより、同じワークロードをより高速に処理できます。
4. 従来のディープラーニングとデータサイエンス
規模に応じてA6000またはL40Sを選択
- A6000は、CNN、RNN、表形式ML、汎用的なタスクを容易に処理できる汎用性の高いGPUです。
- L40Sは、大規模データセット 、 バッチ推論、高解像度入力処理において優れたパフォーマンスを発揮します。
L40Sを非常に低価格で利用する方法
ステップ1:アカウント登録
ウェブサイトからNovita AIアカウントを作成します。登録後、左サイドバーの「Explore」セクションに移動して、GPUの提供内容を確認し、AI開発の旅を始めましょう。

ステップ2:テンプレートとGPUサーバーの探索
プロジェクトのニーズに合ったPyTorch、TensorFlow、CUDAなどのテンプレートを選択します。次に、希望するGPU構成を選択します。オプションには、強力なL40S、RTX 4090、A100 SXM4などがあり、それぞれVRAM、RAM、ストレージの仕様が異なります。

ステップ3:デプロイメントのカスタマイズ
好みのオペレーティングシステムと構成オプションを選択して環境をカスタマイズし、特定のAIワークロードと開発ニーズに最適なパフォーマンスを確保します。

ステップ4:インスタンスの起動
「Launch Instance」を選択してデプロイを開始します。数分で高性能なGPU環境が準備でき、機械学習、レンダリング、計算プロジェクトをすぐに開始できます。
どちらのGPUも優れています。しかし、ハードウェアは始まりに過ぎません。本当の成功は、計算リソースを効率的に使用することから生まれます。Novita AIは、完全に管理されスケーラブルなクラウドベースのL40Sパフォーマンスを提供し、より速く構築し、より賢く費用を使い、常に先を行くことを可能にします。
よくある質問
L40SはA6000の完全な代替品ですか?
完全にはそうではありません。L40SはAI/LLMに優れていますが、A6000は従来のグラフィックスや計算処理でも十分に機能します。
A6000は今でも購入する価値がありますか?
はい。CAD、VFX、FP8以外のAIタスクには依然として有効です。予算が限られている場合、A6000は堅実な選択肢です。ただし、LLMや将来のワークロードにはL40Sの方が投資価値が高いです。
なぜ自分でGPUを購入する代わりに Novita AI を使うべきですか?
- ハードウェアのセットアップやメンテナンスが不要
- 従量課金制
- 常に最新のインフラストラクチャ
- 簡単なスケーリング
- プロフェッショナルサポート
Novita AI は、開発者がシンプルなAPIを使ってAIモデルを簡単にデプロイできるAIクラウドプラットフォームであり、手頃で信頼性の高いGPUクラウドを構築・拡張するために提供しています。
おすすめの記事



