

Novita AI は「Build Month」キャンペーンを開始し、開発者に全主要製品で最大 20% オフの限定インセンティブを提供しています!
マルチモーダルエージェントや複雑なワークフローを構築する開発者は、単一のモデルがどのように画像、ドキュメント、UI 状態を確実に解釈し、視覚的な制約を推論し、ツールを調整し、長いコンテキストにわたって安定性を維持するかを理解するのに苦労することがよくあります。GLM-4.6V は、統一された視覚言語アーキテクチャ、ネイティブのマルチモーダルツール使用、および強力なエージェント推論機能を提供することで、これらの課題に直接対処します。この記事では、GLM-4.6V のアーキテクチャ、ベンチマークによる有効性の検証方法、実際のワークフロー内での機能、そして開発者が API 経由で効率的に GLM-4.6V にアクセスする方法について説明します。
GLM-4.6V のアーキテクチャとは?
ネイティブのマルチモーダルツール使用
GLM-4.6V は、ネイティブのマルチモーダルツール呼び出し機能を備えています:
- マルチモーダル入力: 画像、スクリーンショット、ドキュメントページを、最初にテキスト記述に変換することなく、ツールパラメーターとして直接渡すことができ、信号損失を最小限に抑えます。
- マルチモーダル出力: モデルは、ツールから返された結果(検索結果、統計チャート、レンダリングされた Web スクリーンショット、取得された商品画像など)を視覚的に理解し、その後の推論チェーンに組み込むことができます。
コアアーキテクチャの特性
-
統一された視覚言語表現
- 視覚的特徴とテキストセマンティクスが共有空間に配置され、共同推論を可能にします。
-
長コンテキストインタラクション
- 会話履歴、ドキュメント断片、ツール出力を組み合わせたワークフローをサポートします。
-
構造化出力への親和性
- 説明のみの VLM 使用よりも、関数呼び出し、JSON スキーマ準拠、制約順守に適しています。
ベンチマーク結果によると、GLM-4.6V は実際のワークフローでどの程度効果的ですか?
1. ビジュアル駆動のタスク理解
図、スクリーンショット、視覚仕様への抽象タスクのグラウンディング
GLM-4.6V は、生の視覚入力を構造化されたセマンティック理解に変換する強力な能力を示しており、これはエージェントワークフローの初期化に不可欠です。
| ベンチマーク | 測定される能力 | GLM-4.6V |
|---|---|---|
| MMBench v1.1 | 一般的な視覚質問応答 | 88.8 |
| MMBench v1.1 (CN) | 多言語視覚理解 | 88.2 |
| MMStar | 細かいマルチモーダル知覚 | 75.9 |
| BLINK (val) | 視覚的グラウンディングとアライメント | 65.5 |
2. 視覚的制約に関するマルチモーダル推論
画像を論理的・数学的推論の変数として使用する
知覚を超えて、GLM-4.6V は競争力のあるマルチモーダル推論パフォーマンスを示しており、これは視覚的証拠に依存するワークフローにとって重要です。
| ベンチマーク | 推論の焦点 | GLM-4.6V |
|---|---|---|
| MMMU (val) | 一般的なマルチモーダル推論 | 76.0 |
| MMMU-Pro | ハードなマルチモーダル推論 | 66.0 |
| MathVista | 視覚数学推論 | 85.2 |
| AI2D | 図ベースの推論 | 88.8 |
3. スクリーンショットベースの状態診断
視覚的証拠からの UI 状態と実行時条件の解釈
GLM-4.6V はスクリーンショットや視覚的アーティファクトからシステム状態を推測でき、これはデバッグやエージェントの監視に特に役立ちます。
| ベンチマーク | 測定される能力 | GLM-4.6V |
|---|---|---|
| VideoMMMU | 時間的および状態推論 | 74.7 |
| DynaMath | 動的な視覚推論 | 54.5 |
| WeMath | 応用視覚推論 | 69.8 |
4. エージェント計画とツール調整
ステップ全体でのツール使用の計画、スケジューリング、検証
GLM-4.6V のエージェントベンチマークは、受動的な応答者ではなく、中央制御装置としての適合性を示しています。
| ベンチマーク | エージェント行動 | GLM-4.6V |
|---|---|---|
| Design2Code | 視覚からアクションへの計画 | 88.6 |
| Flame-React-Eval | マルチステップ反応推論 | 86.3 |
| OSWorld | ツールベースの環境相互作用 | 37.2 |
| AndroidWorld | モバイルエージェント推論 | 57.0 |
| WebVoyager | Web ナビゲーションと計画 | 81.0 |
5. 長コンテキストマルチモーダルアライメント
ドキュメント、画像、ツール出力全体で一貫性を維持する
長コンテキストベンチマークは、モデルが拡張インタラクション全体で制約をどの程度維持できるかを示しています。
| ベンチマーク | コンテキスト能力 | GLM-4.6V |
|---|---|---|
| MMLongBench-Doc | ドキュメントレベルの推論 | 54.9 |
| MMLongBench-128K | 超長コンテキスト | 64.1 |
| LVBench | 長い視覚推論 | 59.5 |
6. OCR、チャート、空間グラウンディング
ドキュメントや空間レイアウトからの構造抽出
これらの能力は、ワークフローがレポート、ダッシュボード、またはスキャンされたドキュメントのスクリーンショットに依存する場合に重要です。
| ベンチマーク | 能力 | GLM-4.6V |
|---|---|---|
| OCRBench | テキスト抽出 | 86.5 |
| OCR-Bench v2 (EN) | 英語 OCR | 65.1 |
| ChartQAPro | チャート理解 | 65.5 |
| OmniSpatial | 空間推論 | 52.0 |
| RefCOCO-avg (val) | 参照表現グラウンディング | 88.6 |
GLM-4.6V はエンドツーエンドのワークフロー内でどのような役割を果たしますか?
GLM-4.6V は、単発の回答生成モデルではなく、推論および調整レイヤーとして最も効果的です。マルチモーダル入力を解釈し、制約を抽出し、ツール使用を計画し、中間結果を検証します。
| ワークフローの役割 | 一般的な入力 | ダウンストリームでの使用 |
|---|---|---|
| 推論 + 調整レイヤー(全体的な役割) | 画像、ドキュメント、UI スクリーンショット、ツール出力、タスク目標 | エラー伝播が低減された安定したツール拡張ワークフロー |
| ビジュアル駆動のタスク理解 | アーキテクチャ図、シーケンス図、デプロイスクリーンショット | リポジトリ検索の絞り込み、コードパスの優先順位付け、ターゲットテスト計画の生成 |
| スクリーンショットベースの状態推論 | エラーダイアログ、壊れたレイアウト、ダッシュボードの異常 | 自動ログ取得、ターゲットトレース、インシデントランブック |
| ドキュメント連携推論 | API ドキュメントページ、SDK スニペット、パラメータテーブル | ドキュメントに沿ったコード生成、コントラクトテスト、スキーマ検証 |
| マルチステップ計画と検証 | 高レベルタスク目標、画像、ドキュメント、中間ツール出力 | 信頼性の高いエージェントループ、コンテキストドリフトの低減、より安全なマルチツール実行 |
https://www.youtube.com/watch?v=5gqJKZWYOB4
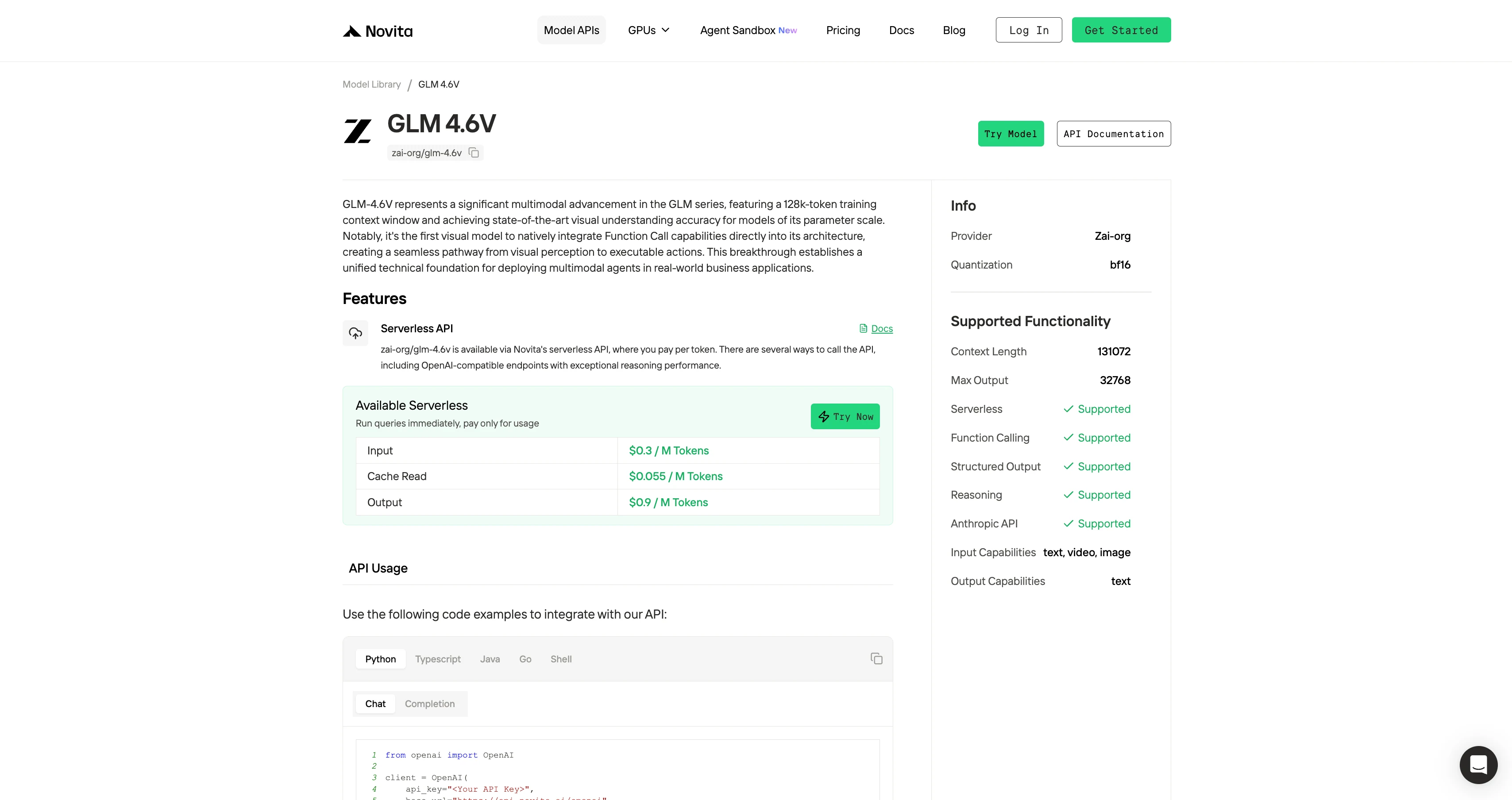
API 経由で GLM-4.6V にアクセスする方法
Novita AI は ERNIE-4.5-VL-28B-A3B-Thinking API を提供しており、131K コンテキストウィンドウ、入力 $0.3、出力 $0.9 で、構造化出力と関数呼び出しをサポートしています。
キャッシュ読み取り: $0.055 / M Token は、キャッシュヒット時にキャッシュされたトークンの読み取りコストを示します。これらのトークンは以前に計算・保存されているため、追加のモデル推論は不要です。多くのリクエストが同じプロンプトプレフィックスを共有するシステム、会話履歴、ツール指示、または固定ルールテキストを再利用する場合、または RAG 検索結果が非常に反復的である場合、高いキャッシュヒット率を達成でき、全体的な推論コストを大幅に削減できます。
ステップ 1: ログインしてモデルライブラリにアクセス
アカウントにログインし、モデルライブラリ ボタンをクリックします。

ステップ 2: モデルを選択
利用可能なオプションを参照し、ニーズに合ったモデルを選択します。

ステップ 3: 無料トライアルを開始
選択したモデルの機能を探索するために、無料トライアルを開始します。
ステップ 4: API キーを取得
API で認証するために、新しい API キーを提供します。「設定」ページに移動し、画像のように API キーをコピーします。

from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="zai-org/glm-4.6v",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=32768,
temperature=0.7
)
print(response.choices[0].message.content)
OpenAIAgentsSDK を使用して GLM 4.6V にアクセスする方法
Novita AI を OpenAI Agents SDK と統合して、高度なマルチエージェントシステムを構築します:
- プラグアンドプレイ: 任意の OpenAI Agents ワークフローで Novita AI の LLM を使用できます。
- ハンドオフ、ルーティング、ツール使用をサポート: 委任、トリアージ、または関数実行が可能なエージェントを設計でき、すべて Novita AI のモデルを搭載しています。
- Python 統合: SDK を Novita のエンドポイント(
https://api.novita.ai/v3/openai)にポイントし、API キーを使用するだけです。
サードパーティプラットフォームで GLM 4.6V にアクセスする方法
- Hugging Face: Novita AI エンドポイントを介して、Spaces、パイプライン、または Transformers ライブラリで GLM 4.6V を使用します。
- エージェント&オーケストレーションフレームワーク: 公式コネクタとステップバイステップの統合ガイドを通じて、Novita AI を Continue、AnythingLLM、LangChain、Dify、Langflow などのパートナープラットフォームと簡単に接続できます。
- OpenAI 互換 API: Cline や Cursor などのツールと、OpenAI API 標準向けに設計されたシームレスな移行と統合をお楽しみください。
GLM-4.6V は、単純な視覚質問応答モデルではなく、マルチモーダルワークフローの推論および調整レイヤーとして最適に位置づけられています。統一された視覚言語表現、長コンテキストアライメント、強力なツール計画能力を通じて、GLM-4.6V はより信頼性が高く、スケーラブルで、コスト効率の高いマルチモーダルエージェントシステムを実現します。
よくある質問
GLM-4.6V のアーキテクチャはなぜマルチモーダルワークフローに適しているのですか?
GLM-4.6V は統一された視覚言語表現とネイティブのマルチモーダルツール呼び出しを使用しており、画像、ドキュメント、ツール出力を GLM-4.6V が共同で推論できるようにします。
エンドツーエンドのエージェントワークフロー内で GLM-4.6V はどのような役割を果たしますか?
GLM-4.6V は推論および調整レイヤーとして機能し、マルチモーダル入力を解釈し、ツール使用を計画し、中間結果を検証します。
開発者は API 経由で GLM-4.6V を使用する際にコストを削減するにはどうすればよいですか?
GLM-4.6V でキャッシュ読み取り価格を活用することで、繰り返しのプロンプト、共有プレフィックス、反復的な RAG 出力を再利用でき、推論コストを大幅に削減できます。
Novita AI は、AI への野心を強化するオールインワンのクラウドプラットフォームです。統合 API、サーバーレス、GPU インスタンス — コスト効率の高いツールを提供します。インフラストラクチャを排除し、無料で開始し、AI ビジョンを現実のものにします。
おすすめの記事



