

Developers face a growing dilemma: choosing between image models optimized for artistic freedom and those engineered for commercial reliability.
Teams building production APIs struggle with inconsistent text rendering, weak instruction adherence, and unpredictable layouts from art-oriented generators like Nano Banana 2.0. This article frames GLM-Image as a production-grade alternative, analyzing its architecture, benchmarks, speed, and hardware profile to help developers select the right model for structured, text-critical, and multilingual applications.
Start a Free trail of GLM Image

From GLM Image
Architecture Overview of GLM Image
GLM-Image adopts a hybrid auto-regressive + diffusion decoder architecture to separate reasoning about content from pixel rendering. The autoregressive component handles semantic layout and instruction interpretation, and the diffusion decoder fills in high-resolution detail. This structure is distinct from pure diffusion models which optimize pixel denoising but often fail at precise instruction adherence and text clarity
| Component | Role | Parameter Count |
|---|---|---|
| Autoregressive Generator | Generates semantic plan and layout tokens | 9B (based on GLM-4-9B) |
| Diffusion Decoder (single-stream DiT) | Renders high-frequency image detail | 7B |
| Total | Hybrid representation | 16B parameters |
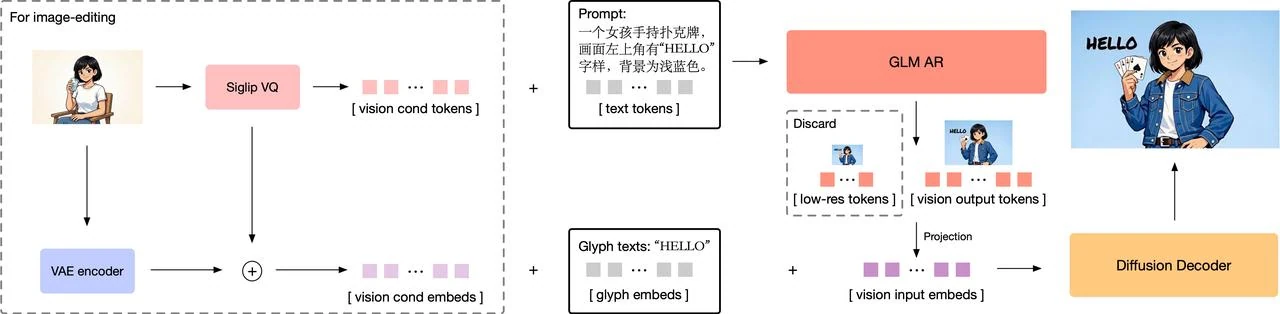
From GLM
Benchmark Performance Comparison of GLM Image and Nano Banana
GLM-Image excels in structured text rendering, especially multi-region text, while Nano Banana tends to be stronger in subjective artistic output.
For legible text and structured diagrams, GLM-Image tends to produce more reliable outputs. For style richness and subjective composition quality, Nano Banana and proprietary generators may still lead.
Start a Free trail of GLM Image
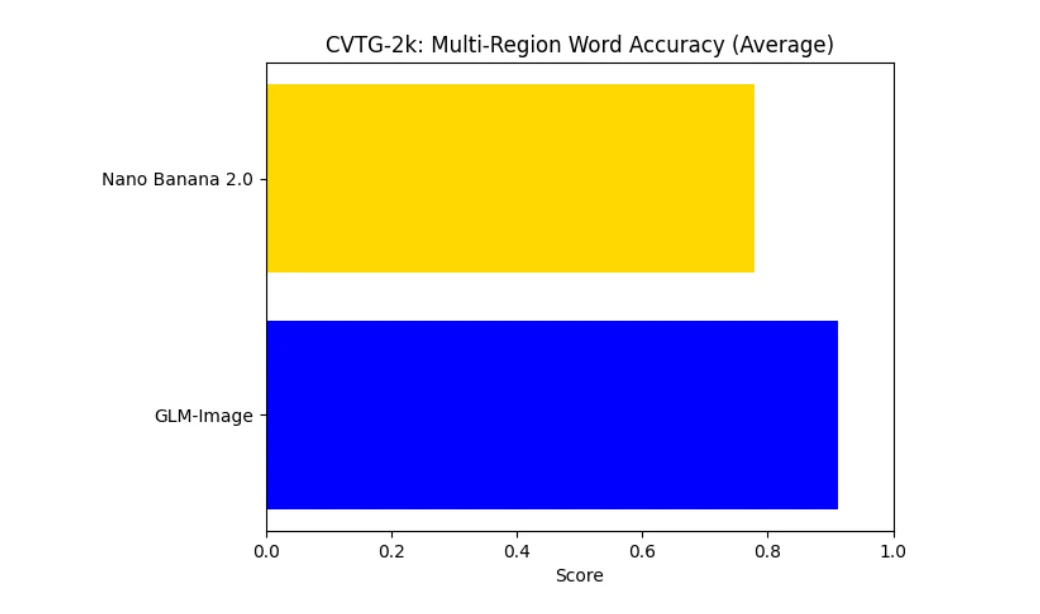
On CVTG-2k, GLM-Image significantly outperforms Nano Banana in multi-region word accuracy. This indicates stronger character-level fidelity and higher robustness when multiple text blocks coexist. The gap reflects GLM-Image’s specialization for controllable text generation, where layout complexity does not immediately degrade recognition quality.
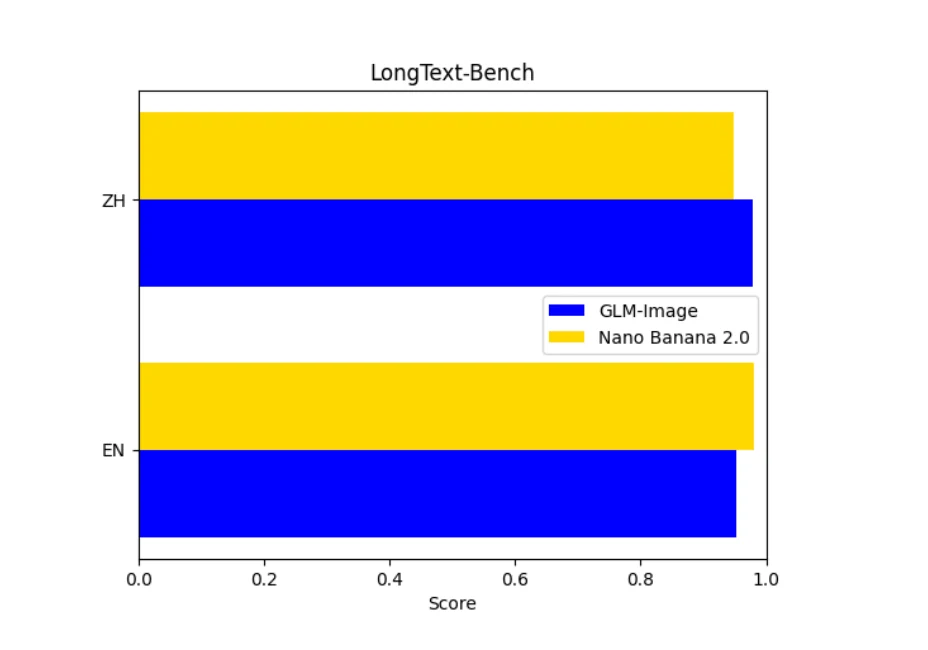
On LongText-Bench, the advantage becomes language-dependent. Nano Banana slightly leads on English long-form text, suggesting better global coherence over long Latin sequences. GLM-Image dominates on Chinese long text, implying more reliable character continuity, line breaking, and dense glyph rendering. This makes GLM-Image a safer choice for Chinese posters, infographics, and instructional graphics, while Nano Banana offers a higher ceiling for English slogans and paragraphs.
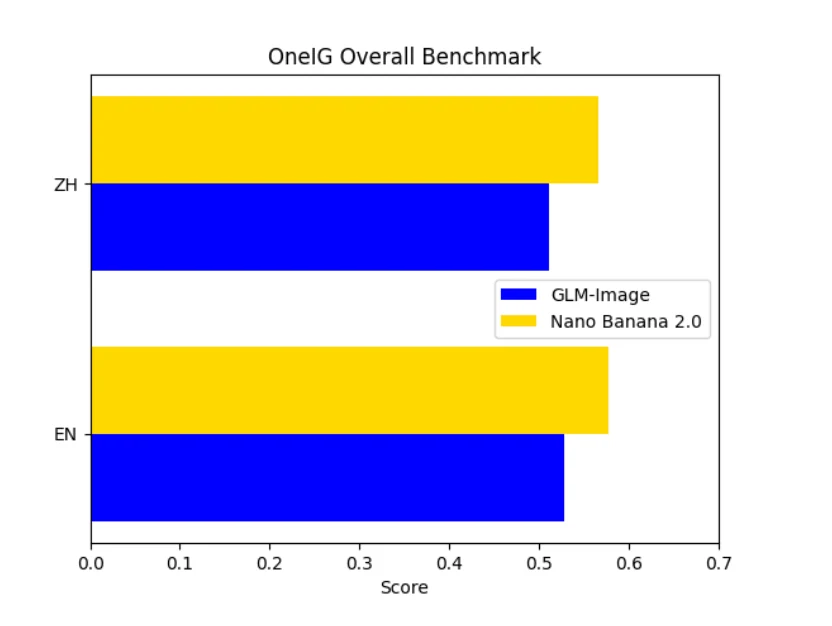
On OneIG Overall, Nano Banana consistently scores higher across both languages. This reflects stronger alignment, style expression, and holistic visual composition. GLM-Image remains extremely strong in text fidelity, yet lags in artistic richness and semantic integration.
Hardware Requirements of GLM Image
| Deployment Type | Recommended GPU | VRAM Requirement |
|---|---|---|
| High-throughput API | NVIDIA H100 / A100 | 80GB |
| Single-instance testing | NVIDIA A40 / RTX 6000 | 48GB |
| Lower cost quantized | GPUs supporting TensorRT/FP16 | 24GB |
The dual-module design and relatively large parameter count lead to higher memory footprints than some efficient diffusion models. Architecture shards must be resident simultaneously if not specially optimized.
Start a Free trail of GLM Image
Commercial Usage Considerations of GLM Image
When to choose GLM-Image:
- Automated generation of infographics, diagrams, posters with precise labels.
- Multilingual text-aware visual asset pipelines.
- Commercial APIs where compliance to specification outweighs purely aesthetic considerations.
When Nano Banana may be preferable:
- Creative art generation with stylistic richness and artist-level detail.
- Applications prioritizing visual diversity and photorealism.
- Cases where external knowledge integration (like search) enhances output.
A Prompt Comparsion
Access GLM Image on Novita AI
GLM Image text-to-image generation tool creates high-quality images from text prompts, producing HD images with fine details and high consistency.
This is an asynchronous API; only the task_id will be returned. You should use the task_id to request the Task Result API to retrieve the video generation results.
import requests
url = "https://api.novita.ai/v3/async/glm-image"
payload = {
"size": "<string>",
"prompt": "<string>",
"quality": "<string>",
"watermark_enabled": True
}
headers = {
"Content-Type": "<content-type>",
"Authorization": "<authorization>"
}
response = requests.post(url, json=payload, headers=headers)
print(response.text)Start a Free trail of GLM Image
GLM-Image is a planning-first image model designed for correctness, while Nano Banana 2.0 prioritizes artistic expressiveness.
GLM-Image excels at multi-region text rendering, semantic fidelity, and multilingual stability, making it ideal for commercial APIs that demand predictable output. Nano Banana 2.0 remains stronger for creative and stylistic tasks. The choice is a tradeoff between production reliability and artistic freedom.
When should I choose GLM-Image over Nano Banana 2.0?
Choose GLM-Image when your product requires accurate text, structured layouts, or multilingual content; choose Nano Banana 2.0 for art-driven creativity.
How does GLM-Image differ architecturally from Nano Banana 2.0?
GLM-Image uses an autoregressive planner plus diffusion decoder, while Nano Banana 2.0 follows a pure diffusion design optimized for visual style.
Which model performs better on text benchmarks?
GLM-Image leads CVTG-2k multi-region word accuracy, outperforming Nano Banana 2.0 in structured text tasks.
Novita AI is an AI cloud platform that offers developers an easy way to deploy AI models using our simple API, while also providing affordable and reliable GPU cloud for building and scaling.



