

Points clés
- Les modèles de langage de grande taille (LLM) et les modèles Generative Pre-trained Transformer (GPT) sont tous deux des types de modèles d’IA qui utilisent le traitement du langage naturel et des techniques d’apprentissage automatique.
- Les LLM sont entraînés sur d’énormes quantités de données textuelles et peuvent effectuer des tâches telles que la synthèse, la traduction, la génération de contenu et l’assistance par chatbot.
- Les modèles GPT, en particulier ChatGPT d’OpenAI, sont un type spécifique de LLM qui utilise une architecture de transformer pour générer des réponses textuelles de type humain.
- Les LLM et les modèles GPT ont tous deux leurs forces et leurs limites, et comprendre leurs différences peut aider à choisir le modèle adapté à des applications spécifiques.
- Les LLM nécessitent un processus approfondi d’entraînement et de réglage fin, tandis que les modèles GPT sont pré-entraînés et peuvent être réglés finement pour des tâches spécifiques.
- Les LLM excellent dans la génération et la compréhension de texte, tandis que les modèles GPT se concentrent spécifiquement sur la génération de réponses textuelles de manière conversationnelle.
Introduction
Les modèles de langage de grande taille (LLM) et les modèles Generative Pre-trained Transformer (GPT) révolutionnent l’intelligence artificielle (IA) et le traitement du langage naturel (NLP). Comprendre la différence entre LLM et GPT, deux acronymes couramment utilisés dans le domaine de l’IA et du NLP, est crucial pour saisir leurs capacités distinctes et leurs applications dans divers secteurs. Bien que tous deux excellent dans la génération de texte, ils diffèrent par leurs architectures sous-jacentes et leurs mesures de performance. Approfondir les nuances de ces modèles permettra de mieux comprendre comment ils redessinent le paysage de l’IA et de l’apprentissage automatique.

Qu’est-ce qu’un modèle de langage de grande taille (LLM)
Les modèles de langage de grande taille (LLM) désignent une large catégorie de modèles linguistiques conçus pour diverses tâches de traitement du langage naturel. Les modèles GPT font partie de cette catégorie en tant que type spécifique de LLM. Le terme « LLM » englobe tout modèle linguistique étendu utilisé dans ce domaine.
Caractéristiques principales des LLM
Les LLM possèdent plusieurs caractéristiques clés qui en font des outils puissants dans le traitement du langage naturel et les applications d’IA. Ces caractéristiques incluent :
- Scalabilité : Les LLM sont remarquables pour leur scalabilité, avec des tailles allant de variantes plus petites à des versions extrêmement grandes comme GPT-3. La taille d’un LLM influence grandement ses capacités.
- Variété d’architectures : Contrairement aux modèles GPT qui utilisent l’architecture Transformer, les LLM peuvent être construits à l’aide de diverses architectures, notamment les réseaux de neurones récurrents (RNN) et les réseaux de neurones convolutifs (CNN).
- Applications étendues : Les LLM sont adaptables à de nombreuses tâches de NLP telles que l’analyse des sentiments, la synthèse de texte et la traduction linguistique, démontrant leur large applicabilité pour relever divers défis.
- Apprentissage basé sur les données : Les LLM sont entraînés sur de vastes ensembles de données, y compris des textes provenant de livres, d’articles et de sites Web, ce qui leur permet d’apprendre et de reproduire des modèles et des nuances linguistiques complexes.
- Défis éthiques : Les LLM rencontrent des problèmes tels que les biais et les préoccupations éthiques, car les données sur lesquelles ils s’entraînent peuvent refléter les biais existants dans le langage humain. Ces défis suscitent des débats sur l’utilisation responsable de l’IA et le comportement des modèles.
Qu’est-ce que Generative Pre-trained Transformer (GPT)
Generative Pre-trained Transformer, communément appelé GPT, est une série de modèles de traitement du langage naturel (NLP) créés par OpenAI. Ces modèles sont conçus pour produire et comprendre un texte qui ressemble au langage humain, en répondant aux entrées qui leur sont fournies. GPT-3, la version la plus récente et la plus importante, est le plus grand modèle de cette série à ce jour.
Caractéristiques principales de GPT
Les modèles GPT excellent dans leur capacité à générer un texte cohérent et contextuellement pertinent, une caractéristique fondamentale appelée complétion de texte. Les principales caractéristiques de GPT incluent :
- Pré-entraînement : Les modèles GPT subissent un pré-entraînement intensif sur de vastes ensembles de données provenant d’Internet pour apprendre les structures linguistiques, la grammaire, la sémantique et le contexte.
- Architecture Transformer : Construits sur le framework Transformer, les modèles GPT traitent efficacement les séquences de données. Cette architecture leur permet de prendre en compte le contexte de chaque mot dans une phrase lors de la génération de texte.
- Réglage fin : Après le pré-entraînement, les modèles GPT peuvent être réglés finement pour des tâches ou des secteurs spécifiques, améliorant leurs performances dans des domaines comme la traduction linguistique, la complétion de texte ou la réponse aux questions.
- Grande échelle : Par exemple, GPT-3 est un modèle massif avec 175 milliards de paramètres, ce qui en fait l’un des plus grands modèles linguistiques existants. Sa taille étendue augmente considérablement sa capacité de génération de texte.
- Génération de texte de type humain : Connus pour produire un texte imitant étroitement l’écriture humaine, les modèles GPT sont capables de composer des essais, de répondre à des requêtes et même de rédiger de la poésie, rendant souvent difficile la distinction entre une production humaine et machine.
Analyse comparative : LLM vs. GPT
Maintenant que nous avons une solide compréhension de ce que sont GPT et LLM, procédons à une analyse comparative pour examiner les différences et similitudes entre GPT et LLM.
Données d’entraînement et échelle
GPT
Les modèles GPT se distinguent par leur grande échelle : GPT-3, par exemple, est pré-entraîné sur 570 Go de données textuelles diverses telles que des textes Internet, des livres et des articles. Cette vaste quantité de données d’entraînement est cruciale pour ses capacités avancées de génération de langage.
LLM
Les LLM couvrent un large spectre de modèles variant en échelle et en données utilisées pour l’entraînement. Ils vont de modèles plus petits comme GPT-2, qui a 1,5 milliard de paramètres, à des modèles beaucoup plus grands comme GPT-3, avec 175 milliards de paramètres. Les données d’entraînement des LLM sont généralement similaires à celles de GPT mais varient selon la conception et les objectifs spécifiques de chaque modèle.
Différence clé
La principale différence en matière de données d’entraînement et d’échelle est que GPT-3 représente un cas spécifique au sein de la catégorie plus large des LLM, se situant à l’extrémité supérieure du spectre d’échelle.
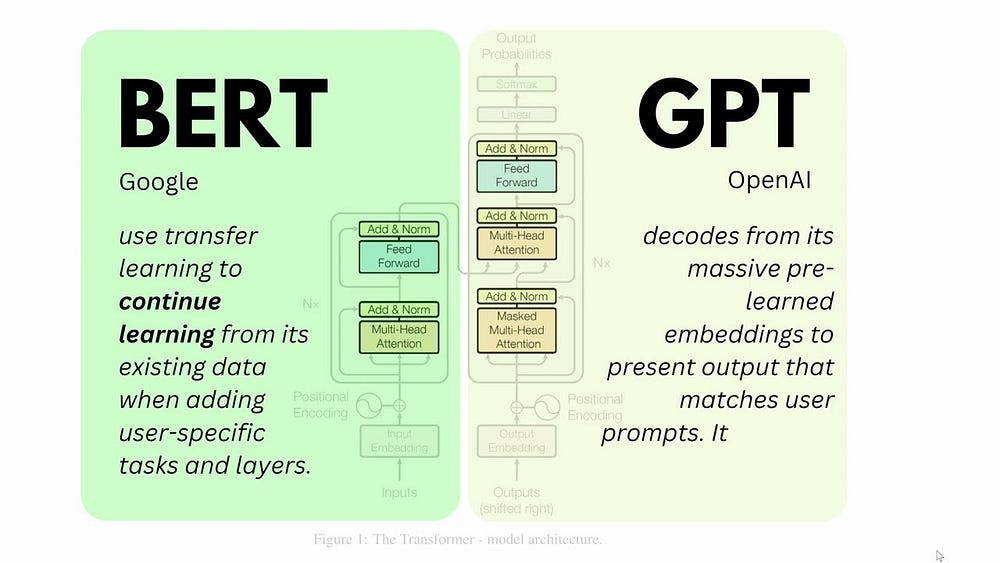
Architecture et fonctionnalité
GPT
Les modèles GPT utilisent l’architecture Transformer, qui est apte à traiter des séquences de données, ce qui la rend très efficace pour diverses tâches de NLP. Ces modèles sont particulièrement réputés pour la génération et la complétion de texte.
LLM
Les LLM emploient diverses architectures, notamment Transformers, RNN et CNN, adaptées à la scalabilité et à la flexibilité en fonction des objectifs du modèle. Les LLM prennent en charge un éventail plus large de tâches de NLP au-delà de la génération de texte.
Différence clé
La distinction critique en matière d’architecture et de fonctionnalité est que les modèles GPT sont exclusivement construits sur l’architecture Transformer et sont principalement reconnus pour leur capacité de génération de texte, tandis que les LLM intègrent plusieurs architectures et un champ d’applications plus large.
Cas d’utilisation et applications
GPT
Les modèles GPT, comme GPT-3, sont acclamés pour produire un texte qui ressemble étroitement à l’écriture humaine, utilisé dans la création de contenu, la réponse aux questions, la traduction linguistique, les chatbots et l’écriture créative. GPT-3 a montré une compétence exceptionnelle dans la compréhension et la génération de langage naturel.
LLM
En tant que catégorie plus étendue, les LLM trouvent une utilisation dans diverses applications telles que l’analyse des sentiments, la synthèse de texte, la traduction linguistique, la classification de texte, etc. Ils peuvent être personnalisés pour des secteurs particuliers comme la santé, la finance et le service client, répondant à des besoins spécifiques à chaque secteur.
Différence clé
Alors que les modèles GPT sont très appréciés pour leurs compétences en génération de texte, les LLM sont utilisés pour un plus large éventail de tâches de NLP, soulignant leur polyvalence.
Implications éthiques et sociétales
GPT
L’utilisation à grande échelle des modèles GPT a suscité des débats éthiques sur les biais, la désinformation et les utilisations abusives potentielles, en particulier avec la capacité de GPT-3 à produire un texte de type humain, soulevant des questions sur l’utilisation responsable de l’IA dans la création de contenu.
LLM
Les préoccupations éthiques concernant les LLM impliquent également des problèmes de biais et de confidentialité, s’étendant à l’utilisation responsable de l’IA dans différentes applications. Compte tenu de leur utilisation étendue dans divers secteurs, il est crucial de considérer les questions éthiques adaptées au contexte spécifique de chaque application.
Différence clé
Les implications éthiques et sociétales associées aux modèles GPT et aux LLM sont similaires, les deux soulevant des préoccupations concernant les biais et l’utilisation responsable de l’IA. Les préoccupations spécifiques peuvent varier en fonction de l’application et de l’échelle du modèle.
Applications existantes des LLM et GPT dans divers secteurs
Les modèles de langage de grande taille (LLM) et les modèles Generative Pre-trained Transformer (GPT) ont trouvé de nombreuses applications dans divers secteurs. Découvrons-les respectivement.
Applications existantes des LLM
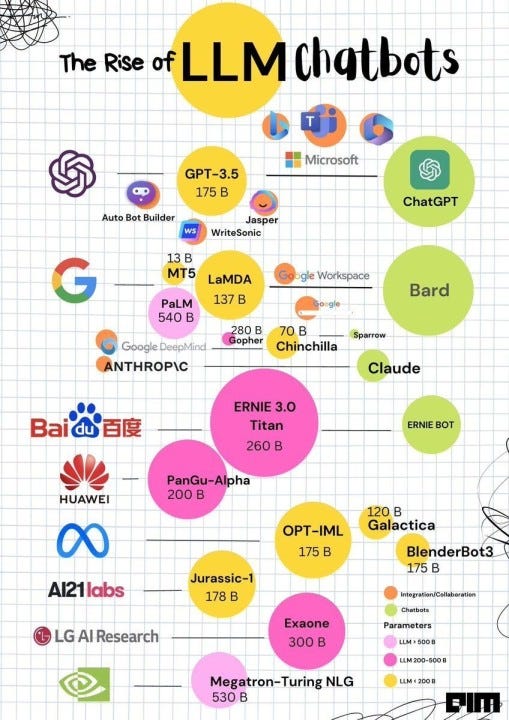
Ces dernières années, de nombreux modèles de langage de grande taille ont montré des capacités remarquables dans une variété de tâches de traitement du langage naturel. Voici quelques exemples notables :
- BERT (Bidirectional Encoder Representations from Transformers) : Créé par Google, BERT est un modèle de transformer pré-entraîné connu pour sa compétence à comprendre les nuances contextuelles. Il a établi de nouvelles références en matière d’analyse des sentiments, de réponse aux questions et de reconnaissance d’entités nommées.
- RoBERTa (Robustly Optimized BERT Pretraining Approach) : Une version améliorée de BERT développée par Facebook, RoBERTa utilise des méthodes de pré-entraînement avancées et des ensembles de données plus volumineux, ce qui a conduit à des résultats supérieurs sur plusieurs benchmarks.
- GPT-2, GPT-3 et GPT-4 (Generative Pre-trained Transformer) : Développés par OpenAI, les modèles de la série GPT sont de puissants modèles linguistiques qui excellent dans la génération de texte de type humain. Ils sont pré-entraînés sur de vastes quantités de données textuelles et peuvent être réglés finement pour diverses applications, telles que la conversation, la traduction et la synthèse.
- ALBERT (A Lite BERT) : Cette version simplifiée de BERT utilise des techniques de partage de paramètres pour réduire le nombre total de paramètres, ce qui économise la mémoire et les ressources de calcul tout en maintenant des performances robustes.
- Chat-completion par Novita.ai : Ces API de chat LLM vous permettent d’engager des conversations sur n’importe quel sujet de votre choix. Elles sont sans restriction, sans règle et non censurées pour vos conversations.

Applications existantes de GPT

En plus des modèles de langage de grande taille mentionnés précédemment, il existe plusieurs transformers pré-entraînés généraux conçus pour diverses tâches, notamment la vision par ordinateur, la reconnaissance vocale et l’apprentissage par renforcement. Quelques exemples notables incluent :
- Vision Transformer (ViT) : ViT est un modèle de transformer initialement pré-entraîné pour les tâches de vision par ordinateur. Il traite les images comme des séquences de patchs, utilisant les puissantes capacités du transformer pour des tâches telles que la classification d’images.
- DETR (Detection Transformer) : DETR applique le framework transformer à la détection d’objets et à la segmentation d’images, modélisant directement les relations entre les régions d’une image et les classes d’objets, éliminant ainsi le besoin de techniques traditionnelles comme les boîtes d’ancrage ou la suppression non maximale.
- Conformer : Conformer mélange l’architecture transformer avec les réseaux de neurones convolutifs (CNN) pour améliorer les tâches de reconnaissance vocale. Il démontre d’excellentes performances en reconnaissance automatique de la parole (ASR) et en détection de mots-clés.
- Swin Transformer : Conçu pour la vision par ordinateur, le Swin Transformer adopte une structure hiérarchique qui permet un traitement efficace des images, le rendant apte à manipuler des images haute résolution et à passer à l’échelle sur des ensembles de données plus volumineux.
- Perceiver et Perceiver IO : Ces modèles de transformer polyvalents peuvent traiter plusieurs types de données, y compris les images, l’audio et le texte. Ils disposent d’un mécanisme d’attention unique qui gère efficacement de grands volumes d’entrée, les rendant adaptables à diverses applications.
Conclusion
En conclusion, comprendre les distinctions entre les modèles de langage de grande taille (LLM) et les modèles Generative Pre-trained Transformer (GPT) est crucial pour exploiter efficacement leurs capacités. Alors que les LLM offrent des fonctionnalités spécifiques adaptées à leur évolution, les modèles GPT excellent dans la création de contenu génératif. Leur analyse comparative met en lumière les variances architecturales et les portées d’application. L’avenir des LLM et des GPT promet des tendances prometteuses dans les avancées de l’IA, avec des considérations éthiques et la confidentialité des données étant primordiales. Surmonter les défis de la mise en œuvre de ces technologies nécessite de traiter les biais et d’assurer des modèles d’IA équitables, soulignant leur rôle central dans la formation de l’avenir de la recherche en IA et de l’apprentissage automatique.

Foire aux questions
Qu’est-ce qui rend les modèles GPT uniques par rapport aux autres LLM ?
Les modèles GPT, y compris ChatGPT d’OpenAI, sont uniques par rapport aux autres modèles de langage de grande taille (LLM) en raison de leur utilisation d’une architecture de transformer et d’un mécanisme d’attention.
Comment les modèles LLM et GPT impactent-ils l’avenir du travail ?
Ces modèles d’IA peuvent automatiser des tâches, améliorer la productivité et fournir une assistance intelligente dans divers secteurs, y compris la création de contenu, le support client et l’analyse de données.
novita.ai, la plateforme tout-en-un pour une créativité illimitée qui vous donne accès à plus de 100 API. De la génération d’images au traitement du langage, en passant par l’amélioration audio et la manipulation vidéo, un paiement à l’utilisation avantageux, elle vous libère des tracas de la maintenance GPU tout en construisant vos propres produits. Essayez-le gratuitement.
Lectures recommandées
TOP LLMs for 2024: How to Evaluate and Improve An Open Source LLM



