

重要なポイント
- 大規模言語モデル(LLM)と生成的事前学習済みトランスフォーマー(GPT)モデルは、どちらも自然言語処理と機械学習技術を活用するAIモデルです。
- LLMは膨大な量のテキストデータで訓練され、要約、翻訳、コンテンツ生成、チャットボットサポートなどのタスクを実行できます。
- GPTモデル、特にOpenAIのChatGPTは、トランスフォーマーアーキテクチャを使用して人間らしいテキスト応答を生成する特定のタイプのLLMです。
- LLMとGPTモデルにはそれぞれ強みと限界があり、それらの違いを理解することで、特定のアプリケーションに適したモデルを選択するのに役立ちます。
- LLMは広範な訓練と微調整のプロセスを必要としますが、GPTモデルは事前学習済みで、特定のタスクに微調整できます。
- LLMはテキスト生成と理解に優れていますが、GPTモデルは会話形式でテキスト応答を生成することに特化しています。
はじめに
大規模言語モデル(LLM)と生成的事前学習済みトランスフォーマー(GPT)モデルは、人工知能(AI)と自然言語処理(NLP)に革命をもたらしています。AIとNLPの分野でよく使われるこの2つの頭字語の違いを理解することは、様々な業界におけるそれぞれの能力と応用を把握する上で重要です。どちらもテキスト生成に優れていますが、基盤となるアーキテクチャとパフォーマンス指標が異なります。これらのモデルのニュアンスを深く掘り下げることで、AIと機械学習の展望をどのように変えているのかが明らかになるでしょう。

大規模言語モデル(LLM)とは
大規模言語モデル(LLM)は、様々な自然言語処理タスク向けに設計された広範な言語モデルのカテゴリを指します。GPTモデルは、このカテゴリに含まれる特定のタイプのLLMです。「LLM」という用語は、この分野で使用されるあらゆる大規模言語モデルを包含します。
LLMの主な特徴
LLMは、自然言語処理やAIアプリケーションにおいて強力なツールとなるいくつかの主要な特徴を備えています。これらの特徴は次のとおりです。
- スケーラビリティ:大規模言語モデル(LLM)は、小型のバリエーションからGPT-3のような非常に大規模なバージョンまで、スケーラビリティで注目されています。LLMのサイズはその能力に大きく影響します。
- 多様なアーキテクチャ:GPTモデルがTransformerアーキテクチャを利用するのに対し、LLMはリカレントニューラルネットワーク(RNN)や畳み込みニューラルネットワーク(CNN)など、さまざまなアーキテクチャで構築できます。
- 幅広いアプリケーション:LLMは、感情分析、テキスト要約、言語翻訳など、多数のNLPタスクに適応でき、多様な課題に対処する際の幅広い応用性を示しています。
- データ駆動型学習:LLMは、書籍、記事、ウェブサイトからのテキストを含む大規模なデータセットで訓練され、複雑な言語パターンやニュアンスを学習・再現できます。
- 倫理的課題:LLMは、訓練データが人間の言語に存在するバイアスを反映する可能性があるため、バイアスや倫理的問題に直面します。これらの課題は、責任あるAIの使用とモデルの動作に関する継続的な議論を引き起こしています。
生成的事前学習済みトランスフォーマー(GPT)とは
生成的事前学習済みトランスフォーマー(GPT)は、一般的にOpenAIによって作成された一連の自然言語処理(NLP)モデルです。これらのモデルは、人間の言語に似たテキストを生成および理解し、与えられた入力に応答するように設計されています。GPT-3は最新かつ最も著名なバージョンであり、これまでのシリーズの中で最大のモデルです。
GPTの主な特徴
GPTモデルは、首尾一貫し文脈に関連したテキストを生成する能力に優れており、これはテキスト補完と呼ばれる基本的な特徴です。GPTの主な特徴は次のとおりです。
- 事前学習:GPTモデルは、言語構造、文法、意味、文脈を学習するために、インターネット上の膨大なデータセットで広範な事前学習を受けます。
- トランスフォーマーアーキテクチャ:Transformerフレームワークに基づいて構築されたGPTモデルは、データのシーケンスを効率的に処理します。このアーキテクチャにより、テキスト生成時に文中の各単語の文脈を考慮することができます。
- 微調整:事前学習後、GPTモデルは特定のタスクや業界向けに微調整でき、言語翻訳、テキスト補完、質問応答などの分野でのパフォーマンスが向上します。
- 大規模:たとえば、GPT-3は1750億のパラメータを持つ巨大なモデルであり、これまでに存在する最大の言語モデルの1つです。その広大なサイズは、テキスト生成能力を大幅に向上させます。
- 人間らしいテキスト生成:人間の文章を密に模倣したテキストを生成することで知られるGPTモデルは、エッセイの作成、質問への回答、詩の作成に至るまで、人間と機械の出力を区別するのが難しいことがよくあります。
比較分析:LLM vs. GPT
ここまででGPTとLLMについてしっかりと理解したところで、比較分析に進み、GPTとLLMの違いと類似点を検討しましょう。
訓練データと規模
GPT
GPTモデルはその大規模さで際立っており、例えばGPT-3はインターネットテキスト、書籍、記事などの多様なテキストデータ570GBで事前学習されています。この膨大な訓練データは、高度な言語生成能力にとって重要です。
LLM
LLMは、規模と訓練に使用されるデータの点で多様なモデルを網羅しています。パラメータ数15億のGPT-2のような小型モデルから、パラメータ数1750億のGPT-3のようなはるかに大型のモデルまであります。LLMの訓練データは一般にGPTと似ていますが、各モデルの特定の設計と目的によって異なります。
主な違い
訓練データと規模における主な違いは、GPT-3がLLMの広範なカテゴリ内の特定のインスタンスであり、規模のスペクトルの上位に位置していることです。
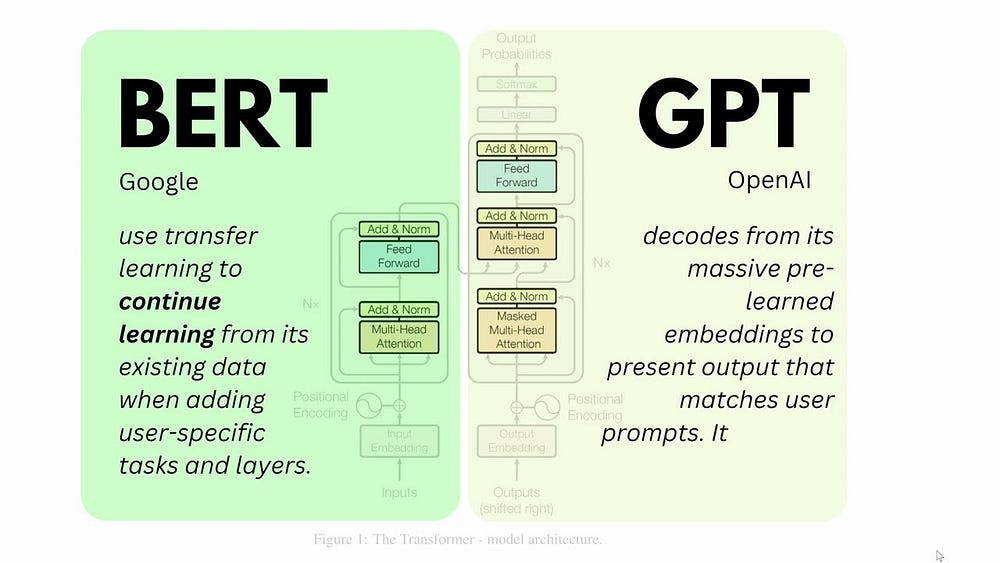
アーキテクチャと機能
GPT
GPTモデルはTransformerアーキテクチャを利用しており、これはデータシーケンスの処理に長けており、様々なNLPタスクに非常に効果的です。これらのモデルは特にテキスト生成と補完で有名です。
LLM
LLMは、Transformer、RNN、CNNなど多様なアーキテクチャを採用しており、モデルの目標に応じてスケーラビリティと柔軟性を考慮して調整されています。LLMはテキスト生成以外のより広範なNLPタスクをサポートします。
主な違い
アーキテクチャと機能における決定的な違いは、GPTモデルが独占的にTransformerアーキテクチャに基づいて構築されており、主にテキスト生成能力で認識されているのに対し、LLMは複数のアーキテクチャとより広範なアプリケーション範囲を組み込んでいることです。
ユースケースとアプリケーション
GPT
GPT-3などのGPTモデルは、人間の文章に非常に似たテキストを生成することで高く評価されており、コンテンツ作成、質問応答、言語翻訳、チャットボット、創作文章などに使用されます。GPT-3は自然言語の理解と生成において例外的な習熟度を示しています。
LLM
より広範なカテゴリであるLLMは、感情分析、テキスト要約、言語翻訳、テキスト分類など、様々なアプリケーションで使用されています。ヘルスケア、金融、カスタマーサービスなどの特定のセクター向けにカスタマイズでき、業界固有のニーズに対応します。
主な違い
GPTモデルはテキスト生成スキルで高く評価されていますが、LLMはより広範なNLPタスクに利用されており、その汎用性が際立っています。
倫理的・社会的影響
GPT
GPTモデルの大規模な使用は、バイアス、誤情報、潜在的な誤用に関する倫理的議論を引き起こしており、特にGPT-3が人間らしいテキストを生成する能力は、コンテンツ作成におけるAIの責任ある使用についての疑問を提起しています。
LLM
LLMに関する倫理的懸念は、バイアスやプライバシーの問題にも及び、さまざまなアプリケーションにおけるAIの責任ある使用にまで拡大します。様々な業界で広く使用されていることを考えると、各アプリケーションの特定の文脈に合わせた倫理的問題を考慮することが重要です。
主な違い
GPTモデルとLLMに関連する倫理的・社会的影響は類似しており、どちらもバイアスと責任あるAI使用に関する懸念を引き起こします。具体的な懸念事項は、アプリケーションとモデルの規模によって異なる場合があります。
様々な業界におけるLLMとGPTの既存のアプリケーション
大規模言語モデル(LLM)と生成的事前学習済みトランスフォーマー(GPT)モデルは、様々な業界で多くのアプリケーションを見出しています。それぞれ見ていきましょう。
LLMの既存のアプリケーション
近年、多数の大規模言語モデルが様々な自然言語処理タスクで顕著な能力を示しています。以下にいくつかの代表的例を挙げます。
- BERT(Transformerからの双方向エンコーダ表現):Googleによって作成されたBERTは、文脈のニュアンスを理解する能力で知られる事前学習済みトランスフォーマーモデルです。感情分析、質問応答、固有表現認識において新たなベンチマークを打ち立てました。
- RoBERTa(ロバストに最適化されたBERT事前学習アプローチ):Facebookによって開発されたBERTの拡張版であるRoBERTaは、高度な事前学習手法と大規模データセットを利用し、複数のベンチマークで優れた結果をもたらしています。
- GPT-2、GPT-3、GPT-4(生成的事前学習済みトランスフォーマー):OpenAIによって開発されたGPTシリーズのモデルは、人間らしいテキストを生成することに優れた強力な言語モデルです。膨大なテキストデータで事前学習され、会話、翻訳、要約などの様々なアプリケーション向けに微調整できます。
- ALBERT(ライトBERT):BERTの合理化されたバージョンで、パラメータ共有技術を採用して総パラメータ数を削減し、メモリと計算リソースを節約しながら堅牢なパフォーマンスを維持します。
- Novita.aiのチャット補完:このLLMチャットAPIを使用すると、任意のトピックに関する会話を行うことができます。会話に制限やルール、検閲はありません。

GPTの既存のアプリケーション

前述の大規模言語モデルに加えて、コンピュータビジョン、音声認識、強化学習など、様々なタスク向けに設計された汎用的な事前学習済みトランスフォーマーがいくつかあります。注目すべき例をいくつか挙げます。
- Vision Transformer (ViT):ViTは、当初コンピュータビジョンタスク向けに事前学習されたトランスフォーマーモデルです。画像をパッチのシーケンスとして処理し、トランスフォーマーの強力な能力を画像分類などのタスクに活用します。
- DETR(検出トランスフォーマー):DETRはトランスフォーマーフレームワークを物体検出と画像セグメンテーションに適用し、画像領域と物体クラスの間の関係を直接モデル化することで、アンカーボックスや非最大値抑制などの従来の手法を不要にします。
- Conformer:Conformerは、トランスフォーマーアーキテクチャと畳み込みニューラルネットワーク(CNN)を融合して音声認識タスクを強化します。自動音声認識(ASR)やキーワードスポッティングで優れた性能を発揮します。
- Swin Transformer:コンピュータビジョン用に設計されたSwin Transformerは、階層構造を採用して効率的な画像処理を可能にし、高解像度画像の処理や大規模データセットへの拡張に適しています。
- Perceiver および Perceiver IO:これらの汎用トランスフォーマーモデルは、画像、音声、テキストを含む複数のデータタイプを処理できます。独自のアテンション機構を備え、大量の入力を効率的に処理するため、様々なアプリケーションに適応可能です。
結論
結論として、大規模言語モデル(LLM)と生成的事前学習済みトランスフォーマー(GPT)モデルの違いを理解することは、それらの能力を効果的に活用するために重要です。LLMはその進化に合わせた特定の機能を提供しますが、GPTモデルは生成的なコンテンツ作成に優れています。比較分析により、アーキテクチャの違いとアプリケーションの範囲が明らかになります。LLMとGPTの未来は、AIの進歩における有望なトレンドを秘めており、倫理的配慮とデータプライバシーが最も重要です。これらの技術を実装する際の課題を克服するには、バイアスに対処し、公正なAIモデルを確保する必要があり、AI研究と機械学習の未来を形作る上でのそれらの極めて重要な役割が強調されます。

よくある質問
GPTモデルを他のLLMと比較してユニークにするものは何ですか?
OpenAIのChatGPTを含むGPTモデルは、トランスフォーマーアーキテクチャとアテンション機構を使用している点で、他の大規模言語モデル(LLM)と比較してユニークです。
LLMとGPTモデルは仕事の未来にどのような影響を与えますか?
これらのAIモデルは、タスクの自動化、生産性の向上、コンテンツ作成、カスタマーサポート、データ分析など様々な業界でのインテリジェントなアシスタンスを提供できます。
novita.ai は、100以上のAPIにアクセスできる、無限の創造性のためのワンストッププラットフォームです。画像生成、言語処理、音声強調、動画操作に至るまで、従量課金制でお手頃価格。自社製品を構築しながらGPUメンテナンスの手間から解放されます。無料でお試しください。
おすすめの記事
TOP LLMs for 2024: How to Evaluate and Improve An Open Source LLM



