
Introduction
Qu’est-ce que le raisonnement cumulatif avec les grands modèles de langage ? Pourquoi avons-nous besoin du raisonnement cumulatif pour les LLM ? À quoi ressemble le raisonnement cumulatif avec les LLM ? Les LLM peuvent-ils bien effectuer le raisonnement cumulatif ? Dans cet article, nous allons discuter de ces questions une par une de manière simple et claire, en nous référant à l’article intitulé “Cumulative Reasoning with Large Language Models” par Yifan Zhang, Jingqin Yang, Yang Yuan et Andrew Chi-Chih Yao.
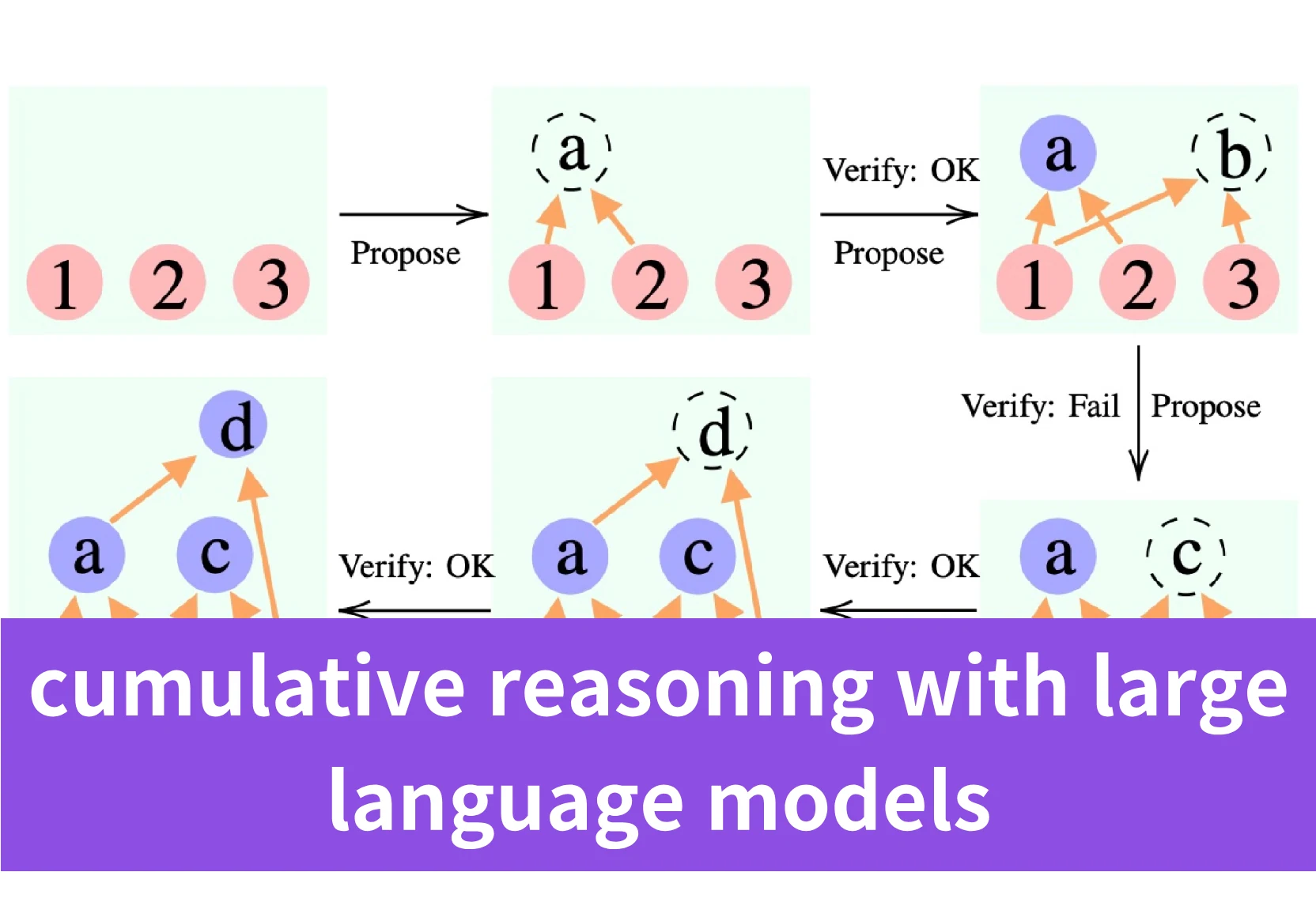
Qu’est-ce que le raisonnement cumulatif ?
L’idée centrale du cadre de raisonnement cumulatif est de décomposer les problèmes de raisonnement complexes en étapes plus petites, puis de construire itérativement la solution finale en accumulant et en vérifiant chaque étape intermédiaire.
S’inspirant des processus cognitifs humains, le raisonnement cumulatif introduit des rôles spécialisés comme le “proposeur” pour suggérer des étapes de raisonnement potentielles, les “vérificateurs” pour valider les propositions par rapport au contexte, et un “rapporteur” pour synthétiser les points accumulés en une solution finale.
Le raisonnement cumulatif permet le stockage dynamique et la composition de propositions intermédiaires vérifiées, formant un graphe acyclique orienté (DAG).

Plus précisément, dans le cadre du raisonnement cumulatif :
- Le proposeur suggère des étapes de raisonnement potentielles basées sur le contexte actuel, qui sont représentées comme de nouveaux nœuds dans le DAG.
- Le(s) vérificateur(s) évaluent si les suggestions du proposeur sont correctes et intègrent les étapes valides dans le contexte évolutif de la solution, ce qui correspond à l’ajout de nouvelles arêtes orientées au DAG.
- Le rapporteur détermine si le contexte accumulé a atteint une solution finale en fonction de l’état actuel. Si c’est le cas, il produit le résultat.
Ainsi, l’ensemble du processus de raisonnement peut être représenté comme un DAG construit dynamiquement, où les nœuds sont des étapes de raisonnement intermédiaires et les arêtes orientées capturent comment de nouvelles étapes de raisonnement sont dérivées des précédentes. Le DAG permet au processus de raisonnement de bifurquer et de reconverger, et permet de revisiter et de réutiliser les résultats de raisonnement précédents, reflétant mieux le processus de pensée flexible à plusieurs chemins des humains pour résoudre des problèmes complexes.
Pourquoi avons-nous besoin du raisonnement cumulatif pour les LLM ?
Malgré les progrès récents des grands modèles de langage (LLM) dans diverses applications, leur capacité à résoudre des problèmes de raisonnement complexes en plusieurs étapes reste limitée. Les méthodes existantes comme le Chain-of-Thought (CoT) et le Tree-of-Thought (ToT), bien qu’elles tentent de guider les LLM à travers un processus de raisonnement étape par étape plus structuré, manquent de mécanismes dynamiques pour stocker et exploiter les résultats intermédiaires générés pendant le processus de raisonnement. Cette incapacité à s’appuyer efficacement sur les propositions précédentes et à les composer restreint leurs performances sur des problèmes complexes et multiformes nécessitant un raisonnement nuancé sur plusieurs étapes.
S’inspirant des processus cognitifs humains, le raisonnement cumulatif introduit des rôles spécialisés comme le “proposeur” pour suggérer des étapes de raisonnement potentielles, les “vérificateurs” pour valider les propositions par rapport au contexte, et un “rapporteur” pour synthétiser les points accumulés en une solution finale. Cette décomposition en cycles itératifs de proposition, vérification et rapport permet aux LLM de décomposer les tâches complexes en composants gérables.
Crucialement, le raisonnement cumulatif permet le stockage dynamique et la composition de propositions intermédiaires vérifiées, formant un graphe acyclique orienté (DAG) plutôt qu’une simple chaîne linéaire ou une structure arborescente. Cette flexibilité structurelle pour exploiter un contexte plus large de validations précédentes reflète le raisonnement nuancé non linéaire utilisé par les humains pour résoudre des problèmes complexes en plusieurs étapes. Ainsi, le raisonnement cumulatif débloque des capacités de raisonnement plus robustes et polyvalentes pour les grands modèles de langage.
À quoi ressemble le raisonnement cumulatif avec les LLM ?
Construction des rôles du modèle de langage
Suivant le cadre du raisonnement cumulatif, les auteurs ont construit trois rôles de modèle de langage :
- Proposeur : suggère des étapes de raisonnement potentielles basées sur le contexte actuel
- Vérificateur : évalue les suggestions du proposeur pour leur exactitude et intègre les étapes valides dans le contexte
- Rapporteur : détermine si le contexte accumulé mène à une solution définitive
Ces trois rôles peuvent utiliser le même grand modèle de langage, avec des prompts spécifiques pour attribuer différents rôles.

Configuration des références
Pour évaluer l’efficacité du raisonnement cumulatif, les auteurs ont configuré les références suivantes :
- Prompt direct entrée-sortie (Direct)
- Prompt Chain-of-Thought (CoT)
- Prompt Chain-of-Thought auto-vérifié (CoT-SC)
- Prompt Tree-of-Thought (ToT)
Suivi des procédures expérimentales
Les auteurs ont testé divers grands modèles de langage, y compris GPT-3.5, GPT-4 et les modèles LLaMA. Les procédures expérimentales sont les suivantes :
- Pour chaque problème dans un ensemble de données, saisir le problème dans le proposeur
- Le proposeur génère une série de suggestions de raisonnement comme étapes intermédiaires
- Introduire les étapes intermédiaires dans le vérificateur, qui évalue chaque étape
- Les étapes valides sont intégrées dans le contexte, tandis que les étapes invalides sont écartées
- Répéter le processus ci-dessus jusqu’à ce que le rapporteur détermine qu’une solution finale peut être donnée
- Dans certaines expériences, le vote majoritaire ou d’autres stratégies sont utilisés pour améliorer la robustesse
Sélection des ensembles de données d’évaluation
Les auteurs ont sélectionné plusieurs ensembles de données à travers différents types de tâches de raisonnement complexes pour l’évaluation, notamment :
- Tâches d’inférence logique : ensemble de données FOLIO wiki, ensemble de données AutoTNLI
- Puzzle mathématique du Jeu du 24
- Résolution de problèmes mathématiques : ensemble de données MATH
Les LLM peuvent-ils bien effectuer le raisonnement cumulatif ?
La réponse est simple : Oui ! Les résultats expérimentaux montrent que le cadre CR surpasse significativement les méthodes de référence dans toutes les tâches évaluées.
Performance globale
Sur l’ensemble de données FOLIO wiki, il améliore la précision de 85,02 % à 98,04 % ; sur l’ensemble de données AutoTNLI, il montre jusqu’à 9,3 % d’amélioration relative par rapport au Chain-of-Thought ; dans le Jeu du 24, il atteint une précision de 98 %, soit une amélioration de 24 % par rapport à la meilleure méthode antérieure ; sur l’ensemble de données MATH, CR obtient une amélioration absolue de 4,2 % et un gain relatif de 43 % sur les problèmes de niveau 5 les plus difficiles. Notamment, en intégrant CR avec un environnement de code, les auteurs atteignent une précision de 72,2 % sur l’ensemble de données MATH, surpassant le meilleur précédent de 38,8 % en relatif.

Supériorité par rapport au Chain of Thought (CoT) et au Tree of Thought (ToT)
Le raisonnement cumulatif (CR) démontre sa supériorité par rapport au Chain of Thought (CoT) et au Tree of Thought (ToT) à travers une série de résultats empiriques sur diverses tâches. Sur les tâches d’inférence logique utilisant les ensembles de données FOLIO wiki et AutoTNLI, CR a montré des performances remarquables, atteignant un taux de précision de 98,04 % sur l’ensemble de données FOLIO organisé, ce qui constitue un bond notable par rapport au 96,09 % de CoT-SC. Cette avancée est attribuée à la capacité de CR à stocker dynamiquement et à exploiter les résultats intermédiaires, formant un graphe acyclique orienté (DAG) qui permet un contexte plus large de propositions validées.
Dans le Jeu du 24, un puzzle mathématique, CR a excellé avec un taux de précision de 98 %, améliorant ToT de 24 % et ce avec seulement un quart des états visités, soulignant son efficacité et sa capacité à résoudre des problèmes.
De plus, sur l’ensemble de données MATH, CR a non seulement établi de nouveaux benchmarks avec une augmentation de 4,2 % par rapport aux méthodes précédentes, mais a également montré une amélioration relative de 43 % sur les problèmes les plus difficiles. L’intégration de CR avec un environnement Python a conduit à une précision frappante de 72,2 %, surpassant des méthodes comme PoT et PAL de 38,8 %. Ces résultats illustrent collectivement l’adaptabilité, la robustesse et les capacités de raisonnement améliorées de CR par rapport à CoT et ToT.

Quelles sont les orientations futures du raisonnement cumulatif avec les LLM ?
Intégration avec les systèmes symboliques
L’article discute du potentiel de combiner CR avec un environnement Python pour exploiter les capacités de calcul et de raisonnement logique des LLM. Les travaux futurs pourraient explorer une intégration plus poussée avec des systèmes symboliques, des graphes de connaissances ou des prouveurs de théorèmes formels pour améliorer encore la précision et la complexité du raisonnement.
Amélioration des capacités de généralisation
Bien que CR ait montré du succès dans des domaines spécifiques, étendre ses capacités de généralisation à un plus large éventail de tâches et de domaines sera crucial. Cela pourrait impliquer d’adapter CR pour gérer différents types de raisonnement et de résolution de problèmes dans diverses disciplines.
Augmentation de la robustesse et de la tolérance aux erreurs
L’article souligne la nature tolérante aux erreurs de CR. Les travaux futurs pourraient se concentrer sur le renforcement de la robustesse de CR, en particulier dans le traitement de données ambiguës ou bruyantes, et sur l’amélioration de sa capacité à se remettre d’étapes intermédiaires incorrectes.
Référencement et normalisation
Le développement de benchmarks standardisés et de métriques d’évaluation spécifiquement pour les tâches de raisonnement cumulatif pourrait aider à évaluer systématiquement les progrès et à comparer différentes approches.
Comment puis-je implémenter le raisonnement cumulatif avec les grands modèles de langage ?
La plupart des codes fournis par les auteurs nécessitent une connexion à l’API OpenAI pour les modèles GPT 3.5 et 4, ce qui devrait être votre première étape.
Ensuite, que vous souhaitiez résoudre des problèmes mathématiques, jouer au Jeu 24 ou reproduire des expériences de raisonnement cumulatif, exécutez simplement les fichiers Python spécifiques fournis sur cette page Github : https://github.com/iiis-ai/cumulative-reasoning.
De plus, si vous souhaitez tester le raisonnement cumulatif avec des modèles LLaMA comme les auteurs l’ont fait dans l’article ou avec d’autres LLM, vous pouvez utiliser Novita AI LLM API pour accéder à plusieurs LLM.

Conclusion
En conclusion, cet article de blog a offert un aperçu complet du raisonnement cumulatif avec les LLM, une approche novatrice qui améliore considérablement les capacités de résolution de problèmes complexes des LLM. En décomposant les problèmes complexes en étapes plus petites et en construisant itérativement des solutions à travers un processus de proposition, de vérification et de rapport, le raisonnement cumulatif reflète les stratégies cognitives humaines.
Les résultats provenant de divers ensembles de données étaient impressionnants, montrant des améliorations substantielles de la précision, en particulier lorsque le raisonnement cumulatif était intégré à un environnement de code. De plus, les résultats ont démontré la supériorité du raisonnement cumulatif par rapport aux méthodes existantes comme Chain-of-Thought et Tree-of-Thought.
Dans l’ensemble, les orientations futures du raisonnement cumulatif avec les LLM ont le potentiel de propulser les LLM vers de nouveaux sommets en matière de raisonnement en IA, conduisant à des capacités de résolution de problèmes plus sophistiquées et plus proches de l’humain.
Références
Zhang, Y., Yang, J., Yuan, Y., & Yao, A. C.-C. (2024). Cumulative Reasoning with Large Language Models. IIIS, Tsinghua University. https://arxiv.org/pdf/2308.04371
Novita AI, la plateforme tout-en-un pour une créativité illimitée qui vous donne accès à plus de 100 API. De la génération d’images au traitement du langage, en passant par l’amélioration audio et la manipulation vidéo, avec un paiement à l’utilisation avantageux, elle vous libère des tracas de la maintenance GPU tout en construisant vos propres produits. Essayez-la gratuitement.



