
Introduction
What is cumulative reasoning with large language models? Why do we need cumulative reasoning for LLMs? What does cumulative reasoning with LLMs look like? Can LLMs Do Cumulative Reasoning Well? In this blog, we will discuss these questions one by one in a plain and simple way, referencing the paper titled “Cumulative Reasoning with Large Language Models” by Yifan Zhang, Jingqin Yang, Yang Yuan and Andrew Chi-Chih Yao.
What Is Cumulative Reasoning?
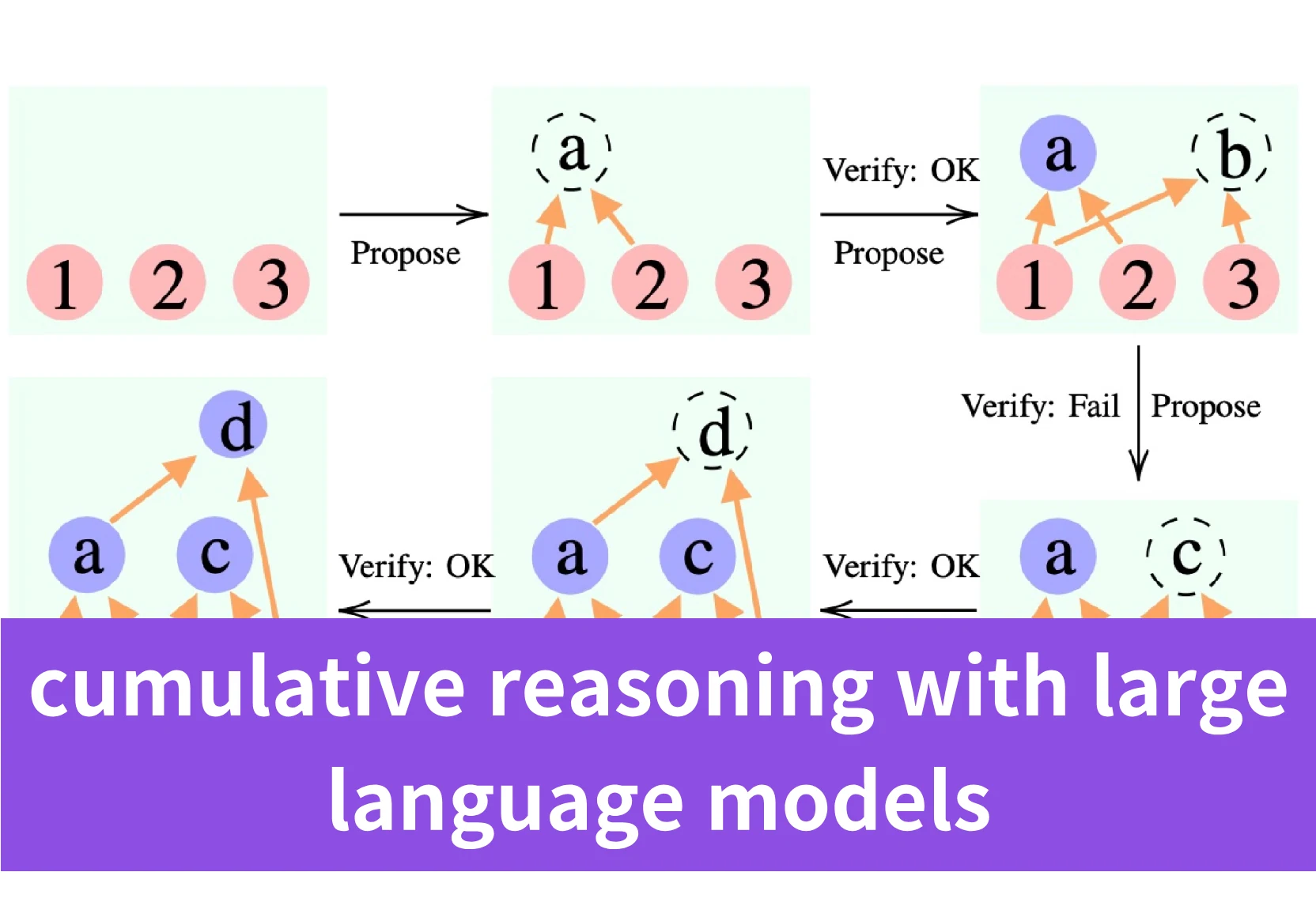
The core idea behind the cumulative reasoning framework is to break down complex reasoning problems into smaller steps, and then iteratively build up the final solution by accumulating and verifying each intermediate step.
Drawing inspiration from human cognitive processes, cumulative reasoning introduces specialized roles like the “proposer” to suggest potential reasoning steps, “verifiers” to validate proposals against context, and a “reporter” to synthesize accumulated points into a final solution.
Cumulative reasoning enables the dynamic storage and composition of verified intermediate propositions, forming a directed acyclic graph (DAG).

Specifically, in the cumulative reasoning framework:
- The proposer suggests potential reasoning steps based on the current context, which are represented as new nodes in the DAG.
- The verifier(s) evaluate whether the proposer’s suggestions are correct and incorporate valid steps into the evolving solution context, which corresponds to adding new directed edges to the DAG.
- The reporter determines whether the accumulated context has reached a final solution based on the current state. If so, it outputs the result.
Therefore, the entire reasoning process can be represented as a dynamically constructed DAG, where nodes are intermediate reasoning steps, and directed edges capture how new reasoning steps are derived from previous ones. The DAG allows the reasoning process to branch out and reconverge, and enables revisiting and reusing previous reasoning results, better mirroring the flexible multi-path thinking process of humans in solving complex problems.
Why Do We Need Cumulative Reasoning for LLMs?
Despite recent advancements of large language models (LLMs) in various applications, their ability to solve complex, multi-step reasoning problems remains limited. Existing methods like Chain-of-Thought (CoT) and Tree-of-Thought (ToT) prompting, though attempting to guide LLMs through a more structured step-by-step reasoning process, lack dynamic mechanisms for storing and leveraging intermediate results generated during the reasoning process. This inability to effectively build upon and compose previous propositions restricts their performance on intricate, multi-faceted problems requiring nuanced reasoning over multiple steps.
Drawing inspiration from human cognitive processes, cumulative reasoning introduces specialized roles like the “proposer” to suggest potential reasoning steps, “verifiers” to validate proposals against context, and a “reporter” to synthesize accumulated points into a final solution. This decomposition into iterative cycles of proposal, verification, and reporting allows LLMs to break down complex tasks into manageable components.
Crucially, cumulative reasoning enables the dynamic storage and composition of verified intermediate propositions, forming a directed acyclic graph (DAG) rather than just a linear chain or tree structure. This structural flexibility to leverage a broader context of previous validations mirrors the nuanced, non-linear reasoning employed by humans to tackle complex multi-step problems. As such, cumulative reasoning unlocks more robust and versatile reasoning capabilities for large language models.
What Does Cumulative Reasoning With LLMs Look Like?
Constructing Language Model Roles
Following the Cumulative Reasoning framework, the authors constructed three language model roles:
- Proposer: Suggests potential reasoning steps based on the current context
- Verifier: Evaluates the proposer’s suggestions for correctness and incorporates valid steps into the context
- Reporter: Determines whether the accumulated context leads to a definitive solution
These three roles can use the same large language model, with specific prompts to assign different roles.

Setting Up Baselines
To evaluate the effectiveness of Cumulative Reasoning, the authors set up the following baselines:
- Direct input-output prompting (Direct)
- Chain-of-Thought prompting (CoT)
- Self-Verified Chain-of-Thought prompting (CoT-SC)
- Tree-of-Thought prompting (ToT)
Following Experiment Procedures
The authors tested various large language models, including GPT-3.5, GPT-4, and LLaMA models. The experiment procedures are as follows:
- For each problem in a dataset, input the problem to the proposer
- The proposer generates a series of reasoning suggestions as intermediate steps
- Feed the intermediate steps to the verifier, which evaluates each step
- Valid steps are incorporated into the context, while invalid steps are discarded
- Repeat the above process until the reporter determines a final solution can be given
- In some experiments, majority voting or other strategies are used to improve robustness
Selecting Evaluation Datasets
The authors selected multiple datasets across different types of complex reasoning tasks for evaluation, including:
- Logical inference tasks: FOLIO wiki dataset, AutoTNLI dataset
- Game of 24 math puzzle
- Math problem solving: MATH dataset
Can LLMs Do Cumulative Reasoning Well?
The simple answer is: Yes! The experimental results demonstrate that the CR framework significantly outperforms baseline methods across all evaluated tasks.
Overall Performance
On the FOLIO wiki dataset, it improves accuracy from 85.02% to 98.04%; on the AutoTNLI dataset, it shows up to 9.3% relative improvement over Chain-of-Thought; in the Game of 24, it achieves 98% accuracy, marking a 24% improvement over the prior best method; on the MATH dataset, CR obtains a 4.2% absolute improvement and a 43% relative gain on the most challenging level 5 problems. Notably, by integrating CR with a code environment, the authors achieve 72.2% accuracy on the MATH dataset, outperforming the previous best by 38.8% relatively.

Superiority Over Chain of Thought (CoT) and Tree of Thought (ToT)
Cumulative Reasoning (CR) demonstrates its superiority over Chain of Thought (CoT) and Tree of Thought (ToT) through a series of empirical results across various tasks. On logical inference tasks using datasets like FOLIO wiki and AutoTNLI, CR showed remarkable performance, achieving a 98.04% accuracy rate on the curated FOLIO dataset, which is a notable leap from CoT-SC’s 96.09%. This advancement is attributed to CR’s ability to dynamically store and leverage intermediate results, forming a Directed Acyclic Graph (DAG) that allows for a broader context of validated propositions.
In the Game of 24, a mathematical puzzle, CR excelled with a 98% accuracy rate, improving upon ToT by 24% and doing so with only a quarter of the visited states, underscoring its efficiency and problem-solving prowess.
Furthermore, on the MATH dataset, CR not only set new benchmarks with a 4.2% increase over previous methods but also showed a 43% relative improvement on the most difficult problems. The integration of CR with a Python code environment led to a striking 72.2% accuracy, outperforming methods like PoT and PAL by 38.8%. These results collectively illustrate the adaptability, robustness, and enhanced reasoning capabilities of CR in comparison to CoT and ToT.

What Are the Future Directions of Cumulative Reasoning With LLMs?
Integration with Symbolic Systems
The article discusses the potential of combining CR with a Python code environment to harness the computational and logical reasoning capabilities of LLMs. Future work could explore deeper integration with symbolic systems, knowledge graphs, or formal theorem provers to further enhance reasoning accuracy and complexity.
Enhancing Generalization Capabilities
While CR has shown success in specific domains, extending its generalization capabilities to a broader range of tasks and domains will be crucial. This could involve adapting CR to handle different types of reasoning and problem-solving across various disciplines.
Increasing Robustness and Error Tolerance
The article highlights the error-tolerant nature of CR. Future work could focus on making CR even more robust, especially in handling ambiguous or noisy data, and improving its ability to recover from incorrect intermediate steps.
Benchmarking and Standardization
Developing standardized benchmarks and evaluation metrics specifically for cumulative reasoning tasks could help in systematically assessing the progress and comparing different approaches.
How Can I Implement Cumulative Reasoning With Large Language Models?
Most codes provided by the authors require a connection to OpenAI API for GPT 3.5 and 4 models, which should be your first step.
Next, whether you want to solve math problems, play Game 24, or replicate cumulative reasoning experiments, just run the specific Python files provided on this Github page: https://github.com/iiis-ai/cumulative-reasoning.
In addition, if you want to test cumulative reasoning with LLaMA models like the authors did in the paper or with other LLMs, you can use Novita AI LLM API to access multiple LLMs.

Conclusion
In conclusion, the blog post has offered a comprehensive overview of cumulative reasoning with LLMs, a novel approach that significantly enhances the complex problem-solving abilities of LLMs. By dissecting complex problems into smaller steps and iteratively building up solutions through a process of proposal, verification, and reporting, cumulative reasoning mirrors human cognitive strategies.
The results from various datasets were impressive, showing substantial improvements in accuracy, especially when cumulative reasoning was integrated with a code environment. What’s more, the results demonstrated the superiority of cumulative reasoning over existing methods like Chain-of-Thought and Tree-of-Thought.
Overall, the future directions of cumulative reasoning with LLMs hold the potential to propel LLMs to new heights in AI reasoning, leading to more sophisticated and human-like problem-solving capabilities.
References
Zhang, Y., Yang, J., Yuan, Y., & Yao, A. C.-C. (2024). Cumulative Reasoning with Large Language Models. IIIS, Tsinghua University. https://arxiv.org/pdf/2308.04371
Novita AI, the one-stop platform for limitless creativity that gives you access to 100+ APIs. From image generation and language processing to audio enhancement and video manipulation, cheap pay-as-you-go, it frees you from GPU maintenance hassles while building your own products. Try it for free.



