
Einführung
Was ist kumulatives Reasoning mit großen Sprachmodellen? Warum brauchen wir kumulatives Reasoning für LLMs? Wie sieht kumulatives Reasoning mit LLMs aus? Können LLMs kumulatives Reasoning gut umsetzen? In diesem Blog gehen wir diese Fragen nacheinander auf einfache und verständliche Weise an, unter Bezugnahme auf das Papier mit dem Titel “Cumulative Reasoning with Large Language Models” von Yifan Zhang, Jingqin Yang, Yang Yuan und Andrew Chi-Chih Yao.
Was ist kumulatives Reasoning?
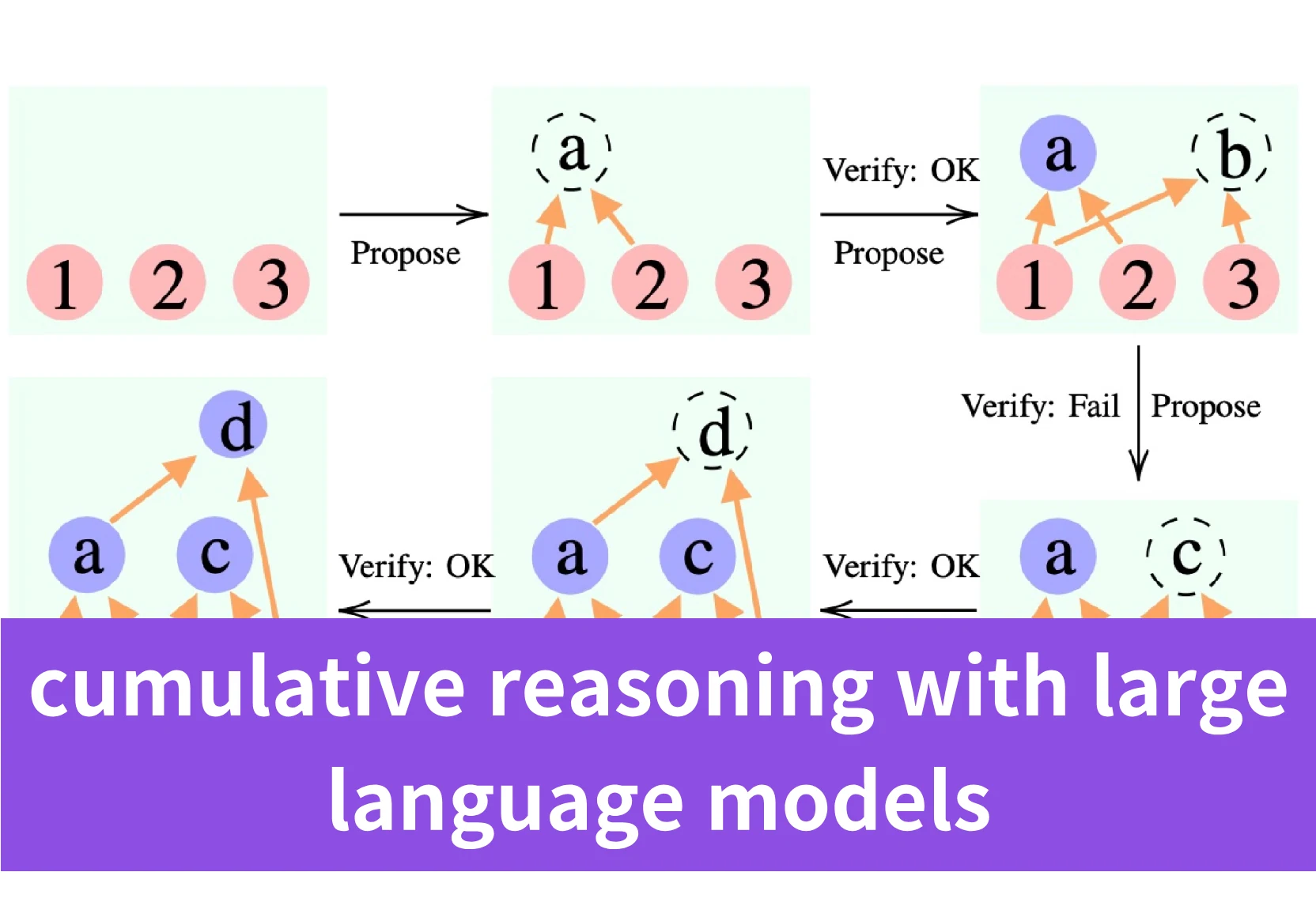
Die Kernidee hinter dem Framework des kumulativen Reasonings besteht darin, komplexe Reasoning-Probleme in kleinere Schritte zu zerlegen und dann die endgültige Lösung iterativ aufzubauen, indem jeder Zwischenschritt akkumuliert und verifiziert wird.
Inspiriert von menschlichen kognitiven Prozessen führt das kumulative Reasoning spezialisierte Rollen ein, wie den “Proposer” zur Vorschlag potenzieller Reasoning-Schritte, “Verifier” zur Validierung von Vorschlägen im Kontext und einen “Reporter” zur Synthese akkumulierter Punkte in eine endgültige Lösung.
Kumulatives Reasoning ermöglicht die dynamische Speicherung und Zusammensetzung verifizierter Zwischenaussagen und bildet einen gerichteten azyklischen Graphen (DAG).

Konkret im Framework des kumulativen Reasonings:
- Der Proposer schlägt basierend auf dem aktuellen Kontext potenzielle Reasoning-Schritte vor, die als neue Knoten im DAG dargestellt werden.
- Die Verifier bewerten, ob die Vorschläge des Proposers korrekt sind, und fügen gültige Schritte in den sich entwickelnden Lösungskontext ein, was dem Hinzufügen neuer gerichteter Kanten zum DAG entspricht.
- Der Reporter entscheidet basierend auf dem aktuellen Zustand, ob der akkumulierte Kontext zu einer endgültigen Lösung gelangt ist. Falls ja, gibt er das Ergebnis aus.
Daher kann der gesamte Reasoning-Prozess als ein dynamisch konstruierter DAG dargestellt werden, wobei Knoten Zwischenschritte des Reasonings sind und gerichtete Kanten erfassen, wie neue Reasoning-Schritte aus vorherigen abgeleitet werden. Der DAG ermöglicht es dem Reasoning-Prozess, sich zu verzweigen und wieder zu vereinen, und ermöglicht das Wiederaufgreifen und Wiederverwenden früherer Reasoning-Ergebnisse, was den flexiblen mehrpfadigen Denkprozess des Menschen bei der Lösung komplexer Probleme besser widerspiegelt.
Warum brauchen wir kumulatives Reasoning für LLMs?
Trotz der jüngsten Fortschritte großer Sprachmodelle (LLMs) in verschiedenen Anwendungen bleibt ihre Fähigkeit, komplexe, mehrschrittige Reasoning-Probleme zu lösen, begrenzt. Bestehende Methoden wie Chain-of-Thought (CoT) und Tree-of-Thought (ToT) versuchen zwar, LLMs durch einen strukturierteren schrittweisen Reasoning-Prozess zu führen, entbehren jedoch dynamischer Mechanismen zur Speicherung und Nutzung von Zwischenergebnissen, die während des Reasoning-Prozesses erzeugt werden. Diese Unfähigkeit, frühere Aussagen effektiv aufzubauen und zu kombinieren, schränkt ihre Leistung bei komplexen, vielschichtigen Problemen ein, die ein nuanciertes Reasoning über mehrere Schritte erfordern.
Inspiriert von menschlichen kognitiven Prozessen führt das kumulative Reasoning spezialisierte Rollen ein, wie den “Proposer” zur Vorschlag potenzieller Reasoning-Schritte, “Verifier” zur Validierung von Vorschlägen im Kontext und einen “Reporter” zur Synthese akkumulierter Punkte in eine endgültige Lösung. Diese Zerlegung in iterative Zyklen von Vorschlag, Verifikation und Berichterstattung ermöglicht es LLMs, komplexe Aufgaben in handhabbare Komponenten zu zerlegen.
Entscheidend ist, dass kumulatives Reasoning die dynamische Speicherung und Zusammensetzung verifizierter Zwischenaussagen ermöglicht und so einen gerichteten azyklischen Graphen (DAG) bildet, anstatt nur eine lineare Kette oder Baumstruktur. Diese strukturelle Flexibilität, einen breiteren Kontext früherer Validierungen zu nutzen, spiegelt das nuancierte, nichtlineare Reasoning wider, das Menschen zur Bewältigung komplexer mehrschrittiger Probleme einsetzen. Daher erschließt kumulatives Reasoning robustere und vielseitigere Reasoning-Fähigkeiten für große Sprachmodelle.
Wie sieht kumulatives Reasoning mit LLMs aus?
Konstruktion von Sprachmodell-Rollen
Dem Framework des kumulativen Reasonings folgend konstruierten die Autoren drei Sprachmodell-Rollen:
- Proposer: Schlägt basierend auf dem aktuellen Kontext potenzielle Reasoning-Schritte vor
- Verifier: Bewertet die Vorschläge des Proposers auf Korrektheit und fügt gültige Schritte in den Kontext ein
- Reporter: Entscheidet, ob der akkumulierte Kontext zu einer endgültigen Lösung führt
Diese drei Rollen können dasselbe große Sprachmodell verwenden, wobei spezifische Aufforderungen zur Zuweisung unterschiedlicher Rollen dienen.

Einrichtung von Basislinien
Um die Wirksamkeit des kumulativen Reasonings zu bewerten, richteten die Autoren die folgenden Basislinien ein:
- Direktes Input-Output-Prompting (Direct)
- Chain-of-Thought-Prompting (CoT)
- Selbstverifiziertes Chain-of-Thought-Prompting (CoT-SC)
- Tree-of-Thought-Prompting (ToT)
Durchführung von Experimenten
Die Autoren testeten verschiedene große Sprachmodelle, darunter GPT-3.5, GPT-4 und LLaMA-Modelle. Die Versuchsabläufe sind wie folgt:
- Für jedes Problem in einem Datensatz wird das Problem dem Proposer eingegeben.
- Der Proposer generiert eine Reihe von Reasoning-Vorschlägen als Zwischenschritte.
- Die Zwischenschritte werden dem Verifier zugeführt, der jeden Schritt bewertet.
- Gültige Schritte werden in den Kontext aufgenommen, ungültige Schritte werden verworfen.
- Wiederholen Sie den obigen Vorgang, bis der Reporter feststellt, dass eine endgültige Lösung gegeben werden kann.
- In einigen Experimenten werden Mehrheitsentscheidungen oder andere Strategien verwendet, um die Robustheit zu verbessern.
Auswahl von Evaluierungsdatensätzen
Die Autoren wählten mehrere Datensätze aus verschiedenen Arten komplexer Reasoning-Aufgaben zur Evaluierung aus, darunter:
- Logische Inferenzaufgaben: FOLIO wiki Datensatz, AutoTNLI Datensatz
- Game of 24 Mathe-Puzzle
- Mathe-Problemlösung: MATH Datensatz
Können LLMs kumulatives Reasoning gut umsetzen?
Die kurze Antwort lautet: Ja! Die experimentellen Ergebnisse zeigen, dass das CR-Framework die Basislinienmethoden in allen bewerteten Aufgaben deutlich übertrifft.
Gesamtleistung
Im FOLIO wiki Datensatz verbessert es die Genauigkeit von 85,02% auf 98,04%; im AutoTNLI Datensatz zeigt es eine relative Verbesserung von bis zu 9,3% gegenüber Chain-of-Thought; im Game of 24 erreicht es eine Genauigkeit von 98%, was eine Verbesserung von 24% gegenüber der bisher besten Methode darstellt; im MATH Datensatz erzielt CR eine absolute Verbesserung von 4,2% und einen relativen Gewinn von 43% bei den anspruchsvollsten Problemen der Stufe 5. Bemerkenswerterweise erreichen die Autoren durch die Integration von CR mit einer Code-Umgebung eine Genauigkeit von 72,2% im MATH Datensatz und übertreffen damit die bisher beste Methode relativ um 38,8%.

Überlegenheit gegenüber Chain of Thought (CoT) und Tree of Thought (ToT)
Kumulatives Reasoning (CR) zeigt seine Überlegenheit gegenüber Chain of Thought (CoT) und Tree of Thought (ToT) durch eine Reihe von empirischen Ergebnissen bei verschiedenen Aufgaben. Bei logischen Inferenzaufgaben mit Datensätzen wie FOLIO wiki und AutoTNLI zeigte CR eine bemerkenswerte Leistung, erreichte eine Genauigkeitsrate von 98,04% im kuratierten FOLIO-Datensatz, was einen deutlichen Sprung gegenüber CoT-SC mit 96,09% darstellt. Dieser Fortschritt wird auf die Fähigkeit von CR zurückgeführt, Zwischenergebnisse dynamisch zu speichern und zu nutzen, wodurch ein gerichteter azyklischer Graph (DAG) entsteht, der einen breiteren Kontext validierter Aussagen ermöglicht.
Im Game of 24, einem Mathe-Puzzle, glänzte CR mit einer Genauigkeit von 98% und verbesserte sich gegenüber ToT um 24%, und zwar mit nur einem Viertel der besuchten Zustände, was seine Effizienz und Problemlösungsfähigkeit unterstreicht.
Darüber hinaus setzte CR im MATH-Datensatz nicht nur neue Maßstäbe mit einer Steigerung von 4,2% gegenüber früheren Methoden, sondern zeigte auch eine relative Verbesserung von 43% bei den schwierigsten Problemen. Die Integration von CR mit einer Python-Code-Umgebung führte zu einer beeindruckenden Genauigkeit von 72,2% und übertraf Methoden wie PoT und PAL um 38,8%. Diese Ergebnisse veranschaulichen gemeinsam die Anpassungsfähigkeit, Robustheit und verbesserten Reasoning-Fähigkeiten von CR im Vergleich zu CoT und ToT.

Was sind die zukünftigen Richtungen des kumulativen Reasonings mit LLMs?
Integration mit symbolischen Systemen
Der Artikel diskutiert das Potenzial, CR mit einer Python-Code-Umgebung zu kombinieren, um die rechnerischen und logischen Reasoning-Fähigkeiten von LLMs zu nutzen. Zukünftige Arbeiten könnten eine tiefere Integration mit symbolischen Systemen, Wissensgraphen oder formalen Theorembeweisern erforschen, um die Reasoning-Genauigkeit und -Komplexität weiter zu verbessern.
Verbesserung der Generalisierungsfähigkeiten
Während CR in bestimmten Bereichen erfolgreich war, wird die Erweiterung seiner Generalisierungsfähigkeiten auf eine breitere Palette von Aufgaben und Domänen entscheidend sein. Dies könnte die Anpassung von CR an verschiedene Arten des Reasonings und der Problemlösung in verschiedenen Disziplinen umfassen.
Erhöhung der Robustheit und Fehlertoleranz
Der Artikel hebt die fehlertolerante Natur von CR hervor. Zukünftige Arbeiten könnten sich darauf konzentrieren, CR noch robuster zu machen, insbesondere bei der Handhabung mehrdeutiger oder verrauschter Daten, und seine Fähigkeit, sich von falschen Zwischenschritten zu erholen, zu verbessern.
Benchmarking und Standardisierung
Die Entwicklung standardisierter Benchmarks und Bewertungsmetriken speziell für kumulative Reasoning-Aufgaben könnte helfen, den Fortschritt systematisch zu bewerten und verschiedene Ansätze zu vergleichen.
Wie kann ich kumulatives Reasoning mit großen Sprachmodellen implementieren?
Die meisten von den Autoren bereitgestellten Codes erfordern eine Verbindung zur OpenAI API für GPT 3.5 und 4 Modelle, was Ihr erster Schritt sein sollte.
Als nächstes, ob Sie Mathe-Probleme lösen, Game 24 spielen oder kumulative Reasoning-Experimente replizieren möchten, führen Sie einfach die spezifischen Python-Dateien aus, die auf dieser Github-Seite bereitgestellt werden: https://github.com/iiis-ai/cumulative-reasoning.
Wenn Sie außerdem kumulatives Reasoning mit LLaMA-Modellen testen möchten, wie die Autoren es im Papier getan haben, oder mit anderen LLMs, können Sie Novita AI LLM API verwenden, um auf mehrere LLMs zuzugreifen.

Fazit
Zusammenfassend hat dieser Blogbeitrag einen umfassenden Überblick über kumulatives Reasoning mit LLMs gegeben, einen neuartigen Ansatz, der die komplexen Problemlösungsfähigkeiten von LLMs erheblich verbessert. Indem komplexe Probleme in kleinere Schritte zerlegt und Lösungen iterativ durch einen Prozess von Vorschlag, Verifikation und Berichterstattung aufgebaut werden, spiegelt kumulatives Reasoning menschliche kognitive Strategien wider.
Die Ergebnisse aus verschiedenen Datensätzen waren beeindruckend und zeigten deutliche Verbesserungen der Genauigkeit, insbesondere wenn kumulatives Reasoning in eine Code-Umgebung integriert wurde. Darüber hinaus demonstrierten die Ergebnisse die Überlegenheit des kumulativen Reasonings gegenüber bestehenden Methoden wie Chain-of-Thought und Tree-of-Thought.
Insgesamt bergen die zukünftigen Richtungen des kumulativen Reasonings mit LLMs das Potenzial, LLMs zu neuen Höhen im KI-Reasoning zu führen, was zu anspruchsvolleren und menschenähnlicheren Problemlösungsfähigkeiten führt.
Referenzen
Zhang, Y., Yang, J., Yuan, Y., & Yao, A. C.-C. (2024). Cumulative Reasoning with Large Language Models. IIIS, Tsinghua University. https://arxiv.org/pdf/2308.04371
Novita AI, die One-Stop-Plattform für grenzenlose Kreativität, die Ihnen Zugang zu über 100 APIs bietet. Von Bildgenerierung und Sprachverarbeitung bis hin zu Audioverbesserung und Videomanipulation – günstig nach Pay-as-you-go-Prinzip, befreit sie Sie von GPU-Wartungsproblemen, während Sie Ihre eigenen Produkte entwickeln. Probieren Sie es kostenlos aus.



